Bag of Freebies for Training Object Detection Neural Networks
Abstract
本文和cls一样都是由AWS发出,找到了财富密码,多的不说,就是干饭sota,对于论文里面的表格真是有必要学习的,对于几个点的增加,只要缩小y轴距离看着就很明显了。总的来说在复杂的目标检测任务下,数据至关重要。其中论文中提到的以下点贡献
- 系统地评估了各种训练trick对目标检测模型的影响
- 设计了一种用于目标检测的image mix up,该方法能提高模型的泛化能力
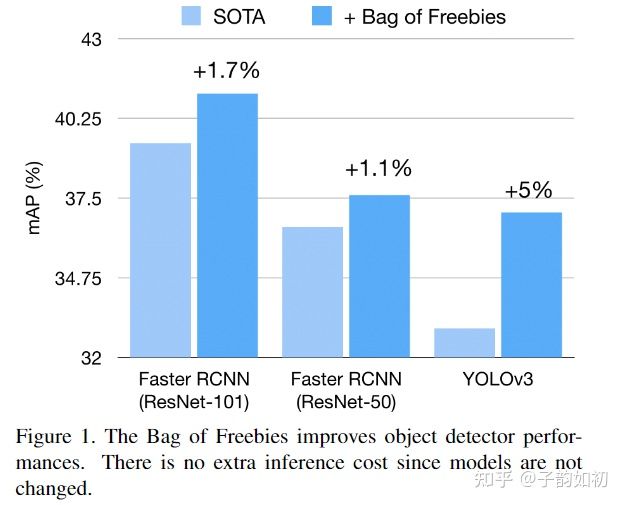
- 在不修改网络结构的情况下,可以实现高达5%的精度提升,这些改进不会带来额外的推理开销,且bof能够用于各种模型架构
Algorithm
OBJ MIX UP
之前的mix up将one-hot标签乘以相应的比例,结构一个one-hot标签。

作者提出在混合过程中,为了避免图像变形,保留了图像的几何形状。并将两个图像的标签合并为一个新的数组,而不是跟cls一样直接mixup。
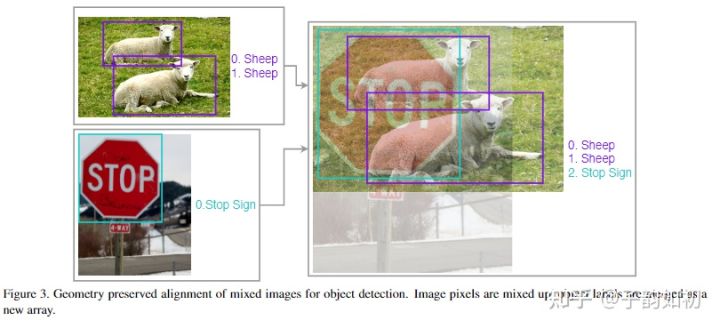
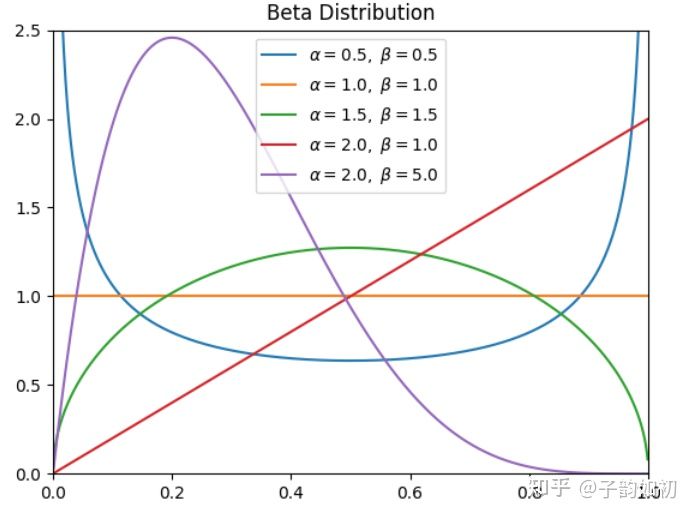
同时,作者采用了参数α和β都至少为1的beta分布,X为随机变量,Y为对应的概率,总的面积为1,这样在视觉上更加连贯。当α和β都等于1.5时效果最好,与baseline相比mAP提升了3%。

Classification Head Label Smoothing
可参考子韵如初:Paper Reading - 基础系列 - Tricks for Image Classification with CNN
举个例子,如果平滑系数为0.08,K=5时候,one-hot就会变成。总的来说避免模型过拟合认死理。
[0.02 0.02 0.92 0.02 0.02]Data Preprocessing
数据增强不多说,用了都说爽
- Random geometry transformation. Including random cropping (with constraints), random expansion, random horizontal flip and random resize (with random interpolation).
- Random color jittering including brightness, hue, saturation, and contrast.
Training Schedule Revamping
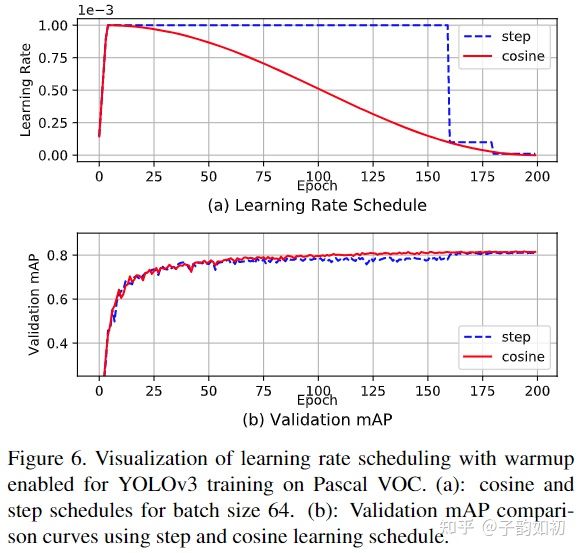
值得一提的是,分类任务中 cosine learning schedule影响不大,但是目标检测中效果不错,在复杂的任务重cosine能让loss下降更加平滑
Synchronized Batch Normalization
普通的BN是单卡的实现模式,只对单个卡上对样本进行归一化,相当于减小了批量大小(batch-size)。而跨卡同步 Batch Normalization 可以使用全局的样本进行归一化。Implementing Synchronized Multi-GPU Batch Normalization

Random shapes training for single-stage object detection networks
多尺度训练也是目标检测中对于小目标性能提升常用的trick,效果挺好。具体来说,在训练时不同batch中图片的高和宽从一组H和W中随机选取。类似的yolov3为32的倍数,因为darknet-53一共进行5次下采样操作每次特征图减半,将输出特征图缩小到输入的1/32

Experiment
值得一提的是作者论文中如此绘图确实效果不错,值得学习,红色表示有对应类别提升AP的幅度

tricks加满都很好,但是值得一提的是FasterRcnn加了数据增强反而下降了。可以看到基于proposal的两阶段检测方法在其训练中的采样过程已经优于数据增强中的随机操作,单阶段方法中则更适合使用数据增强
