-
前言
本文开始对零知识证明应用最广泛的技术——zkSNARKs进行介绍,本文主要介绍其原理与流程,其中应用到的密码学知识和工具很多,本人能力有限,尽量做到阐述清晰,如有错误欢迎讨论。
零知识证明学习起来难度很大,是数论、密码学、抽象代数的综合应用,它引入的概念、符号很多会让人眼花缭乱。V神在一篇介绍零知识证明的文章中就提醒读者看不懂也不要怀疑自己的智商,因为“它实在是太难了!” 因此,能坚持搞懂的,一定是意(固)志(执)力有异常人。所以在学习过程中要保持耐心,慢慢来。
本人在学习过程中主要参考了“安比实验室”、“星想法”、向程@HUST、Vitalik等许多优秀平台或个人的文章,不敢说全部看懂,只掌握了zkSNARKs的基本原理、流程以及部分优化方案,希望对zkSNARKs感兴趣的小伙伴能在理解本文的基础上,理解上述前辈们的文章,进而完全掌握zkSNARKs。写了有1万多字,希望是有价值的干货。
-
什么是zk-SNARKs
zk-SNARK表示“Zero-Knowledge Succinct Non-Interactive Argument of Knowledge”,即零知识简明非交互式知识,这一长串名字的主体是“argument of knowledge”,即“知情证明”,也就是掌握某知识的证据。修饰主体由三部分组成,分别代表了此技术要解决的三个问题,分别是:
- zero knowledge:零知识,证明某个陈述为真但不揭露任何其他信息。
- succinct:简洁的,表示证明大小很短且易于验证。
- non-interactive:无交互。上篇文章深入浅出零知识证明(一):Schnorr协议,交互式schnorr协议需要verifier生成一个随机数,故而是交互证明,而非交互式schnorr协议,则不需要这样的角色,prover可以自行生成证明,给所有人验证。
再来解释下“argument of knowledge”:
- arguments:注意这里没有用proofs这个词,proof(证明)和argument(论证)在零知识证明里,是有区别的,在proof system中,即便是计算能力无限的prover也没法欺骗verifier去相信一个错误的陈述为真(统计可靠性),而在argument system中,只有多项式时间计算能力的没法欺骗(计算可靠性),假设能破解椭圆曲线离散对数问题,那么可能就不再安全。
- of Knowledge:如果prover没有相应的witness(证据),那么构建相应的proof(对于proof system)或argument(对于argument system)是不可能的。
下面开始zk-SNARK原理的介绍。
-
zk-SNARK原理
1.NP与QAP
通俗来讲,P问题即为在多项式时间内可解的一类问题,而NP问题属于在多项式时间内不可解,但是给定一个解,可以在多项式时间内验证解是否正确的一类问题,此外还有NP完全问题,属于NP问题中最难的一种,任何NP问题都可以归约(Reduction)到一个NP完全问题,所以只要找到了一个NP完全问题的多项式时间解法,由于可以相互归约,相当于解决了所有的NP问题。
zkSNARKs是基于NP问题的,因为如果是一个P问题的话,那么直接求解就行了,证明就无从谈起,所以zkSNARKs的依托于某种NP问题,很难求解但是可以快速验证。它作为一种数学方法,不能直接用于解决任何计算问题,我们必须先把问题转换成正确的“形式”来处理,这种形式叫做 "quadratic arithmetic problem"(QAP),在进行 QAP 转换的同时,如果你有代码的输入就可以创建一个对应的解(有时称之为 QAP 的 witness)。之后,还需要一个相当复杂的步骤来为 witness 创建实际的“零知识证明”,此外还有一个独立的过程来验证某人发送给你的证明。
首先看看QAP的形式化定义:

emmm。。。这也太复杂了吧,如果我是初学者一上来就看这个就会很晕。理解QAP问题是什么非常重要,如果不理解,你就不知道zkSNARKs做的那一系列操作是为了什么,没有一个目标或指导思想学习起来会很迷茫,下面就以“基于多项式构建零知识证明”的构建来引出QAP的具体形式。
1.1 直观版本
随机抽查,随机提供样本,对照结果。这种协议,需要通过设定随机抽查的次数,确定安全系数。这种思想和交互式Schnorr协议类似,具体可以看之前的文章深入浅出零知识证明(一):Schnorr协议。
1.2 从多项式的系数证明开始
最简单的d阶多项式,可以随机选择一个点x,让prover通过多项式计算生成y, verifier可以查看y是否正确。不同的多项式,最多有d个相交的点(相等的点)。
如果x/y的取值范围很大(设为n),在不知道原始多项式的情况下,能正确给出证明的概率比较低: d/n。多项式,能在一次交互,就能获取比较好的安全系数(如果n远大于d的话,将近100%)。比版本1,优秀不少。
这种协议还是比较简单和原始。证明建立在双方还是相互信任的基础上。本质上,prover并没有证明他/她知道多项式。证明本身并不能推出他/她知道一个确定的多项式。知道一个值,并不代表知道一个多项式。而且,如果多项式的值范围不大的话,证明者可以随机选择一个值撞概率。
1.3 基于多项式因式分解改进
假设一个多项式可以分解成:p(x)= t(x)h(x)。t(x)是目标多项式,是由p(x)的部分解组成的多项式:
![]() 。也就是说,证明者需要证明的一部分,证明者知道一个多项式的部分解。从验证者的角度看,既然你知道一个多项式的部分解,那你知道的多项式一定能整除t(x)。在随机挑选x的情况下,你都能给出正确的证明,即可认定你知道这个满足条件的多项式。
。也就是说,证明者需要证明的一部分,证明者知道一个多项式的部分解。从验证者的角度看,既然你知道一个多项式的部分解,那你知道的多项式一定能整除t(x)。在随机挑选x的情况下,你都能给出正确的证明,即可认定你知道这个满足条件的多项式。
·验证者,随机生成r,并计算出t(r),将r发送给证明者
·证明者,计算h(x) = p(x) / t(x),并给出p(r)以及h(r)
·验证者验证,是否p(r) = t(r)h(r)
该版本要求证明者,知道一个能整除t(x)的多项式。但比较容易发现,该协议存在如下的问题:
1)证明者,可以自己计算出t(r),随机生成h(r),并构造出p(r) = t(r)h(r)
2)即使不像1),证明者不考虑多项式,直接通过结果伪造证明。证明者,因为知道随机数r,证明者可以使用任何一个多项式,保证存在相同点(r, t(r)h(r))。这样,证明的p(r)和h(r)虽然和正确的证明是一样的,但是,证明者却不需要知道正确的多项式。
3)证明者,可以自己构造多项式,只要满足h(x)=p(x)/t(x)即可。
这三个问题会在后面分别解决,我们现在的重点在于QAP问题的具体形式是什么,目前看来是要证明p(x)= t(x)h(x),但这还不是最终的形式。
1.4 扩展到一般计算
如果把一个算子的左右两个输入和输出,都看作多项式的话:![]()
也就是说,![]()
可以把![]() 看成一个多项式,类似上述的p(X)。通过之前的协议,可以证明证明者知道一个多项式,但是,并没有证明这个多项式的组成方式(不一定具有
看成一个多项式,类似上述的p(X)。通过之前的协议,可以证明证明者知道一个多项式,但是,并没有证明这个多项式的组成方式(不一定具有![]() 的形式)。
的形式)。
1.5 最终版本
如果这个算子是乘法的话,并且如果随机数为s的话,![]() 。也就是说,验证者除了需要验证l,r以及o是多项式外,还需要在加密空间验证等式成立。因为在加密空间做"减"法相对麻烦,需要算逆,可以将等式稍稍变形:
。也就是说,验证者除了需要验证l,r以及o是多项式外,还需要在加密空间验证等式成立。因为在加密空间做"减"法相对麻烦,需要算逆,可以将等式稍稍变形:![]()
这样,就得到了QAP问题的多项式形式:![]()
简单总结一下QAP,给一系列的多项式以及一个目标多项式,是否能根据这一系列的多项式,求得它们的一个线性组合,刚好可以整除多项式。综合协议1-协议5,总结出一个简洁的QAP形式化定义:

综上,zkSNARKs的基本思路就是,将原问题的解转化为一个QAP问题的解,然后公开QAP问题,这样的话拥有解的人用证明公开自己拥有一个解,其他人可以简单验证证明是否成立。
接下来讲解如何将一个具体的问题转换为一个zkSNARKs能处理的问题,即QAP形式。
2.问题转化:多项式 → R1CS → QAP
以一个简单的多项式方程![]()
(这个方程的解是x=3,因为3^3+3+5 = 35)来举例说明将目标计算问题转换为一个QAP的过程。请重点观察:伴随着问题的转化,解的形式会发生什么变化。(引用“逐歌传舞”文章中的图例,并修改了有歧义的地方),流程图如下:

如上图所示,转换分三步完成:
2.1 算术电路拍平
通过引入中间变量,将计算式![]() 转换为若干简单算式 x = y 或 x (op) y= z 的形式。操作符op代表加(+)、减(-)、乘(*)和除(/)。这些简单算式可视为数字电路中的逻辑门,因此也被称为“代数电路(Algebraic Circuit)”。上图中引入的中间变量是sym_1、sym_2和sym_3,那么转化为
转换为若干简单算式 x = y 或 x (op) y= z 的形式。操作符op代表加(+)、减(-)、乘(*)和除(/)。这些简单算式可视为数字电路中的逻辑门,因此也被称为“代数电路(Algebraic Circuit)”。上图中引入的中间变量是sym_1、sym_2和sym_3,那么转化为![]() 以后,可以得到下面这个电路:
以后,可以得到下面这个电路:
sym_1 = x * x
sym_2 = sym_1 * x
sym_3 = sym_2 + x
~out = sym_3 + 5可以看出,为了将所有操作都转成 x (op) y = z 的形式,加入了sym_1 ... sym_3等中间变量。上面的形式即代数电路形式,向电路输入参数得到结果,即将代码逻辑拆成了电路的计算,计算完以后就会得到一组满足电路的值,如下图:

解的新形式:
x=3, sym_1=9, sym_2=27, sym_3=30, ~out=35(将这些变量的值代入各个简单算式,所有等式成立)2.2 电路转成R1CS
现在我们把所有变量包括中间变量组成一组向量,s=[~one, x, ~out, sym_1, sym_2, sym_3](s即为R1CS中的解向量,~one是伪变量,表示常数1),将每个简单算式转换为“s · c = s · a × s · b”的形式。其中,“·"代表向量内积(将两个向量对应位置的成员相乘,结果再累加),a、b和c是其系数向量。依次完成所有简单算式的转化,将系数向量分别顺序排列,便得到A、B和C三个矩阵(例如,矩阵C的最后一行,就是简单算式“~out = sym_3 + 5”的系数向量c)。
这个描述形式有个专门的术语,称作"一阶约束系统R1CS(rank 1 constraint system)",R1CS 是一个由三向量组 (a,b,c) 组成的序列,R1CS有一个解向量s,需要满足 s · a × s · b - s · c = 0,以流程图中红色变量的计算过程为例:
a = (5,0,0,0,0,1)
b = (1,0,0,0,0,0)
c = (0,0,1,0,0,0)
s = (1,3,35,9,27,30)这是一个满足的 R1CS,通过下图可以更直观的看出运算过程:

上述例子只有一个约束,接下来我们要将每个逻辑门(即“拍平”后的每一个声明语句)转化成一个约束(即一个三向量组),转化的方法取决于声明是什么运算 (+,-,*,/) 和声明的参数是变量还是数字。在我们这个例子中,除了“拍平”后的五个变量 ('x', '~out', 'sym_1', 'y', 'sym_2') 外,还需要在第一个分量位置处引入一个冗余变量~one来表示数字1,就我们这个系统而言,一个向量所对应的 6 个分量是:'~one',' x', '~out', 'sym_1', 'sym_2', 'sym_3' (可以是其他顺序,只要对应起来即可)
解向量是以这个顺序对这些变量所赋的值。通常,我们得到的向量都是稀疏的,现在我们给出第一个门 sym_1 = x * x → x * x - sym_1 的三向量组(a,b,c):
a = [0, 1, 0, 0, 0, 0]
b = [0, 1, 0, 0, 0, 0]
c = [0, 0, 0, 1, 0, 0]可以看出如果解向量 s 的第二个标量是 3,第四个标量是 9,无论其他标量是多少,都满足约束,同样,如果 s 的第二个标量是 7,第四个标量是 49,也会通过检查,第一次检查仅仅是为了验证第一个门的输入和输出的一致性。
类似的第二个门 sym_2 = sym_1 * x → sym_1 * x - sym_2 的三向量组(a,b,c)为:
a = [0, 0, 0, 1, 0, 0]
b = [0, 1, 0, 0, 0, 0]
c = [0, 0, 0, 0, 1, 0]第三个门 sym_3 = sym_2 + x → sym_2 + x - sym_3 的三向量组(a,b,c)为:
a = [0, 1, 0, 0, 1, 0]
b = [1, 0, 0, 0, 0, 0]
c = [0, 0, 0, 0, 0, 1]加法的转化方式略有不同,可以理解为(x + sym_2)*1 - sym_2
类似的,最后一个门 ~out = sym_3 + 5 → sym_3 + 5 - (~out) 的三向量组 (a,b,c) 为:
a = [5, 0, 0, 0, 0, 1]
b = [1, 0, 0, 0, 0, 0]
c = [0, 0, 1, 0, 0, 0]现在已经做了最后一次验证:~out = sym_3 + 5。witness(即解向量)是 [1,3,35,9,27,30]。(因为我们知道 x=3,将它带入“拍平”后的声明语句就可得到其他变量的解)。
现在我们得到了四个约束的R1CS,完整的R1CS如下:
A
[0, 1, 0, 0, 0, 0]
[0, 0, 0, 1, 0, 0]
[0, 1, 0, 0, 1, 0]
[5, 0, 0, 0, 0, 1]
B
[0, 1, 0, 0, 0, 0]
[0, 1, 0, 0, 0, 0]
[1, 0, 0, 0, 0, 0]
[1, 0, 0, 0, 0, 0]
C
[0, 0, 0, 1, 0, 0]
[0, 0, 0, 0, 1, 0]
[0, 0, 0, 0, 0, 1]
[0, 0, 1, 0, 0, 0]接下来我们要做的是将 R1CS 转化成 QAP 形式,这两者的区别是 QAP 使用多项式来代替点积运算,他们所实现的逻辑完全相同。
2.3 R1CS转为QAP
在介绍这种转化之前,我们需要学习拉格朗日差值公式,这个公式的作用是构造一个穿过指定点的多项式,Vitalik的文章中用了很大的篇幅介绍这个公式的使用,在这里我直接给出拉格朗日插值公式:

现在要将四个长度为六的三向量组转化为六组多项式,每组多项式包括三个三阶多项式,我们在每个 x 点处来评估不同的约束,在这里,我们共有四个约束,因此我们分别用多项式在x=1,2,3,4 处来评估这四个向量组。现在我们使用拉格朗日差值公式来将 R1CS 转化为 QAP 形式。
先求出四个约束所对应的每个 a 向量的第一个值的多项式,也就是说使用拉格朗日插值定理求过点 (1,0), (2,0), (3,0), (4,0) 的多项式,类似的我们可以求出其余的四个约束所对应的每个向量的第i个值的多项式。结果如下:
A 多项式组
[-5.0, 9.166, -5.0, 0.833]
[8.0, -11.333, 5.0, -0.666]
[0.0, 0.0, 0.0, 0.0]
[-6.0, 9.5, -4.0, 0.5]
[4.0, -7.0, 3.5, -0.5]
[-1.0, 1.833, -1.0, 0.166]
B 多项式组
[3.0, -5.166, 2.5, -0.333]
[-2.0, 5.166, -2.5, 0.333]
[0.0, 0.0, 0.0, 0.0]
[0.0, 0.0, 0.0, 0.0]
[0.0, 0.0, 0.0, 0.0]
[0.0, 0.0, 0.0, 0.0]
C 多项式组
[0.0, 0.0, 0.0, 0.0]
[0.0, 0.0, 0.0, 0.0]
[-1.0, 1.833, -1.0, 0.166]
[4.0, -4.333, 1.5, -0.166]
[-6.0, 9.5, -4.0, 0.5]
[4.0, -7.0, 3.5, -0.5]这些系数是升序排序的,例如上述第一个多项式是 0.833x3 - 5x2+9.166x -5. 如果我们将 x=1 带入上述十八个多项式,可以得到第一个约束的三个向量 (0, 1, 0, 0, 0, 0), (0,1, 0, 0, 0, 0), (0, 0, 0, 1, 0, 0) ,类似的我们将 x = 2, 3, 4 带入上述多项式可以恢复出 R1CS 的剩余部分。
通过将 R1CS 转换成 QAP 我们可以通过多项式的内积运算来同时检查所有的约束而不是像R1CS 那样单独的检查每一个约束。如下图所示:

我们需要检查结果多项式 A(x) * B(x) - C(x) 在 x=1,2,3,4 处是否都为 0,若在这四个点处有一处不为 0,那么验证失败,否则,验证成功。
根据代数学原理,正确性检查 等价于 结果多项式 A(x) * B(x) - C(x) 是否能够整除多项式 Z(x) = (x-1)(x-2)(x-3)(x-4)。不难看出多项式 Z(x) 是根据所有逻辑门约束条件所对应的点算出来的。通过这种等价形式的转化会大大减少我们的开销。
3. 在QAP上构建zkSNARKs
第2部分花了很大篇幅讲述如何将一个代码逻辑问题转换为一个zkSNARKs可以处理的QAP表达,现在来讲讲,针对一个QAP问题,怎么做zkSNARKs的证明过程呢?
为了统一符号,这部分的符号均采用第1部分定义的符号,第2部分定义的符号本质上与第1部分的符号是表达同样的意思。
让我们慢慢去思考这个问题,首先,我们有一系列的多项式![]() ,以及一个t(x),在非零知识的过程中我们只需要让prover传回一个解即可,但如果要做成零知识呢?我们一步一步引入密码工具完成zk-SNARKs。
,以及一个t(x),在非零知识的过程中我们只需要让prover传回一个解即可,但如果要做成零知识呢?我们一步一步引入密码工具完成zk-SNARKs。
首先明确我们的目的,对于一个QAP问题,witness就是![]() ,想达到的是,prover知道这么一组满足给定QAP问题的系数witness,是prover能通过验证的充要条件,但是witness的信息不会泄露。
,想达到的是,prover知道这么一组满足给定QAP问题的系数witness,是prover能通过验证的充要条件,但是witness的信息不会泄露。
我们先思考需要交互的情况:
1)此时verifier随机选取一个数s,发送给prover。
2)prover根据![]() ,代入自己的系数计算出L(x),R(x),O(x),并令P(x) = L(x)R(x) - O(x),求得P(x) / t(x) = h(x),发送L(s),R(s),O(s)与h(s)给verifier。
,代入自己的系数计算出L(x),R(x),O(x),并令P(x) = L(x)R(x) - O(x),求得P(x) / t(x) = h(x),发送L(s),R(s),O(s)与h(s)给verifier。
3)verifier计算是![]() 否成立。
否成立。
但是,上述协议根本不是一个证明协议,证明本身是可以任意伪造的,因为我们只通过一次检验,没法保证prover如实计算了P(x)以及h(x),这个不能用来证明的协议放在这里这里仅作一个引子。另外,最开始不考虑通用化的问题,所以要证明的重点就体现在构造出来的QAP问题中,后面会讲通用化。
接下来要引入密码学工具一步一步限制prover达到目的,圈一个重点,下面做的所有工作都是为了这三件事:
1.验证证明是用给定CRS公共参考串里面的值线性组合而来。
2.验证证明中L R O三者的系数是一致的。
3.验证给出的证明是满足QAP的解。
3.1同态隐藏
还记得第1部分1.2存在的问题1)和2)吗,都是因为证明者知道随机数r以及t(r)。引入同态加密可以解决。数据是加密的,在加密数据的基础上可以进行计算,能和原始数据计算具有同样的“形态”。
假设有一个映射E(),映射前的某些操作可以在映射后体现,就说明映射具有同态性。
定义:
(1)对于一个给定的x,知道E(x),很难逆推得到x。
(2)对于不同的x和y,![]() 。
。
(3)对于某些操作,映射后依然存在,比如E(x+y)可以从E(x)和E(y)中计算出来。
一个简单的例子是椭圆曲线域上的幂运算,![]() ,x是需要加密的数据,g为生成元,根据椭圆曲线离散对数问题,E(x)和g并不能反推回x。
,x是需要加密的数据,g为生成元,根据椭圆曲线离散对数问题,E(x)和g并不能反推回x。
在引入双线性映射之前,暂时用E(s)来写,引入后都用幂形式写,两者在本文意义相同。
举个例子,verifier可以选择一个秘密s,然后发送![]() 给prover,verifier知道一个多项式
给prover,verifier知道一个多项式![]() ,想验证prover知不知道此多项式,可将
,想验证prover知不知道此多项式,可将![]() 发送给prover,prover计算
发送给prover,prover计算![]() ,将
,将![]() 发回。
发回。
显而易见,一个多项式的值,可以通过各项的加密结果乘上各项的系数,计算出多项式的加密结果。verifier既可验证,计算过程prover无法知道具体的s值为多少。
根据同态加密的性质,修改1.2基础协议:
·Verifier
·取一个随机数s,也就是秘密值。
·指数i取值为 0,1,…,d (d为h的阶)时分别计算对s求幂的加密结果,即![]() ,以及
,以及![]() 。
。
·代入 s 计算未加密的目标多项式:![]() 。
。
·将![]() 以及
以及![]() 提供给 prover。
提供给 prover。
·Prover
·prover根据![]() ,代入自己的系数计算出L(x),R(x),O(x),并令P(x) = L(x)R(x) - O(x),求得 h(x) = P(x)/t(x),得到了h(x)的系数
,代入自己的系数计算出L(x),R(x),O(x),并令P(x) = L(x)R(x) - O(x),求得 h(x) = P(x)/t(x),得到了h(x)的系数![]() 。
。
·用![]() 计算出E(P(s))。
计算出E(P(s))。
·用![]() 和系数
和系数![]() 计算
计算![]() =
=![]() 。
。
·将E(P(s))和E(h(s))发送给verifier。
·Verifier
·最后一步是 verifier 去校验![]() 是否成立。
是否成立。
(注意,此时方案已经不成立,因为在验证中出现了![]() 和
和![]() 两个加密结果“相乘”,从同态加密的定义的定义可知,两个加密结果不能相乘,这个问题在下面的双线性映射部分会得到解决,因为双线性映射具备乘法同态,这一步放这里起一个递进的作用)
两个加密结果“相乘”,从同态加密的定义的定义可知,两个加密结果不能相乘,这个问题在下面的双线性映射部分会得到解决,因为双线性映射具备乘法同态,这一步放这里起一个递进的作用)
这个改进之后的协议,Verifier没有暴露随机值s,Prover只能通过多项式计算出h得到对应的系数,进而计算出证明。
但是这个协议也存在问题,Prover有可能只用Verifier提供的各项加密结果中的几项来构造证明。也就是说没法保证prover一定是用![]() 的排列组合计算出来的值,比如Verifier发送
的排列组合计算出来的值,比如Verifier发送![]() ,prover也可以用随便选个E(3)进行计算,只需要满足幂次计算即可。Verifier无法识别这种情况,需要引出另一个工具来解决这个问题了。
,prover也可以用随便选个E(3)进行计算,只需要满足幂次计算即可。Verifier无法识别这种情况,需要引出另一个工具来解决这个问题了。
3.2 KCA(Knowledge of Coefficient Test and Assumption)
假如我们对![]() ,每一个值再计算相应的
,每一个值再计算相应的![]() ,而α对于prover是未知的,因为离散对数难题,prover也无法从中提取出α,那么我们就能限制prover只能用我发送的值进行计算了。
,而α对于prover是未知的,因为离散对数难题,prover也无法从中提取出α,那么我们就能限制prover只能用我发送的值进行计算了。
假如Verifier发送![]() ,那么prover就只能用5这个值进行计算
,那么prover就只能用5这个值进行计算![]() ,以及
,以及![]() ,最终验证prover返回的两个值,
,最终验证prover返回的两个值,![]() 即可保证prover一定是诚实的按照
即可保证prover一定是诚实的按照![]() 的排列组合计算出来的,如果prover想用
的排列组合计算出来的,如果prover想用![]() 进行计算,可是他提供不了
进行计算,可是他提供不了![]() 就通过不了这一步验证。
就通过不了这一步验证。
(这个方案的具体实现过程将在 4.1.2中结合双线性映射 作为例子给出。)
3.2.1 串用问题-α对
但是上面的解决方案可能导致串用问题,因为所有的α都一样,prover可能用![]() 串在R(x)的计算中,那么我们给
串在R(x)的计算中,那么我们给![]() 三个不同的
三个不同的![]() ,这样verifier需要事先计算
,这样verifier需要事先计算![]() 以及对应的
以及对应的![]() ,这样就可保证都是根据各自的隐藏值算的。
,这样就可保证都是根据各自的隐藏值算的。
这样的话,Prover就可以直接,
通过![]() 计算
计算![]() ;
;
通过![]() 计算
计算![]() ;
;
通过![]() 计算
计算![]()
![]()
![]() ,并将结果全部发送给verifier。
,并将结果全部发送给verifier。
verifier在收到以后,
验证![]()
![]()
![]() 几个等式是否成立;
几个等式是否成立;
验证![]() 。
。
这一部分相当于加了一步验证"证明是用 给定参考串里面的值 线性组合计算而来"。
3.2.2 系数一致性问题-检验和
但是又有新的问题,我们知道QAP问题中,![]() ,三个多项式分别排列组合后得到L(x), R(x),O(x),他们的系数序列
,三个多项式分别排列组合后得到L(x), R(x),O(x),他们的系数序列![]() 应该是相同的。
应该是相同的。
但仅仅通过不同的α并不能保证prover一定会用相同的系数序列计算,可以用不同的几组系数a1, a2, a3计算,也可能通过验证。我们又需要新的思路,再加一步验证。
可以通过检验和来解决这个问题,verifier除了需要事先计算![]() ,
,![]() ,
,![]() 之外,还要计算一个
之外,还要计算一个![]() ,相当于对每一个
,相当于对每一个![]() 三元组,都计算一个检验和,最后加起来,需要系数序列相等才可能满足β的系数约束。
三元组,都计算一个检验和,最后加起来,需要系数序列相等才可能满足β的系数约束。
基于这个改进,prover生成证明还需要多计算一个结果,![]() ,这个
,这个![]() 就是针对每一组
就是针对每一组![]() 解中相同的系数,得
解中相同的系数,得![]() 发送给Verifier。verifier再多一步验证
发送给Verifier。verifier再多一步验证![]() ,即可验证线性组合是否相同。
,即可验证线性组合是否相同。
但是如果只用一个β,prover还是有操作空间的,比如当l(s)=r(s)的时候,有检验和![]() ,理论上需要
,理论上需要![]() 才能提取出一个公因子
才能提取出一个公因子![]() ,变成统一的
,变成统一的![]() 。
。
但由于l(s)=r(s),则可以进行如下操作:
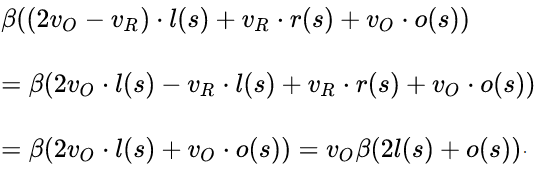
也得到了满足提取公因子的形式,可以通过验证,但此时系数并不一样。为了解决这个问题,我们可以对不同的![]() 选择不同的β,即
选择不同的β,即

![]() 多一步验证
多一步验证 ![]() ,即可验证线性组合是否相同。
,即可验证线性组合是否相同。
其实,改进之后还有一点缺陷,β虽然限制了计算需要![]() 的形式,但并没有限制在证明数据上同时偏移。解决的办法是︰引入γ,进一步隐藏β的加密结果。
的形式,但并没有限制在证明数据上同时偏移。解决的办法是︰引入γ,进一步隐藏β的加密结果。

最后Verifier的操作用到了双线性映射,这个在后面的章节会介绍。
总之这一步我们的目的就是确保prover计算的时候,三个系数序列一定要是相等的。
4.改进方案
4.1变为非交互
根据第3部分的分析,其实还是针对交互型协议的,每一次verifier每次都需要计算特别多的数字序列,比如:

现实情况中,多项式的阶数都非常高(即算数电路特别多),一般都几百万甚至上亿,每一次参数生成需要几小时乃至几天,对于verifier太耗时了,但如果![]() 等值没有泄露的话,其实所有的prover可以用相同的参数生成证明,这个就叫公共参考串(CRS)。
等值没有泄露的话,其实所有的prover可以用相同的参数生成证明,这个就叫公共参考串(CRS)。
如果用公共参考串这里就引出两个问题:
·如何保证生成公共参考串的人不泄露这几个隐私参数?
·在verifier验证的时候,很多地方都直接用上了![]() 这几个参数才可以验证,但是这几个参数在非交互情况下又必须隐藏,怎么保证还可以验证呢?
这几个参数才可以验证,但是这几个参数在非交互情况下又必须隐藏,怎么保证还可以验证呢?
4.1.1安全多方计算
关于上面两个问题,第一个问题是通过安全多方计算解决的,就是会有很多人参与生成公共参考串,每个人贡献出自己的随机数,最后通过某些手段拼合,由于没人知道所有的随机值,那么只要还剩一个人没有作恶,协议就是安全的。 
以此类推,可以扩展到计算其他参数以及更多人参与,细节就不赘述了,能理解思想即可。
4.1.2双线性映射
还记得3.1章留下的坑,两个同态加密结果不能相乘,于是引入了新的计算特性:双线性映射:![]() 。
。
双线性映射的核心性质,可以表达成如下的等式:
![]()


具体关于这样的双线性配对如何构造就超出本文谈论范围了。
那么以 3.2加入相同α对 的方案为例,应用双线性映射的zkSANRKs流程:

4.2通用化
(这一部分,主要参考自向程@HUST)
根据上面的分析,始终有一个问题,那就是针对每一个问题,都需要一次参数生成。
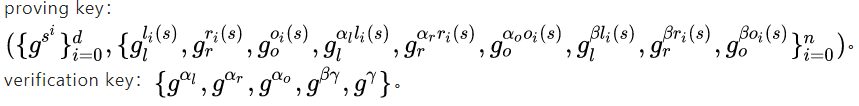
针对这个具体的问题,参数可以一直复用,但换一个问题,似乎又得做一遍重复操作了。
此时,我们希望我们设计的协议是通用的,即我们可以往协议中加入一个公共输入,针对不同的公共输入,就对应不同的问题。
这个该怎么做呢?首先回想一下,最开始我们想证明什么?是给定一系列多项式![]() 目标t(x),然后想求一个线性组合
目标t(x),然后想求一个线性组合![]() ,使得
,使得![]() 。
。
那么我们可不可以针多项式,从里面摘出一部分系数做验证,prover再生成证明呢?或者针对同一个多项式,我加入一些限制条件呢?比如说,按上面那个例子,我可以要求给出的证明必须满足,输出值为183,在此前提下给出证明。即prover生成的证明必须是要和公共输出对应,针对的是同一个问题,这样的话,我每次选择不同多项式的局部,prover都得生成针对性的证明才行,就可以对不同的问题复用参数生成。
现在我有一个特定的![]() ,对应一个特定的问题,我可以取出前l个用于验证。即将上面的多项式分为
,对应一个特定的问题,我可以取出前l个用于验证。即将上面的多项式分为![]() ,只对后面这部分进行KCA处理,而前面一部分
,只对后面这部分进行KCA处理,而前面一部分![]() 放入verification key,对应的
放入verification key,对应的![]()
直接当成公共输入(可认为是prover要证明的论述statement)用来限制prover的证明,根据不同的问题,这个公共输入也不一样。
这样prover生成证明时,verifier验证证明时也将公共输入输进去,如果依然成立就能保证prover是对一个特定问题生成证明,相当于把问题本身的一部分当成了公共输入。
5.总结
结合上面所有的改进,我们对协议进行一个总结:


在完整的写完协议后,我们可以分析下怎么做到的,首先由于同态性,上面的式子肯定是成立的,并且由于verifier在验证时,已经输入了一部分系数,所以说prover给出的证明必须要在verifier给出系数的前提下才可以通过。
讲个具体实例可能比较好理解,比如说你想设计一个电路,用于验证prover持不持有跟某个比特币地址对应的私钥,如果没有公共输入,你要么给每个地址都生成一次参数,要么就只能证明prover有没有某个私钥对应任意一个比特币地址(这个没有任何意义)。
但是如果加入公共输入,那就可以通用化,我们可以把地址的限制当成公共输入,那么prover的证明就必须得有与公共地址对应的私钥才行。比如将比特币创世地址1A1zP1eP5QGefi2DMPTfTL5SLmv7DivfNa转化为公共输出的限制,如果有人能证明自己拥有对应的私钥,那就有大概率可以证明自己是中本聪了。
以上就是我对zkSNARKs的大致理解,应该是把自己理解的zkSNARKs基本原理和重要的优化方案写出来了,还有部分优化的内容没有看懂就没写出来,自己也在不断学习和深入理解之中,会继续学习、补充关于零知识证明的内容。