一. 概述
1.1 Hadoop概述
- Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
- 主要解决,海量数据的存储和海量数据的分析计算问题。
- 广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。

1.2 Hadoop优势
1)高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。

2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。

3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处
理速度。

4)高容错性:能够自动将失败的任务重新分配。

1.3 Hadoop 组成(面试重点)
Hadoop1.x、2.x、3.x区别
1.3.1 HDFS 架构概述
Hadoop Distributed File System,简称 HDFS,是一个分布式文件系统。

1.3.2 YARN 架构概述
Yet Another Resource Negotiator 简称 YARN ,另一种资源协调者,是 Hadoop 的资源管理器。
1)ResourceManager(RM):整个集群资源(内存、CPU等)的老大
3)ApplicationMaster(AM):单个任务运行的老大
2)NodeManager(N M):单个节点服务器资源老大
4)Container:容器,相当一台独立的服务器,里面封装了
任务运行所需要的资源,如内存、CPU、磁盘、网络等。

1.3.3 MapReduce 架构概述
MapReduce 将计算过程分为两个阶段:Map 和 Reduce
1)Map 阶段并行处理输入数据
2)Reduce 阶段对 Map 结果进行汇总

1.3.4 HDFS、YARN、MapReduce 三者关系

发布任务后,找一个结点开启容器,然后向ResourceManager申请资源,MapTask独立检索自己结点,然后返回结果。
1.4 大数据技术生态体系

图中涉及的技术名词解释如下:
1)Sqoop:Sqoop 是一款开源的工具,主要用于在 Hadoop、Hive 与传统的数据库(MySQL)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进
到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到关系型数据库中。
2)Flume:Flume 是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,
Flume 支持在日志系统中定制各类数据发送方,用于收集数据;
3)Kafka:Kafka 是一种高吞吐量的分布式发布订阅消息系统;
4)Spark:Spark 是当前最流行的开源大数据内存计算框架。可以基于 Hadoop 上存储的大数据进行计算。
5)Flink:Flink 是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。
6)Oozie:Oozie 是一个管理 Hadoop 作业(job)的工作流程调度管理系统。
7)Hbase:HBase 是一个分布式的、面向列的开源数据库。HBase 不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
8)Hive:Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的 SQL 查询功能,可以将 SQL 语句转换为 MapReduce 任务进行运行。其优点是学习成本低,可以通过类 SQL 语句快速实现简单的 MapReduce 统计,不必开发专门的 MapReduce 应用,十分适合数据仓库的统计分析。
9)ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等
二. Hadoop 运行环境搭建(开发重点)
2.1 模板虚拟机环境准备
安装模板虚拟机,IP 地址 192.168.10.100、主机名称 hadoop100、内存 4G、硬盘 50G

根据自身电脑cpu数量配置虚拟机,(本人是八个CPU,然后要四台虚拟机,所以单个虚拟机只能分到两个CPU)

2.2 在 hadoop102 安装 JDK
在一台虚拟机中安装jdk,然后其他虚拟机复制其的jdk即可。
先卸载虚拟机自带的jdk,再把jdk解压到自己制定的路径,然后在新建/etc/profile.d/my_env.sh 文件,添加如下内容


安装成功
2.3 在 hadoop102 安装 hadoop
同样解压,然后在/etc/profile.d/my_env.sh 文件,添加如下内容
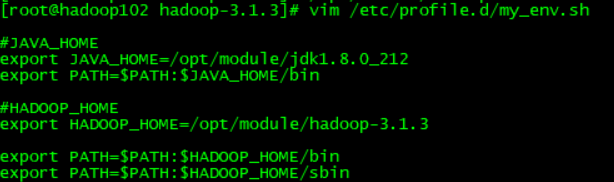
然后source检验一下
2.4 Hadoop 目录结构
1)查看 Hadoop 目录结构
[atguigu@hadoop102 hadoop-3.1.3]$ ll
总用量 52
drwxr-xr-x. 2 atguigu atguigu 4096 5 月 22 2017 bin
drwxr-xr-x. 3 atguigu atguigu 4096 5 月 22 2017 etc
drwxr-xr-x. 2 atguigu atguigu 4096 5 月 22 2017 include
drwxr-xr-x. 3 atguigu atguigu 4096 5 月 22 2017 lib
drwxr-xr-x. 2 atguigu atguigu 4096 5 月 22 2017 libexec
-rw-r–r--. 1 atguigu atguigu 15429 5 月 22 2017 LICENSE.txt
-rw-r–r--. 1 atguigu atguigu 101 5 月 22 2017 NOTICE.txt
-rw-r–r--. 1 atguigu atguigu 1366 5 月 22 2017 README.txt
drwxr-xr-x. 2 atguigu atguigu 4096 5 月 22 2017 sbin
drwxr-xr-x. 4 atguigu atguigu 4096 5 月 22 2017 share
2)重要目录
(1)bin 目录:存放对 Hadoop 相关服务(hdfs,yarn,mapred)进行操作的脚本
(2)etc 目录:Hadoop 的配置文件目录,存放 Hadoop 的配置文件
(3)lib 目录:存放 Hadoop 的本地库(对数据进行压缩解压缩功能)
(4)sbin 目录:存放启动或停止 Hadoop 相关服务的脚本
(5)share 目录:存放 Hadoop 的依赖 jar 包、文档、和官方案例
三. Hadoop 运行模式
1)Hadoop 官方网站:http://hadoop.apache.org/
2)Hadoop 运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
- 本地模式:单机运行,只是用来演示一下官方案例。生产环境不用。
- 伪分布式模式:也是单机运行,但是具备 Hadoop 集群的所有功能,一台服务器模拟一个分布式的环境。个别缺钱的公司用来测试,生产环境不用。
- 完全分布式模式:多台服务器组成分布式环境。生产环境使用。
3.1 编写集群分发脚本 xsync
1)scp(secure copy)安全拷贝
(1)scp 定义
scp 可以实现服务器与服务器之间的数据拷贝。(from server1 to server2) (2)基本语法
scp -r $pdir/$fname $user@$host:$pdir/$fname
命令 递归 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
(3)案例实操
➢ 前提:在 hadoop102、hadoop103、hadoop104 都已经创建好的/opt/module、 /opt/software 两个目录,并且已经把这两个目录修改为 atguigu:atguigu
[atguigu@hadoop102 ~]$ sudo chown atguigu:atguigu -R
/opt/module
- 在 hadoop102 上,将 hadoop102 中/opt/module/jdk1.8.0_212 目录拷贝到hadoop103 上,拷贝hadoop同理
[rosie@hadoop102 module]$ scp -r jdk1.8.0_212/ rosie@192.168.10.103:/opt/module/
4. Hadoop集群搭建
4.1 集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起。
HDFS集群负责海量数据的存储,集群中的角色主要有:
NameNode、DataNode、SecondaryNameNode
- YARN集群负责海量数据运算时的资源调度,集群中的角色主要有:
ResourceManager、NodeManager- 那mapreduce是什么呢?它其实是一个分布式运算编程框架,是应用程序开发包,由用户按照编程规范进行程序开发,后打包运行在HDFS集群上,并且受到YARN集群的资源调度管理。
4.2 集群部署方式
Hadoop部署方式分三种:
4.2.1 standalone mode(独立模式)
独立模式又称为单机模式,仅1个机器运行1个java进程,主要用于调试。
4.2.2 Pseudo-Distributed mode(伪分布式模式)
伪分布模式也是在1个机器上运行HDFS的NameNode和DataNode、YARN的 ResourceManger和NodeManager,但分别启动单独的java进程,主要用于调试。
4.2.3 Cluster mode(群集模式)
集群模式主要用于生产环境部署。会使用N台主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署在不同的机器上。
4.3 hadoop重新编译
4.3.1 为什么要编译hadoop?
由于appache给出的hadoop的安装包没有提供带C程序访问的接口,所以我们在使用本地库(本地库可以用来做压缩,以及支持C程序等等)的时候就会出问题,需要对Hadoop源码包进行重新编译,请注意,资料中已经提供好了编译过的Hadoop安装包,所以这一部分的操作,大家可以不用做,了解即可。
4.3.2 Hadoop编译文档
Hadoop的编译步骤可以参考:1_Hadoop编译文档.docx文档



4.4 启动
每台机器上每次手动启动关闭一个角色进程
HDFS集群
hdfs --daemon start namenode|datanode|secondarynamenode
hdfs --daemon stop namenode|datanode|secondarynamenode
YARN集群
yarn --daemon start resourcemanager|nodemanager
yarn --daemon stop resourcemanager|nodemanager

启动成功后,可以看到ui界面



yarn的webui界面
5.Hadoop初体验
5.1 Hadoop HDFS初体验
1.HDFS本质就是一个文件系统
2.有目录树结构 和Linux类似,分文件、文件夹
3.为什么上传一个小文件也这么慢?

5.2 MapReduce +YARN初体验
[root@node1 ~]# cd /export/server/hadoop-3.1.4/share/hadoop/mapreduce/
[root@node1 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.1.4.jar pi 2 4
跑官方示例,计算圆周率
5.3 HDFS基准测试
测试写:
确保HDFS集群和YARN集群成功启动
hadoop jar /export/server/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.4-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 10MB
说明:向HDFS文件系统中写入数据,10个文件,每个文件10MB,文件存放到/benchmarks/TestDFSIO中
Throughput:吞吐量、Average IO rate:平均IO率、IO rate std deviation:IO率标准偏差

测试读取速度:
确保HDFS集群和YARN集群成功启动
hadoop jar /export/server/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.4-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 10MB
说明:在HDFS文件系统中读入10个文件,每个文件10M
Throughput:吞吐量、Average IO rate:平均IO率、IO rate std deviation:IO率标准偏差

到此,hadoop的搭建算是初步完成了,下面会另外开篇文章开始HDFS的学习