使用CV-CUDA提高基于计算机视觉的任务吞吐量

涉及基于 AI 的计算机视觉的实时云规模应用程序正在迅速增长。 用例包括图像理解、内容创建、内容审核、映射、推荐系统和视频会议。
然而,由于对处理复杂性的需求增加,这些工作负载的计算成本也在增长。 从静止图像到视频的转变现在也正在成为消费者互联网流量的主要组成部分。 鉴于这些趋势,迫切需要构建高性能但具有成本效益的计算机视觉工作负载。
基于 AI 的计算机视觉流程通常涉及围绕 AI 推理模型的数据预处理和后处理步骤,这可能占整个工作负载的 50-80%。 这些步骤中的常用运算符包括:
- 调整大小
- 裁剪
- 归一化
- 降噪
- 张量转换
虽然开发人员可能会使用 NVIDIA GPU 来显着加速其流程中的 AI 模型推理,但预处理和后处理仍然通常使用基于 CPU 的库来实现。 这导致整个 AI 流程的性能出现瓶颈。 通常作为 AI 图像或视频处理流程一部分的解码和编码过程也可能在 CPU 上成为瓶颈,从而影响整体性能。

CV-CUDA优化
CV-CUDA 是一个开源库,可让您构建高效的云级 AI 计算机视觉流程。 该库提供一组专门的 GPU 加速计算机视觉和图像处理内核作为独立运算符,以轻松实现 AI 流程的高效预处理和后处理步骤。
CV-CUDA 可用于各种常见的计算机视觉流程,例如图像分类、对象检测、分割和图像生成。 如需了解更多信息,请参阅 NVIDIA GTC 2022 秋季主题演讲。
在这篇博文中,我们展示了使用 CV-CUDA 为典型的 AI 计算机视觉工作负载启用端到端 GPU 加速的好处,可实现约 5 倍至高达 50 倍的整体吞吐量加速。 这可以导致每年节省数亿美元的云成本,并在数据中心每年节省数百 GWh 的能源消耗。
GPU 加速解决了 CPU 瓶颈
CV-CUDA 提供高度优化的 GPU 加速内核作为计算机视觉处理的独立运算符。 这些内核可以有效地实现预处理和后处理流程,从而显着提高吞吐量。
编码和解码操作也可能是流程中的潜在瓶颈。 借助优化的 NVIDIA 视频处理框架 (VPF),您还可以高效地优化和运行它们。 VPF 是 NVIDIA 的一个开源库,具有与 C++ 库的 Python 绑定。 它为 GPU 上的视频解码和编码提供完整的硬件加速。omniverse
要加速 GPU 上的整个端到端 AI 流程,请使用 CV-CUDA,以及用于解码/编码加速的 VPF 和用于进一步推理优化的 TensorRT。 与典型流程中基于 CPU 的实施相比,您可以使用四个 NVIDIA L4 GPU 实现高达 50 倍的端到端吞吐量改进。
改进程度取决于推理 DNN 的复杂性、所需的预处理和后处理步骤以及硬件等因素。 对于多 GPU 节点,您可以期望加速因子针对给定流程线性扩展。
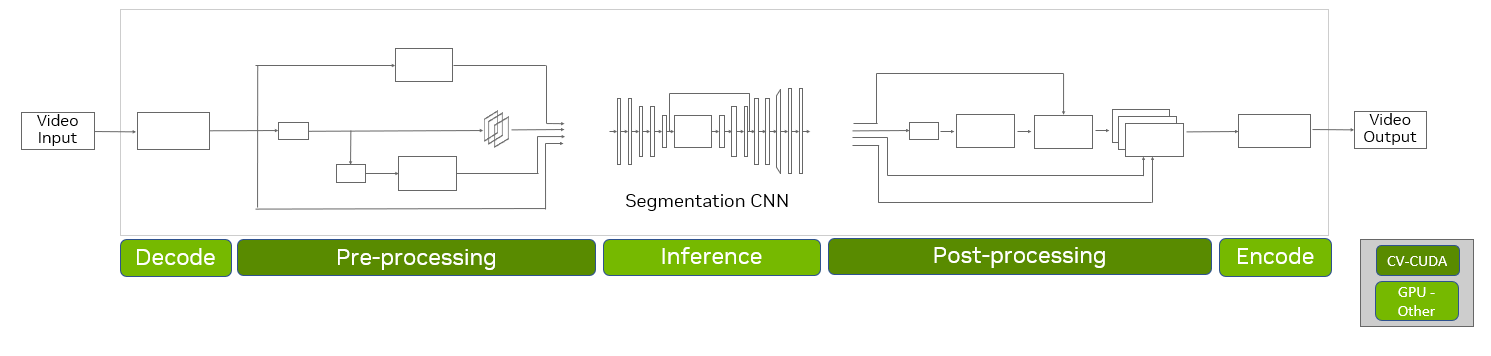
CV-CUDA如何实现高性能
CV-CUDA 利用 GPU 的强大功能来实现高性能:
- 预分配内存池,避免在推理阶段重复分配 GPU 内存
- 异步操作
- 内核融合——使用一个 GPU 内核实现运算符组合,以最大限度地减少不必要的数据传输和内核启动延迟
- 通过向量化全局内存访问和使用快速共享内存来提高内存访问效率
- 计算效率、快速数学、扭曲减少/块减少
案例研究:视频分割流程的端到端加速
基于视频的分割是一种常见的 AI 技术,它根据属性对视频帧中的像素进行分割。 例如,在视频会议中的虚拟背景或背景模糊应用中,它将前景人物或物体与背景分割开来。
在本研究中,我们讨论了使用 AWS 上的 NVIDIA T4 Tensor Core GPU 实例部署在云中的 AI 视频分割流程的性能评估,特别关注计算成本优化。 连接到实例的 CPU 是 Intel Xeon Platinum 8362。
当整个端到端 AI 流程在 GPU 上执行时,您可以预期显着节省成本。 然后,我们讨论相同工作负载的这种吞吐量性能加速对数据中心能耗的影响。
为了进行实验,我们将带有 CV-CUDA AI 流程的 GPU 与带有相同流程的 OpenCV 实现的 CPU 进行了比较,假设两种情况下的推理工作负载都在 GPU 上运行。 具体来说,我们部署了 ResNet-101 视频分割模型流程,以执行 AI 背景模糊。

在这种情况下,我们测量了整个端到端流程中不同阶段的延迟和最大吞吐量。 流程包含多个阶段:
- 视频解码
- 使用 Downscale、Normalize 和 Reformat 等操作进行预处理
- 使用 PyTorch 进行推理
- 使用 Reformat、Upscale、BilateralFilter、Composition 和 Blur 等操作进行后处理
- 视频编码
对于 CPU 和 GPU 流程,我们假设推理工作负载分别使用 PyTorch 和 TensorRT 在 GPU 上运行。
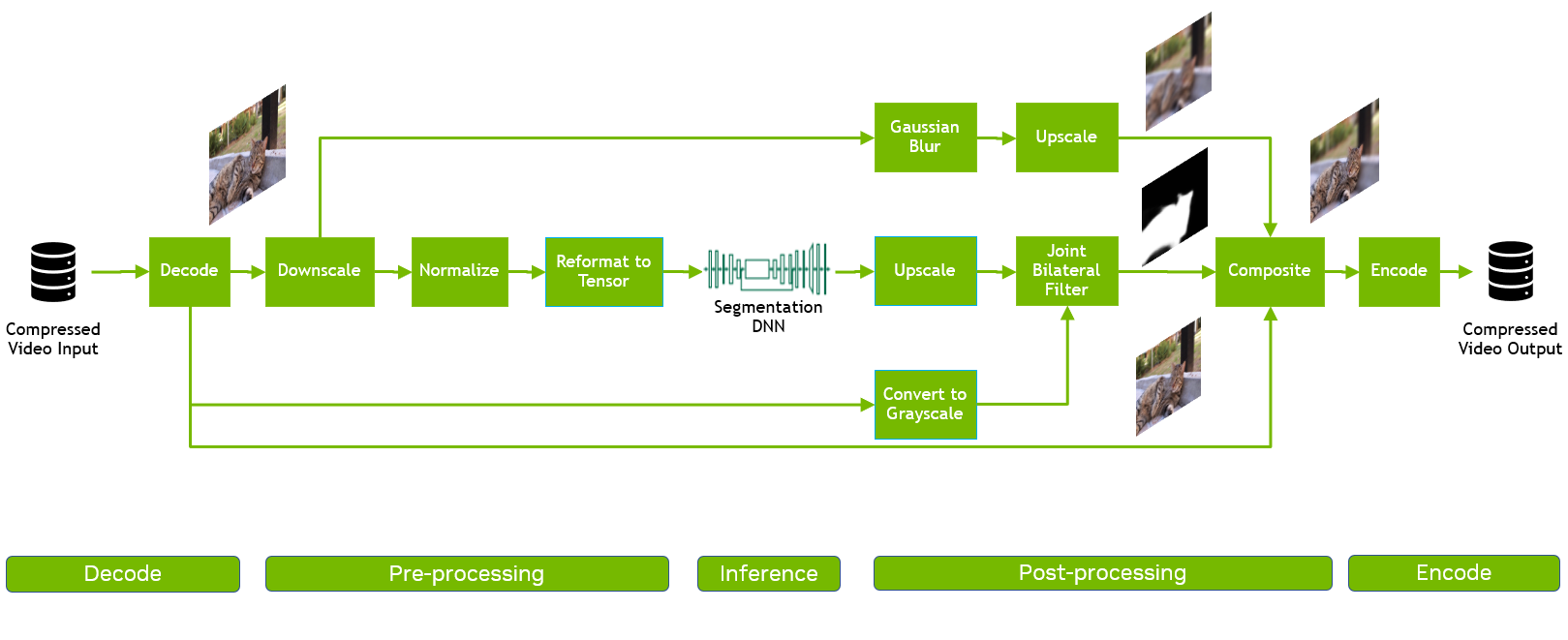
传统的流程是用 OpenCV 和 PyTorch (GPU) 构建的,用 Python 实现,因为这是客户的典型模式。 输入视频的分辨率为 1080p,由 474 帧组成,批量大小为 1。在此流程中,由于 PyTorch,GPU 仅用于推理,而其余过程是基于 CPU 的:
- 这些帧使用 OpenCV/ffmpeg 解码。
- 解码后的图像使用 OpenCV 进行预处理,并送入 PyTorch 支持的 DNN 以检测哪些像素属于猫,生成掩码。
- 在后处理阶段,将前一阶段的输出掩码与原始图像及其模糊版本合成,导致前景中的猫和背景模糊。
对于基于 GPU 的流程,我们使用来自 CV-CUDA 库的优化运算符实现了预处理和后处理阶段,并使用 NVIDIA TensorRT 库进行了推理。 我们还使用 VPF 在 GPU 上加速了流程的解码和编码部分。
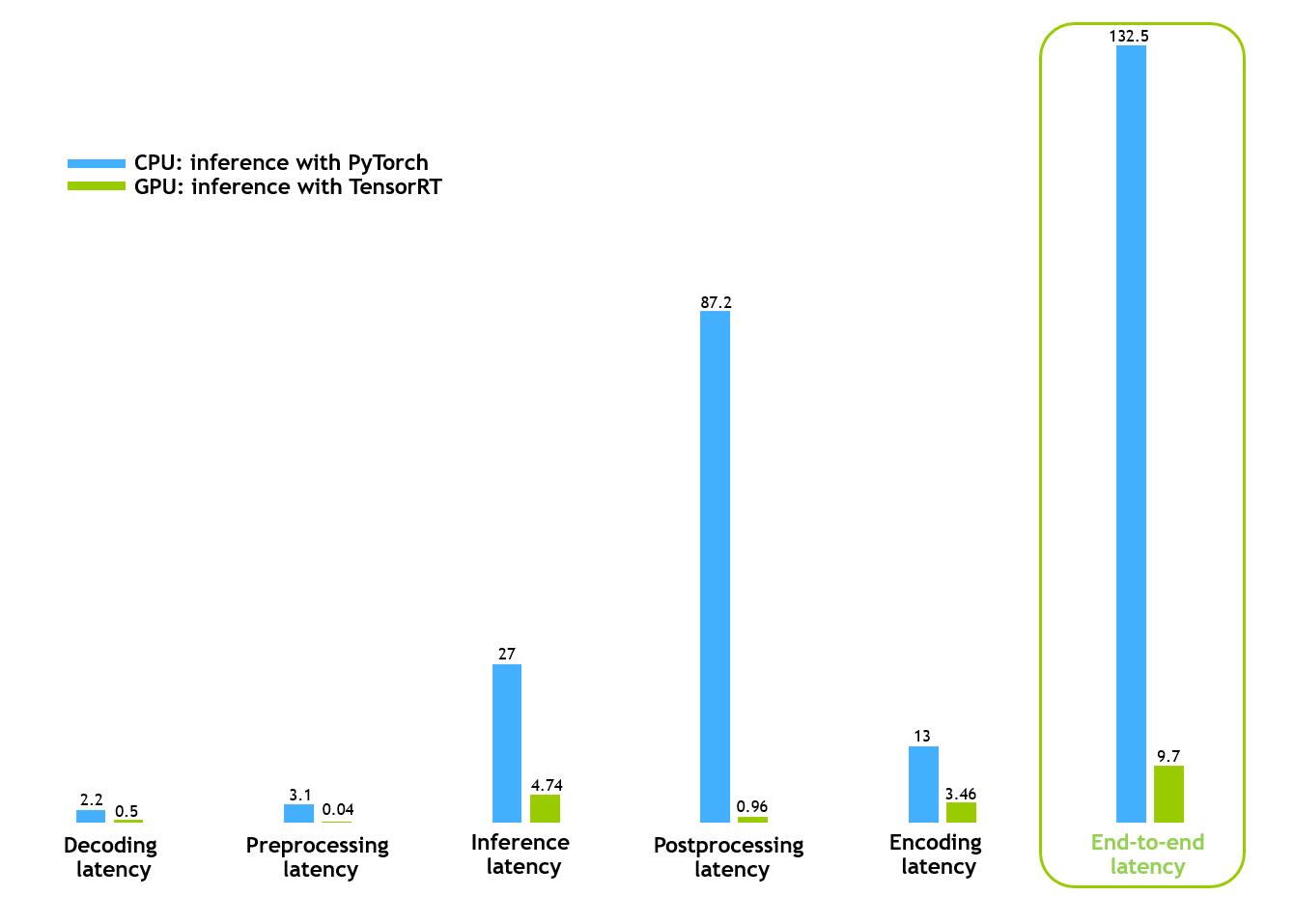
上图显示,单帧批处理的端到端时间从 132 毫秒减少到大约 10 毫秒,这表明 GPU 流程实现了令人印象深刻的延迟减少。 通过使用单个 NVIDIA T4 GPU,CV-CUDA 流水线比 CPU 流水线快约 13 倍。
此结果是针对处理单个视频的单个进程获得的。 通过部署多个进程来同时处理多个视频,这些优化可以使用相同的硬件实现更高的吞吐量,从而显着节省成本和能源。
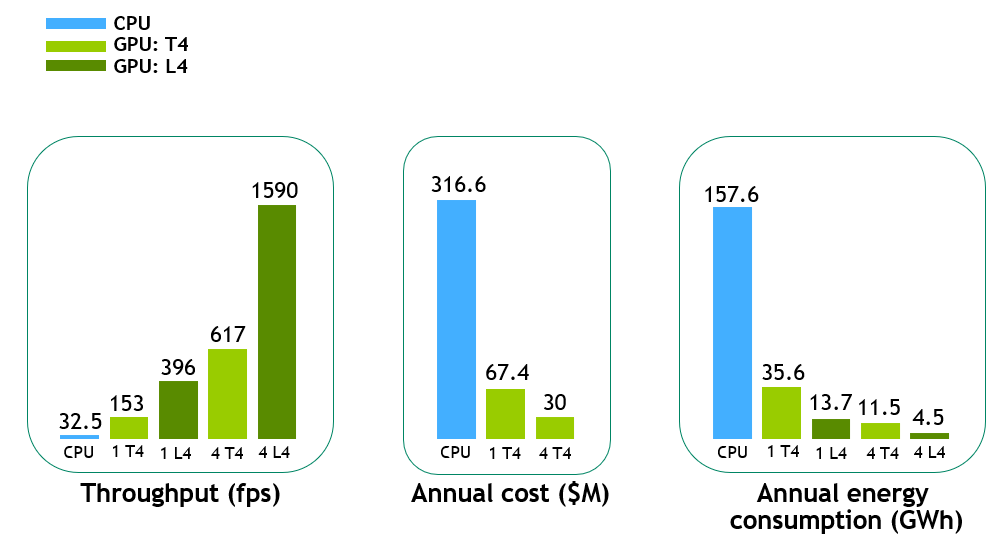
为了更好地展示 CV-CUDA 带来的好处,我们在不同的实例(一个 T4 GPU、一个 L4 GPU、四个 T4 GPU 和四个 L4 GPU)上执行了 GPU 流水线。
新推出的 NVIDIA L4 Tensor Core GPU 由 NVIDIA Ada Lovelace 架构提供支持,可为视频、人工智能、视觉计算、图形和虚拟化提供低成本、高能效的加速。
在上图 中,与 CPU 基线相比,单个 T4 GPU 上的端到端吞吐量加速约为 5 倍,新的 L4 GPU 上的加速进一步提高至约 12 倍。 对于多个 GPU 实例,性能几乎呈线性扩展,例如,在四个 T4 GPU 和四个 L4 GPU 上分别约为 19 倍和 48 倍。
为了计算每年的云成本和能源消耗,我们假设典型的视频工作负载为每分钟上传到视频流平台的 500 个视频小时。 对于每年的云成本,我们只考虑了 T4 GPU(L4 GPU 将在未来可用)并假设 Amazon EC2 G4 实例的一年预留定价。
鉴于此,单个 T4 GPU 上此示例视频工作负载的年度成本将约为 CPU 流程的 1/5。 这预示着此类工作负载的典型云成本节省估计约为数亿美元。
对于数据中心,除了与处理如此庞大的工作负载所需的硬件相关的成本外,能源效率对于降低能源成本和环境影响也至关重要。
在上图中,年能耗(以 GWh 为单位)是根据服务器的平均小时功耗计算的,该服务器具有相应硬件的相同视频工作负载。 单个 L4 系统的能耗约为 CPU 服务器的 1/12。 对于像示例视频这样的工作负载(每分钟 500 小时的视频),每年的节能估计约为数百 GWh。
这些节能效果非常显着,因为这相当于避免每年驾驶的数万辆乘用车排放温室气体,每辆乘用车每年行驶约 11,000 英里。
CV-CUDA Beta v0.3.0 功能
现在您已经看到使用 CV-CUDA 加速 AI 计算机视觉工作负载的好处,下面是一些关键特性:
- 开源:GitHub 上的 Apache 2.0 许可开源软件。
- 支持的运算符:CV-CUDA 提供了 30 多个常用于 AI 计算机视觉工作负载的预处理和后处理步骤的专用运算符。 这些无状态、独立的操作符很容易插入到现有的自定义处理框架中。 常见的运算符包括 ConvertTo、Custom crop、Normalize、PadStack、Reformat 和 Resize。 有关详细信息,请参阅 CV-CUDA 开发人员指南中的完整列表。
- 新运算符:CV-CUDA Beta v0.3.0 提供了新的运算符,例如重新映射、查找轮廓、非最大抑制、阈值处理和自适应阈值处理。
- NVIDIA Triton 的自定义后端:您现在可以使用示例应用程序在构建计算机视觉管道时将 CV-CUDA 集成到自定义后端中。
- 多语言 API:CV-CUDA 包括用于 C/C++ 和 Python 的 API。
- 框架接口:对现有 DL 框架(如 PyTorch 和 TensorFlow)的易于使用和零复制接口。
- 批量支持:支持所有 CV-CUDA 算子,让您获得更高的 GPU 利用率和更好的性能。
- 统一和可变形状批处理支持:CV-CUDA 接受具有相同或不同维度的张量。
- 示例应用程序:端到端加速图像分类、对象检测和视频分割示例应用程序。
- PIP安装。
- 安装、入门和 API 参考指南。