3. 误差反向传播法
文章链接
https://gitee.com/fakerlove/deep-learning
BP神经网络
资料参考
https://www.zybuluo.com/hanbingtao/note/476663
3.1 概念
反向传播(英语:Backpropagation,缩写为BP)是“误差反向传播”的简称。
- 是1986年由Rumelhart和McClelland为首的科学家提出的概念,是一种按照误差逆向传播算法训练的多层前馈神经网络,是目前应用最广泛的神经网络。
- 是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。
- 该方法对网络中所有权重计算损失函数的梯度。 这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。(误差的反向传播)
- 由于多层前馈神经网络的训练经常采用误差反向传播算法,人们也常把多层前馈神经网络称为BP网络。
梯度下降是求极值的方法
bp是求梯度的算法
3.2 前期准备
3.2.1 链式法则
a) 复合函数
复合函数是由多个函数构成的函数
z = t 2 t = x + y z=t^2 \\ t=x+y z=t2t=x+y
b) 链式法则
如果某个函数由复合函数表示,则该复合函数的导数可以用构成复合函数的各个函数的导数的乘积表示。
这就是链式法则的原理,乍一看可能比较难理解,但实际上它是一个非常简单的性质。

∂ z ∂ x = ∂ z ∂ t ∂ t ∂ x \frac{\partial z}{\partial x}=\frac{\partial z}{\partial t}\frac{\partial t}{\partial x} ∂x∂z=∂t∂z∂x∂t
∂ z \partial z ∂z正好可以像下面这样“互相抵消”,所以记起来很简单。
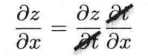
∂ z ∂ t = 2 t , ∂ t ∂ x = 1 \frac{\partial z}{\partial t}=2t,\frac{\partial t}{\partial x}=1 ∂t∂z=2t,∂x∂t=1
∂ z ∂ x = 2 t × 1 = 2 ( x + y ) \frac{\partial z}{\partial x}=2t\times 1=2(x+y) ∂x∂z=2t×1=2(x+y)


3.2.2 例子
两个人猜数字
这一过程类比没有隐层的神经网络,比如逻辑回归,
其中马里奥代表输出层节点,左侧接受输入信号,右侧产生输出结果,哆啦A梦则代表了误差,指导参数往更优的方向调整。
由于哆啦A梦可以直接将误差反馈给马里奥,同时只有一个参数矩阵和马里奥直接相连,所以可以直接通过误差进行参数优化(实纵线),迭代几轮,误差会降低到最小。
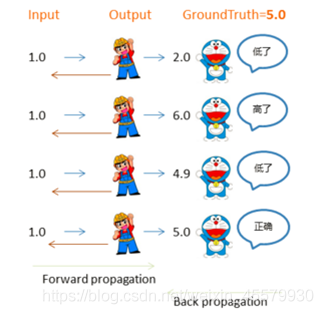
三个人猜数字
这一过程类比带有一个隐层的三层神经网络。
其中小女孩代表隐藏层节点,马里奥依然代表输出层节点,小女孩左侧接受输入信号,经过隐层节点产生输出结果,哆啦A梦代表了误差,指导参数往更优的方向调整。
由于哆啦A梦可以直接将误差反馈给马里奥,所以与马里奥直接相连的左侧参数矩阵可以直接通过误差进行参数优化(实纵线);
而与小女孩直接相连的左侧参数矩阵由于不能得到哆啦A梦的直接反馈而不能直接被优化(虚棕线)。
但由于反向传播算法使得哆啦A梦的反馈可以被传递到小女孩那进而产生间接误差,所以与小女孩直接相连的左侧权重矩阵可以通过间接误差得到权重更新,迭代几轮,误差会降低到最小。

3.2.3 反向传播
资料参考
https://blog.csdn.net/linxiaoyin/article/details/104123881
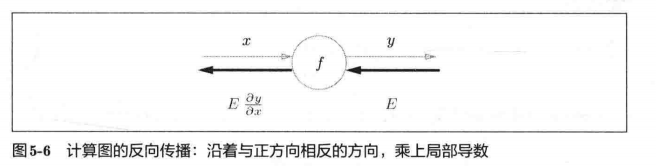
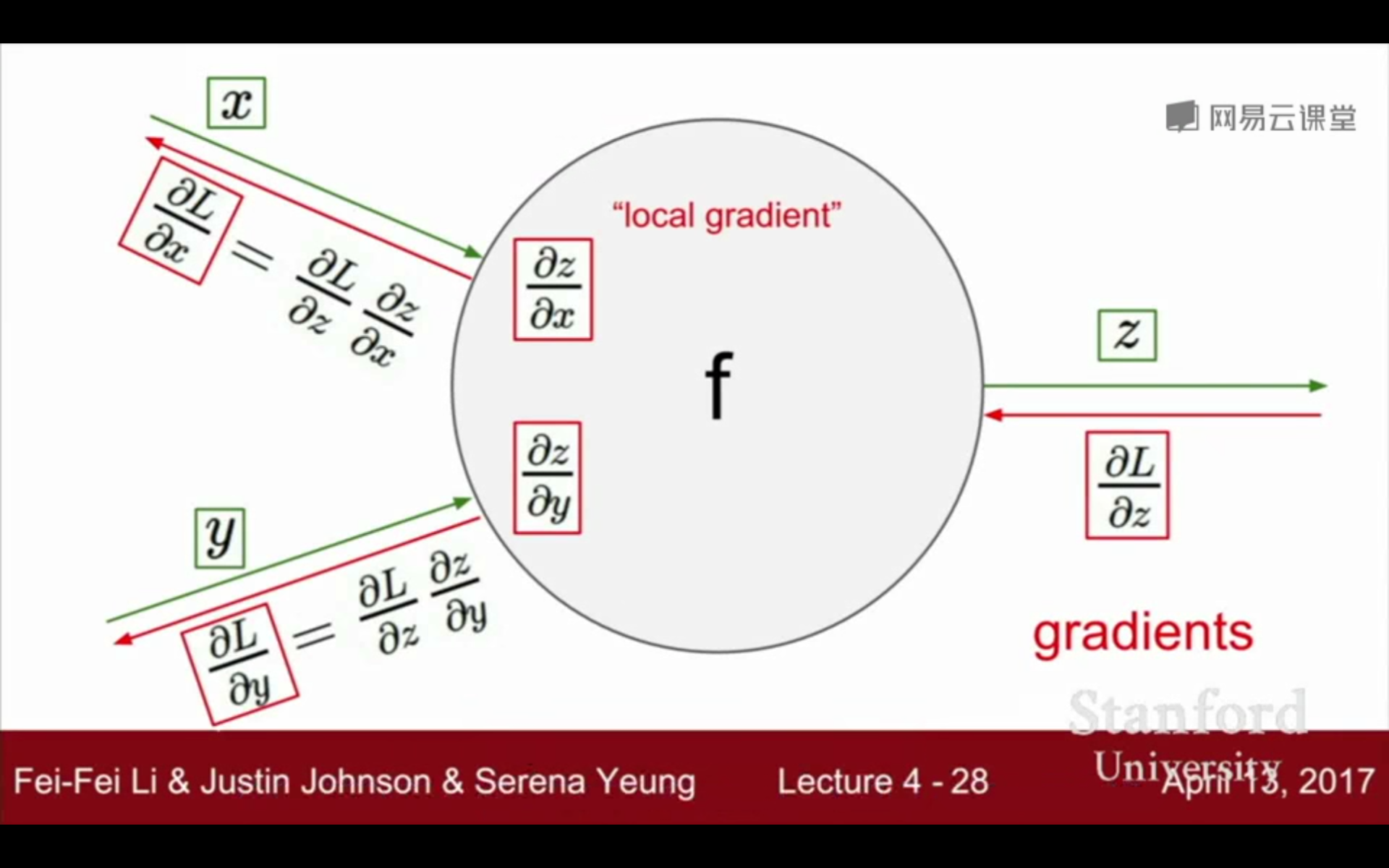
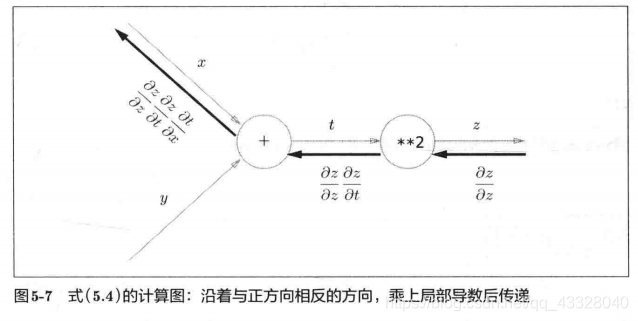
反向传播的计算顺序是,将信号 E E E乘以节点的局部导数 ∂ y ∂ x \frac{\partial y}{\partial x} ∂x∂y,然后将结果传递给下一个节点。这里所说的局部导数是指正向传播中 y = f ( x ) y = f(x) y=f(x)的导数,也就是 y 关于 x 的导数
∂ y ∂ x \frac{\partial y}{\partial x} ∂x∂y,比如,假设 y = f ( x ) = x 2 y=f(x)=x^2 y=f(x)=x2,则局部导数为 ∂ y ∂ x = 2 x \frac{\partial y}{\partial x}=2x ∂x∂y=2x。把这个局部导数乘以上游传过来的值(本例中为 E E E),然后传递给前面的节点。
这就是反向传播的计算顺序。通过这样的计算,可以高效地求出导数的值,这是反向传播的要点。
例子
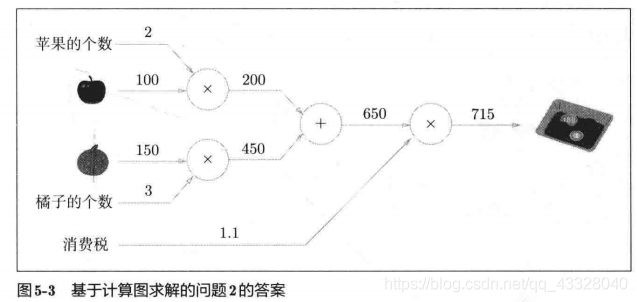
现在我们尝试将链式法则的计算用计算图表示出来。
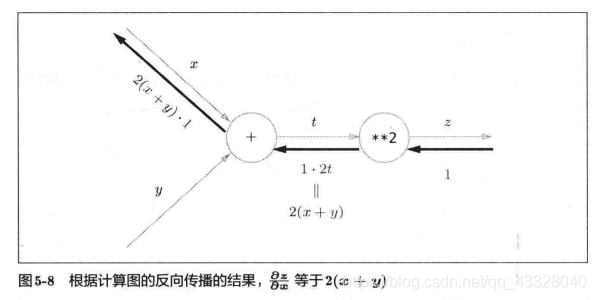
反向传播向x上面的就是 ∂ z ∂ x \frac{\partial z}{\partial x} ∂x∂z的结果为 2 ( x + y ) 2(x + y) 2(x+y)。
反向传播向y下面的就是 ∂ z ∂ y \frac{\partial z}{\partial y} ∂y∂z的结果为 2 ( x + y ) 2(x + y) 2(x+y)。
1) 加法反向传播
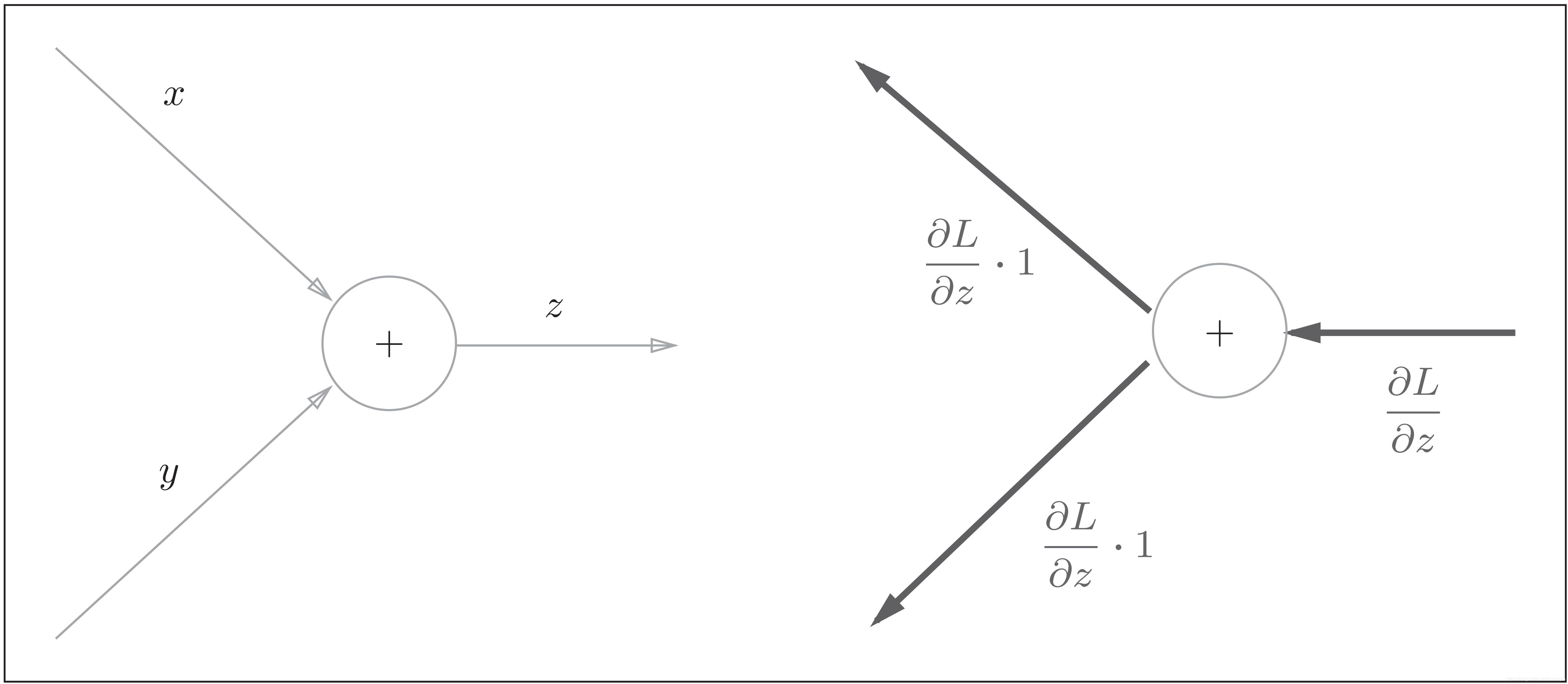
加法节点的反向传播:左图是正向传播,右图是反向传播。如右图的反向传播所示,加法节点的反向传播将上游的值原封不动地输出到下游
2) 乘法反向传播
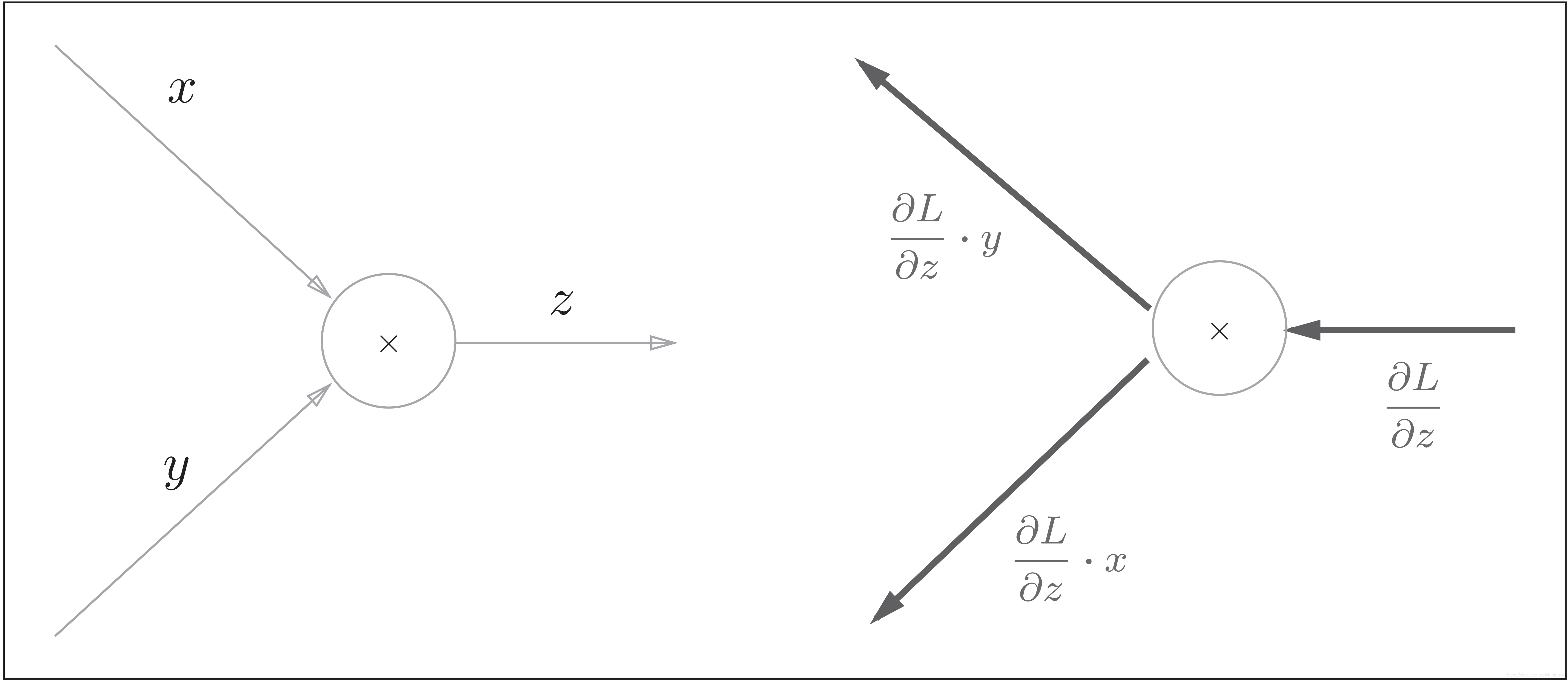
乘法的反向传播:左图是正向传播,右图是反向传播。乘法的反向传播会将上游的值乘以正向传播时的输入信号的“翻转值”后传递给下游。
3)ReLU层的反向传播
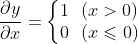
ReLU函数的计算图:
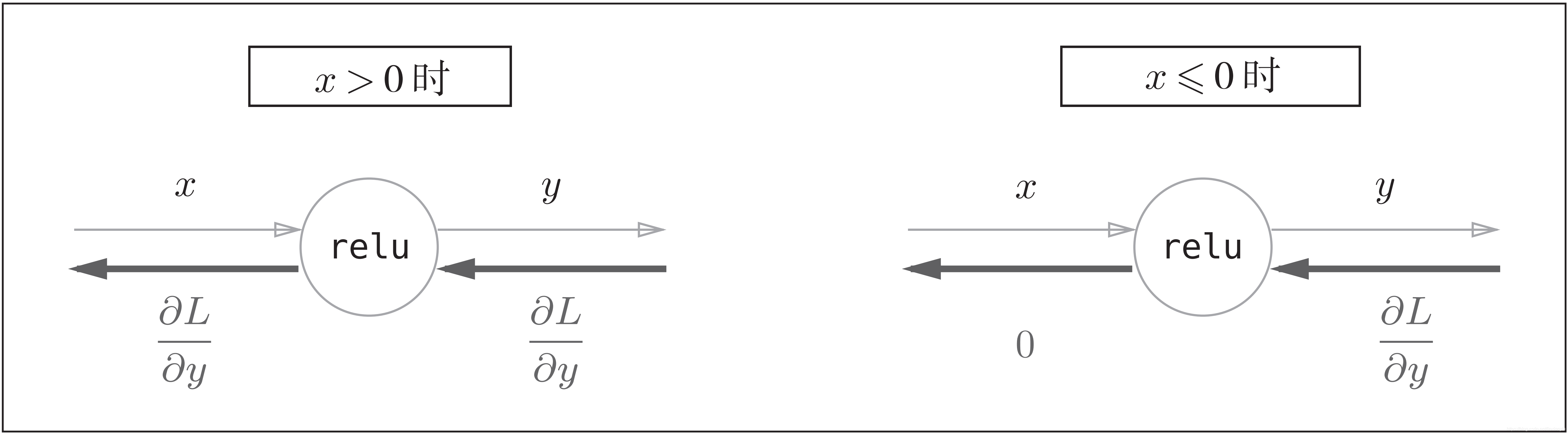
ReLU 层的作用就像电路中的开关一样。正向传播时,有电流通过的话,就将开关设为ON;没有电流通过的话,就将开关设为OFF。反向传播时,开关为ON的话,电流会直接通过;开关为OFF的话,则不会有电流通过。
4) Sigmoid层的反向传播

Sigmoid函数的正向计算图如下:
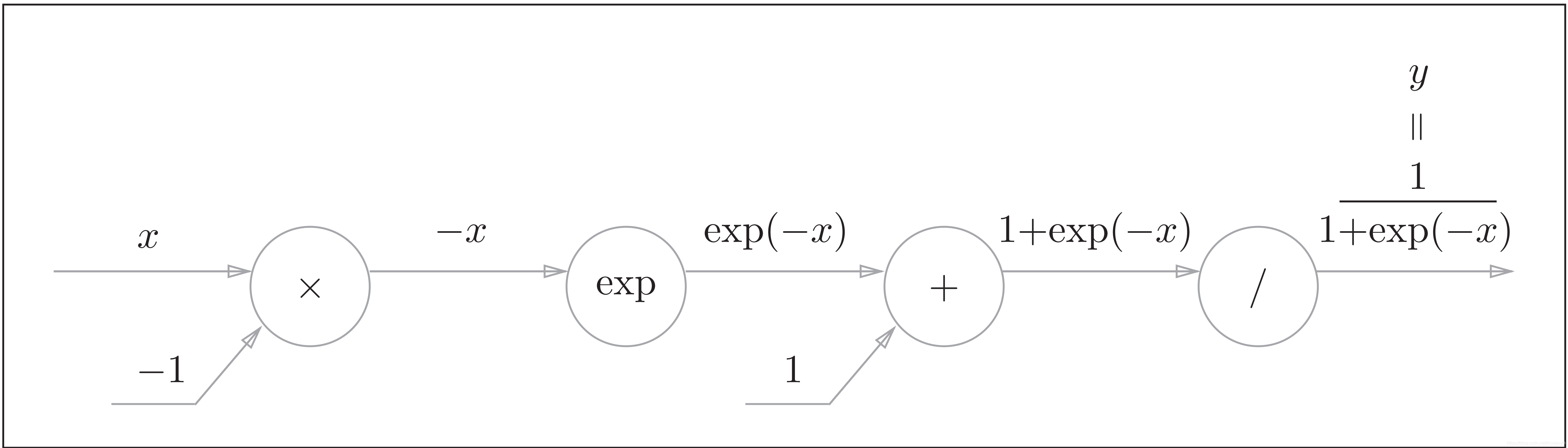
Sigmoid函数的计算图的简洁版为:
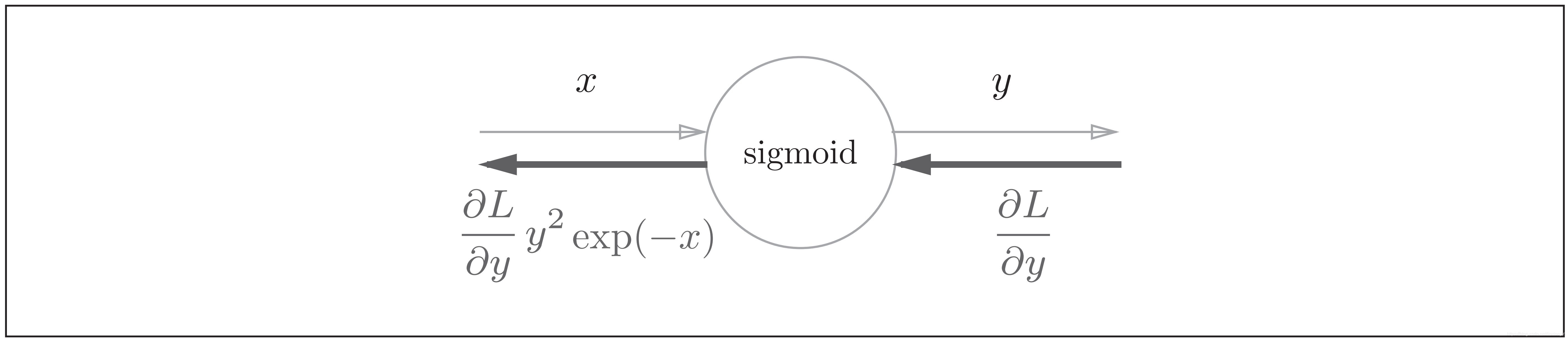
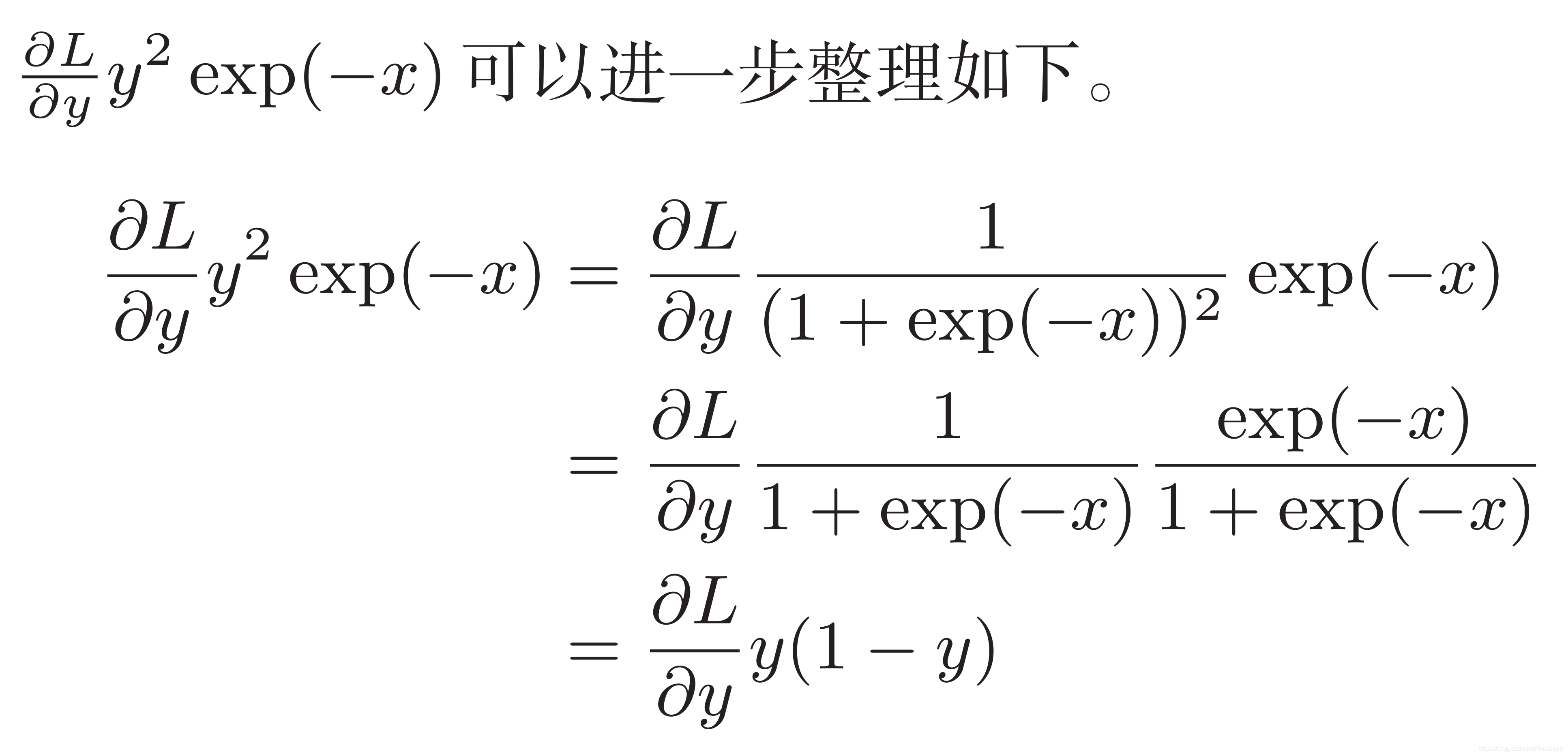
因此,Sigmoid函数的反向传播,只根据正向传播的输出就能计算出来

Sigmoid函数被选为激活函数还有一个很重要的原因是它的导数很容易计算:
f ′ ( x ) = f ( x ) ( 1 − f ( x ) ) f^\prime(x)=f(x)(1-f(x)) f′(x)=f(x)(1−f(x))
5) Softmax-with-Loss层的反向传播
这里假设要进行3类分类,从前面的层接收3个输入。如下图所示, Softmax层将输入 ( a 1 , a 2 , a 3 ) (a_1, a_2, a_3) (a1,a2,a3)正规化,输出 ( y 1 , y 2 , y 3 ) (y_1, y_2, y_3) (y1,y2,y3)。 Cross Entropy Error层接收Softmax的输出 ( y 1 , y 2 , y 3 ) (y_1, y_2, y_3) (y1,y2,y3)和监督标签 ( t 1 , t 2 , t 3 ) (t_1,t_2, t_3) (t1,t2,t3),从这些数据中输出损失 L L L
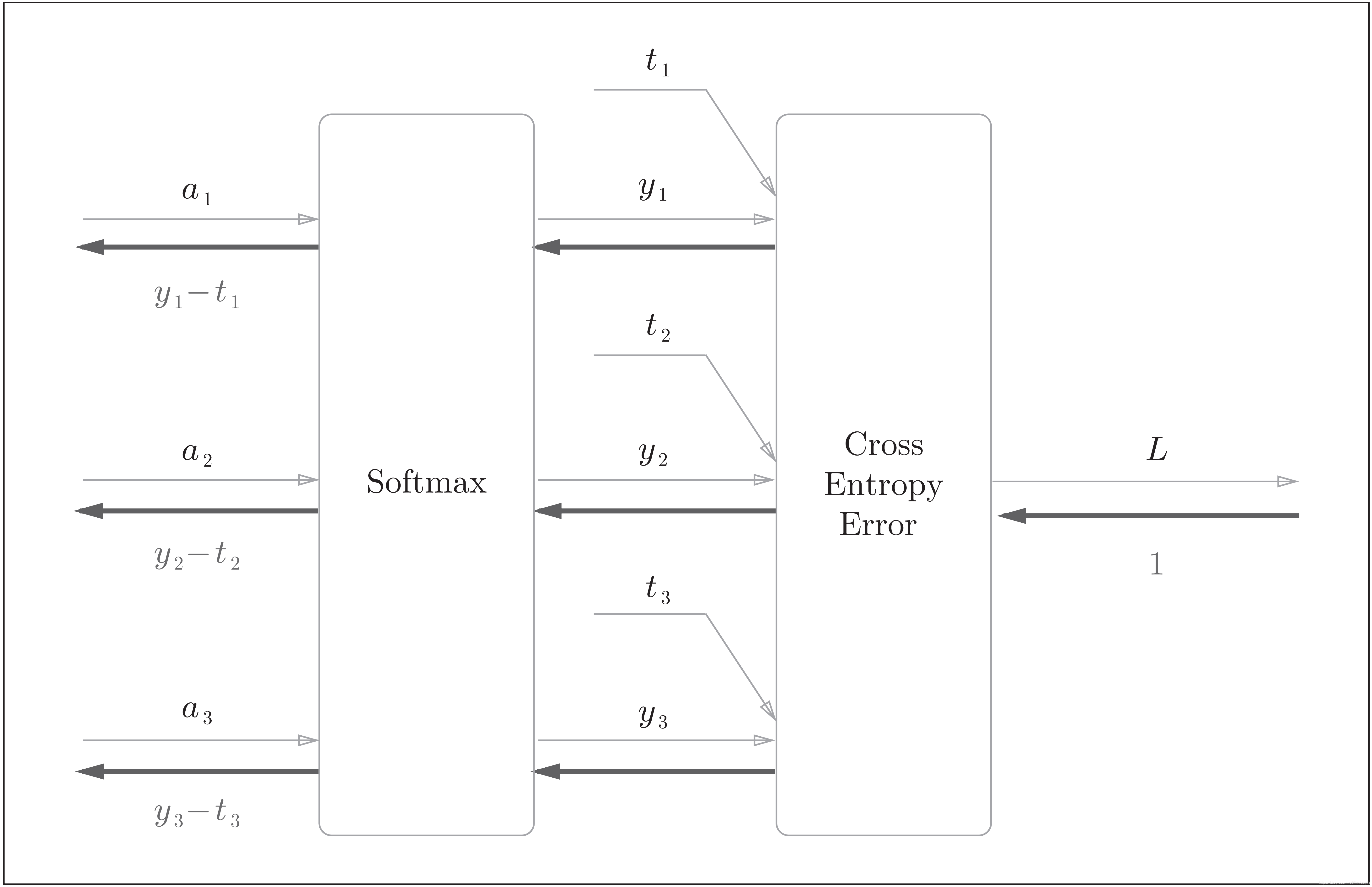
Softmax层的反向传播得到了 ( y 1 − t 1 , y 2 − t 2 , y 3 − t 3 ) (y_1 − t_1, y_2 − t_2, y_3-t_3) (y1−t1,y2−t2,y3−t3)这样“漂亮”的结果。由于 ( y 1 , y 2 , y 3 ) (y_1, y_2, y_3) (y1,y2,y3)是Softmax层的输出, ( t 1 , t 2 , t 3 ) (t_1, t_2, t_3) (t1,t2,t3)是监督数据,所以 ( y 1 − t 1 , y 2 − t 2 , y 3 − t 3 ) (y_1 − t_1, y_2 − t_2, y_3-t_3) (y1−t1,y2−t2,y3−t3)是Softmax层的输出和监督标签的差。
3.2.3 随机梯度下降SGD
更新公式 θ j = θ j − α ( h θ ( x 0 ( i ) , x 1 ( i ) , x 2 ( i ) . . . x n ( i ) ) − y ( i ) ) x j ( i ) \theta_j=\theta_j-\alpha (h_{\theta}(x_0^{(i)},x_1^{(i)},x_2^{(i)}...x_n^{(i)})-y^{(i)})x_j^{(i)} θj=θj−α(hθ(x0(i),x1(i),x2(i)...xn(i))−y(i))xj(i)
h θ ( x 0 ( i ) , x 1 ( i ) , x 2 ( i ) . . . x n ( i ) ) − y ( i ) h_{\theta}(x_0^{(i)},x_1^{(i)},x_2^{(i)}...x_n^{(i)})-y^{(i)} hθ(x0(i),x1(i),x2(i)...xn(i))−y(i) 是误差
α \alpha α 是步长,或者学习率
x i x_i xi是值
参考资料
https://blog.csdn.net/ft_sunshine/article/details/90221691
参考资料
https://blog.csdn.net/u014313009/article/details/51039334
参考资料
https://blog.csdn.net/weixin_42398658/article/details/83859131
参考资料
https://blog.csdn.net/ft_sunshine/article/details/90221691
参考资料
https://www.cnblogs.com/charlotte77/p/5629865.html
资料参考2
https://blog.csdn.net/weixin_45579930/article/details/112464775
参考资料
https://www.jianshu.com/p/fc0f28bf6aa2
参考链接
https://zhuanlan.zhihu.com/p/32819991
3.3 算法推导
首先明确,“正向传播”求损失,“反向传播”回传误差。同时,神经网络每层的每个神经元都可以根据误差信号修正每层的权重,
- 将训练集数据输入到ANN的输入层,经过隐藏层,最后达到输出层并输出结果,这是ANN的前向传播过程;
- 由于ANN的输出结果与实际结果有误差,则计算估计值与实际值之间的误差,并将该误差从输出层向隐藏层反向传播,直至传播到输入层;
- 在反向传播的过程中,根据误差调整各种参数的值;不断迭代上述过程,直至收敛
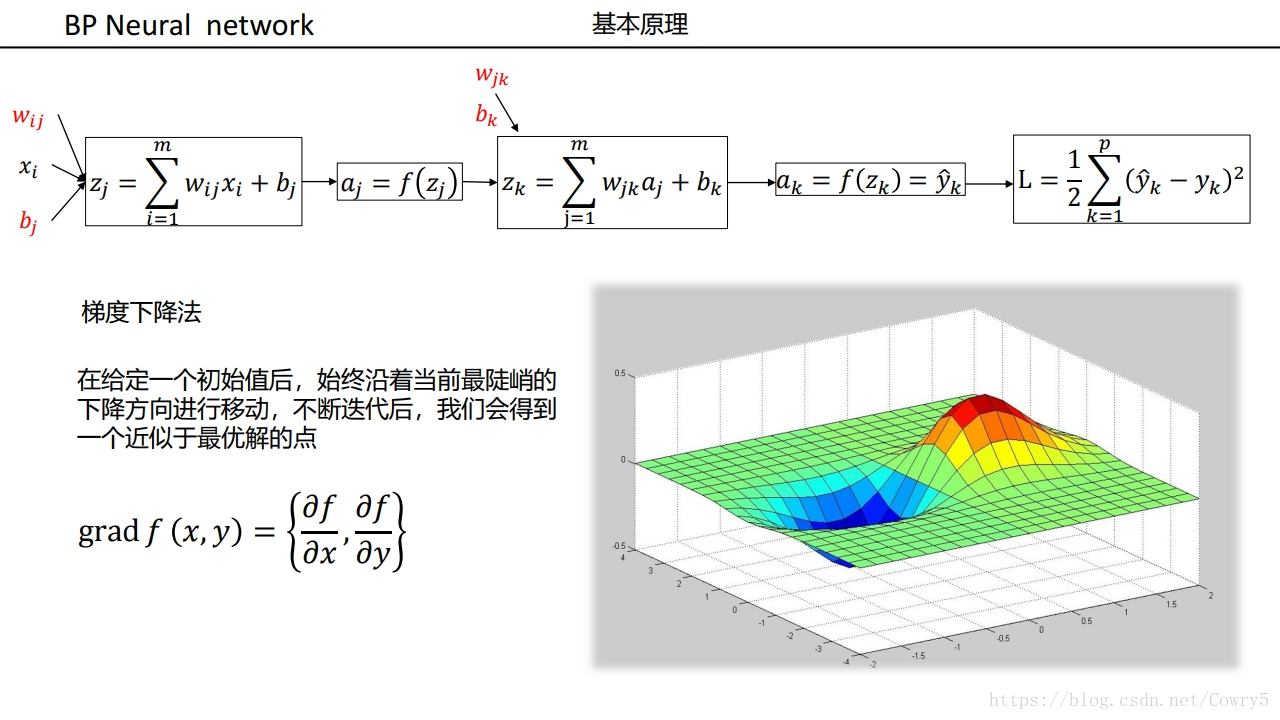
3.3.1 前向传播计算
- w j k l w^l_{jk} wjkl代表的是第l层的第j个神经元,与上一层 ( l − 1 ) (l-1) (l−1)第k个神经元输出相对应的权重
- a j l a_j^l ajl代表在第 l l l层上,第 j j j个神经元的输出
- z j l z_j^l zjl代表在第 l l l层上,第 j j j个神经元的输入
- b j l b_j^l bjl代表在第 l l l层上,第 j j j个神经元的偏置
- W W W代表权重举证, Z l Z^l Zl代表 l l l层输入矩阵
- A l A^l Al代表第l层输出矩阵, Y ^ \hat{Y} Y^代表最终输出矩阵, Y Y Y代表标准答案
- l l l表示神经网络的层数
- W = [ w 11 2 w 21 2 w 12 2 w 22 2 ] W=\begin{bmatrix}w_{11}^2&w_{21}^2\\ w_{12}^2&w_{22}^2\end{bmatrix} W=[w112w122w212w222]
- e o i e_{oi} eoi代表输出层第 i i i个神经元误差, e h i e_{hi} ehi代表隐藏层第i个神经元误差, e l i e_{li} eli代表输入层第 i i i个神经元误差
- E o E_o Eo表示输出层误差矩阵, E h E_h Eh隐藏层误差矩阵, E l E_l El输入层误差矩阵
- 对于3层神经网络 Y ^ = A 3 \hat{Y}=A^3 Y^=A3
过程如下
-
如何将输入层的信号传输至隐藏层呢,以隐藏层节点c为例,站在节点c上往后看(输入层的方向),可以看到有两个箭头指向节点c,因此a,b节点的信息将传递给c,同时每个箭头有一定的权重,因此对于c节点来说,输入信号为:
z 1 2 = a 1 1 ⋅ w 11 1 + a 2 1 ⋅ w 21 1 + b 1 2 z_1^2=a_1^1\cdot w_{11}^1+a_2^1\cdot w_{21}^1+b_1^2 z12=a11⋅w111+a21⋅w211+b12
-
同理,节点d的输入信号为:
z 2 2 = a 1 1 ⋅ w 12 1 + a 2 1 ⋅ w 22 1 + b 2 2 z_2^2=a_1^1\cdot w_{12}^1+a_2^1\cdot w_{22}^1+b_2^2 z22=a11⋅w121+a21⋅w221+b22
-
由于计算机善于做带有循环的任务,因此我们可以用矩阵相乘来表示:
Z 2 = W 1 A 1 + B 2 Z^2=W^1A^1+B^2 Z2=W1A1+B2
-
所以,隐藏层节点经过非线性变换后的输出表示如下:
A 2 = s i g m o i d ( Z 2 ) A^2=sigmoid(Z^2) A2=sigmoid(Z2)
-
同理,输出层的输入信号表示为权重矩阵乘以上一层的输出:
Z 3 = W 2 ⋅ A 2 + B 3 Z^3=W^2\cdot A^2+B^3 Z3=W2⋅A2+B3
-
同样,输出层节点经过非线性映射后的最终输出表示为:
A 3 = s i g m o i d ( Z 3 ) A^3=sigmoid(Z^3) A3=sigmoid(Z3)
-
输入信号在权重矩阵们的帮助下,得到每一层的输出,最终到达输出层。可见,权重矩阵在前向传播信号的过程中扮演着运输兵的作用,起到承上启下的功能。
统一表达式
输入表达式
z k 3 = ∑ j = 0 m w j k 2 a j 2 , k = 1 , 2 , 3 , ⋯ , n z^3_k=\sum_{j=0}^mw^2_{jk}a^2_j,k=1,2,3,\cdots,n zk3=∑j=0mwjk2aj2,k=1,2,3,⋯,n,表示输出层的输入
z j 2 = ∑ i = 0 m w i j 1 a i 1 , j = 1 , 2 , 3 , ⋯ , n z^2_j=\sum_{i=0}^mw^1_{ij}a^1_i,j=1,2,3,\cdots,n zj2=∑i=0mwij1ai1,j=1,2,3,⋯,n,表示隐藏层的输入
使用的是权重计算
输出表达式
a k 3 = f ( z k 3 ) = f ( ∑ j = 0 m w j k 2 a j 2 ) a^3_k=f(z^3_k)=f(\sum_{j=0}^mw^2_{jk}a^2_j) ak3=f(zk3)=f(∑j=0mwjk2aj2),
a k 2 = f ( z k 2 ) = f ( ∑ j = 0 m w j k 1 a j 1 ) a^2_k=f(z^2_k)=f(\sum_{j=0}^mw^1_{jk}a^1_j) ak2=f(zk2)=f(∑j=0mwjk1aj1),
其中 f f f为激活函数, f f f一般为sigmoid函数
使用的是激活函数计算
从后往前,利用链式求导法则,计算损失函数值对各参数 / 输入值 / 中间值的偏导数 / 梯度,梯度下降法需要使用反向传播来计算梯度。
在利用梯度下降法对权重矩阵等参数进行更新时,需要利用反向传播去计算损失函数对权重参数的偏导数。
3.3.2 计算各个层的误差
代价函数被用来计算ANN输出值与实际值之间的误差。
常用的代价函数是二次代价函数(Quadratic cost function):
1) 输出层误差
定义输出层误差
E = 1 2 ( Y − Y ^ ) 2 = 1 2 ∑ k = 1 m ( y k − a k 3 ) 2 E=\frac{1}{2}(Y-\hat{Y})^2=\frac{1}{2}\sum_{k=1}^m(y_k-a_k^3)^2 E=21(Y−Y^)2=21k=1∑m(yk−ak3)2
2) 隐藏层误差
将误差E式展开到隐层为:
E = 1 2 ∑ k = 1 n ( y k − a k 3 ) 2 = = 1 2 ∑ k = 1 n ( y k − f ( z k 3 ) ) 2 = 1 2 ∑ k = 1 n ( y k − f ( ∑ j = 0 m w j k 2 a j 2 ) ) 2 E=\frac{1}{2}\sum_{k=1}^n(y_k-a^3_k)^2= \\ =\frac{1}{2}\sum_{k=1}^n(y_k-f(z^3_k))^2 \\ =\frac{1}{2}\sum_{k=1}^n(y_k-f(\sum_{j=0}^mw_{jk}^2a^2_j))^2 E=21k=1∑n(yk−ak3)2==21k=1∑n(yk−f(zk3))2=21k=1∑n(yk−f(j=0∑mwjk2aj2))2
3) 输入层误差
将误差E进一步展开至输入层为:
E = 1 2 ∑ k = 1 n ( y k − f ( ∑ j = 0 m w j k 2 a j 2 ) ) 2 = 1 2 ∑ k = 1 n ( y k − f ( ∑ j = 0 m w j k 2 f ( ∑ i = 0 l w i j 1 z i 1 ) ) ) 2 E=\frac{1}{2}\sum_{k=1}^n(y_k-f(\sum_{j=0}^mw_{jk}^2a^2_j))^2 \\= \frac{1}{2}\sum_{k=1}^n(y_k-f(\sum_{j=0}^mw_{jk}^2f(\sum_{i=0}^lw_{ij}^1z^1_i)))^2 E=21k=1∑n(yk−f(j=0∑mwjk2aj2))2=21k=1∑n(yk−f(j=0∑mwjk2f(i=0∑lwij1zi1)))2
上面的计算过程并不难,只要耐心一步步的拆开式子,逐渐分解即可。现在还有两个问题需要解决:
误差E有了,怎么调整权重让误差不断减小?
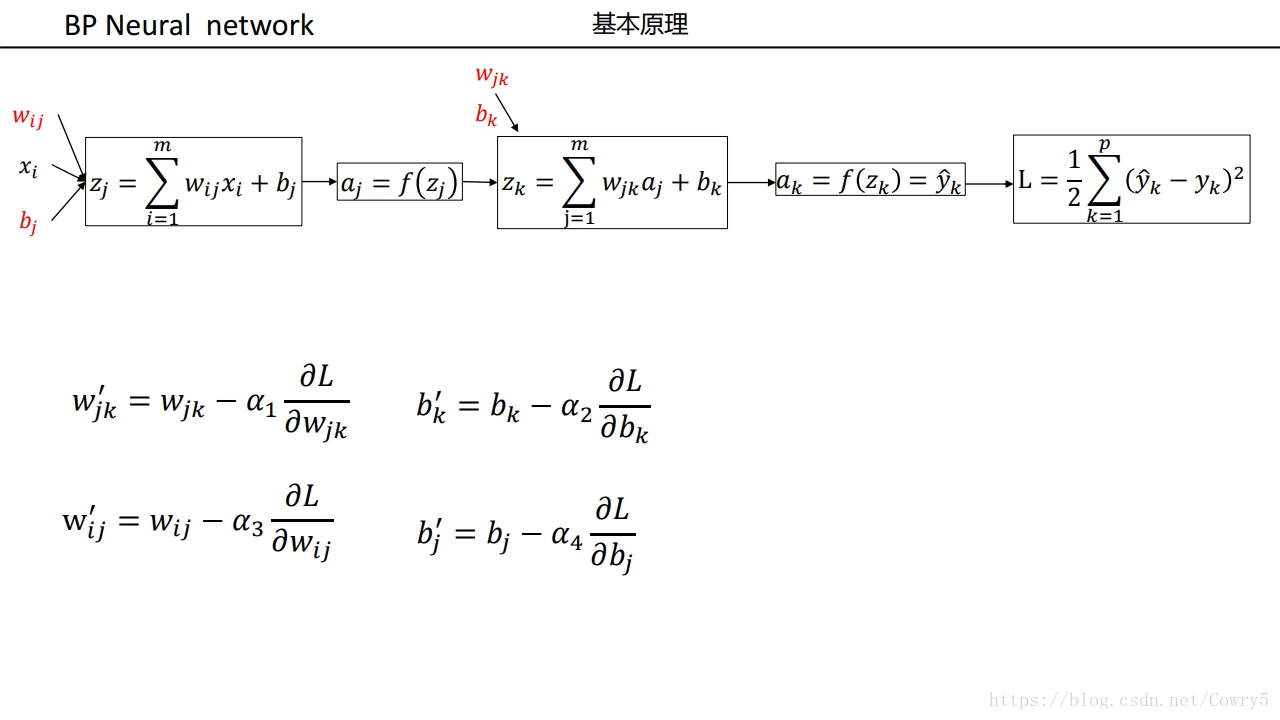
想到使用梯度下降法进行更新权值可以达到最优,
我们知道了,怎么传递到上一层,有随机梯度下降可知道,我们还需要梯度
3.3.3 计算梯度
1) 均方误差的梯度
均方差损失函数表达式为:
E = 1 2 ∑ k = 1 K ( y k − a k ) 2 E=\frac{1}{2}\sum_{k=1}^K(y_k-a_k)^2 E=21∑k=1K(yk−ak)2
其中 y k y_k yk为输出值, a k a_k ak为输出值,偏导数为
∂ E ∂ a i = ( a i − y i ) \frac{\partial E}{\partial a_i}=(a_i-y_i) ∂ai∂E=(ai−yi)
2) 单个神经元梯度
更新公式 x t + 1 ← x t − η × 梯 度 x_{t+1}\leftarrow x_t-\eta \times 梯度 xt+1←xt−η×梯度
梯度这么来????
想要更新参数,就得计算梯度,梯度是根据误差计算的。所以先试用反向传播来传递误差
定义误差
计算各个层损失

从最后一层的误差开始计算,用 δ j ( l ) \delta_j^{(l)} δj(l)表示第 l l l层的单元 j j j的损失, Δ ( l ) \Delta^{(l)} Δ(l)表示第 l l l层的梯度,则 δ 5 = a 5 − y \delta^{5}=a^{5}-y δ5=a5−y,利用这个误差值来计算前一层的误差:
δ 5 = a 5 − y δ ( 4 ) = ( ( θ ( 4 ) ) T δ ( 5 ) ⋅ g ′ ( z ( 4 ) ) ) δ ( 3 ) = ( ( θ ( 3 ) ) T δ ( 4 ) ⋅ g ′ ( z ( 3 ) ) ) Δ ( 3 ) = δ ( 4 ) ⋅ a ( 3 ) Δ ( 2 ) = δ ( 3 ) ⋅ a ( 2 ) \delta^{5}=a^{5}-y \\ \delta^{(4)}=((\theta^{(4)})^T\delta^{(5)}\cdot g^\prime(z^{(4)})) \\ \delta^{(3)}=((\theta^{(3)})^T\delta^{(4)}\cdot g^\prime(z^{(3)})) \\ \Delta^{(3)}=\delta^{(4)}\cdot a^{(3)} \\ \Delta^{(2)}=\delta^{(3)}\cdot a^{(2)} δ5=a5−yδ(4)=((θ(4))Tδ(5)⋅g′(z(4)))δ(3)=((θ(3))Tδ(4)⋅g′(z(3)))Δ(3)=δ(4)⋅a(3)Δ(2)=δ(3)⋅a(2)
于是假设λ=0,即不做任何正则化处理时:
∂ J ( θ ) ∂ θ i j ( l ) = a j ( l ) δ i ( l + 1 ) \frac{\partial J(\theta)}{\partial \theta_{ij}^{(l)}}=a_j^{(l)}\delta_i^{(l+1)} ∂θij(l)∂J(θ)=aj(l)δi(l+1)
- 输出层产生的错误 δ L = ( a L − y ) ⋅ g ′ ( z ( L ) ) \delta^L=(a^L-y)\cdot g^\prime(z^{(L)}) δL=(aL−y)⋅g′(z(L))
- 隐藏层传递的错误 δ l = ( ( θ l + 1 ) T δ l + 1 ) ⋅ g ′ ( z l ) \delta^l=((\theta^{l+1})^T\delta^{l+1})\cdot g^\prime(z^l) δl=((θl+1)Tδl+1)⋅g′(zl)
为啥这样子呢????,请看下面的公式推导
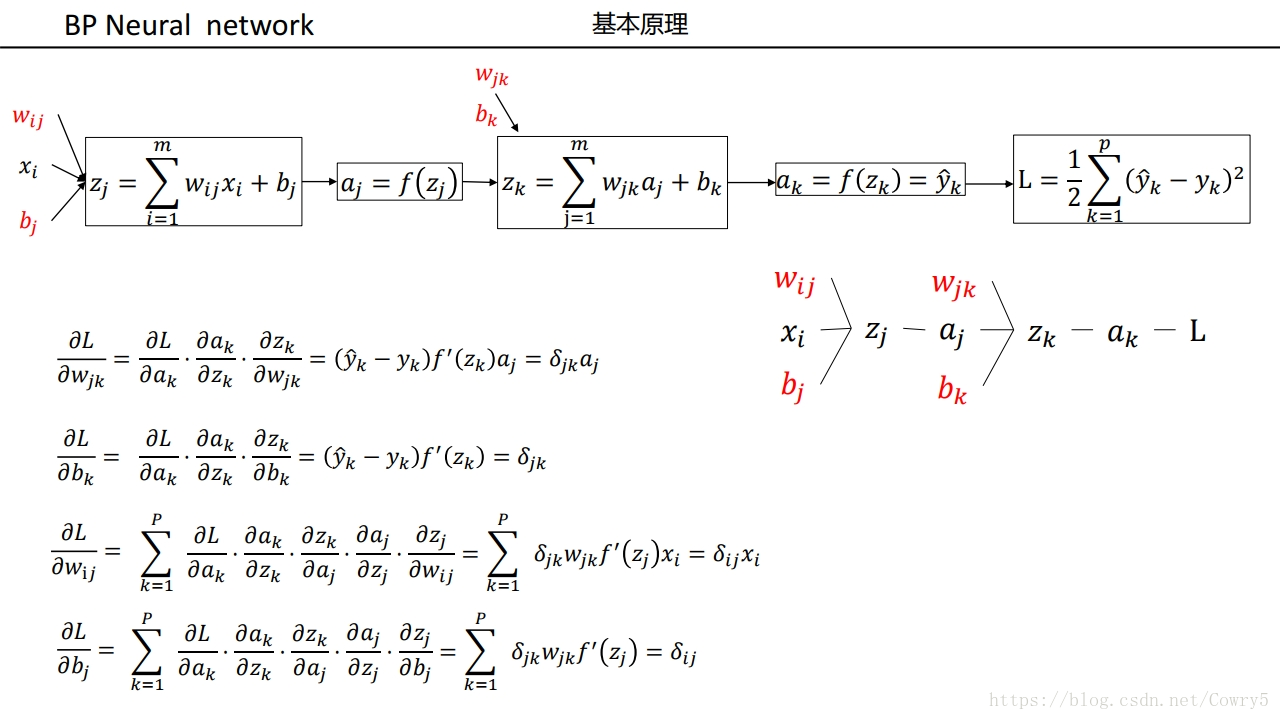
公式推导
1. 求偏导
E = 1 2 ( Y − Y ^ ) 2 = 1 2 ∑ k = 1 m ( y k − a k 3 ) 2 E=\frac{1}{2}(Y-\hat{Y})^2=\frac{1}{2}\sum_{k=1}^m(y_k-a_k^3)^2 E=21(Y−Y^)2=21∑k=1m(yk−ak3)2
我们知道一点的梯度就是这里的一阶偏导,因此对w求偏导即可:
KaTeX parse error: Undefined control sequence: \part at position 29: …k}=-\eta \frac{\̲p̲a̲r̲t̲ ̲E}{\part w_{jk}…
KaTeX parse error: Undefined control sequence: \part at position 29: …^1=-\eta \frac{\̲p̲a̲r̲t̲ ̲E}{\part w_{ij}…
w i j 1 w^1_{ij} wij1表示隐藏层权值, Δ v i j 1 \Delta v_{ij}^1 Δvij1表示输出层权值
负号表示梯度下降, η \eta η表示学习率
2.利用链式法则
KaTeX parse error: Undefined control sequence: \part at position 28: …k}=-\eta \frac{\̲p̲a̲r̲t̲ ̲E}{\part w_{jk}…
3. 定义误差信号
为了看起来方便,我们对输出层和隐层各定义一个误差信号 e e e
KaTeX parse error: Undefined control sequence: \part at position 32: …{k}^{o}=-\frac{\̲p̲a̲r̲t̲ ̲E}{\part z^3_k}…
权值调整为
Δ w j k = η ⋅ δ k o ⋅ a j 2 Δ v i j = η ⋅ δ j h ⋅ a i 1 \Delta w_{jk}=\eta \cdot \delta_{k}^{o}\cdot a^2_j \\ \Delta v_{ij}=\eta \cdot \delta_{j}^{h}\cdot a^1_i Δwjk=η⋅δko⋅aj2Δvij=η⋅δjh⋅ai1
4. 再次使用链式法则
KaTeX parse error: Undefined control sequence: \part at position 23: …{k}^{o}=-\frac{\̲p̲a̲r̲t̲ ̲E}{\part z^3_k}…
KaTeX parse error: Undefined control sequence: \part at position 23: …{j}^{h}=-\frac{\̲p̲a̲r̲t̲ ̲E}{\part z^2_j}…
替换变量KaTeX parse error: Undefined control sequence: \part at position 7: \frac{\̲p̲a̲r̲t̲ ̲E}{\part a^3_k}
E = 1 2 ∑ k = 1 m ( y k − a k 3 ) 2 E=\frac{1}{2}\sum_{k=1}^m(y_k-a_k^3)^2 E=21∑k=1m(yk−ak3)2
KaTeX parse error: Undefined control sequence: \part at position 7: \frac{\̲p̲a̲r̲t̲ ̲E}{\part a^3_k}…
替换变量KaTeX parse error: Undefined control sequence: \part at position 7: \frac{\̲p̲a̲r̲t̲ ̲E}{\part a^2_j}
KaTeX parse error: Undefined control sequence: \part at position 8: \frac{\̲p̲a̲r̲t̲ ̲E}{\part a^2_j}…
最终
KaTeX parse error: Undefined control sequence: \part at position 79: …_k^3) \\ \frac{\̲p̲a̲r̲t̲ ̲E}{\part a^2_j}…
5. 使用上面的公式带入其中
Δ w j k = η ⋅ δ k o ⋅ a j 2 = η ( y k − a k 3 ) f ′ ( z k 3 ) a j 2 Δ v i j = η ⋅ δ j h ⋅ a i 1 = η ( ∑ k = 1 l δ k o ⋅ w j k ) f ′ ( z j 2 ) a i 1 \Delta w_{jk}=\eta \cdot \delta_{k}^{o}\cdot a^2_j=\eta (y_k-a_k^3)f^\prime(z^3_k) a_j^2 \\ \Delta v_{ij}=\eta \cdot \delta_{j}^{h}\cdot a^1_i=\eta (\sum_{k=1}^l\delta_{k}^{o}\cdot w_{jk})f^\prime(z^2_j) a^1_i Δwjk=η⋅δko⋅aj2=η(yk−ak3)f′(zk3)aj2Δvij=η⋅δjh⋅ai1=η(k=1∑lδko⋅wjk)f′(zj2)ai1
3.3.4 通用公式
通用公式
反向传播算法伪代码
训练集 { ( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , ⋯ , ( x ( m ) , y ( m ) ) } \{(x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),\cdots,(x^{(m)},y^{(m)})\} { (x(1),y(1)),(x(2),y(2)),⋯,(x(m),y(m))}
f o r i = 1 t o m for\ i=1\ to\ m for i=1 to m
-
对于训练集中的每个样本 x x x,设置输入层(Input layer)对应的激活值令 a ( 1 ) = x ( i ) a^{(1)}=x^{(i)} a(1)=x(i)
-
前向传播,计算出所有的 a ( l ) , z ( l ) a^{(l)},z^{(l)} a(l),z(l)
-
计算输出层产生的错误 δ L = ( a L − y ) ⋅ g ′ ( z ( L ) ) \delta^L=(a^L-y)\cdot g^\prime(z^{(L)}) δL=(aL−y)⋅g′(z(L))
-
反向传播错误 δ l = ( ( w l + 1 ) T δ l + 1 ) ⋅ g ′ ( z l ) \delta^l=((w^{l+1})^T\delta^{l+1})\cdot g^\prime(z^l) δl=((wl+1)Tδl+1)⋅g′(zl)
-
使用梯度下降(gradient descent),训练参数
Δ i j ( l ) = Δ i j ( l ) + a j ( l ) δ i ( l + 1 ) \Delta_{ij}^{(l)}=\Delta_{ij}^{(l)}+a_j^{(l)}\delta_i^{(l+1)} Δij(l)=Δij(l)+aj(l)δi(l+1)
D i j ( l ) = 1 m Δ i j ( l ) + λ θ i j ( l ) , i f j ≠ 0 D_{ij}^{(l)}=\frac{1}{m}\Delta_{ij}^{(l)}+\lambda \theta_{ij}^{(l)},if \ j\ne 0 Dij(l)=m1Δij(l)+λθij(l),if j=0
D i j ( l ) = 1 m Δ i j ( l ) , i f j = 0 D_{ij}^{(l)}=\frac{1}{m}\Delta_{ij}^{(l)},if \ j= 0 Dij(l)=m1Δij(l),if j=0
∂ J ( θ ) ∂ θ i j ( l ) = D i j ( l ) \frac{\partial J(\theta)}{\partial \theta_{ij}^{(l)}}=D_{ij}^{(l)} ∂θij(l)∂J(θ)=Dij(l)
3.3.5 例子
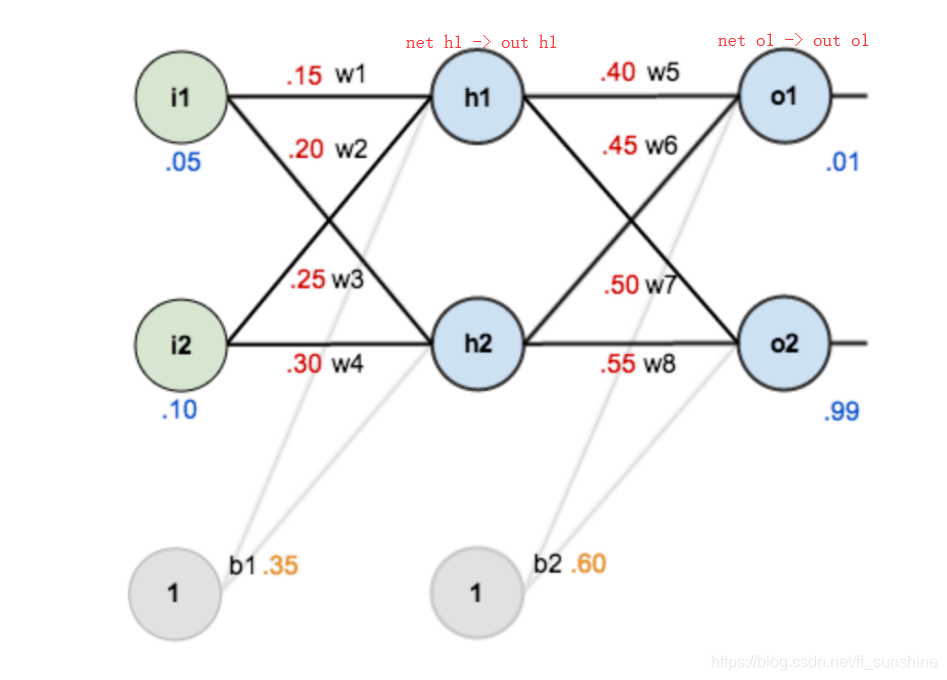
下面是前向(前馈)运算(激活函数为sigmoid):
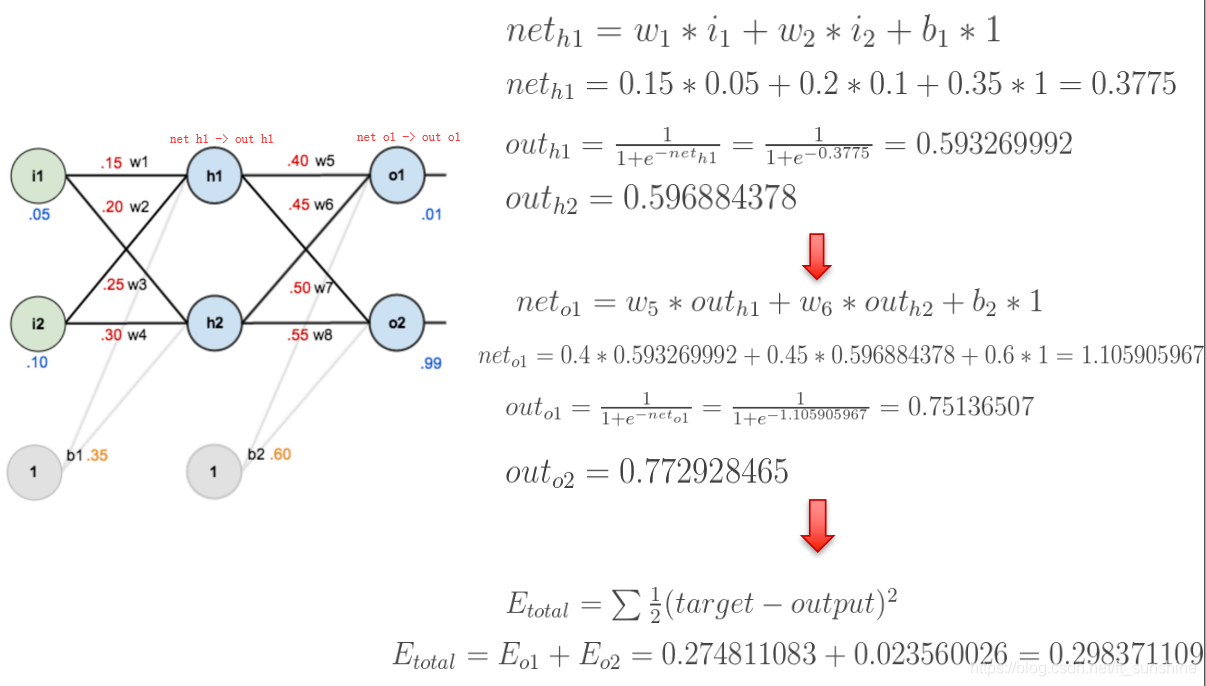
下面是反向传播(求网络误差对各个权重参数的梯度):
我们先来求最简单的,求误差E对w5的导数。首先明确这是一个“链式求导”过程,要求误差E对w5的导数,需要先求误差E对out o1的导数,再求out o1对net o1的导数,最后再求net o1对w5的导数,经过这个链式法则,我们就可以求出误差E对w5的导数(偏导),如下图所示:

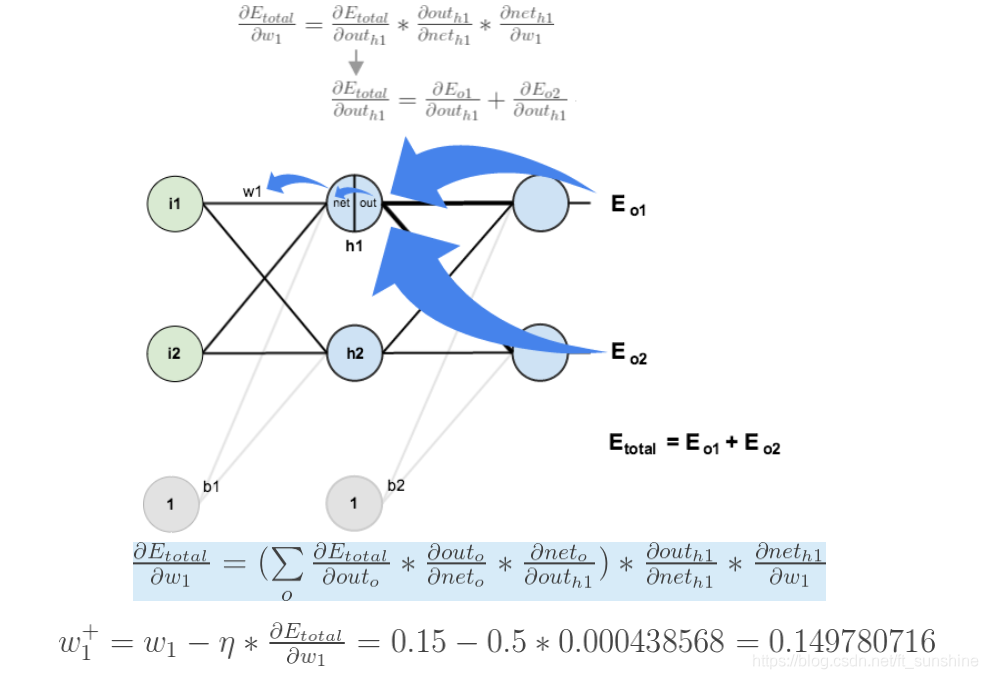
导数(梯度)已经计算出来了,下面就是反向传播与参数更新过程:

上面的图已经很显然了,如果还看不懂真的得去闭门思过了(开玩笑~),耐心看一下上面的几张图,一定能看懂的。
如果要想求误差E对w1的导数,误差E对w1的求导路径不止一条,这会稍微复杂一点,但换汤不换药,计算过程如下所示:
3.4 BP神经网络优缺点
BP网络优点:
-
非线性映射能力:BP神经网络实质上实现了一个从输入到输出的映射功能,数学理论证明三层的神经网络就能够以任意精度逼近任何非线性连续函数。这使得其特别适合于求解内部机制复杂的问题,即BP神经网络具有较强的非线性映射能力。
-
自学习和自适应能力:BP神经网络在训练时,能够通过学习自动提取输出、输出数据间的“合理规则”,并自适应的将学习内容记忆于网络的权值中。即BP神经网络具有高度自学习和自适应的能力。
-
泛化能力:所谓泛化能力是指在设计模式分类器时,即要考虑网络在保证对所需分类对象进行正确分类,还要关心网络在经过训练后,能否对未见过的模式或有噪声污染的模式,进行正确的分类。也即BP神经网络具有将学习成果应用于新知识的能力。
-
容错能力:BP神经网络在其局部的或者部分的神经元受到破坏后对全局的训练结果不会造成很大的影响,也就是说即使系统在受到局部损伤时还是可以正常工作的。即BP神经网络具有一定的容错能力。
BP网络缺点:
- 局部极小化问题:从数学角度看,传统的 BP神经网络为一种局部搜索的优化方法,它要解决的是一个复杂非线性化问题,网络的权值是通过沿局部改善的方向逐渐进行调整的,这样会使算法陷入局部极值,权值收敛到局部极小点,从而导致网络训练失败。加上BP神经网络对初始网络权重非常敏感,以不同的权重初始化网络,其往往会收敛于不同的局部极小,这也是很多学者每次训练得到不同结果的根本原因。
- BP 神经网络算法的收敛速度慢:由于BP神经网络算法本质上为梯度下降法,它所要优化的目标函数是非常复杂的,因此,必然会出现“锯齿形现象”,这使得BP算法低效;又由于优化的目标函数很复杂,它必然会在神经元输出接近0或1的情况下,出现一些平坦区,在这些区域内,权值误差改变很小,使训练过程几乎停顿;BP神经网络模型中,为了使网络执行BP算法,不能使用传统的一维搜索法求每次迭代的步长,而必须把步长的更新规则预先赋予网络,这种方法也会引起算法低效。以上种种,导致了BP神经网络算法收敛速度慢的现象。
- BP 神经网络结构选择不一:BP神经网络结构的选择至今尚无一种统一而完整的理论指导,一般只能由经验选定。网络结构选择过大,训练中效率不高,可能出现过拟合现象,造成网络性能低,容错性下降,若选择过小,则又会造成网络可能不收敛。而网络的结构直接影响网络的逼近能力及推广性质。因此,应用中如何选择合适的网络结构是一个重要的问题。
- 应用实例与网络规模的矛盾问题:BP神经网络难以解决应用问题的实例规模和网络规模间的矛盾问题,其涉及到网络容量的可能性与可行性的关系问题,即学习复杂性问题。
- BP神经网络预测能力和训练能力的矛盾问题:预测能力也称泛化能力或者推广能力,而训练能力也称逼近能力或者学习能力。一般情况下,训练能力差时,预测能力也差,并且一定程度上,随着训练能力地提高,预测能力会得到提高。但这种趋势不是固定的,其有一个极限,当达到此极限时,随着训练能力的提高,预测能力反而会下降,也即出现所谓“过拟合”现象。出现该现象的原因是网络学习了过多的样本细节导致,学习出的模型已不能反映样本内含的规律,所以如何把握好学习的度,解决网络预测能力和训练能力间矛盾问题也是BP神经网络的重要研究内容。
- BP神经网络样本依赖性问题:网络模型的逼近和推广能力与学习样本的典型性密切相关,而从问题中选取典型样本实例组成训练集是一个很困难的问题。
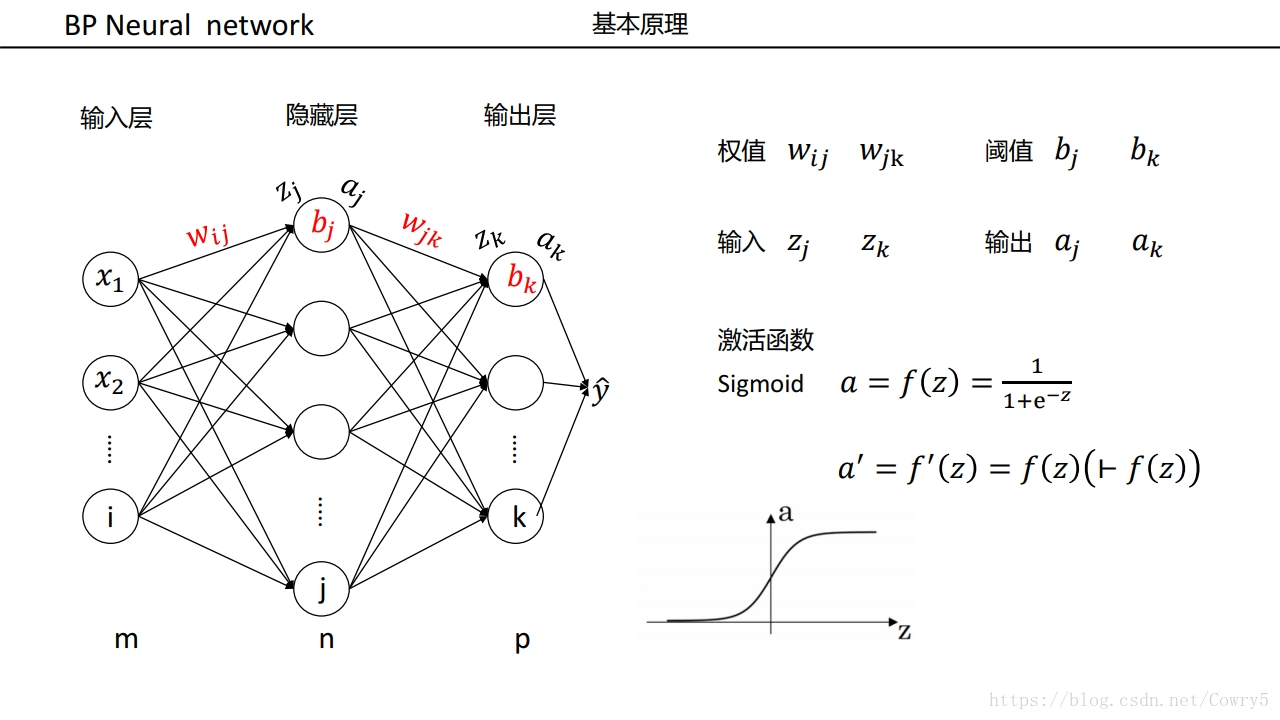
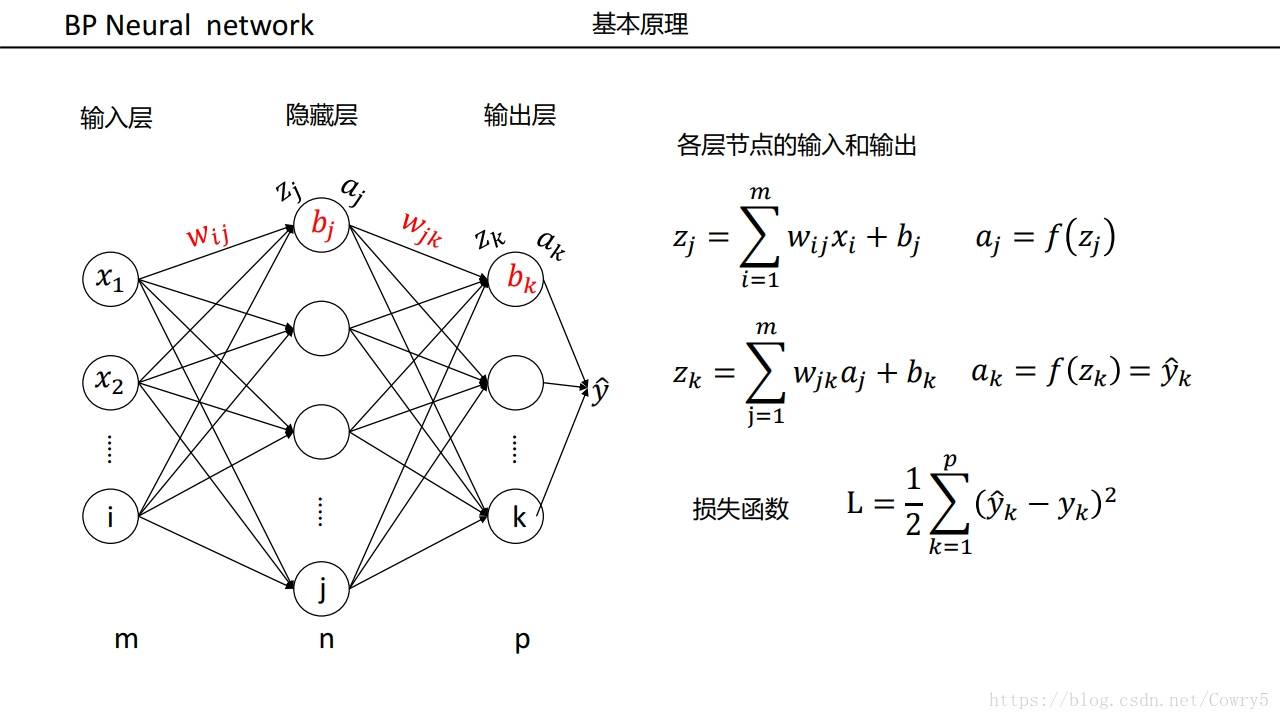
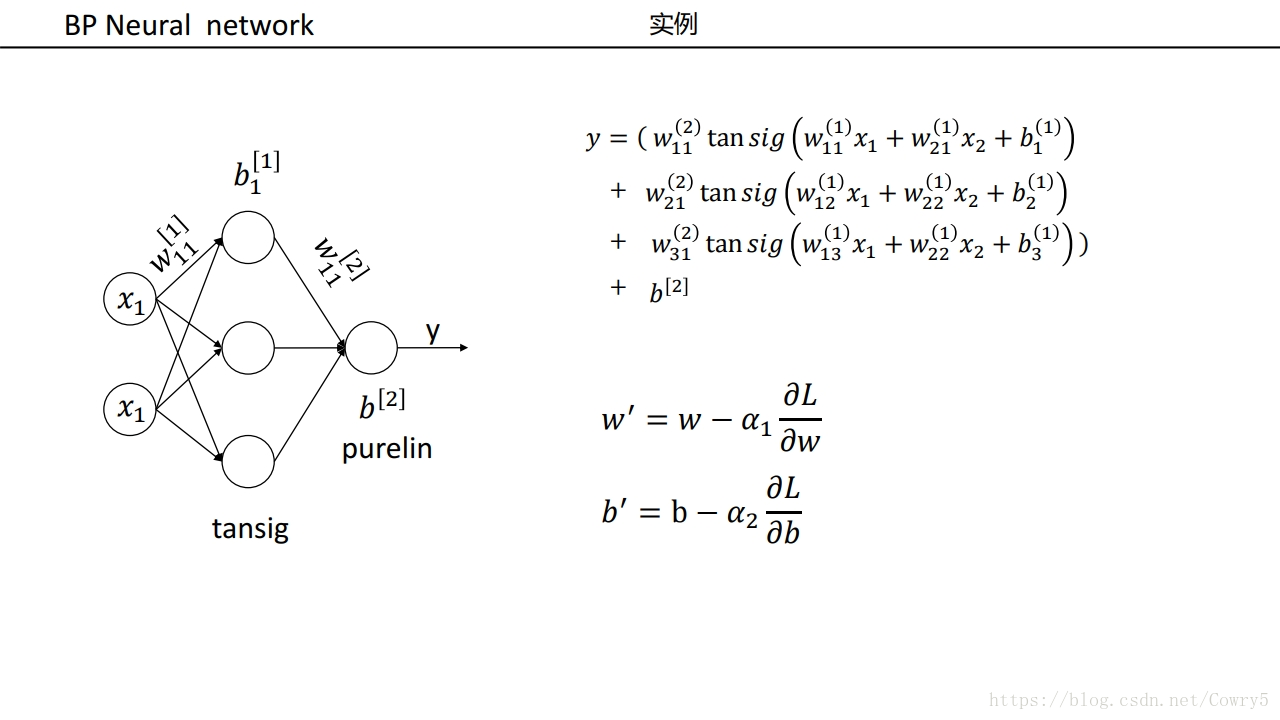
3.5 例子

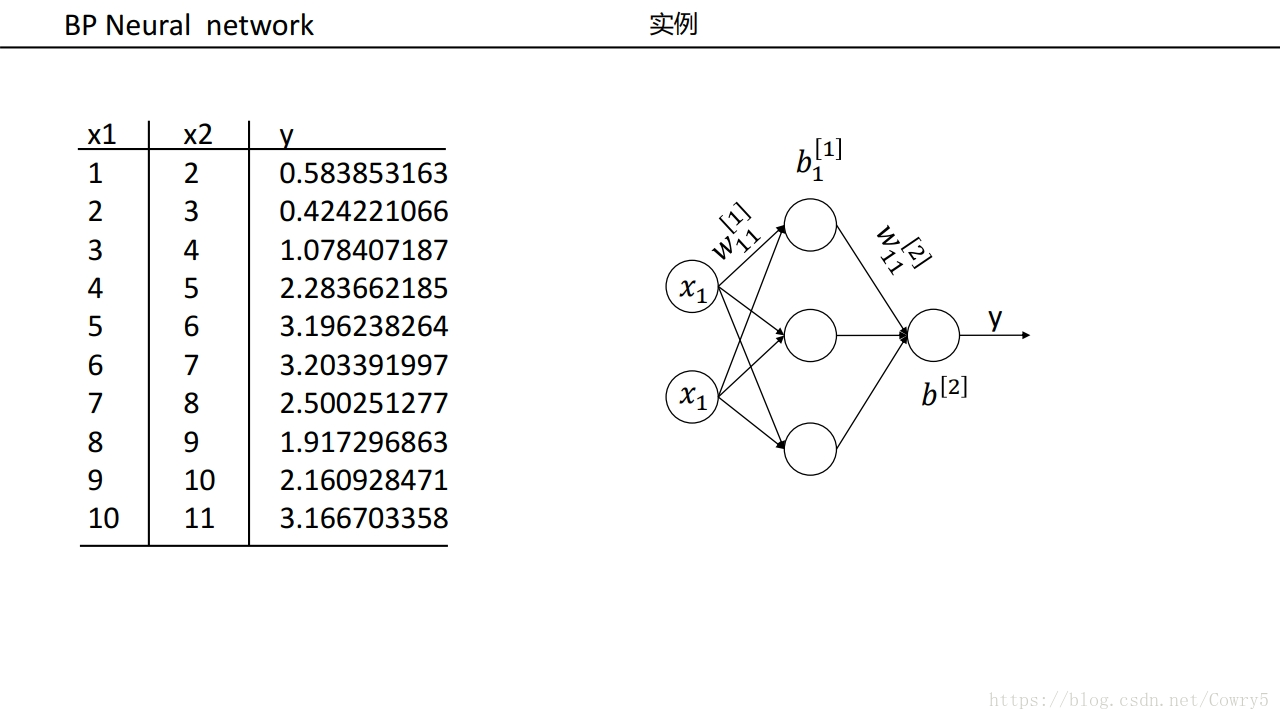

3.6 其他流程讲解(没写成功)
3.6.1 文字流程
- 将训练集数据输入到神经网络的输入层,经过隐藏层,最后达到输出层并输出结果,这就是前向传播过程。
- 由于神经网络的输出结果与实际结果有误差,则计算估计值与实际值之间的误差,并将该误差从输出层向隐藏层反向传播,直至传播到输入层;
- 在反向传播的过程中,根据误差调整各种参数的值(相连神经元的权重),使得总损失函数减小。
- 迭代上述三个步骤(即对数据进行反复训练),直到满足停止准则。
3.6.2 矩阵讲解反向传播
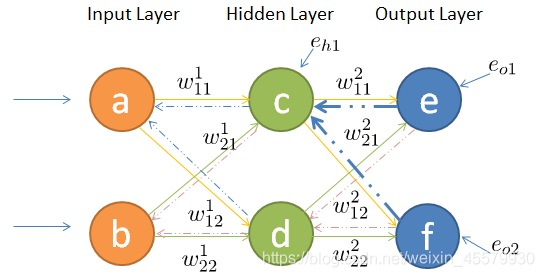
- w j k l w^l_{jk} wjkl代表的是第l层的第j个神经元,与上一层 ( l − 1 ) (l-1) (l−1)第k个神经元输出相对应的权重
- a j l a_j^l ajl代表在第 l l l层上,第 j j j个神经元的输出
- z j l z_j^l zjl代表在第 l l l层上,第 j j j个神经元的输入
- b j l b_j^l bjl代表在第 l l l层上,第 j j j个神经元的偏置
- W W W代表权重举证, Z l Z^l Zl代表 l l l层输入矩阵
- A l A^l Al代表第l层输出矩阵, Y ^ \hat{Y} Y^代表最终输出矩阵, Y Y Y代表标准答案
- l l l表示神经网络的层数
- W = [ w 11 2 w 21 2 w 12 2 w 22 2 ] W=\begin{bmatrix}w_{11}^2&w_{21}^2\\ w_{12}^2&w_{22}^2\end{bmatrix} W=[w112w122w212w222]
- e o i e_{oi} eoi代表输出层第 i i i个神经元误差, e h i e_{hi} ehi代表隐藏层第i个神经元误差, e l i e_{li} eli代表输入层第 i i i个神经元误差
- E o E_o Eo表示输出层误差矩阵, E h E_h Eh隐藏层误差矩阵, E l E_l El输入层误差矩阵
- 对于3层神经网络 Y ^ = A 3 \hat{Y}=A^3 Y^=A3
W 1 W^1 W1表示隐藏层的权值矩阵
W 2 W^2 W2表示输出层的权值矩阵
B B B表示偏置矩阵
-
既然梯度下降需要每一层都有明确的误差才能更新参数,所以接下来的重点是如何将输出层的误差反向传播给隐藏层。
-
其中输出层、隐藏层节点的误差如图所示,输出层误差已知,接下来对隐藏层第一个节点c作误差分析。还是站在节点c上,不同的是这次是往前看(输出层的方向),可以看到指向c节点的两个蓝色粗箭头是从节点e和节点f开始的,因此对于节点c的误差肯定是和输出层的节点e和f有关。
-
因此对于隐藏层节点c的误差为:
e h 1 = w 11 2 w 11 2 + w 21 2 e o 1 + w 12 2 w 12 2 + w 22 2 e o 2 e_{h1}=\frac{w_{11}^2}{w_{11}^2+w_{21}^2}e_{o1}+\frac{w_{12}^2}{w_{12}^2+w_{22}^2}e_{o2} eh1=w112+w212w112eo1+w122+w222w122eo2 -
同理,对于隐藏层节点d的误差为:
e h 2 = w 21 2 w 11 2 + w 21 2 e o 1 + w 22 2 w 12 2 + w 22 2 e o 2 e_{h2}=\frac{w_{21}^2}{w_{11}^2+w_{21}^2}e_{o1}+\frac{w_{22}^2}{w_{12}^2+w_{22}^2}e_{o2} eh2=w112+w212w212eo1+w122+w222w222eo2 -
为了减少工作量,我们还是乐意写成矩阵相乘的形式:
[ e h 1 e h 2 ] = [ w 11 2 w 11 2 + w 21 2 w 12 2 w 11 2 + w 22 2 w 21 2 w 11 2 + w 21 2 w 22 2 w 12 2 + w 22 2 ] ⋅ [ e o 1 e o 2 ] \begin{bmatrix}e_{h1}\\ e_{h2}\end{bmatrix}=\begin{bmatrix}\frac{w_{11}^2}{w_{11}^2+w_{21}^2}&\frac{w_{12}^2}{w_{11}^2+w_{22}^2}\\ \frac{w_{21}^2}{w_{11}^2+w_{21}^2}&\frac{w_{22}^2}{w_{12}^2+w_{22}^2}\end{bmatrix}\cdot \begin{bmatrix}e_{o1}\\ e_{o2}\end{bmatrix} [eh1eh2]=⎣⎡w112+w212w112w112+w212w212w112+w222w122w122+w222w222⎦⎤⋅[eo1eo2] -
你会发现这个矩阵比较繁琐,如果能够简化到前向传播那样的形式就更好了。实际上我们可以这么来做,只要不破坏它们的比例就好,因此我们可以忽略掉分母部分,所以重新成矩阵形式为:
[ e h 1 e h 2 ] = [ w 11 2 w 12 2 w 21 2 w 22 2 ] ⋅ [ e o 1 e o 2 ] \begin{bmatrix}e_{h1}\\ e_{h2}\end{bmatrix}=\begin{bmatrix}w_{11}^2&w_{12}^2\\ w_{21}^2&w_{22}^2\end{bmatrix}\cdot \begin{bmatrix}e_{o1}\\ e_{o2}\end{bmatrix} [eh1eh2]=[w112w212w122w222]⋅[eo1eo2] -
仔细观察,你会发现这个权重矩阵,其实是前向传播时权重矩阵w的转置,因此简写形式如下:
E h = W 2 T E o E_h=W_2^TE_o Eh=W2TEo
-
不难发现,输出层误差在转置权重矩阵的帮助下,传递到了隐藏层,这样我们就可以利用间接误差来更新与隐藏层相连的权重矩阵。