卷积注意力模块(CBAM)
1. 简介
1.1 简介
CBAM 是对标于SENet所提出的一种结合了通道注意力和空间注意力的轻量级模块,它和SENet一样,几乎可以嵌入任何CNN网络中,在带来小幅计算量和参数量的情况下,大幅提升模型性能。
github: https://github.com/Jongchan/attention-module
SENet(Sequeeze and Excitation Net)是2017届ImageNet分类比赛的冠军网络,本质上是一个基于
通道的Attention模型,它通过建模各个特征通道的重要程度,然后针对不同的任务增强或者抑制不同的通道
CBAM 是对标于SENet所提出的一种结合了通道注意力和空间注意力的轻量级模块,它和SENet一样,几乎可以嵌入任何CNN网络中,在带来小幅计算量和参数量的情况下,大幅提升模型性能。
卷积神经网络在很大程度上推动了计算机视觉任务的发展,最近的众多研究主要关注了网络的三个重要因素:深度、宽度、基数(cardinality)
深度的代表:VGG、ResNet
宽度的代表:GooLeNet
基数的代表:Xception、ResNeXt
而本文作者承接SENet的思想,从attention(注意力)这个维度出发,研究提升网络性能的方法。
2. 网络
人类视觉系统的一个重要特性是,人们不会试图同时处理看到的整个场景。取而代之的是,为了更好地捕捉视觉结构,人类利用一系列的局部瞥见,有选择性地聚集于显著部分。近年来,有人尝试将注意力机制引入到卷积神经网络中,以提高其在大规模分类任务中的性能。
本文作者为了强调空间和通道这两个维度上的有意义特征,依次应用通道和空间注意力模块,来分别在通道和空间维度上学习关注什么、在那里关注。CBAM如下图1 所示。
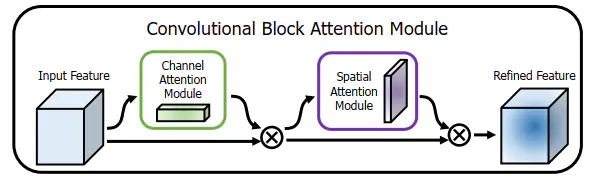
给定一个中间特征图,我们沿着通道和空间两个维度依次推断出注意力权重,然后与原特征图相乘来对特征进行自适应调整。 由于
CBAM是一个轻量级的通用模块,它可以无缝地集成到任何 CNN 架构中,额外开销忽略不计,并且可以与基本 CNN 一起进行端到端的训练。 在不同的分类和检测数据集上,将 CBAM 集成到不同的模型中后,模型的表现都有了一致的提升,展示了其广泛的可应用性。输入特征依次通过
通道注意力模块、空间注意力模块的筛选,最后获得经过了重标定的特征,即强调重要特征,压缩不重要特征。
2.1 通道注意力(Channel Attention CA)
通道注意力有SE-Net,ECA-Net机制,可以理解为让网络在看什么。
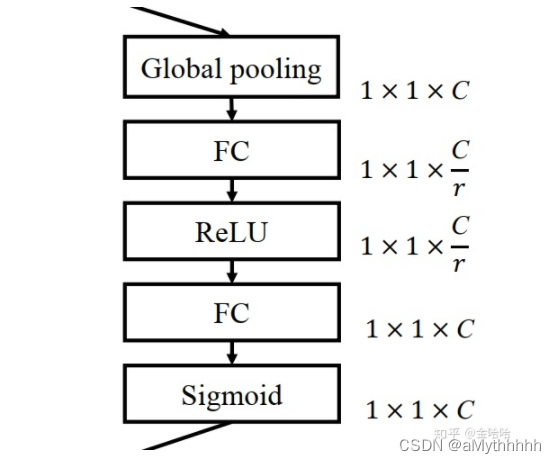
特征的每一个通道都代表着一个专门的检测器,因此,通道注意力是关注什么样的特征是有意义的。为了汇总空间特征,作者采用了全局平均池化和最大池化两种方式来分别利用不同的信息。

简而言之:注意力机制可对特征进行校正,校正后的特征可保留有价值的特征,剔除没价值的特征。
步骤
-
挤压(Squeeze)输入图像
对输入特征图的空间维度进行压缩,这一步可以通过全局平均池化(GAP)和全局最大池化(GMP)(全局平均池化效果相对来说会比最大池化要好),通过这一步。 H × W × C H\times W\times C H×W×C的输入图像被压缩成为 1 × 1 × C 1\times 1\times C 1×1×C的通道描述符。下方公式输入为 S × S × B S\times S\times B S×S×B的 f e a t u r e m a p feature map featuremap:
s b l + 1 = 1 S × S ∑ i = 1 S ∑ j = 1 S u i , j , b ( l + 1 ) s_b^{l+1}=\frac{1}{S\times S}\sum_{i=1}^S \sum_{j=1}^S u_{i,j,b}^{(l+1)} sbl+1=S×S1i=1∑Sj=1∑Sui,j,b(l+1)
将全局空间信息压缩到通道描述符,既降低了网络参数,也能达到防止过拟合的作用。 -
excitation通道描述符
这一步主要是将上一步得到的通道描述符送到两个全连接网络中,得到注意力权重矩阵,再与原图做乘法运算得到校准之后的注意力特征图。
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Sequential(nn.Conv2d(in_planes, in_planes // 16, 1, bias=False),
nn.ReLU(),
nn.Conv2d(in_planes // 16, in_planes, 1, bias=False))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc(self.avg_pool(x))
max_out = self.fc(self.max_pool(x))
out = avg_out + max_out
return self.sigmoid(out)
2.2 空间注意力
来源于 空间域注意力(spatial transformer network, STN)
空间域注意力机制的论文:Spatial Transformer Networks, pytorch实现:https://github.com/fxia22/stn.pytorch。
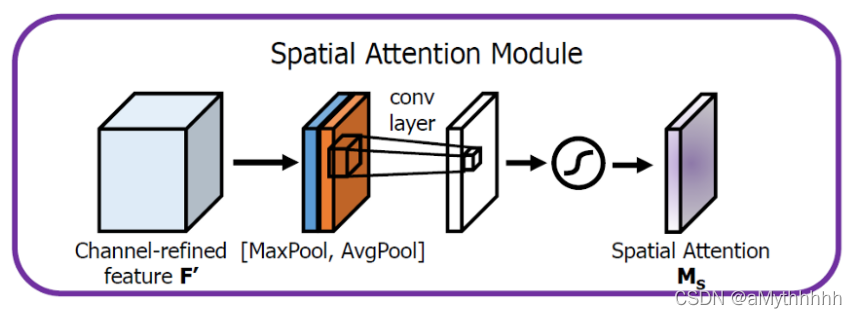
使用通道注意力的目的:找到关键信息在map上哪个位置上最多,是对通道注意力的补充,简单来说,通道注意力是为了找到哪个通道上有重要信息,而空间注意力则是在这个基础上,基于通道的方向,找到哪一块位置信息聚集的最多。
空间注意力步骤:
-
沿着通道轴应用平均池化和最大池操作,然后将它们连接起来生成一个有效的特征描述符。
注意:池化操作是沿着通道轴进行的,即每次池化时对比的是不同通道之间的数值,而非同一个通道不同区域的数值。
-
将特征描述符送入一个卷积网络进行卷积,将得到的特征图通过激活函数得到最终的空间注意特征图。
M S ( F ) = σ ( f 7 × 7 ( [ A v g P o o l ( F ) ; M a x P o o l ( F ) ] ) ) = σ ( f 7 × 7 ( F a v g s ; F m a x s ) ) M_S(F)=\sigma(f^{7\times 7}([AvgPool(F);MaxPool(F)])) \\ =\sigma(f^{7\times 7}(F^s_{avg};F^s_{max})) MS(F)=σ(f7×7([AvgPool(F);MaxPool(F)]))=σ(f7×7(Favgs;Fmaxs))
具体来说,使用两个pooling操作聚合成一个feature map的通道信息,生成两个2D图: Fsavg大小为 1 × H × W 1×H×W 1×H×W,Fsmax大小为 1 × H × W 1×H×W 1×H×W。 σ σ σ表示sigmoid函数, f 7 × 7 f^{7×7} f7×7表示一个滤波器大小为 7 × 7 7×7 7×7的卷积运算。
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
3. 代码
class ChannelAttentionModule(nn.Module):
def __init__(self, channel, ratio=16):
super(ChannelAttentionModule, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.shared_MLP = nn.Sequential(
nn.Conv2d(channel, channel // ratio, 1, bias=False),
nn.ReLU(),
nn.Conv2d(channel // ratio, channel, 1, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = self.shared_MLP(self.avg_pool(x))
maxout = self.shared_MLP(self.max_pool(x))
return self.sigmoid(avgout + maxout)
class SpatialAttentionModule(nn.Module):
def __init__(self):
super(SpatialAttentionModule, self).__init__()
self.conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avgout, maxout], dim=1)
out = self.sigmoid(self.conv2d(out))
return out
class CBAM(nn.Module):
def __init__(self, channel):
super(CBAM, self).__init__()
self.channel_attention = ChannelAttentionModule(channel)
self.spatial_attention = SpatialAttentionModule()
def forward(self, x):
out = self.channel_attention(x) * x
out = self.spatial_attention(out) * out
return out
改装后的Unet
class conv_block(nn.Module):
def __init__(self,ch_in,ch_out):
super(conv_block,self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=3,stride=1,padding=1,bias=True),
nn.BatchNorm2d(ch_out),
nn.ReLU(inplace=True),
nn.Conv2d(ch_out, ch_out, kernel_size=3,stride=1,padding=1,bias=True),
nn.BatchNorm2d(ch_out),
nn.ReLU(inplace=True)
)
def forward(self,x):
x = self.conv(x)
return x
class up_conv(nn.Module):
def __init__(self,ch_in,ch_out):
super(up_conv,self).__init__()
self.up = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.Conv2d(ch_in,ch_out,kernel_size=3,stride=1,padding=1,bias=True),
nn.BatchNorm2d(ch_out),
nn.ReLU(inplace=True)
)
def forward(self,x):
x = self.up(x)
return x
class U_Net_v1(nn.Module): #添加了空间注意力和通道注意力
def __init__(self,img_ch=3,output_ch=2):
super(U_Net_v1,self).__init__()
self.Maxpool = nn.MaxPool2d(kernel_size=2,stride=2)
self.Conv1 = conv_block(ch_in=img_ch,ch_out=64) #64
self.Conv2 = conv_block(ch_in=64,ch_out=128) #64 128
self.Conv3 = conv_block(ch_in=128,ch_out=256) #128 256
self.Conv4 = conv_block(ch_in=256,ch_out=512) #256 512
self.Conv5 = conv_block(ch_in=512,ch_out=1024) #512 1024
self.cbam1 = CBAM(channel=64)
self.cbam2 = CBAM(channel=128)
self.cbam3 = CBAM(channel=256)
self.cbam4 = CBAM(channel=512)
self.Up5 = up_conv(ch_in=1024,ch_out=512) #1024 512
self.Up_conv5 = conv_block(ch_in=1024, ch_out=512)
self.Up4 = up_conv(ch_in=512,ch_out=256) #512 256
self.Up_conv4 = conv_block(ch_in=512, ch_out=256)
self.Up3 = up_conv(ch_in=256,ch_out=128) #256 128
self.Up_conv3 = conv_block(ch_in=256, ch_out=128)
self.Up2 = up_conv(ch_in=128,ch_out=64) #128 64
self.Up_conv2 = conv_block(ch_in=128, ch_out=64)
self.Conv_1x1 = nn.Conv2d(64,output_ch,kernel_size=1,stride=1,padding=0) #64
def forward(self,x):
# encoding path
x1 = self.Conv1(x)
x1 = self.cbam1(x1) + x1
x2 = self.Maxpool(x1)
x2 = self.Conv2(x2)
x2 = self.cbam2(x2) + x2
x3 = self.Maxpool(x2)
x3 = self.Conv3(x3)
x3 = self.cbam3(x3) + x3
x4 = self.Maxpool(x3)
x4 = self.Conv4(x4)
x4 = self.cbam4(x4) + x4
x5 = self.Maxpool(x4)
x5 = self.Conv5(x5)
# decoding + concat path
d5 = self.Up5(x5)
d5 = torch.cat((x4,d5),dim=1)
d5 = self.Up_conv5(d5)
d4 = self.Up4(d5)
d4 = torch.cat((x3,d4),dim=1)
d4 = self.Up_conv4(d4)
d3 = self.Up3(d4)
d3 = torch.cat((x2,d3),dim=1)
d3 = self.Up_conv3(d3)
d2 = self.Up2(d3)
d2 = torch.cat((x1,d2),dim=1)
d2 = self.Up_conv2(d2)
d1 = self.Conv_1x1(d2)
return d1
4. 拓展
4.1 位置注意力(position-wise attention)
论文地址:CCNet: Criss-Cross Attention for Semantic Segmentation
代码地址:https://github.com/speedinghzl/CCNet
def _check_contiguous(*args):
if not all([mod is None or mod.is_contiguous() for mod in args]):
raise ValueError("Non-contiguous input")
class CA_Weight(autograd.Function):
@staticmethod
def forward(ctx, t, f):
# Save context
n, c, h, w = t.size()
size = (n, h+w-1, h, w)
weight = torch.zeros(size, dtype=t.dtype, layout=t.layout, device=t.device)
_ext.ca_forward_cuda(t, f, weight)
# Output
ctx.save_for_backward(t, f)
return weight
@staticmethod
@once_differentiable
def backward(ctx, dw):
t, f = ctx.saved_tensors
dt = torch.zeros_like(t)
df = torch.zeros_like(f)
_ext.ca_backward_cuda(dw.contiguous(), t, f, dt, df)
_check_contiguous(dt, df)
return dt, df
class CA_Map(autograd.Function):
@staticmethod
def forward(ctx, weight, g):
# Save context
out = torch.zeros_like(g)
_ext.ca_map_forward_cuda(weight, g, out)
# Output
ctx.save_for_backward(weight, g)
return out
@staticmethod
@once_differentiable
def backward(ctx, dout):
weight, g = ctx.saved_tensors
dw = torch.zeros_like(weight)
dg = torch.zeros_like(g)
_ext.ca_map_backward_cuda(dout.contiguous(), weight, g, dw, dg)
_check_contiguous(dw, dg)
return dw, dg
ca_weight = CA_Weight.apply
ca_map = CA_Map.apply
class CrissCrossAttention(nn.Module):
""" Criss-Cross Attention Module"""
def __init__(self,in_dim):
super(CrissCrossAttention,self).__init__()
self.chanel_in = in_dim
self.query_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.key_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.value_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim , kernel_size= 1)
self.gamma = nn.Parameter(torch.zeros(1))
def forward(self,x):
proj_query = self.query_conv(x)
proj_key = self.key_conv(x)
proj_value = self.value_conv(x)
energy = ca_weight(proj_query, proj_key)
attention = F.softmax(energy, 1)
out = ca_map(attention, proj_value)
out = self.gamma*out + x
return out
__all__ = ["CrissCrossAttention", "ca_weight", "ca_map"]
4.2 Non-local Neural Networks
2017年论文
论文地址:https://arxiv.org/abs/1711.07971
代码地址:https://github.com/pprp/SimpleCVReproduction/tree/master/attention/Non-local/Non-Local_pytorch_0.4.1_to_1.1.0/lib
文章中列出了卷积网络在 统计全局信息 时出现的 三个问题 如下:
- 捕获长范围特征依赖需要累积很多层的网络,导致学习效率太低;
- 由于网络需要累计很深,需小心的设计模块和梯度;
- 当需要在比较远位置之间来回传递消息时,卷积或时序局部操作很困难。
故作者 基于图片滤波领域的非局部均值滤波操作思想,提出了一个泛化、简单、可直接嵌入到当前网络的 非局部操作算子,可以 捕获时间(一维时序信号)、空间 (图片) 和时空 (视频序列) 的长范围依赖。这样设计的 *好处* 是:
参考文章
(4条消息) 通道注意力与空间注意力模块_aMythhhhh的博客-CSDN博客_通道注意力模型
(4条消息) 一张手绘图带你搞懂空间注意力、通道注意力、local注意力及生成过程(附代码注释)_Mr DaYang的博客-CSDN博客_通道注意力
https://blog.csdn.net/qq_43205656/article/details/121191937