文章目录
一、数据整理
1、合并+处理缺失值
# tmdb_5000_movies.csv
budget :电影成本
genres:风格列表,按|分隔,最多5种风格
homepage:电影首页URL
id :电影ID
keywords:电影关键词,按|分隔,最多5种关键词
original_language:原始语言
original_title :电影名称
overview:剧情摘要
popularity:热度
production_companies:制作商
production_countries:制作地区
release_date:首次上映日期
revenue :收入
runtime :电影时长
spoken_languages:语言
status:是否发布
tagline:一句话说明一部电影(往往是海报上面的)
title :电影名称
vote_average:平均分
vote_count:投票人数
# tmdb_5000_credits.csv
movie_id:电影ID
title:电影名称
cast:演员表
crew:制作团队(分析那些人经常出现在高票房的电影里面)
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('ggplot')
import json
import warnings
warnings.filterwarnings('ignore')#忽略警告
credits_file='D:/S072003Python/05DataMineML/tmdb_5000_credits.csv'
movies_file='D:/S072003Python/05DataMineML/tmdb_5000_movies.csv'
credits=pd.read_csv(credits_file)
movies=pd.read_csv(movies_file)
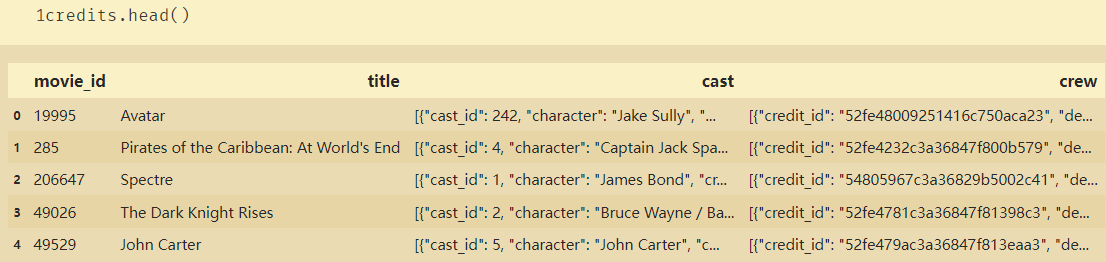
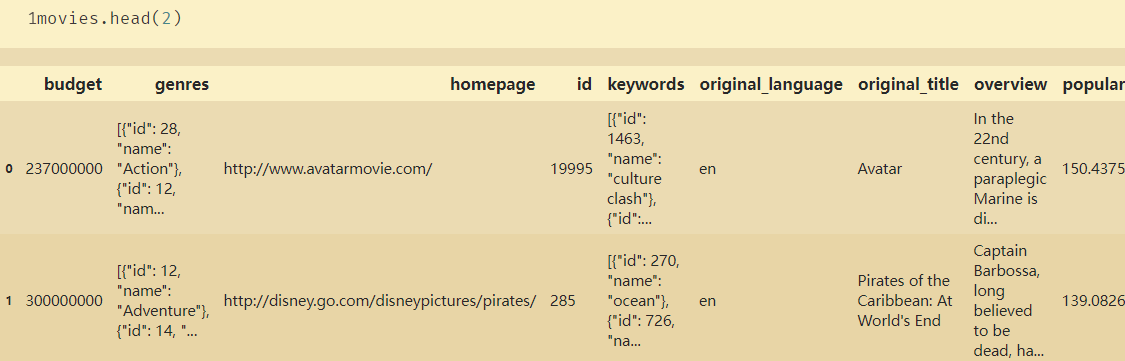
# 合并文档
fulldf=pd.concat([credits,movies],axis=1)
# 选择子集
moviesnames=['movie_id','original_title','cast','crew','release_date','genres','keywords','production_companies','production_countries','revenue','budget','runtime','vote_average']
moviesdf=fulldf[moviesnames]
moviesdf.head()
# 增加电影利润
moviesdf['profit']=moviesdf['revenue']-moviesdf['budget']
# 处理不理想数据
release_date_null=movies['release_date'].isnull()
moviesdf.loc[release_date_null]
moviesdf['release_date']=movies['release_date'].fillna('2014-06-01')
moviesdf['release_date']=pd.to_datetime(moviesdf['release_date'],format='%Y-%m-%d')
moviesdf.to_excel('moviesdf.xlsx',index=False)
moviesdf.head()
#3 找出runtime的缺失值
runtime_date_null=moviesdf['runtime'].isnull()
moviesdf[runtime_date_null]
values={
'runtime:':98.0}
values={
'runtime:':81.0}
moviesdf.fillna(value=values,limit=1,inplace=True)
moviesdf.fillna(value=values,limit=2,inplace=True)
2、对于json格式的数据进行分割提取
# 如何从json的数据格式提取需要的数据
# 提取电影风格数据genres
moviesdf['genreslist']=moviesdf['genres'].apply(json.loads)
moviesdf.head(1)
moviesdf['castlist']=moviesdf['cast'].apply(json.loads)
moviesdf['countries']=moviesdf['production_countries'].apply(json.loads) # json.loads()将str类型的数据转换为dict类型
moviesdf['companies']=moviesdf['production_companies'].apply(json.loads)
moviesdf['crewslist']=moviesdf['crew'].apply(json.loads)
moviesdf.head(1)
定义函数处理genres:
# 每一个genres
[{
"id": 28, "name": "Action"}, {
"id": 12, "name": "Adventure"}, {
"id": 14, "name": "Fantasy"}, {
"id": 878, "name": "Science Fiction"}]
#等于json格式的数据进行分割提取,通过自定义函数
def decode(column):
z=[]
for i in column:
z.append(i['name'])
return ' '.join(z)
# 获取dict中第一个元素的name值
def decode1(column):
z=[]
for i in column:
z.append(i['name'])
return ''.join(z[0:1]) #切片,只输出第一个分隔
moviesdf['genresls']=moviesdf['genreslist'].apply(decode1)
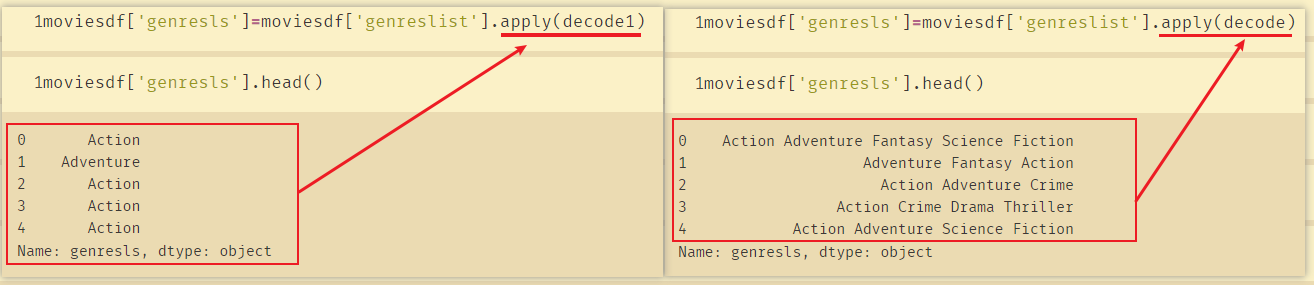
二、 电影类型随时间变化怎么样?
# 电影类型与时间的关系
genres_list=set() # 获取所有的电影风格
for i in moviesdf['genresls'].str.split(' '):
genres_list=set().union(i,genres_list) # 集合(set)是一个无序的不重复元素序列。可以使用大括号 { } 或者 set() 函数创建集合。
genres_list=list(genres_list)
genres_list
genres_list.remove('') # 去除空的元素
print(genres_list)
moviesdf['releaseyear']=pd.to_datetime(moviesdf['release_date']).dt.year
moviesdf.head(3)
moviesdf.to_excel('moviesdfv3.xlsx',index=False)
得到的所有电影的风格genres_list:
['Movie', 'Documentary', 'Comedy', 'Crime', 'Fantasy', 'History', 'Drama', 'Horror', 'Action', 'War', 'Foreign', 'Thriller', 'Fiction', 'Animation', 'Science', 'Music', 'Western', 'Romance', 'Family', 'TV', 'Mystery', 'Adventure']
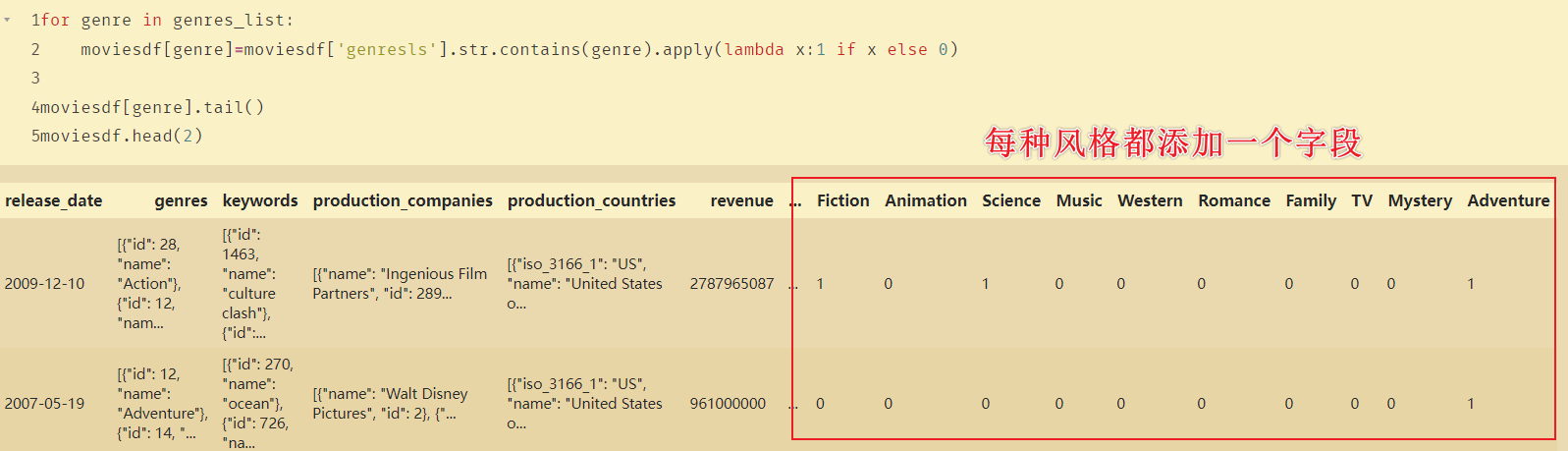
目的:由于每部电影不只一种风格,则为每种风格添加一个字段,如果该电影包含这种风格则填1,否则填0。
for genre in genres_list:
moviesdf[genre]=moviesdf['genresls'].str.contains(genre).apply(lambda x:1 if x else 0)
moviesdf[genre].tail()
moviesdf.head(2)
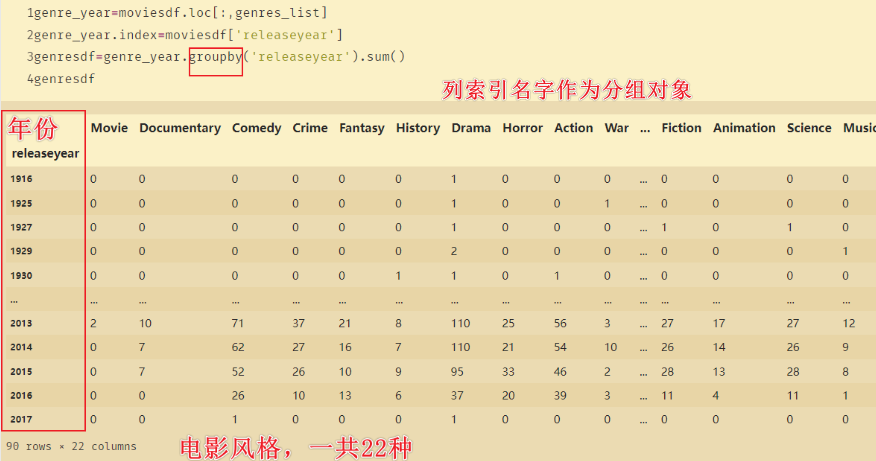
genre_year=moviesdf.loc[:,genres_list]
genre_year.index=moviesdf['releaseyear']
genresdf=genre_year.groupby('releaseyear').sum()
genresdf
genresdf.plot(figsize=(16,10))
genresdfsum=genresdf.sum(axis=0).sort_values(ascending=False)
genresdfsum
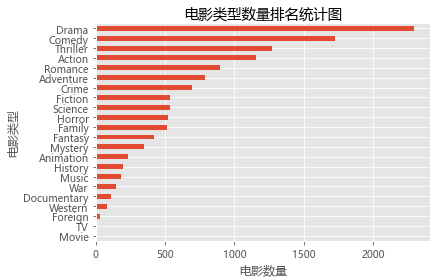
genresdfsum:拿到从1916到2017年所有风格电影数据的总和
Drama 2297
Comedy 1722
Thriller 1274
Action 1154
Romance 894
Adventure 790
Crime 696
Fiction 535
Science 535
Horror 519
Family 513
Fantasy 424
Mystery 348
Animation 234
History 197
Music 185
War 144
Documentary 110
Western 82
Foreign 34
TV 8
Movie 8
dtype: int64
genresdfsum.sort_values().plot(kind='barh',label='genres') # 如果是kind='bar'则横纵坐标交换
plt.rcParams['font.sans-serif']=['Microsoft YaHei'] # 使用微软雅黑的字体
plt.title('电影类型数量排名统计图')
plt.xlabel('电影数量')
plt.ylabel('电影类型')
plt.show()
扫描二维码关注公众号,回复:
13790040 查看本文章

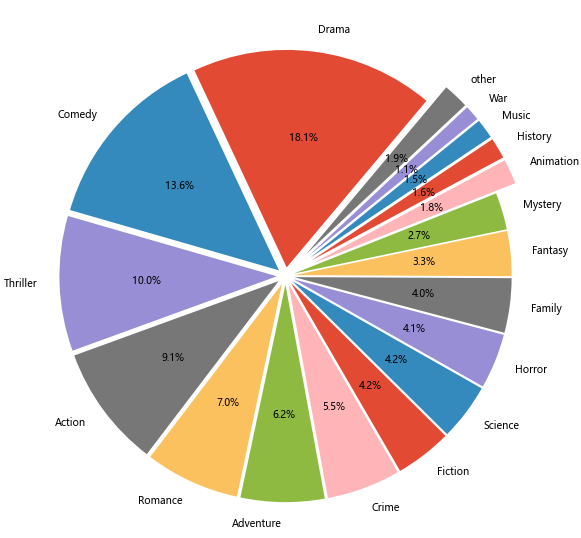
# 计算电影类型的饼图
genres_pie=genresdfsum/genresdfsum.sum()
others=0.01
genres_pie_otr=genres_pie[genres_pie>=others]
genres_pie_otr['other']=genres_pie[genres_pie<others].sum()
explode=(genres_pie_otr<=0.02)/10+0.04
genres_pie_otr.plot(kind='pie',label='',startangle=50,shadow=False,figsize=(10,10),autopct='%1.1f%%',explode=explode)
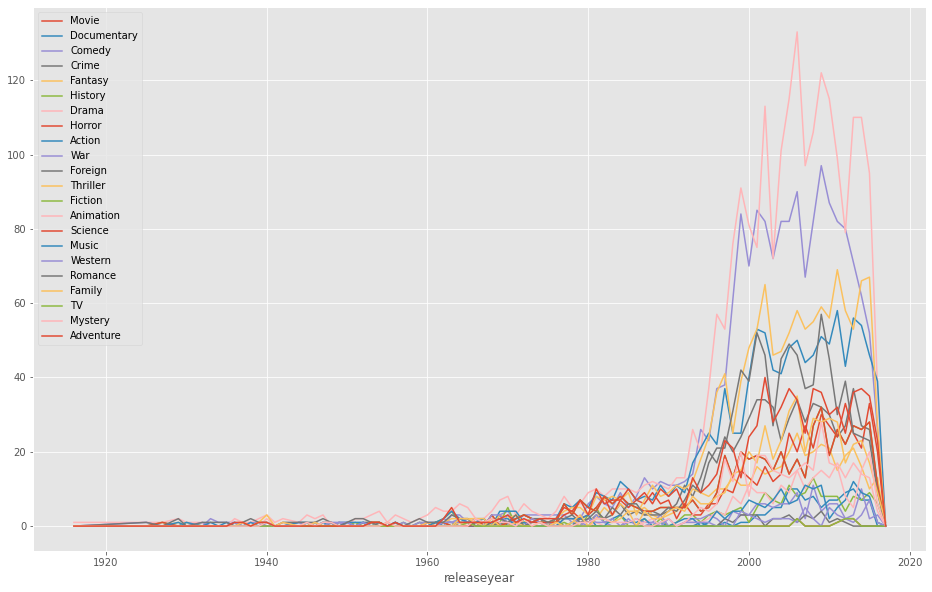
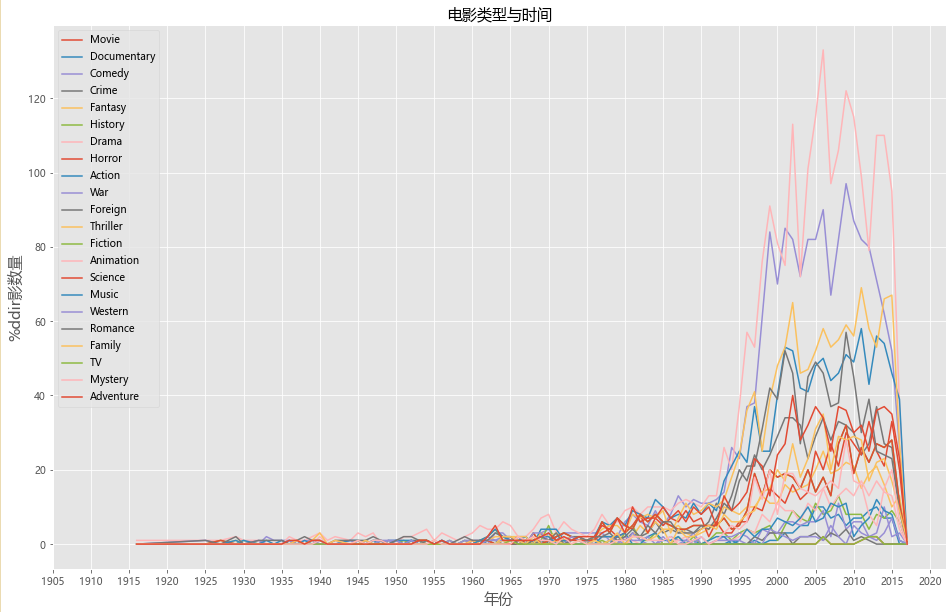
# 电影类型和时间关系的分析
plt.figure(figsize=(16,10))
plt.plot(genresdf,label=genresdf.columns)
plt.xticks(range(1905,2021,5))
plt.legend(genresdf)
plt.title('电影类型与时间',fontsize=15)
plt.xlabel('年份',fontsize=15)
plt.ylabel('%ddir影数量',fontsize=15)
plt.show()
三、 电影类型与利润的关系
# 电影类型与利润的关系
mean_genre_profit=pd.DataFrame(index=genres_list)
mean_genre_profit.head()
newarray=[]
for genre in genres_list:
# moviesdf.groupby('War',as_index=True)['profit'].mean() # 使得War得到两组数据,第一组为0,即不是War类型的平均值,无意义,因此下面只取第二组1
newarray.append(moviesdf.groupby(genre,as_index=True)['profit'].mean())
newarray2=[]
for i in range(len(genres_list)):
newarray2.append(newarray[i][1]) # 这里取的是第二个数据,
mean_genre_profit['mean_profit']=newarray2
mean_genre_profit.head(17)

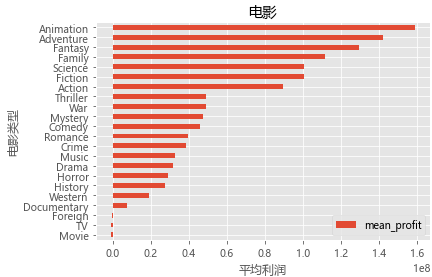
得到的mean_profit:
mean_profit
Movie -1.150000e+06
Documentary 7.185600e+06
Comedy 4.597608e+07
Crime 3.830085e+07
Fantasy 1.297936e+08
History 2.762010e+07
Drama 3.143791e+07
Horror 2.897105e+07
Action 8.970235e+07
War 4.887342e+07
Foreign -2.934369e+05
Thriller 4.907608e+07
Fiction 1.005910e+08
Animation 1.592271e+08
Science 1.005910e+08
Music 3.254800e+07
Western 1.916726e+07
Romance 3.969103e+07
Family 1.116260e+08
TV -1.150000e+06
Mystery 4.755644e+07
Adventure 1.423333e+08
# 绘制电影类型与平均利润的关系
mean_genre_profit.sort_values(by='mean_profit').plot(kind='barh')
plt.xlabel('平均利润')
plt.ylabel('电影类型')
plt.title('电影类型与平均利润的关系')
四、 Universal和Paramount两家影视公司的对比情况如何?
# 对比两家电影公司的电影发行情况
# 对电影公司的数据进行整理
moviesdf['prodcompanies']=moviesdf['production_companies'].apply(json.loads)
moviesdf['prodcompany']=moviesdf['prodcompanies'].apply(decode) # 用到上面定义的函数
moviesdf.head()
moviesdf['Universal']=moviesdf['prodcompany'].str.contains('Universal Pictures').apply(lambda x:i if x else 0)
moviesdf['Paramount']=moviesdf['prodcompany'].str.contains('Paramount Pictures').apply(lambda x:i if x else 0)
moviesdf.tail()
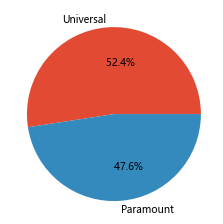
a=moviesdf['Universal'].sum()
b=moviesdf['Paramount'].sum()
dict_companies={
'Universal':a,'Paramount':b}
dict_companies
companies_number=pd.Series(dict_companies)
companies_number.plot(kind='pie',label='',autopct='%11.1f%%')
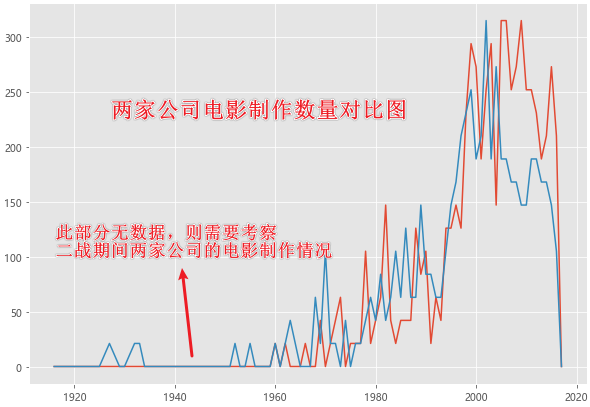
company=moviesdf[['Universal','Paramount']]
company.index=moviesdf['releaseyear']
companydf=company.groupby('releaseyear').sum()
companydf.head()
plt.figure(figsize=(10,7))
plt.plot(companydf,label=companydf.columns)
五、 改编电影和原创电影以及评分情况如何
# 通过keywords字段,分割改编电影与原创电影的对比
# 分析:在keywords字段中,如果存在based on novel 则说明电影改编自小说
moviesdf['keywds']=moviesdf['keywords'].apply(json.loads)
moviesdf['keywds2']=moviesdf['keywds'].apply(decode)
# 标注是否为基于小说改编的电影
a='based on novel'
moviesdf['if_original']=moviesdf['keywds2'].str.contains(a).apply(lambda x:'no original' if x else 'original')
moviesdf['if_original'].value_counts()
# moviesdf.head(2)
original_profit=moviesdf[['if_original','budget','revenue','profit']]
original_profit_mean=original_profit.groupby(by='if_original').mean()
original_profit_mean.head()
plt.figure(figsize=(12,9))
original_profit_mean.plot(kind='bar')
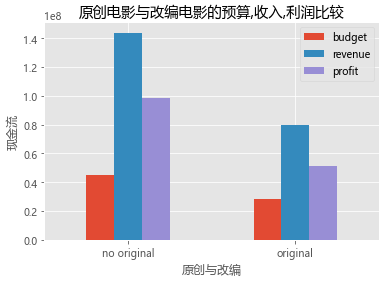
plt.title('原创电影与改编电影的预算,收入,利润比较')
plt.xlabel('原创与改编')
plt.ylabel('现金流')
plt.xticks(rotation=0)
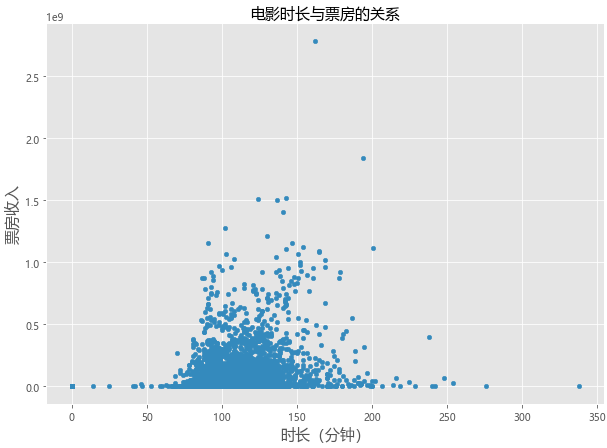
六、 电影时长与电影票房以及评分的关系
# 电影的runtime与票房,评分之间的关系
moviesdf.plot(kind='scatter',x='runtime',y='revenue',figsize=(10,7))
plt.title('电影时长与票房的关系',fontsize=15)
plt.xlabel('时长(分钟)',fontsize=15)
plt.ylabel('票房收入',fontsize=15)
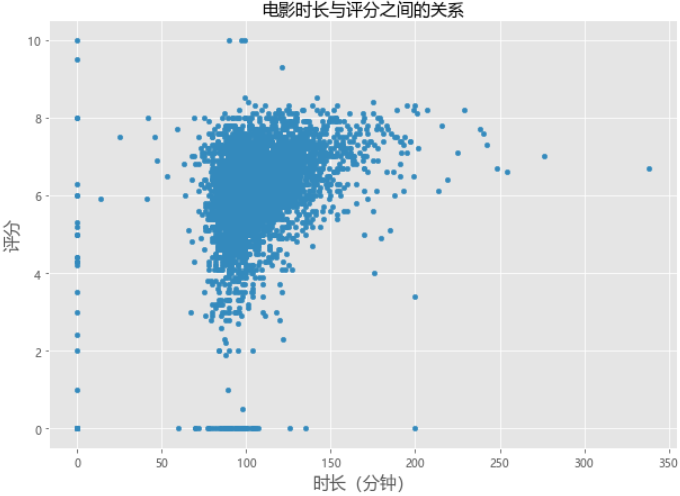
# 电影的时长与评分之间的关系
moviesdf.plot(kind='scatter',x='runtime',y='vote_average',figsize=(10,7))
plt.title('电影时长与评分之间的关系',fontsize=15)
plt.xlabel('时长(分钟)',fontsize=15)
plt.ylabel('评分',fontsize=15)
七、 分析电影关键字
1、根据jieba生成词频计算
# 电影关键字词频计算和词云生成
keywords_list=[]
for i in moviesdf['keywds2']:
keywords_list.append(i)
# keywords_list=list(keywords_list)
lis=''.join(keywords_list)
lis.replace('\'s','')
lis
# 根据电影关键词生成词频计算
import jieba
words=jieba.lcut(lis)
counts={
}
mytext_list=[]
for word in words:
if len(word)==1: # 单个分词不需要
continue
else:
counts[word]=counts.get(word,0)+1
mytext_list.append(word.replace(" ",""))
cloud_text=','.join(mytext_list)
# print(cloud_text)
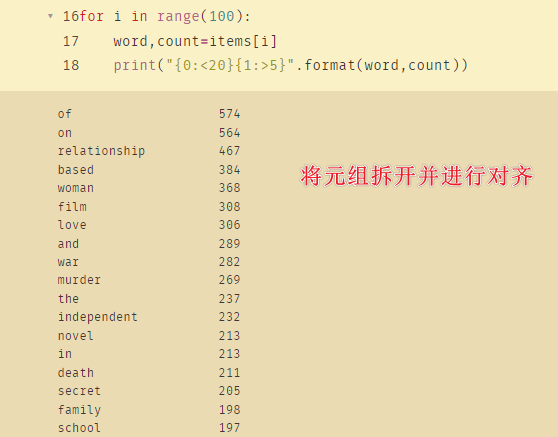
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(100):
word,countsnt=items[i]
print("{0:<10}{1:>5}".format(word,count))

from PIL import Image #需要下载安装PIL包
import numpy as np
from wordcloud import WordCloud, ImageColorGenerator
from matplotlib import pyplot as plt
import pandas as pd
# 简单生成词云
wc=WordCloud(
background_color='black',
max_words=2000,
max_font_size=100,
min_font_size=10,
random_state=12
)
wc.generate(lis)
plt.figure(figsize=(12,9))
plt.imshow(wc)
plt.axis('off')
plt.show()
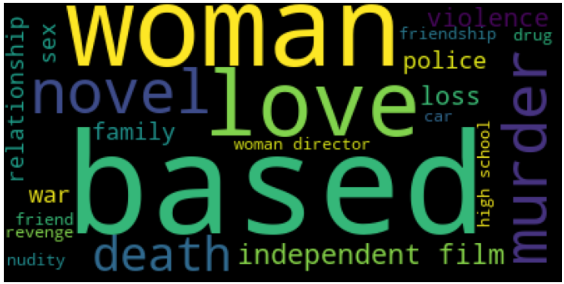
2、根据pkuseg生成词频计算
# 安装pkuseg
!pip install pkuseg
#调用北大算法和jieba算法得到的结果对于英文来说基本相同,但对于中文来说pkuseg会更加准确
#根据电影关键词生成词频计算 北大算法pkuseg
# 根据电影关键词生成词频计算
import pkuseg
seg=pkuseg.pkuseg()
words=seg.cut(lis) # 与jieba的区别主要是调用的算法不同
counts={
}
mytext_list=[]
for word in words:
if len(word)==1: # 单个分词不需要
continue
else:
counts[word]=counts.get(word,0)+1
mytext_list.append(word.replace(" ",""))
cloud_text=','.join(mytext_list)
# print(cloud_text)
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(100):
word,count=items[i]
print("{0:<20}{1:>5}".format(word,count))
八、分析演员的关联度(社会网络计算)

# 分析演员的关联度(社会网络计算)
moviesdf['actorsls']
actors_list=[]
actorsforcut=[]
# 将每部电影的演员放在列表当中
for i in moviesdf['actorsls']:
actors_list.append(i.split(','))
# 将演员列表中的对象放置到为分割而设置的另一个列表
for k in range(0,len(actors_list)):
for j in range(len(actors_list[k])):
actorsforcut.append(actors_list[k][j])
actors_list=''.join(actorsforcut)
actors_list
此时生成的actors_list[0:100]:

wc=WordCloud(
background_color='black',
max_words=2000,
max_font_size=100,
min_font_size=10,
random_state=12
)
wc.generate(actors_list)
plt.figure(figsize=(12,9))
plt.imshow(wc)
plt.axis('off')
plt.show()
此时生成的词云是不完整的
改进方法:变换词云的结构:
# 改进方案:
# 分析演员的关联度(社会网络计算)
moviesdf['actorsls']
actors_list=[]
actorsforcut=[]
# 将每部电影的演员放在列表当中
for i in moviesdf['actorsls']:
actors_list.append(i.split(','))
# 将演员列表中的对象放置到为分割而设置的另一个列表
for k in range(0,len(actors_list)):
for j in range(len(actors_list[k])):
actorsforcut.append("'"+actors_list[k][j]+"'") # 在这里对每个人的姓名前后都加上单引号
actors_list=','.join(actorsforcut)
actors_list[0:100]
此时生成的actors_list[0:100]:

将演员中间的空格去除,并合并为一个整体
# 如何将演员中间的空格去除,并合并为一个整体
movieactorsdfv2=moviesdf['actorsls'].apply(lambda x:''.join(x.split())).replace()
movieactorsdfv2.head(2)
movieactorsdfv2.to_csv('actors.txt',index=False,header=False)
# 读取数据并加载字典
with open('actors.txt',encoding='utf-8-sig') as f:
actorstxt=f.readlines()
# 此处的actors_forcut是手工查找替换单引号等完成的,在进行DF转换中可以直接处理
jieba.load_userdict("actors_forcut")
actorsforcut
actorsdf=pd.DataFrame(actorsforcut).drop_duplicates()
actorsdf[0]=actorsdf[0].apply(lambda x:''.join(x.split())).replace() # 将中间的空格删除
# 此时拿到了完整的人物列表
actorsdf[0]=actorsdf[0].apply(lambda x:''.join(x.split('\''))).replace() # 将姓名两边的单引号去除
actorsdf['']='nr'
actorsdf.to_excel('actorsdf.xlsx',index=False)
actorsdf.head()
movieactorsdfv2=pd.DataFrame(moviesdf['actorsls'])
movieactorsdfv2.head(5)
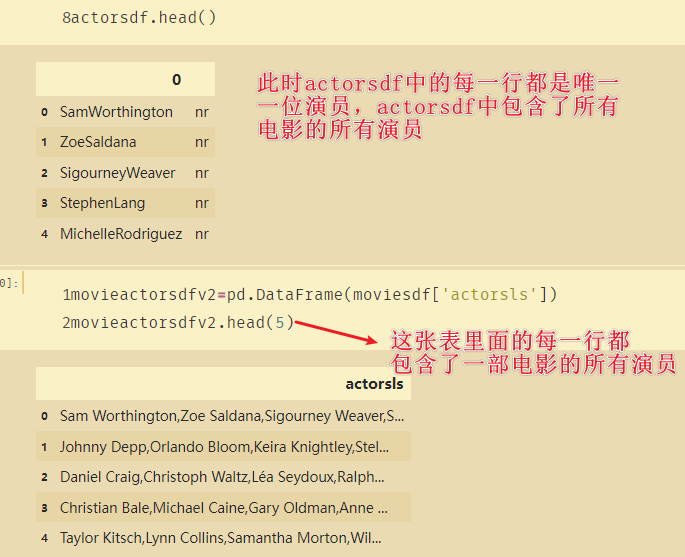
思路:如果我们按照actorsdf去寻找movieactorsdfv2,只要在电影里面找到了演员的名字,则在对应的actorsdf上面加一,就能知道哪些演员演过的电影最多。并且还可以将不同演员之间建立关系,最后使用pyechart进行可视化。