关键词提取
移除标点符号一般有两种方法:删除停止词(Stop Words);
根据词性提取关键词。
words2 = jieba.cut(words1)
words3 = list(words2)
print("/".join(words3))
# 速度/快/,/包装/好/,/看着/特别/好/,/喝/着/肯定/不错/!/价廉物美
stop_words = [",", "!"]
words4 =[x for x in words3 if x not in stop_words]
print(words4)
# ['速度', '快', '包装', '好', '看着', '特别', '好', '喝', '着', '肯定', '不错', '价廉物美']
另一种优化分词结果的方式叫做根据词性提取关键词。这种方式的优点在于不用事先准备停用词列表,jieba 库就能够根据每个词的词性对其进行标注。
这里为你提供了一张 paddle(paddle 是百度开源的深度学习平台,jieba 使用了 paddle 的模型库)模式词性表作为参考,你可以根据 jieba 自动分析得到的词性结果,手动将助词、虚词(标点符号)移除。
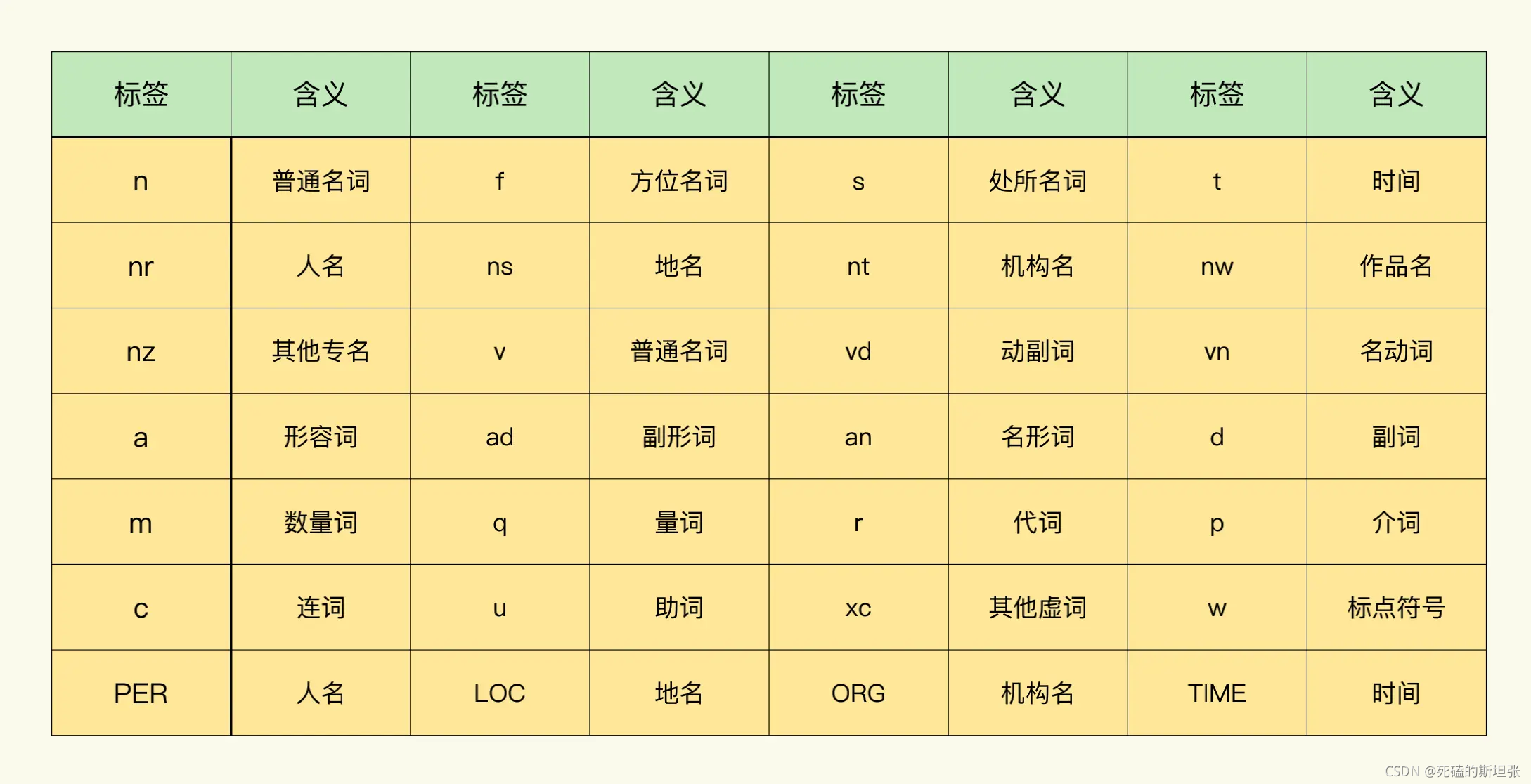
# words5 基于词性移除标点符号
import jieba.posseg as psg
words5 = [ (w.word, w.flag) for w in psg.cut(words1) ]
# 保留形容词
saved = ['a',]
words5 =[x for x in words5 if x[1] in saved]
print(words5)
# [('快', 'a'), ('好', 'a'), ('好', 'a'), ('不错', 'a')]
语义情感分析
对于已经分好词的语句,我们需要使用另一个库统计词的正向、负向情感倾向,这个库就是 snownlp 库。
snownlp 的算法问题,会让它对否定词划分得不够准确。例如“不喜欢”,snownlp 会把这个词划分为两个独立的词,分别是“不”和“喜欢”。那么,在计算语义情感时,就会产生较大的误差。所以我们会先采用 jieba 进行分词,分词之后再采用 snownlp 来实现语义情感分析功能。
from snownlp import SnowNLP
words6 = [ x[0] for x in words5 ]
s1 = SnowNLP(" ".join(words3))
print(s1.sentiments)
# 0.99583439264303
这段代码通过 snownlp 的 Bayes(贝叶斯)模型训练方法,将模块自带的正样本和负样本读入内存之后,再使用 Bayes 模型中的 classify() 函数进行分类,这样就得到了 sentiments 属性的值,sentiments 的值表示情感倾向的方向。在 snownlp 中:如果情感倾向是正向的,sentiments 的结果会接近 1。如果情感倾向是负向的,结果会接近 0。
positive = 0
negtive = 0
for word in words6:
s2 = SnowNLP(word)
if s2.sentiments > 0.7:
positive+=1
else:
negtive+=1
print(word,str(s2.sentiments))
print(f"正向评价数量:{
positive}")
print(f"负向评价数量:{
negtive}")
# 快 0.7164835164835165
# 好 0.6558628208940429
# 好 0.6558628208940429
# 不错 0.8612132352941176
# 价廉物美 0.7777777777777779
# 正向评价数量:3
# 负向评价数量:2
在 snownlp 中,通过 train() 和 save() 两个函数把模型训练和保存之后,就能实现扩展默认字典的功能了。此外,我在工作中还会利用这种方式增加 emoji 表情对应的情感倾向分析功能,以此来进一步提升 snownlp 分析情感倾向的准确度。
sentiment.train(neg2.txt,pos2.txt); # 训练用户自定义正负情感数据集
sentiment.save('sentiment2.marshal'); # 保存训练模型