关于缓存的一些思考
这里讨论的缓存,不是CPU中的缓存,而是介于数据库和应用程序之间,用于存放数据,从而加快访问速度,降低数据库压力的技术。
当我第一次听到缓存这个词,我是有点懵逼的。redis是一个内存型数据库,把数据放内存?在我的意识里,内存是一个宝贵的东西,把如此多的数据放在内存中,似乎非常浪费。另外的疑惑是,如果内存不够用怎么办?怎么保持缓存和数据库的一致性?
当然,上面的问题都是需要去解决的。而关于内存是否是宝贵的资源这个疑问,答案是:随着时间的推移,内存变得越来越廉价。或者说为了让数据得以高速访问,付出内存的代价是值得的。像redis这样的内存型数据库,为了支撑起互联网应用庞大的数据量,通过搭建redis集群,就可以解决。
常用的缓存技术:
1.直接在内存中缓存
通过Java的HashMap、ConcurrentHashMap等容器,直接缓存在内存中。

不要小看本地缓存,它是最快速的,因为它不需要经过网络层,就可以直接从内存中获取数据。当你选择缓存技术的时候,在考虑花里胡哨的NoSql之前,先问问自己,到底有没有必要去使用它们?
适用场景:
事实上,只要数据量不超过单机可承受的范围,你都可以使用这种方案。
比如我们公司的游戏,一个服务器的数据,全部都会通过Map缓存到内存中,然后所有对数据的操作直接在内存中进行,最后定时将缓存刷回MySQL。我们没有使用redis,原因是一个服务器峰值3000人的数据量,单机的内存是可以承受的。目前一个服务器,内存大小在40G左右。
2.内存型数据库
内存型的key-value数据库,最为出名的是redis,大量运用在互联网企业中。

相比传统的关系型数据库,redis的IO操作发生在内存中,所以速度大大提高。
保持缓存一致性的方案:
1.Cache Aside
更新: 当有更新操作到来,直接更新数据库,在成功更新数据库后将缓存淘汰。
读取:缓存命中直接读缓存,没有命中则从数据库中取出后,置入缓存中
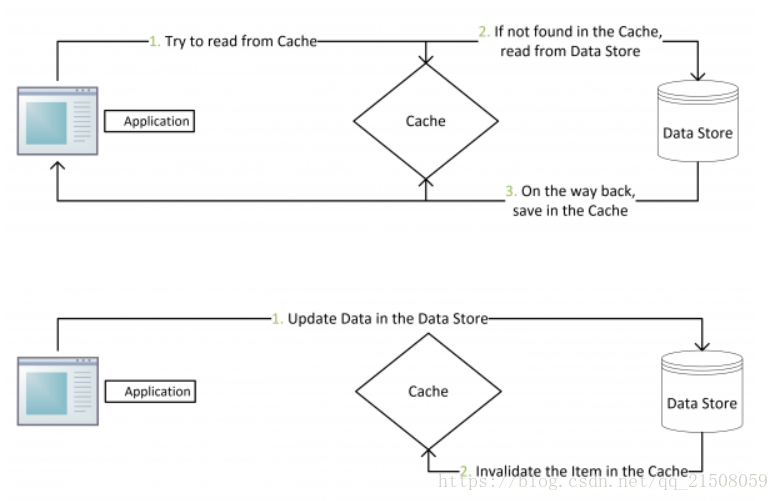
这里的关键的在于,先更新数据库,再淘汰缓存。
更新数据库后更新缓存,如果在更新数据库过程中,有读操作,会读到脏数据。但更新操作完成后,缓存会被淘汰,因此最终数据会保持一致(弱一致型)。
如果先淘汰缓存,再更新数据库。在淘汰缓存后,如果存在并发读操作,缓存中会存入旧数据,并长时间得不到更新。
事实上,先更新数据库,再淘汰缓存再在特殊的时序下,也可能存在问题。如果线程1在更新数据库,此时线程2读到脏数据,之后线程1淘汰缓存,线程2把脏数据写到缓存中,此时缓存中的脏数据也是得不到更新的。但是这种情况发生概率会很小,原因是更新数据库的操作相比redis的读操作,非常耗时。在更新数据库过程中,并发读取旧数据,并等待更新完成后淘汰缓存这么长的时间,概率非常非常小。
关于这点,参考这篇文章:缓存更新策略
2.一切以缓存为准
网上将这种策略称之为Read-through/Write-through,实际上就是以缓存中数据为准。
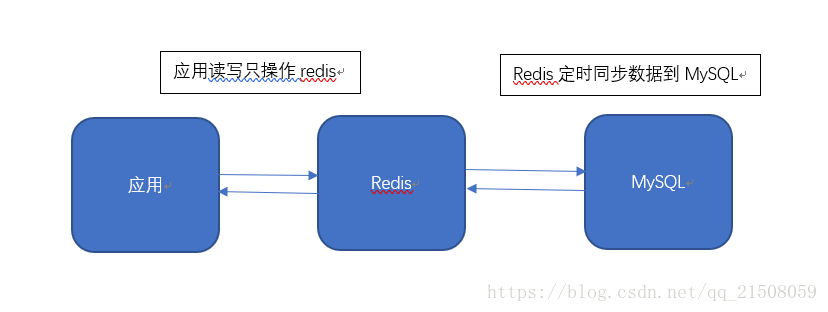
这种方式,应用程序只操作cache,因此可以加快访问速度。但实现起来并不简单,你需要有算法去标识发生改变的缓存,定时只把有改变的数据刷回数据库。
当然,这里没有考虑到数据安全的问题,关于如何保证数据不丢失,以及强一致,博主并不清楚。因为只是个小菜鸡而已。。
写在最后,本来是想结合jdbc + redis 写一个小例子的,但想想都是一些curd操作,也就没有激情了。。。