亲爱的同学们,我们的世界是3D世界,我们的双眼能够观测三维信息,帮助我们感知距离,导航避障,从而翱翔于天地之间。而当今世界是智能化的世界,我们的科学家们探索各种机器智能技术,让机器能够拥有人类的三维感知能力,并希望在速度和精度上超越人类,比如自动驾驶导航中的定位导航,无人机的自动避障,测量仪中的三维扫描等,都是高智机器智能技术在3D视觉上的具体实现。
立体视觉是三维重建领域的重要方向,它模拟人眼结构用双相机模拟双目,以透视投影、三角测量为基础,通过逻辑复杂的同名点搜索算法,恢复场景中的三维信息。它的应用十分之广泛,自动驾驶、导航避障、文物重建、人脸识别等诸多高科技应用都有它关键的身影。
本课程将带大家由浅入深的了解立体视觉的理论与实践知识。我们会从坐标系讲到相机标定,从被动式立体讲到主动式立体,甚至可能从深度恢复讲到网格构建与处理,感兴趣的同学们,来和我一起探索立体视觉的魅力吧!
本课程是电子资源,所以行文并不会有太多条条框框的约束,但会以逻辑清晰、浅显易懂为目标,水平有限,若有不足之处,还请不吝赐教!
个人微信:EthanYs6,加我申请进技术交流群 StereoV3D,一起技术畅聊。
CSDN搜索 :Ethan Li 李迎松,查看网页版课程。
随课代码,将上传至github上,地址:StereoV3DCode:https://github.com/ethan-li-coding/StereoV3DCode
前两篇博主介绍了两种单相机标定方法,有同学一定会有所疑惑,本系列明明是立体视觉,为什么要介绍单相机标定而不是双相机标定呢?原因很简单,那就是单相机标定是双相机标定的基础,具体来说,双相机标定正是先分别完成两个单相机的标定,再进行整体标定的。且听我娓娓道来~
双视立体
有一个常识性认知,即立体视觉一般而言是指双相机组成的立体系统,就像人眼一样。当两个相机拍摄的视图之间存在重叠区,它们便形成了基本的双视立体。

双视图通过极线校正和立体匹配,可以通过三角关系得到三维点,

但这一切实现的前提:
- 要准确的知道双相机之间的位置关系,即其中一个相机对于另一个相机的旋转 R R R和平移 t t t,即相机的外参数
- 要准确的知道双相机内部的设备参数,比如像主点 ( x 0 , y 0 ) (x_0,y_0) (x0,y0)、焦距 f f f、畸变参数等,即相机的内参数
关于内外参数的介绍,请看前篇:立体视觉入门指南(1):坐标系与相机参数
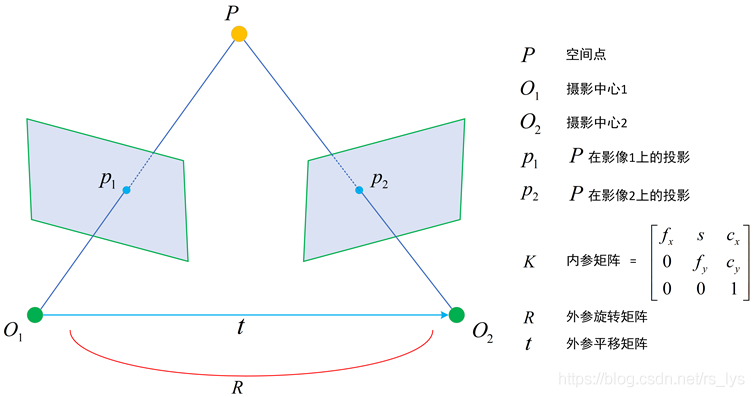
双相机标定
一般情况下,我们所见到的最多的双视立体,由两个不同的相机固定在刚性的结构上,构成稳定的双目立体系统。在使用过程中,相机之间不会有明显的相互移动,稳定的双视结构可以在任意时刻完成单帧深度信息的获取。下图为一些示例:

|

|

|
前面我们说到,单相机可以得到相机内参矩阵 K K K、外参矩阵 R , t R,t R,t,而双相机标定相比单相机标定来说
- 多了一个相对外参,即右相机相对于左相机的旋转矩阵 R R R 和平移向量 t t t。
- 少了两个绝对外参,即单相机自身标定出来的外参矩阵不再需要了,即只保留1得到的相对外参,称之为立体视觉系统的外参。(实际上单相机标定一般也不需要绝对外参,只是作为标定的输出自然产出,在双相机标定中,绝对外参可以作为中间变量计算相对外参)
我们在文章开头说到,双相机标定是基于单相机标定做的,我想聪明的同学已经想到了一部分思路,首先我们采用同样的拍摄方法采集标定标定图案,大部分操作方式和注意点都是一样的,详见立体视觉入门指南(3):相机标定之张式标定法【超详细值得收藏】
不同的地方在于:
- 每一次拍摄时,要注意两个相机的重叠区是否足够,一般超过1/2的图像区域就可以了,当然越大越好,在一些偏的较大的角度下,可以牺牲一定的重叠度。
- 注意两个相机尽量保持在统一的距离下采集,这样是为了保证两个视图的尺度和清晰度一致,减小不一致带来的误差。
示意图:
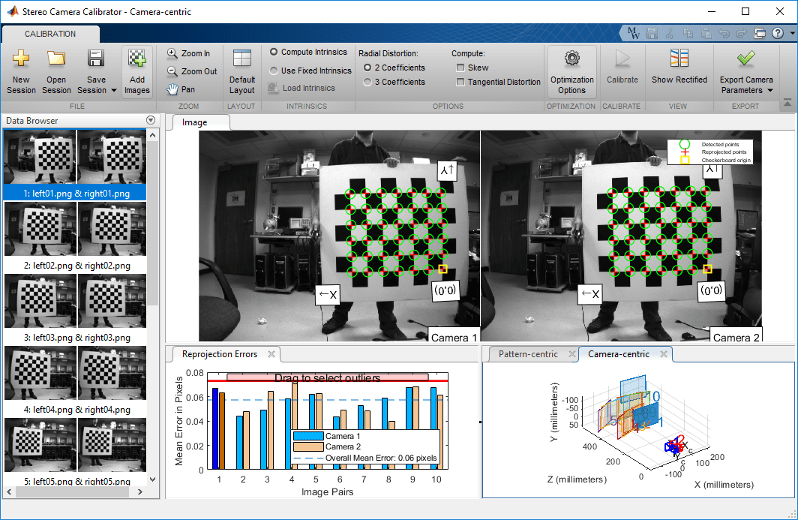
算法部分
图像采集后,进入算法部分,如前所述,第一步我们对两个相机单独做单相机标定,得到两个相机各自的内参矩阵K、绝对外参 R , t R,t R,t(即每次采集时相机相对于标定板的外参),和畸变系数 d d d(这里的 d d d是所有畸变系数的集合)
1. 对两个相机单独做单相机标定,得到两个相机各自的内参矩阵K、绝对外参 R , t R,t R,t,和畸变系数 d d d
然后有的同学可能想到了,根据每次采集的绝对外参,即可以计算出相对外参,但是显然我们会生成N个相对外参(N是采集的像对数量,也就是采集位置数),取哪一个好呢?取均值?还是取中值?
有经验的同学会发现,这两种都不太可靠,首先取均值就对显著性异常值毫无鲁棒性,只要某一对的绝对外参求错了,均值就影响很大;其次取中值由于只取某一对,又没有利用到多次测量的误差平均特性。
所以比较可靠的做法是,计算每次采集的相对外参,并取中值作为初值,再基于最小化重投影误差,非线性迭代优化得到最优解。在此方案下,相机的内参可以做为固定值,未知数为N组左相机的绝对外参 ( R i , t i ) , i = 1 , . . n (R_i,t_i),i=1,..n (Ri,ti),i=1,..n、1组右相对相对于左相机的相对外参 R ′ , t ′ R',t' R′,t′。最小重投影误差方程和单相机标定一样,只是右相机的绝对外参通过左相机的绝对外参和相对外参计算得到。
2. 计算每次采集的相对外参,并取中值作为初值,再基于最小化重投影误差,非线性迭代优化得到最优解
由于第二次迭代优化时,相机内参是固定的,外参个数也减少了且有较为准确的初值,所以迭代会相对更容易收敛且更精确。
总结
立体视觉通过立体匹配计算深度的前提:
- 要准确的知道相机之间的位置关系,即其中一个相机对于另一个相机的旋转 R R R和平移 t t t,即相机的外参数
- 要准确的知道相机内部的设备参数,比如像主点 ( x 0 , y 0 ) (x_0,y_0) (x0,y0)、焦距 f f f、畸变参数等,即相机的内参数
双相机标定相比单相机标定来说:
- 多了一个相对外参,即右相机相对于左相机的旋转矩阵 R R R 和平移向量 t t t。
- 少了两个绝对外参,即单相机自身标定出来的外参矩阵不再需要了,即只保留1得到的相对外参,称之为立体视觉系统的外参。
双相机图像采集的相比单相机图像采集不同的地方在于:
- 每一次拍摄时,要注意两个相机的重叠区是否足够,一般超过1/2的图像区域就可以了,当然越大越好,在一些偏的较大的角度下,可以牺牲一定的重叠度。
- 注意两个相机尽量保持在统一的距离下采集,这样是为了保证两个视图的尺度和清晰度一致,减小不一致带来的误差。
双相机标定算法步骤:
- 对两个相机单独做单相机标定,得到两个相机各自的内参矩阵K、绝对外参 R , t R,t R,t,和畸变系数 d d d
- 计算每次采集的相对外参,并取中值作为初值,再基于最小化重投影误差,非线性迭代优化得到最优解
所以你

作业
这里为大家准备了一些练习题,可以通过实践加深理解:
1 通过opencv开源库提供的接口完成双相机标定。
2 更高阶的是,你能够自己不依赖opencv库写一套双相机标定算法吗?或者只使用opencv来检测角点坐标,其他步骤自己来实现。
参考答案地址:https://github.com/ethan-li-coding/StereoV3DCode [不好意思放了,代码其实很久没更新了,但是你相信我有一天会更的对吗?]