论文名称:Res2Net: A New Multi-scale Backbone Architecture
论文下载:https://arxiv.org/abs/1904.01169
论文年份:TPAMI 2021
论文被引:844(2022/05/19)
论文代码:https://mmcheng.net/res2net/
Abstract
Representing features at multiple scales is of great importance for numerous vision tasks. Recent advances in backbone convolutional neural networks (CNNs) continually demonstrate stronger multi-scale representation ability, leading to consistent performance gains on a wide range of applications. However, most existing methods represent the multi-scale features in a layerwise manner. In this paper, we propose a novel building block for CNNs, namely Res2Net, by constructing hierarchical residual-like connections within one single residual block. The Res2Net represents multi-scale features at a granular level and increases the range of receptive fields for each network layer. The proposed Res2Net block can be plugged into the state-of-the-art backbone CNN models, e.g., ResNet, ResNeXt, and DLA. We evaluate the Res2Net block on all these models and demonstrate consistent performance gains over baseline models on widely-used datasets, e.g., CIFAR-100 and ImageNet. Further ablation studies and experimental results on representative computer vision tasks, i.e., object detection, class activation mapping, and salient object detection, further verify the superiority of the Res2Net over the state-of-the-art baseline methods.
在多个尺度上表示特征对于许多视觉任务都非常重要。骨干卷积神经网络 (CNN) 的最新进展不断展示出更强的多尺度表示能力,从而在广泛的应用中实现一致的性能提升。然而,大多数现有方法以分层方式表示多尺度特征。在本文中,我们提出了一种新的 CNN 构建块,即 Res2Net,通过在单个残差块内构建分层的残差状连接。 Res2Net 在粒度级别表示多尺度特征,并增加每个网络层的感受野范围。提出的 Res2Net 块可以插入最先进的主干 CNN 模型,例如 ResNet、ResNeXt 和 DLA。我们在所有这些模型上评估 Res2Net 块,并在广泛使用的数据集(例如 CIFAR-100 和 ImageNet)上展示了与基线模型相比的一致性能提升。对代表性计算机视觉任务(即目标检测、类激活映射和显着目标检测)的进一步消融研究和实验结果,进一步验证了 Res2Net 相对于最先进的基线方法的优越性。
1 INTRODUCTION
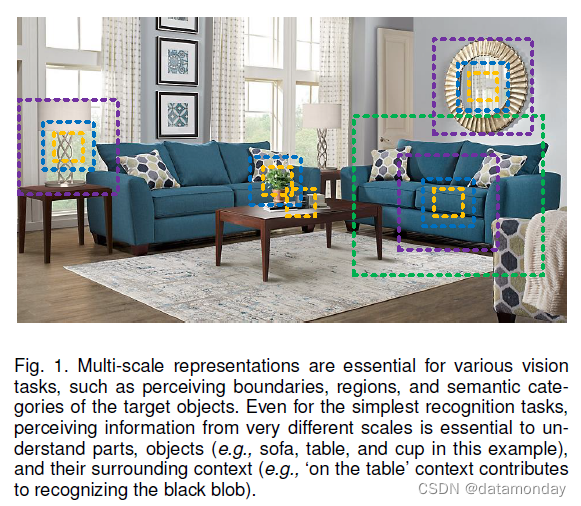
视觉模式在自然场景中以多尺度出现,如图 1 所示。首先,物体可能以不同尺寸出现在单个图像中,例如,沙发和杯子的尺寸不同。其次,目标的基本上下文信息可能比目标本身占据更大的区域。例如,我们需要依靠大桌子作为上下文来更好地判断放在上面的黑色小斑点是杯子还是笔筒。第三,感知不同尺度的信息对于理解部分和目标对于细粒度分类和语义分割等任务至关重要。因此,为视觉认知任务设计良好的多尺度刺激特征至关重要,包括 image classification [33], object detection [53], attention prediction [55], target tracking [76], action recognition [56], semantic segmentation [6], salient object detection [2], [29], object proposal [12], [53], skeleton extraction [80], stereo matching [52], and edge detection [45], [69]。
不出所料,多尺度特征 (multi-scale features) 已广泛用于传统特征设计 [1], [48] 和深度学习 [10], [61]。在视觉任务中获得多尺度表示需要特征提取器使用大范围的感受野来描述不同尺度的目标/部分/上下文。卷积神经网络 (CNN) 通过一堆卷积算子自然地学习从粗到细的多尺度特征。 CNN 的这种固有的多尺度特征提取能力为解决众多视觉任务提供了有效的表示。如何设计更高效的网络架构是进一步提升 CNN 性能的关键。
在过去的几年里,一些骨干网络 (backbone networks),例如,[10], [15], [27], [30], [31], [33], [57], [61], [68], [72],在众多视觉任务中取得了重大进展,并具有一流的性能。早期的架构,如 AlexNet [33] 和 VGGNet [57] 堆叠卷积算子,使得多尺度特征的数据驱动学习变得可行。随后通过使用具有不同卷积核大小的卷积层(例如,InceptionNets [60], [61], [62])、残差模块(例如,ResNet [27])、快捷连接(例如,DenseNet [31])和分层层聚合(例如,DLA [72])。主干 CNN 架构的进步已经证明了朝着更有效和高效的多尺度表示的趋势。
在这项工作中,我们提出了一种简单而有效的多尺度处理方法。与大多数增强 CNN 逐层多尺度表示强度的现有方法不同,我们在更细粒度的级别上提高了多尺度表示能力。与一些通过利用不同分辨率的特征来提高多尺度能力的并行工作[5], [9], [11]不同,我们提出的方法的多尺度是指在更细粒度 (granular) 级别上的多个可用感受野 (multiple available receptive fields)。为了实现这个目标,我们用一组较小的滤波器组替换了 n 个通道的 3×3 滤波器,每个滤波器组有 w 个通道(不失一般性,我们使用 n = s × w)。如图 2 所示,这些较小的滤波器组以分层残差样式连接,以增加输出特征可以表示的尺度数量。具体来说,我们将输入特征图分为几组。一组滤波器首先从一组输入特征图中提取特征。然后将前一组的输出特征与另一组输入特征图一起发送到下一组滤波器。这个过程重复几次,直到处理完所有输入特征图。最后,来自所有组的特征图被连接起来并发送到另一组 1×1 滤波器以完全融合信息。随着输入特征转换为输出特征的任何可能路径,当通过 3×3 滤波器时,等效感受野会增加,由于组合效应导致许多等效特征尺度。
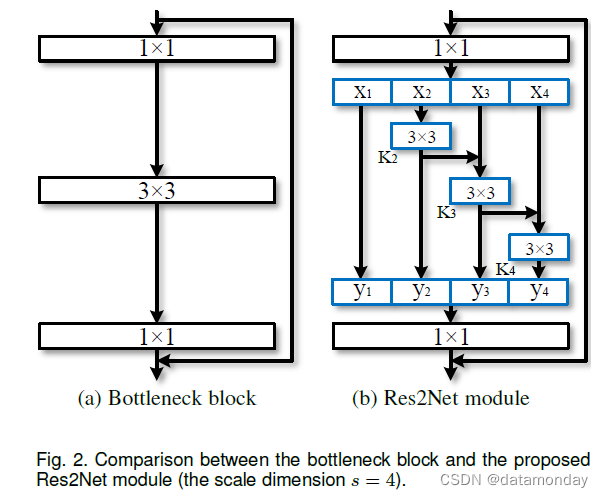
Res2Net 策略探索了一个新维度,即尺度 (scale)(Res2Net 块中特征组的数量),作为现有深度 ( depth) [57]、宽度 (width) 和基数 (cardinality) [68] 维度之外的重要因素。我们在 Sec 4.4 中说明。增加规模比增加其他维度更有效。
请注意,所提出的方法在更细粒度的级别上利用了多尺度潜力,这与利用分层操作的现有方法正交。因此,所提出的构建块,即 Res2Net 模块,可以很容易地插入到许多现有的 CNN 架构中。大量实验结果表明,Res2Net 模块可以进一步提高最先进的 CNN 的性能,例如 ResNet [27]、ResNeXt [68] 和 DLA [72]。
2 RELATED WORK
2.1 Backbone Networks
近年来见证了许多骨干网络 [15], [27], [31], [33], [57], [61], [68], [72],在各种视觉任务中取得了最先进的性能具有更强的多尺度表示。按照设计,CNN 具备基本的多尺度特征表示能力,因为输入信息遵循从细到粗的方式。 AlexNet [33] 按顺序堆叠滤波器,与传统的视觉识别方法相比,获得了显着的性能提升。然而,由于滤波器的网络深度和卷积核大小有限,AlexNet 只有一个相对较小的感受野。 VGGNet [57] 增加了网络深度并使用更小的卷积核大小的滤波器。更深的结构可以扩展感受野,这对于从更大规模中提取特征很有用。通过堆叠更多层来扩大感受野比使用大卷积核更有效。因此,VGGNet 提供了比 AlexNet 更强大的多尺度表示模型,参数更少。但是,AlexNet 和 VGGNet 都是直接堆叠滤波器,这意味着每个特征层都有一个相对固定的感受野。
网络中的网络(NIN)[38]将多层感知器作为微网络插入到大型网络中,以增强模型对感受野内局部补丁的可辨别性。 NIN 中引入的 1×1 卷积一直是融合特征的流行模块。 GoogLeNet [61] 利用具有不同卷积核大小的并行滤波器来增强多尺度表示能力。然而,由于其有限的参数效率,这种能力通常受到计算约束的限制。 Inception Nets [60], [62] 在 GoogLeNet 中并行路径的每个路径中堆叠更多滤波器,以进一步扩展感受野。另一方面,ResNet [27] 引入了与神经网络的短连接,从而缓解了梯度消失问题,同时获得了更深的网络结构。在特征提取过程中,短连接允许卷积算子的不同组合,从而产生大量等效的特征尺度。同样,DenseNet [31] 中的密集连接层使网络能够处理范围非常广泛的目标。 DPN [10] 将 ResNet 与 DenseNet 相结合,实现了 ResNet 的特征重用能力和 DenseNet 的特征探索能力。最近提出的 DLA [72] 方法将层组合成树结构。层次树结构使网络能够获得更强的逐层多尺度表示能力。
2.2 Multi-scale Representations for Vision Tasks
CNN 的多尺度特征表示对许多视觉任务非常重要,包括目标检测 [53]、人脸分析 [4], [51]、边缘检测 [45]、语义分割 [6]、显着目标检测 [ 42], [78] 和骨架检测 [80],提高了这些领域的模型性能。
2.2.1 Object detection.
有效的 CNN 模型需要在场景中定位不同尺度的目标。早期的工作如
- R-CNN [22] 主要依靠骨干网络,即 VGGNet [57] 来提取多尺度的特征。
- He 等人提出了一种 SPP-Net 方法 [26],该方法在骨干网络之后利用空间金字塔池化来增强多尺度能力。
- Faster R-CNN方法[53]进一步提出了区域提出网络来生成各种尺度的边界框。
- 基于 Faster RCNN,FPN [39] 方法引入了特征金字塔从单个图像中提取不同尺度的特征。
- SSD方法[44]利用来自不同阶段的特征图来处理不同尺度的视觉信息。
2.2.2 Semantic segmentation.
提取目标的基本上下文信息需要 CNN 模型来处理各种尺度的特征以进行有效的语义分割。
- [47] 提出了最早的方法之一,该方法可以对全卷积网络 (FCN) 进行多尺度表示以进行语义分割任务。
- 在 DeepLab [6], [7] 引入了级联的空洞卷积模块,以进一步扩展感受野,同时保持空间分辨率。
- 最近,全局上下文信息通过 PSPNet [77] 中的金字塔池化方案从基于区域的特征中聚合。
2.2.3 Salient object detection.
精确定位图像中的显着目标区域需要了解用于确定目标显着性的大规模上下文信息,以及准确定位目标边界的小规模特征[79]。早期的方法
- [3] 利用手工制作的全局对比度表示 [13] 或多尺度区域特征 [64]。
- [34] 提出了一种最早的方法,可以为显着目标检测启用多尺度深度特征。
- 后来,提出了多上下文深度学习[81]和多级卷积特征[75]来改进显着目标检测。
- 最近,[29] 在阶段之间引入密集的短连接,以在每一层提供丰富的多尺度特征图,用于显着目标检测。
2.3 Concurrent Works
最近,有一些并行的工作旨在通过利用多尺度特征 [5], [9], [11], [59] 来提高性能。
-
Big-Little Net [5] 是由具有不同计算复杂度的分支组成的多分支网络。
-
Octave Conv [9] 将标准卷积分解为两种分辨率,以处理不同频率的特征。
-
MSNet [11]利用高分辨率网络通过使用低分辨率网络学习的上采样低分辨率特征来学习高频残差。
-
除了当前工作中的低分辨率表示之外,HRNet [58], [59] 在网络中引入了高分辨率表示,并反复执行多尺度融合以增强高分辨率表示。
-
[5], [9], [11], [58], [59] 中的一个常见操作是它们都使用池化或上采样将特征图调整为原始比例的 2n 倍以节省计算预算同时保持甚至提高性能。
而在 Res2Net 块中,单个残差块模块中的分层残差样连接能够在更细粒度的级别上改变感受野,以捕获细节和全局特征。实验结果表明,Res2Net 模块可以与那些新颖的网络设计集成以进一步提高性能。
3 RES2NET
3.1 Res2Net Module
图 2(a) 所示的瓶颈结构是许多现代主干 CNN 架构的基本构建块,例如 ResNet [27]、ResNeXt [68] 和 DLA [72]。我们不是像在瓶颈块中那样使用一组 3×3 滤波器来提取特征,而是寻求具有更强多尺度特征提取能力的替代架构,同时保持相似的计算负载。具体来说,我们用较小的滤波器组替换一组 3×3 滤波器,同时以分层残差样式连接不同的滤波器组。由于我们提出的神经网络模块涉及单个残差块内的类似残差的连接,我们将其命名为 Res2Net。
图 2 显示了瓶颈块和提出的 Res2Net 模块之间的差异。在 1×1 卷积之后,我们将特征图均匀地分成 s 个特征图子集,记为 xi,其中 i ∈ {1, 2, …, s}。与输入特征图相比,每个特征子集 xi 具有相同的空间大小,但通道数为 1/s。除 x1 外,每个 xi 都有一个对应的 3×3 卷积,记为 Ki()。我们用 yi 表示 Ki() 的输出。特征子集 xi 与 Ki-1() 的输出相加,然后输入 Ki()。为了在增加 s 的同时减少参数,我们省略了 x1 的 3×3 卷积。因此,yi 可以写成:
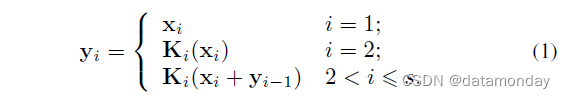
请注意,每个 3 × 3 卷积算子 Ki() 都可能从所有特征拆分 {xj, j ≤ i} 中接收特征信息。每次特征分割 xj 通过一个 3×3 的卷积算子,输出结果可以有比 xj 更大的感受野。由于组合爆炸效应 (combinatorial explosion effect),Res2Net 模块的输出包含不同数量和不同的感受野大小/尺度组合。
在 Res2Net 模块中,splits 以多尺度方式处理,有利于提取全局和局部信息。为了更好地融合不同尺度的信息,我们将所有拆分连接起来并通过 1 × 1 卷积传递它们。拆分和连接策略可以强制卷积更有效地处理特征。为了减少参数的数量,我们省略了第一次分割的卷积,这也可以看作是特征重用的一种形式。
在这项工作中,我们使用 s 作为尺度维度的控制参数。较大的 s 可能允许学习具有更丰富的感受野大小的特征,而连接引入的计算/内存开销可以忽略不计。
3.2 Integration with Modern Modules
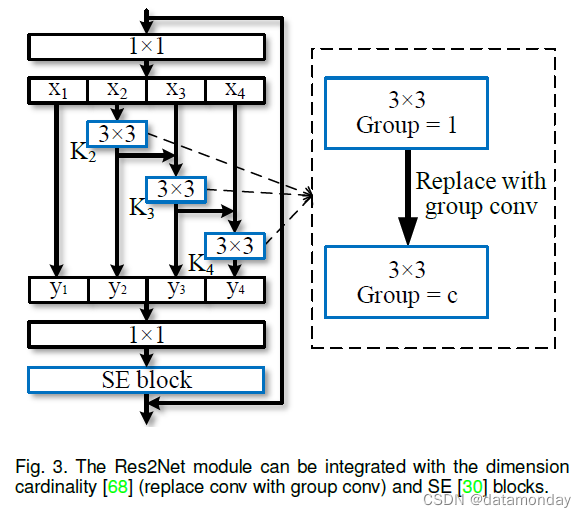
近年来已经提出了许多神经网络模块,包括 Xie 等人 [68]引入的基数维度 (cardinality dimension),以及 Hu 等人[30]提出的挤压和激发 (SE) 块。提出的 Res2Net 模块引入了与这些改进正交的尺度维度。如图 3 所示,我们可以轻松地将基数维度 [68] 和 SE 块 [30] 与建议的 Res2Net 模块集成。
3.2.1 Dimension cardinality
维度基数表示滤波器中的组数[68]。该维度将滤波器从单分支更改为多分支,并提高了 CNN 模型的表示能力。在我们的设计中,可以将 3×3 卷积替换为 3×3 组卷积,其中 c 表示组数。尺度维度和基数之间的实验比较在Sec 4.2 节和 Sec4.4 中给出。
3.2.2 SE block.
SE 块通过显式建模通道之间的相互依赖关系 [30] 来自适应地重新校准通道特征响应。与 [30] 类似,我们在 Res2Net 模块的残差连接之前添加 SE 块。我们的 Res2Net 模块可以从 SE 块的集成中受益,我们已经在 Sec4.2 和 Sec4.3 中进行了实验证明。
3.3 Integrated Models
由于提出的 Res2Net 模块对整体网络结构没有特定要求,并且 Res2Net 模块的多尺度表示能力与 CNN 的逐层特征聚合模型正交,因此我们可以轻松地将提出的 Res2Net 模块集成到SOTA模型,例如 ResNet [27]、ResNeXt [68]、DLA [72] 和 Big-Little Net [5]。相应的模型分别称为 Res2Net、Res2NeXt、Res2Net-DLA 和 bLRes2Net-50。
提出的尺度维度与先前工作的基数 [68] 维度和宽度 [27] 维度正交。因此,在设置比例后,我们调整基数和宽度的值,以保持与对应模型相似的整体模型复杂度。我们不专注于减少这项工作中的模型大小,因为它需要更细致的设计,例如深度可分离卷积 [49]、模型修剪 [23] 和模型压缩 [14]。
对于 ImageNet [54] 数据集的实验,我们主要使用 ResNet-50 [27]、ResNeXt-50 [68]、DLA-60 [72] 和 bLResNet-50 [5] 作为我们的基线模型。所提出模型的复杂度大约等于基线模型的复杂度,其参数数量约为 25M,对于 50 层网络,224 × 224 像素图像的 FLOP 数量约为 4.2G。对于 CIFAR [32] 数据集的实验,我们使用 ResNeXt-29, 8c×64w [68] 作为我们的基线模型。关于模型复杂性的建议模型的经验评估和讨论在 Sec4.4 中介绍。
4 EXPERIMENTS
4.1 Implementation Details
我们使用 Pytorch 框架实现所提出的模型。为了公平比较,我们使用了 ResNet [27]、ResNeXt [68]、DLA [72] 以及 bLResNet50 [5] 的 Pytorch 实现,并且只用建议的 Res2Net 模块替换了原来的瓶颈块。与之前的工作类似,在 ImageNet 数据集 [54] 上,每张图像都是从重新调整大小的图像中随机裁剪的 224×224 像素。我们使用与 [27], [62] 相同的数据论证策略。与 [27] 类似,我们在 4 个 Titan Xp GPU 上使用 SGD 训练网络,权重衰减为 0.0001,动量为 0.9,小批量为 256。学习率最初设置为 0.1,每 30 个 epoch 除以 10。
ImageNet 的所有模型,包括基线模型和提出模型,都使用相同的训练和数据论证策略进行了 100 个 epoch 的训练。为了测试,我们使用与 [27] 相同的图像裁剪方法。在 CIFAR 数据集上,我们使用 ResNeXt-29 [68] 的实现。对于所有任务,我们使用基线的原始实现,并且只用建议的 Res2Net 替换主干模型。
4.2 ImageNet
我们在 ImageNet 数据集 [54] 上进行了实验,该数据集包含来自 1000 个类别的 128 万张训练图像和 5 万张验证图像。我们构建了具有大约 50 层的模型,用于针对最先进的方法进行性能评估。在 CIFAR 数据集上进行了更多的消融研究。
4.2.1 Performance gain.
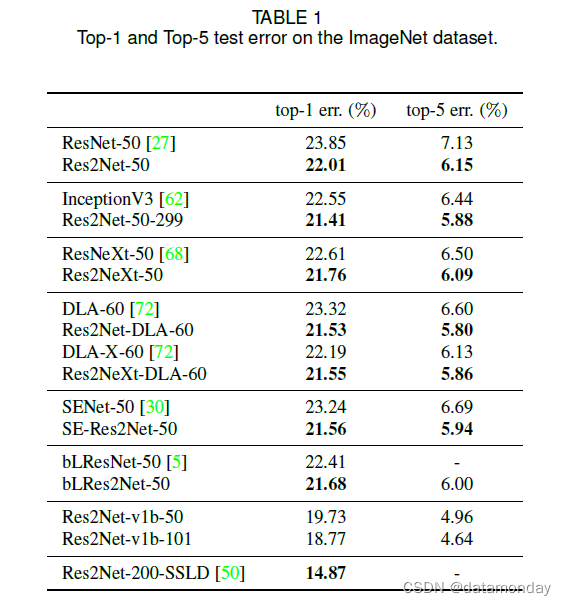
表 1 显示了 ImageNet 数据集上的 top-1 和 top-5 测试错误。为简单起见,表 1 中的所有 Res2Net 模型的尺度 s = 4。与 ResNet-50 相比,Res2Net-50 的 top-1 误差提高了 1.84%。 Res2NeXt-50 在 top-1 误差方面比 ResNeXt50 提高了 0.85%。此外,Res2Net-DLA-60 在 top-1 错误方面比 DLA-60 高 1.27%。在 top-1 错误方面,Res2NeXt-DLA-60 比 DLA-X-60 高 0.64%。 SE-Res2Net-50 比 SENet50 提升了 1.68%。 bLRes2Net-50 在 top-1 error 方面比 bLResNet-50 提高了 0.73%。 Res2Net 模块在粒度级别上进一步增强了 bLResNet 的多尺度能力,即使 bLResNet 旨在利用不同尺度的特征,如第 2.3 节中讨论的那样。请注意,ResNet [27]、ResNeXt [68]、SE-Net [30]、bLResNet [5] 和 DLA [72] 是最先进的 CNN 模型。与这些强大的基线相比,与 Res2Net 模块集成的模型仍然具有一致的性能增益。
我们还将我们的方法与 InceptionV3 [62] 模型进行了比较,该模型使用具有不同卷积核组合的并行滤波器。为了公平比较,我们使用 ResNet-50 [27] 作为基线模型,并使用 InceptionV3 模型中使用的输入图像大小为 299×299 像素来训练我们的模型。提出的 Res2Net-50-299 在 top-1 错误上比 InceptionV3 高 1.14%。我们得出结论,在处理多尺度信息时,Res2Net 模块的分层残差连接比 InceptionV3 的并行滤波器更有效。虽然 InceptionV3 中滤波器的组合模式是专门设计的,但 Res2Net 模块提供了一种简单但有效的组合模式。
4.2.2 Going deeper with Res2Net.

更深的网络已被证明具有更强的视觉任务表示能力[27], [68]。为了更深入地验证我们的模型,我们比较了 Res2Net 和 ResNet 的分类性能,两者都有 101 层。如表 2 所示,与 ResNet-101 相比,Res2Net-101 在 top-1 错误方面实现了 1.82% 的显着性能提升。请注意,与 ResNet-50 相比,Res2Net-50 的 top-1 error 性能提升了 1.84%。这些结果表明,所提出的具有额外维度尺度的模块可以与更深层次的模型集成以实现更好的性能。我们还将我们的方法与 DenseNet [31] 进行了比较。与官方提供的 DenseNet 系列中性能最好的模型 DenseNet-161 相比,Res2Net-101 在 top-1 error 方面有 1.54% 的提升。
4.2.3 Effectiveness of scale dimension.
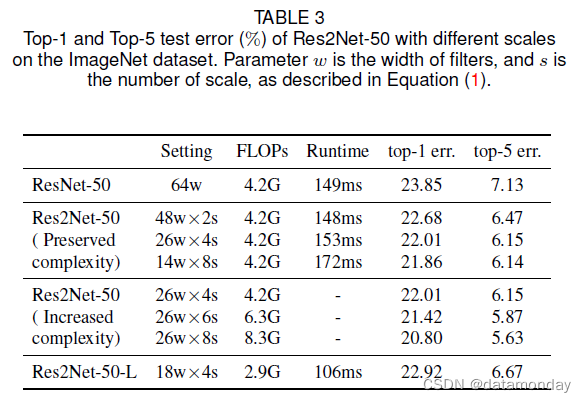
为了验证我们提出的维度尺度,我们通过实验分析了不同尺度的影响。如表 3 所示,性能随着规模的增加而增加。随着规模的增加,14w×8s 的 Res2Net-50 在 top-1 error 方面比 ResNet-50 实现了 1.99% 的性能提升。请注意,在保留复杂度的情况下,Ki() 的宽度随着尺度的增加而减小。我们进一步评估随着模型复杂性增加而增加规模的性能增益。与 ResNet-50 相比,具有 26w×8s 的 Res2Net-50 在 top-1 错误方面实现了显着的性能提升,达到了 3.05%。具有 18w×4s 的 Res2Net-50 在 top-1 错误方面也比 ResNet-50 高 0.93%,只有 69% 的 FLOPs。表 3 显示了不同尺度下的 Runtime,即推断大小为 224 × 224 的 ImageNet 验证集的平均时间。虽然由于分层连接,需要按顺序计算特征拆分 {yi},但额外的运行时间Res2Net 模块引入的内容通常可以忽略。由于 GPU 中可用张量的数量有限,对于 Res2Net 的典型设置,即 s = 4,通常在单个 GPU 时钟周期内有足够的并行计算。
4.2.4 Stronger representation with ResNet.
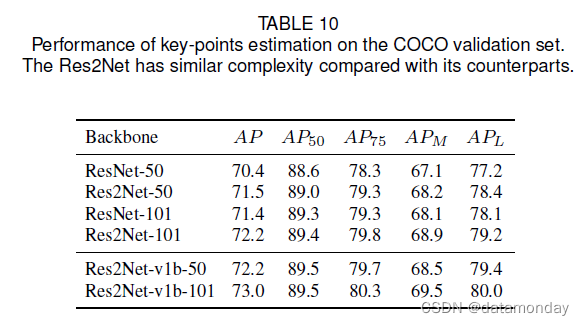
为了进一步探索 Res2Net 的多尺度表示能力,我们按照 ResNet v1d [28] 对 Res2Net 进行修改,并使用数据增强技术即 CutMix [73] 训练模型。 Res2Net 的修改版本,即 Res2Net v1b,大大提高了 ImageNet 上的分类性能,如表 1 所示。Res2Net v1b 进一步提高了模型在下游任务上的性能。我们分别在表 5、表 8 和表 10 中展示了 Res2Net v1b 在目标检测、实例分割、关键点估计方面的性能。
Res2Net 更强的多尺度表示已在许多下游任务上得到验证,即矢量化道路提取 [63]、目标检测 [35]、弱监督语义分割 [46]、显着目标检测 [21]、交互式图像分割 [41] ]、视频识别[37]、隐藏目标检测[18]和医学分割[19], [20], [66]。半监督知识蒸馏解决方案 [50] 也可以应用于 Res2Net,在 ImageNet 上达到 85.13% top.1 准确率。
4.3 CIFAR
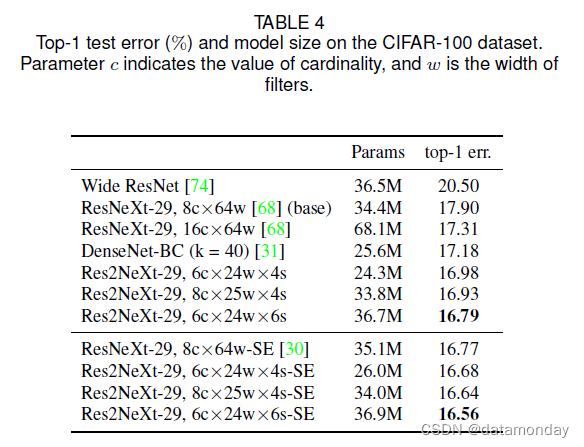
我们还在 CIFAR-100 数据集 [32] 上进行了一些实验,其中包含来自 100 个类别的 50k 个训练图像和 10k 个测试图像。 ResNeXt-29, 8c×64w [68] 被用作基线模型。我们只用我们提出的 Res2Net 模块替换原来的基本块,同时保持其他配置不变。表 4 显示了 CIFAR-100 数据集上的 top-1 测试错误和模型大小。实验结果表明,我们的方法以更少的参数超越了基线和其他方法。我们提出的 Res2NeXt-29, 6c×24w×6s 比基线高出 1.11%。 Res2NeXt29, 6c×24w×4s 甚至超过了 ResNeXt-29, 16c×64w,只有 35% 的参数。与 DenseNet-BC (k = 40) 相比,我们还以更少的参数实现了更好的性能。与Res2NeXt-29、6c×24w×4s相比,Res2NeXt29、8c×25w×4s取得了更好的结果,宽度和基数更大,说明维度尺度与维度宽度和基数正交。我们还将最近提出的 SE 块集成到我们的结构中。使用更少的参数,我们的方法仍然优于 ResNeXt-29, 8c×64w-SE 基线。
4.4 Scale Variation
类似于谢等人[68],我们通过增加不同的 CNN 维度来评估基线模型的测试性能,包括尺度(等式(1))、基数 [68] 和深度 [57]。在使用一个维度增加模型容量的同时,我们修复了所有其他维度。在这些变化下训练和评估了一系列网络。由于 [68] 已经表明增加基数比增加宽度更有效,我们只将提出的维度尺度与基数和深度进行比较。
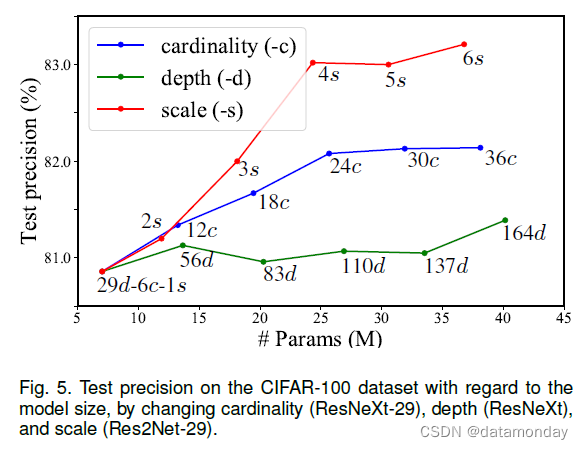
图 5 显示了 CIFAR-100 数据集上关于模型大小的测试精度。基线模型的深度、基数和规模分别为 29、6 和 1。实验结果表明,规模是提高模型性能的有效维度,这与我们在 Sec. 中的 ImageNet 数据集上观察到的一致。 4.2.此外,增加规模比其他维度更有效,从而更快地提高性能。如等式(1)和图 2 所述,对于尺度 s = 2 的情况,我们仅通过添加更多 1×1 滤波器的参数来增加模型容量。因此,s = 2 的模型性能比增加基数的模型性能稍差。对于 s = 3、4,我们的分层残差结构的组合效应产生了一组丰富的等效尺度,从而显着提高了性能。然而,尺度为 5 和 6 的模型性能提升有限,我们假设 CIFAR 数据集中的图像太小(32×32)而不能有很多尺度。
4.5 Class Activation Mapping
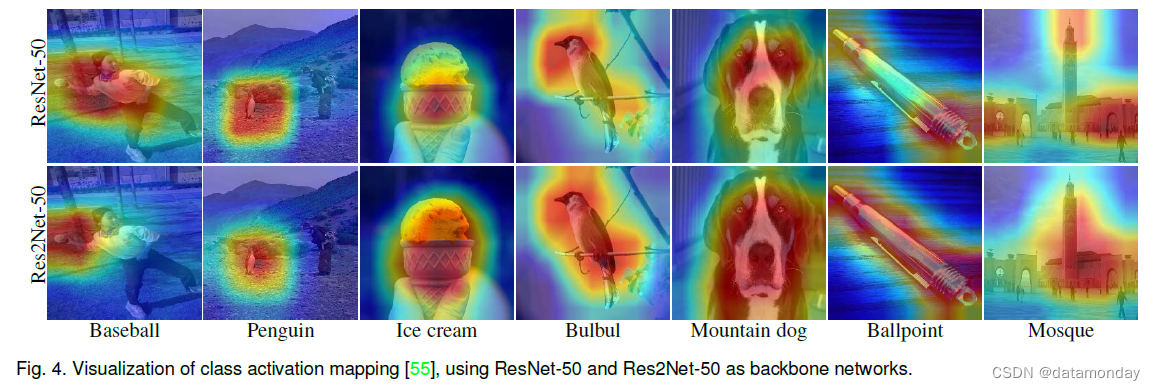
为了理解 Res2Net 的多尺度能力,我们使用 Grad-CAM [55] 可视化类激活映射 (CAM),这通常用于定位图像分类的判别区域。在图 4 所示的可视化示例中,较强的 CAM 区域被较浅的颜色覆盖。与 ResNet 相比,基于 Res2Net 的 CAM 结果在“棒球”和“企鹅”等小物体上具有更集中的激活图。两种方法在中等大小的物体上都有相似的激活图,比如“冰淇淋”。由于更强的多尺度能力,Res2Net 的激活图倾向于覆盖“bulbul”、“mountain dog”、“ballpoint”和“mosque”等大物体上的整个目标,而 ResNet 的激活图仅覆盖目标的部分。这种精确定位 CAM 区域的能力使得 Res2Net 对于弱监督语义分割任务中的目标区域挖掘具有潜在的价值 [65]。
4.6 Object Detection
对于目标检测任务,我们使用 Faster RCNN [53] 作为基线方法,在 PASCAL VOC07 [17] 和 MS COCO [40] 数据集上验证 Res2Net。我们使用 ResNet-50 与 Res2Net-50 的骨干网络,并遵循 [53] 的所有其他实现细节进行公平比较。表 5 显示了目标检测结果。在 PASCAL VOC07 数据集上,基于 Res2Net-50 的模型在平均精度 (AP) 上优于其对应模型 2.3%。在 COCO 数据集上,基于 Res2Net50 的模型在 AP 上的表现优于其对应模型 2.6%,在 AP@IoU=0.5 上优于 2.2%。

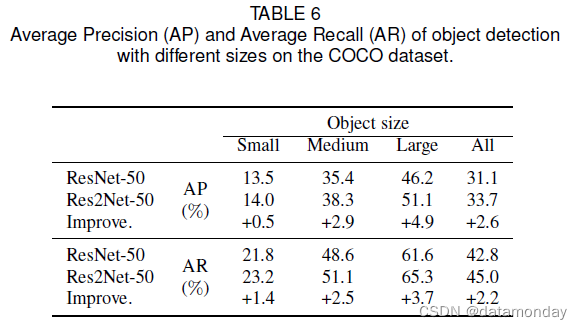
我们进一步测试了不同大小目标的 AP 和平均召回 (AR) 分数,如表 6 所示。根据 [40],目标根据大小分为三类。基于 Res2Net 的模型在小、中、大目标的 AP 上分别比同类模型有 0.5%、2.9% 和 4.9% 的大幅改进。 AR 对小型、中型和大型物体的改进分别为 1.4%、2.5% 和 3.7%。由于强大的多尺度能力,基于 Res2Net 的模型可以覆盖大范围的感受野,提升不同尺寸目标的性能。
4.7 Semantic Segmentation
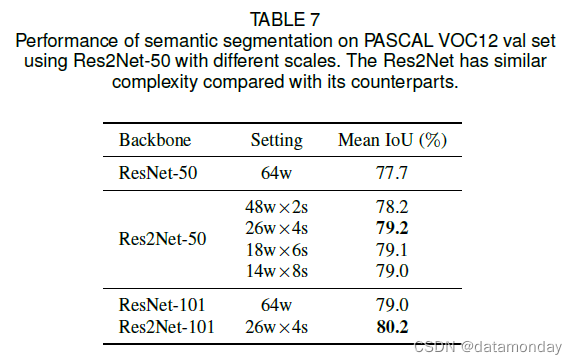
语义分割需要 CNN 强大的多尺度能力来提取目标的基本上下文信息。因此,我们使用 PASCAL VOC12 数据集 [16] 评估 Res2Net 在语义分割任务上的多尺度能力。我们按照之前的工作使用增强的 PASCAL VOC12 数据集 [24],其中包含 10582 个训练图像和 1449 个验证图像。我们使用 Deeplab v3+ [8] 作为我们的分割方法。除了用 ResNet 和我们提出的 Res2Net 替换主干网络之外,所有实现与 Deeplab v3+ [8] 保持一致。训练和评估中使用的输出步幅均为 16。如表 7 所示,基于 Res2Net-50 的方法在平均 IoU 上优于其对应方法 1.5%。并且基于 Res2Net-101 的方法在平均 IoU 上的表现优于其对应方法 1.2%。图 6 说明了具有挑战性的示例的语义分割结果的视觉比较。基于 Res2Net 的方法倾向于分割目标的所有部分,而不管目标大小。

4.8 Instance Segmentation
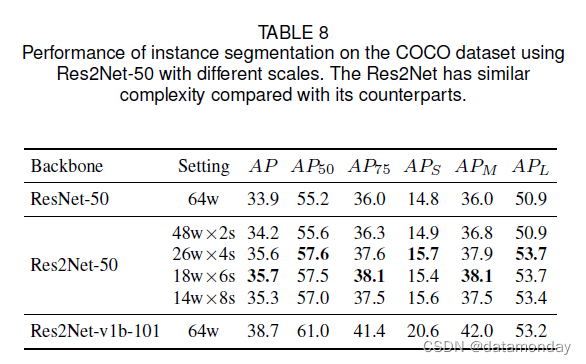
实例分割是目标检测和语义分割的结合。它不仅需要正确检测图像中各种大小的目标,还需要对每个目标进行精确分割。如第4.6节和第4.7节所述 ,目标检测和语义分割都需要CNNs强大的多尺度能力。因此,多尺度表示非常有利于实例分割。我们使用 Mask R-CNN [25] 作为实例分割方法,并将 ResNet-50 的主干网络替换为我们提出的 Res2Net-50。 MS COCO [40] 数据集上实例分割的性能如表 8 所示。基于 Res2Net-26w×4s 的方法在 AP 上的性能比同类方法高 1.7%,在 AP50 上高 2.4%。还展示了不同大小目标的性能提升。小、中、大物体的 AP 提升分别为 0.9%、1.9% 和 2.8%。表 8 还显示了 Res2Net 在相同复杂度下不同尺度下的性能比较。随着规模的扩大,性能总体呈上升趋势。请注意,与 Res2Net-50-48w×2s 相比,Res2Net-50-26w×4s 在 APL 上提高了 2.8%,而 Res2Net-50-48w×2s 与 ResNet-50 相比具有相同的 APL。我们假设大型物体的性能提升得益于额外的尺度。当规模相对较大时,性能增益并不明显。 Res2Net 模块能够学习合适范围的感受野。当图像中目标的规模已经被 Res2Net 模块中的可用感受野覆盖时,性能增益是有限的。在固定复杂度的情况下,增加的规模会导致每个感受野的通道减少,这可能会降低处理特定规模特征的能力。
4.9 Salient Object Detection
诸如显着目标检测之类的像素级任务也需要 CNN 强大的多尺度能力来定位整体目标及其区域细节。在这里,我们使用最新的方法 DSS [29] 作为我们的基线。为了公平比较,我们只用 ResNet-50 和我们提出的 Res2Net-50 替换主干,同时保持其他配置不变。
在 [29] 之后,我们使用 MSRA-B 数据集 [43] 训练这两个模型,并在 ECSSD [70]、PASCALS [36]、HKU-IS [34] 和 DUT-OMRON [71] 数据集上评估结果。 F-measure 和平均绝对误差 (MAE) 用于评估。如表 9 所示,基于 Res2Net 的模型与所有数据集上的对应模型相比都有一致的改进。在 DUT-OMRON 数据集(包含 5168 张图像)上,与基于 ResNet 的模型相比,基于 Res2Net 的模型在 F-measure 上提高了 5.2%,在 MAE 上提高了 2.1%。基于 Res2Net 的方法在 DUT-OMRON 数据集上实现了最大的性能提升,因为与其他三个数据集相比,该数据集包含最显着的目标大小变化。图 7 显示了具有挑战性示例的显着目标检测结果的一些视觉比较。

4.10 Key-points Estimation
人体部位大小不一,这就需要关键点估计方法来定位不同尺度的人体关键点。为了验证 Res2Net 的多尺度表示能力是否有利于关键点估计任务,我们使用 SimpleBaseline [67] 作为关键点估计方法,并且只用提出的 Res2Net 替换主干。包括训练和测试策略在内的所有实现都与 SimpleBaseline [67] 保持一致。我们使用 COCO 关键点检测数据集 [40] 训练模型,并使用 COCO 验证集评估模型。按照通用设置,我们在 SimpleBaseline [67] 中使用相同的人员检测器进行评估。表 10 显示了使用 Res2Net 在 COCO 验证集上进行关键点估计的性能。基于 Res2Net-50 和 Res2Net-101 的模型在 AP 上的性能分别优于基线 3.3% 和 3.0%。此外,与基线相比,基于 Res2Net 的模型在不同尺度的人类身上具有可观的性能提升。
5 CONCLUSION AND FUTURE WORK
我们提出了一个简单而有效的模块,即 Res2Net,以进一步探索 CNN 在更细粒度级别上的多尺度能力。 Res2Net 暴露了一个新的维度,即“规模”,这是除了现有的深度、宽度和基数维度之外的一个重要且更有效的因素。我们的 Res2Net 模块可以毫不费力地与现有的最先进方法集成。 CIFAR-100 和 ImageNet 基准的图像分类结果表明,我们的新骨干网络始终优于其最先进的竞争对手,包括 ResNet、ResNeXt、DLA 等。
尽管已证明所提出的骨干模型的优越性在几个具有代表性的计算机视觉任务的背景下,包括类激活映射、目标检测和显着目标检测,我们相信多尺度表示对于更广泛的应用领域是必不可少的。为了鼓励未来的工作利用 Res2Net 强大的多尺度能力,源代码可在 https://mmcheng.net/res2net/ 上获得。