持续更新中…
前言
本文主要写一些程序代码相关的部分,注重coding实践,不会涉及太多理论分析
k-Nearest Neighbor
Nearest Neighbor
1,数据的读取
以CIFAR10的图像数据为例,在官网cifar10下载python部分的图像数据集。
读取cifar10的数据:
根据官网给的程序:
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
data = unpickle(r'F:/course/computer_vision/cifar_10/data_batch_1') #加载一个batch的数据
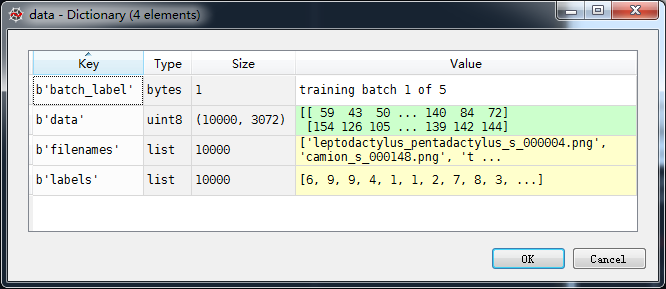
可以看到’data’是100003072,这里数据已经被从332*32展开为3072储存。使用cs231n给的代码:
from __future__ import print_function
from builtins import range
from six.moves import cPickle as pickle
import numpy as np
import os
from scipy.misc import imread
import platform
def load_pickle(f):
#使用platform获取python版本,如果使用的是platform.python_version()则结果为'3.6.5',是str
#如果使用platform.python_version_tuple()则得到的是元组('3','6','5')
version = platform.python_version_tuple()
if version[0] == '2':
return pickle.load(f)
elif version[0] == '3':
return pickle.load(f, encoding='latin1')
raise ValueError("invalid python version: {}".format(version))
def load_CIFAR_batch(filename):
""" load single batch of cifar """
with open(filename, 'rb') as f: #以二进制格式打开一个文件用于只读
datadict = load_pickle(f)
X = datadict['data']
Y = datadict['labels']
#原本得到的data是10000*3072,现在分成10000行(即10000样本),3层,每层是32*32
#transpose之后是转置,相当于坐标轴交换,即转置后变成了(10000,32,32,3)
#transpose在这里是将第二个坐标轴,即1调到了最后,所以对应的3调到32之后
X = X.reshape(10000, 3, 32, 32).transpose(0,2,3,1).astype("float")
Y = np.array(Y)
#返回的X是10000*32*32*3,Y是10000
return X, Y
def load_CIFAR10(ROOT):
""" load all of cifar """
xs = []
ys = []
for b in range(1,6):
#将路径连在一起,可以只用%b,不用括号
f = os.path.join(ROOT, 'data_batch_%d' % (b, ))
X, Y = load_CIFAR_batch(f)
xs.append(X)
ys.append(Y)
# 按行将数据放一块
Xtr = np.concatenate(xs)
Ytr = np.concatenate(ys)
# 将X,Y变量删除,释放空间
del X, Y
Xte, Yte = load_CIFAR_batch(os.path.join(ROOT, 'test_batch'))
return Xtr, Ytr, Xte, Yte
Xtr,Ytr,Xte,Yte = load_CIFAR10(r'F:/course/computer_vision/cifar_10')
上面的os.path.join是将路径相连接,比如b=1,则有:

上面程序进行一遍,如当b=4,则有
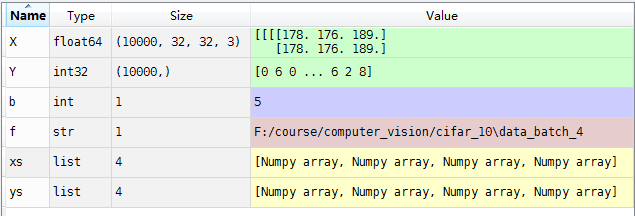
表示将4个batches加在了一块,xs中每个Numpy array就是上面的X,100003232*3.继续运行,到Xtr,Ytr,有
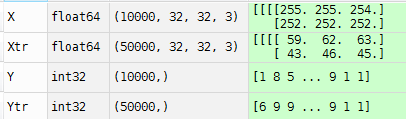
concatenate函数见concatenate,在这里的作用是将5个10000变成了5行,并且将数据从list变成array。
预测实现
完整的NN分类代码如下:
from __future__ import print_function
from builtins import range
from six.moves import cPickle as pickle
import numpy as np
import os
from scipy.misc import imread
import platform
class NearestNeighbor(object):
def __init__(self):
pass
def train(self, X, y):
""" X is N x D where each row is an example. Y is 1-dimension of size N """
# the nearest neighbor classifier simply remembers all the training data
self.Xtr = X
self.ytr = y
def predict(self, X):
""" X is N x D where each row is an example we wish to predict label for """
num_test = X.shape[0]
# lets make sure that the output type matches the input type
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
# loop over all test rows
for i in range(num_test):
# find the nearest training image to the i'th test image
# using the L1 distance (sum of absolute value differences)
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)
min_index = np.argmin(distances) # get the index with smallest distance
Ypred[i] = self.ytr[min_index] # predict the label of the nearest example
return Ypred
def load_pickle(f):
#使用platform获取python版本,如果使用的是platform.python_version()则结果为'3.6.5',是str
#如果使用platform.python_version_tuple()则得到的是元组('3','6','5')
version = platform.python_version_tuple()
if version[0] == '2':
return pickle.load(f)
elif version[0] == '3':
return pickle.load(f, encoding='latin1')
raise ValueError("invalid python version: {}".format(version))
def load_CIFAR_batch(filename):
""" load single batch of cifar """
with open(filename, 'rb') as f: #以二进制格式打开一个文件用于只读
datadict = load_pickle(f)
X = datadict['data']
Y = datadict['labels']
#原本得到的data是10000*3072,现在分成10000行(即10000样本),3层,每层是32*32
#transpose之后是转置,相当于坐标轴交换,即转置后变成了(10000,32,32,3)
#transpose在这里是将第二个坐标轴,即1调到了最后,所以对应的3调到32之后
X = X.reshape(10000, 3, 32, 32).transpose(0,2,3,1).astype("float")
Y = np.array(Y)
return X, Y
def load_CIFAR10(ROOT):
""" load all of cifar """
xs = []
ys = []
for b in range(1,6):
f = os.path.join(ROOT, 'data_batch_%d' % (b, ))
X, Y = load_CIFAR_batch(f)
xs.append(X)
ys.append(Y)
Xtr = np.concatenate(xs)
Ytr = np.concatenate(ys)
del X, Y
Xte, Yte = load_CIFAR_batch(os.path.join(ROOT, 'test_batch'))
return Xtr, Ytr, Xte, Yte
Xtr,Ytr,Xte,Yte = load_CIFAR10(r'F:/course/computer_vision/cifar_10')
Xtr_rows = Xtr.reshape(Xtr.shape[0], 32*32*3)
Xte_rows = Xte.reshape(Xte.shape[0], 32*32*3)
nn = NearestNeighbor()
nn.train(Xtr_rows,Ytr)
Yte_predict = nn.predict(Xte_rows)
print('accuracy: %f'%(np.mean(Yte_predict==Yte)))
由于没有训练(因为直接就是数据存储),但有测试(要每个对比,非常慢),使得过程非常慢,最后结果大概是38.6%,比随机猜好(随机猜是1/10)