CBAM 全称 Convolutional Block Attention Module,论文地址:CBAM
与 SE Block 相比,CBAM 对分类网络的 Top-1 Error 约有 0.2% 的改进;对 Top-5 Error 约有 0.1% 的改进
但是 SE Block 的不足之处在于只有通道注意力,没有空间注意力,用在目标检测这种定位任务上效果可想而知
CBAM 作为 通道注意力 + 空间注意力 的模块,用在目标检测任务上的效果是非常惊艳的:
- [email protected]:约有 2.0% 的改进
- [email protected]:约有 2.0% 的改进
- mAP@[.5, .95]:约有 1.0% 的改进
通道注意力模块
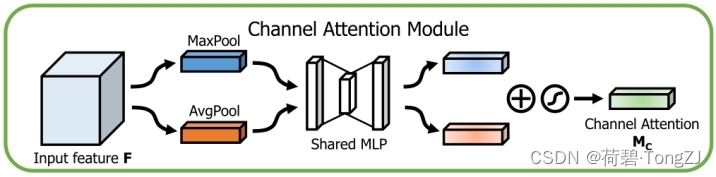
这个结构和 SE Block 是比较相似的,不同点在于 SE Block 只使用了平均池化
与 SE Block 相比,CBAM 增加最大池化可以对分类网络的 Top-1 Error、Top-5 Error 产生约 0.5% 的改进
通道注意力模块的运算可用以下公式表示:
运算流程为:将特征图的最大池特征、平均池特征,然后再使用全连接层 (等价于 1×1 卷积,参考 Torch 二维多通道卷积运算方式) 分别运算,求和之后使用 sigmoid 函数得到通道注意力 (值域为 [0, 1])
空间注意力模块
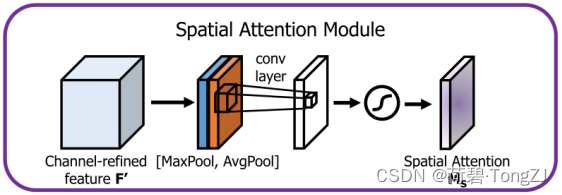
空间注意力模块则是沿着通道维度取最大值、平均值,拼接为二通道的特征图,再使用 7×7 卷积提取,使用 sigmoid 函数后得到空间注意力 (值域为 [0, 1])
CBAM 复现
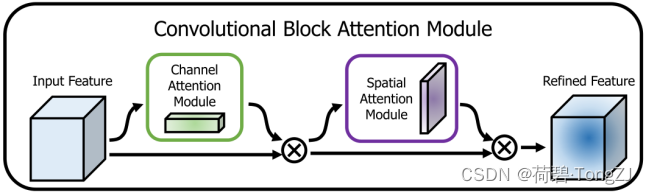
对于 [c, h, w] 的特征图,通道注意力的 shape 为 [c, 1, 1],空间注意力的 shape 为 [1, h, w]
而通道注意力和空间注意力的值域都是 [0, 1],用作特征图的门控因子与特征图相乘
class CBAM(nn.Module):
''' Convolutional Block Attention Module
c1: 输入通道数
r: 全连接层隐藏层通道缩放比
k: 空间注意力模块卷积核大小'''
def __init__(self, c1, r=16, k=7):
super(CBAM, self).__init__()
c_ = int(c1 // r)
self.mlp = nn.Sequential(
nn.Conv2d(c1, c_, kernel_size=1),
nn.Conv2d(c_, c1, kernel_size=1)
)
assert k & 1, '卷积核尺寸需为奇数'
self.conv = nn.Conv2d(2, 1, kernel_size=k, padding=k // 2)
def forward(self, x):
# Channel Attention
ca = torch.cat([
F.adaptive_avg_pool2d(x, 1),
F.adaptive_max_pool2d(x, 1)
], dim=3)
ca = torch.sigmoid(self.mlp(ca).sum(dim=3, keepdims=True))
x *= ca
# Spatial Attention
sa = torch.sigmoid(self.conv(torch.cat([
x.mean(dim=1, keepdims=True),
x.max(dim=1, keepdims=True)[0]
], dim=1)))
x *= sa
return x