CBAM: Convolutional Block Attention Module
ECCV2018
1、介绍
CBAM的中文名字是基于卷积块的注意机制,从结构上来看,它结合了空间注意力机制和通道注意力机制,从效果上来看,它能提高分类和检测的正确率。
2、模型结构
总体结构
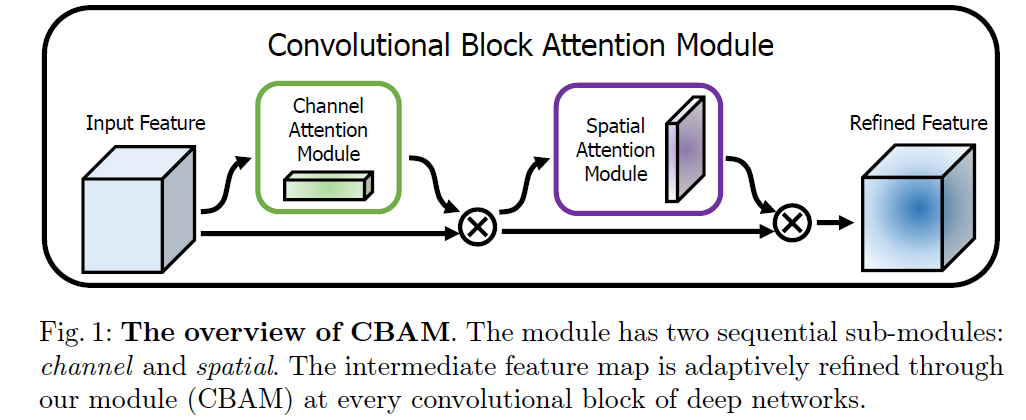

输入的Feature map维度为 R B ∗ C ∗ H ∗ W \mathbb R ^{B*C*H*W} RB∗C∗H∗W(各维度代表BCHW),经过通道注意力机制之后
先得到Channel Attention Module维度为 R B ∗ C ∗ 1 ∗ 1 \mathbb R^{B*C*1*1} RB∗C∗1∗1 (得到每一个channel的对应权重,权重值越大,代表着那个通道特征图越重要),element-wised相乘
得到空间注意力Spatial Attention Module 维度为 R B ∗ 1 ∗ H ∗ W \mathbb R^{B*1*H*W} RB∗1∗H∗W,(得到针对空间的对应注意力权重,权重越大,代表特征图上的内容越重要)
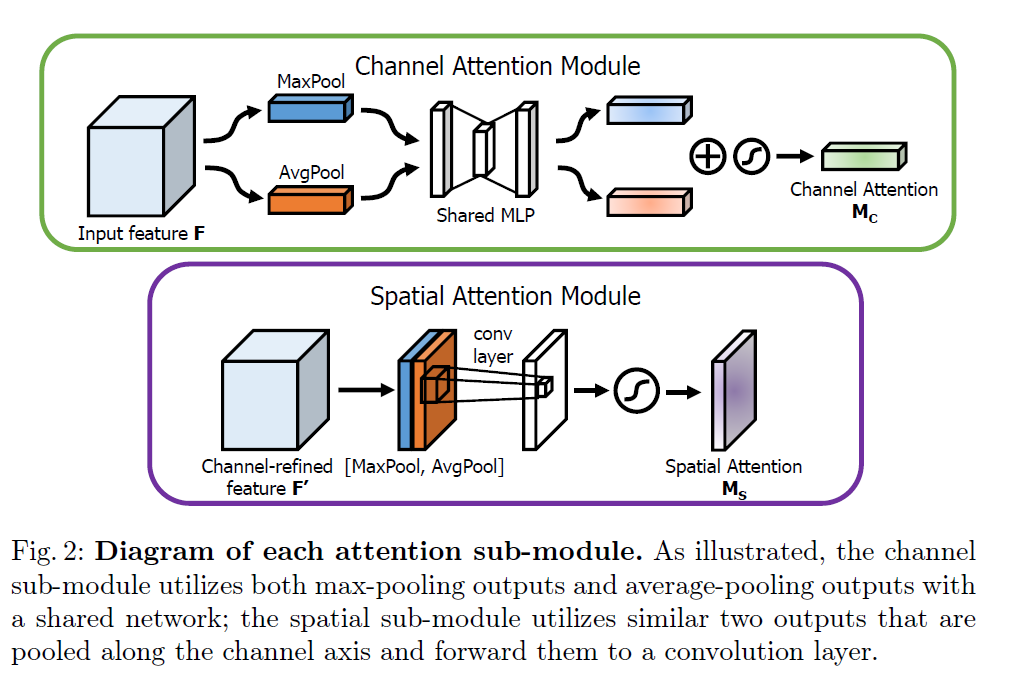
通道注意力机制
在下图中,MaxPool的操作就是提取一副特征图上的最大值,提取后的维度是 R B ∗ C ∗ 1 ∗ 1 \mathbb R^{B*C*1*1} RB∗C∗1∗1;AvgPool的操作就是提取一副特征图上的平均值,提取后的维度是 R B ∗ C ∗ 1 ∗ 1 \mathbb R^{B*C*1*1} RB∗C∗1∗1;MLP是一个共享(共用,只有一个)的全连接操作,在此得到两个对应的通道注意力编码序列(两个序列都蕴含着不同的注意力信息),加和激活后形成正式的通道注意力
M c ( F ) = σ ( M L P ( A v g P o o l ( F ) ) + M L P ( Max Pool ( F ) ) ) = σ ( W 1 ( W 0 ( F a v g c ) ) + W 1 ( W 0 ( F max c ) ) ) \begin{aligned} \mathbf{M}_{\mathbf{c}}(\mathbf{F}) &=\sigma(M L P(A v g P o o l(\mathbf{F}))+M L P(\operatorname{Max} \operatorname{Pool}(\mathbf{F}))) \\ &=\sigma\left(\mathbf{W}_{1}\left(\mathbf{W}_{0}\left(\mathbf{F}_{\mathbf{a v g}}^{\mathbf{c}}\right)\right)+\mathbf{W}_{\mathbf{1}}\left(\mathbf{W}_{0}\left(\mathbf{F}_{\max }^{\mathbf{c}}\right)\right)\right) \end{aligned} Mc(F)=σ(MLP(AvgPool(F))+MLP(MaxPool(F)))=σ(W1(W0(Favgc))+W1(W0(Fmaxc)))

空间注意力机制
在下图中,MaxPool的操作就是在通道上提取最大值,针对高和宽的每一个像素点都进行一次提取,得到 F m a x s ∈ R 1 × H × W \mathbf{F}_{\mathbf{max}}^{\mathbf{s}} \in \mathbb{R}^{1 \times H \times W} Fmaxs∈R1×H×W;AvgPool的操作就是在通道上提取平均值,针对高和宽的每一个像素点都进行一次提取,得到 F a v g s ∈ R 1 × H × W \mathbf{F}_{\mathbf{a v g}}^{\mathbf{s}} \in \mathbb{R}^{1 \times H \times W} Favgs∈R1×H×W;接着将前面所提取到的特征图(通道数都为1)合并得到一个2通道的特征图,在通过卷积层映射成一个单通道的feature map
概括为
- 基于 channel 进行 max pooling 和 avg pooling ;
- 将上述的结果基于 channel 做 concat ;
- 将 concat 后的结果经过一个 7x7 卷积操作, channel 降为1;
- 将结果经过 sigmoid 生成 spatial attention feature ,可以与输入的特征图做乘法,为 feature map 增加空间注意力。
M s ( F ) = σ ( f 7 × 7 ( [ A v g P o o l ( F ) ; M a x P o o l ( F ) ] ) ) = σ ( f 7 × 7 ( [ F a v g s ; F max s ] ) ) \begin{aligned} \mathbf{M}_{\mathbf{s}}(\mathbf{F}) &=\sigma\left(f^{7 \times 7}\left(\left[A v g P_{o o l}(\mathbf{F}) ; M a x P o o l(\mathbf{F})\right]\right)\right) \\ &=\sigma\left(f^{7 \times 7}\left(\left[\mathbf{F}_{\mathbf{a v g}}^{\mathbf{s}} ; \mathbf{F}_{\max }^{\mathbf{s}}\right]\right)\right) \end{aligned} Ms(F)=σ(f7×7([AvgPool(F);MaxPool(F)]))=σ(f7×7([Favgs;Fmaxs]))

3、模型特点
1.在通道注意力机制中引入全连接,并通过全连接降维,有利于提取更重要的信息(相当于PCA操作)
2.一般注意力机制是用AvgPool操作,本文引入MaxPool操作,可以提取到不同信息,增强特征的多样性。
实验
整合进入Resnet

4、代码实现Pytorch
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
class Flatten(nn.Module):
def forward(self, x):
return x.view(x.size(0), -1)
class ChannelGate(nn.Module):
def __init__(self, gate_channels, reduction_ratio=16):
super(ChannelGate, self).__init__()
self.gate_channels = gate_channels
self.mlp = nn.Sequential(
Flatten(),
nn.Linear(gate_channels, gate_channels // reduction_ratio),
nn.ReLU(),
nn.Linear(gate_channels // reduction_ratio, gate_channels)
)
def forward(self, x):
avg_pool = F.avg_pool2d(x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
channel_avg = self.mlp(avg_pool)
max_pool = F.max_pool2d(x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))
channel_max = self.mlp(max_pool)
channel_att_sum = channel_avg + channel_max
scale = torch.sigmoid(channel_att_sum).unsqueeze(2).unsqueeze(3).expand_as(x)
return x * scale
class ChannelPool(nn.Module):
def forward(self, x):
return torch.cat((torch.max(x, 1)[0].unsqueeze(1), torch.mean(x, 1).unsqueeze(1)), dim=1)
class SpatialGate(nn.Module):
def __init__(self):
super(SpatialGate, self).__init__()
self.compress = ChannelPool()
self.spatial = torch.nn.Conv2d(2, 1, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
def forward(self, x):
x_compress = self.compress(x)
x_out = self.spatial(x_compress)
scale = torch.sigmoid(x_out) # broadcasting
return x * scale
class CBAM(nn.Module):
def __init__(self, gate_channels, reduction_ratio=16, pool_types=['avg', 'max']):
super(CBAM, self).__init__()
self.ChannelGate = ChannelGate(gate_channels, reduction_ratio, pool_types)
self.SpatialGate = SpatialGate()
def forward(self, x):
x_out = self.ChannelGate(x)
x_out = self.SpatialGate(x_out)
return x_out
参考文献:
CBAM: Convolutional Block Attention Module_修行之路-CSDN博客
Convolutional Block Attention Module - 知乎
【论文复现】CBAM: Convolutional Block Attention Module_luuuyi的博客-CSDN博客
CBAM: Convolutional Block Attention Module_karen17的博客-CSDN博客