ElasticSearch 学习笔记
学习视频:【尚硅谷】ElasticSearch 入门到精通(基于 ELK 技术栈 elasticsearch 7.8.x 版本)
学习大纲:
- 第 1 章 Elasticsearch 概述
- 第 2 章 Elasticsearch 入门
- 第 3 章 Elasticsearch 环境
- 第 4 章 Elasticsearch 进阶
- 第 5 章 Elasticsearch 集成
- 第 6 章 Elasticsearch 优化
- 第 7 章 Elasticsearch 面试题
第 1 章 ElasticSearch 概述
结构化数据:
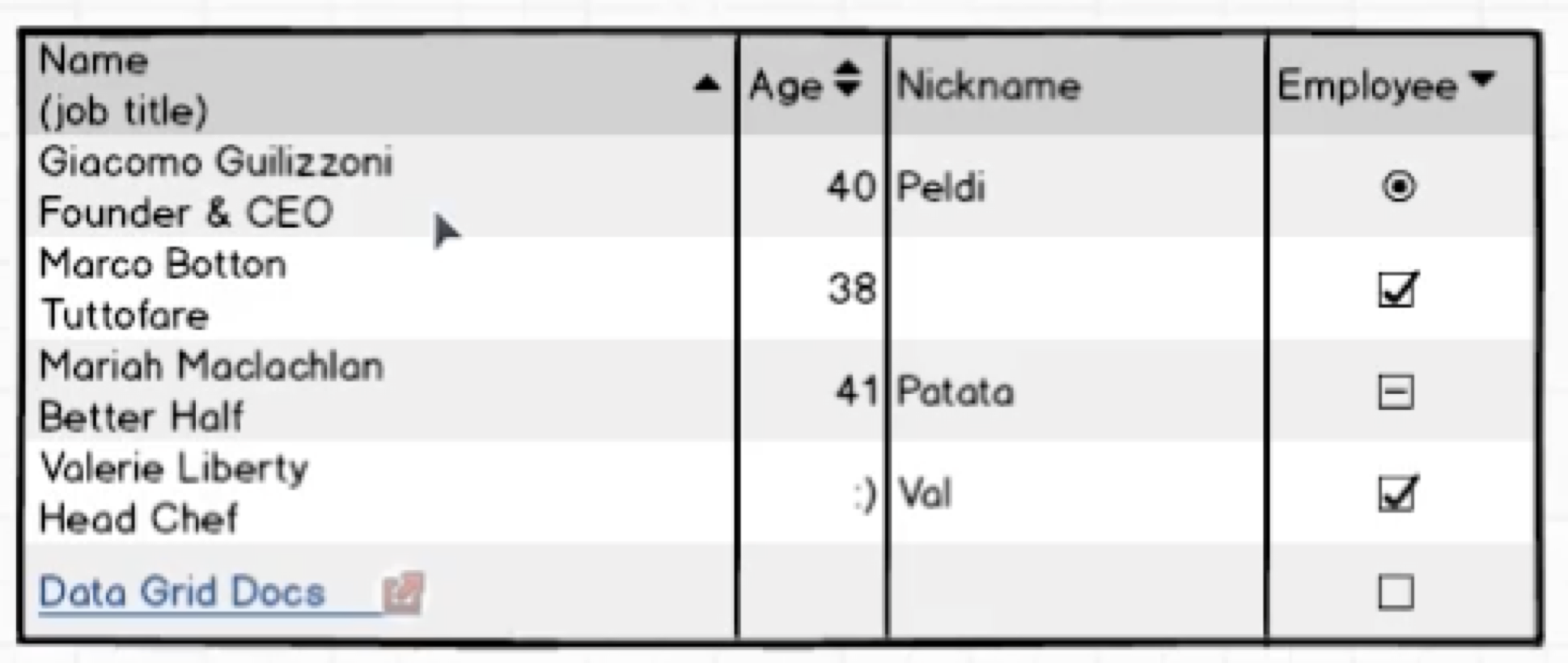 非结构化数据:
非结构化数据:
半结构化数据:
技术选型
Elasticsearch 是什么
The Elastic Stack 包括 Elasticsearch、 Kibana、 Beats 和 Logstash(也称为 ELK Stack)。能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。
Elaticsearch 简称为 ES,它是一个开源的高扩展的分布式全文搜索引擎, 是整个 ElasticStack 技术栈的核心。

它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。
全文搜索引擎
Google、百度类 的网站搜索,都是根据网页中的关键字生成索引,我们在搜索的时候输入关键字,它们会将该关键字即索引匹配到的所有网页返回;还有常见的项目中应用日志的搜索等等。对于这些非结构化的数据文本,关系型数据库搜索不是能很好的支持。
一般传统数据库,全文检索都实现的很鸡肋,因为一般也没人用数据库存文本字段。进行全文检索需要扫描整个表,如果数据量大的话即使对 SQL 的语法优化,也收效甚微。建立了索引,但是维护起来也很麻烦,对于 insert 和 update 操作都会重新构建索引。
基于以上原因可以分析得出,在一些生产环境中,使用常规的搜索方式,性能是非常差的:
- 搜索的数据对象是大量的非结构化的文本数据。
- 文件记录量达到数十万或数百万个甚至更多。
- 支持大量基于交互式文本的查询。
- 需求非常灵活的全文搜索查询。
- 对高度相关的搜索结果的有特殊需求,但是没有可用的关系数据库可以满足。
- 对不同记录类型、非文本数据操作或安全事务处理的需求相对较少的情况。为了解决结构化数据搜索和非结化数据搜索性能问题,我们就需要专业,健壮,强大的全文搜索引擎 。
这里说到的全文搜索引擎指的是目前广泛应用的主流搜索引擎。它的工作原理是计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
Elasticsearch 应用案例
- GitHub:2013 年初,抛弃了 Solr,采取 Elasticsearch 来做 PB 级的搜索。 “GitHub 使用Elasticsearch 搜索 20TB 的数据,包括 13 亿文件和 1300 亿行代码”。
- 维基百科:启动以 Elasticsearch 为基础的核心搜索架构
- 百度:目前广泛使用 Elasticsearch 作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部 20 多个业务线(包括云分析、网盟、预测、文库、直达号、钱包、 风控等),单集群最大 100 台机器, 200 个 ES 节点,每天导入 30TB+ 数据。
- 新浪:使用 Elasticsearch 分析处理 32 亿条实时日志。
- 阿里:使用 Elasticsearch 构建日志采集和分析体系。
- Stack Overflow:解决 Bug 问题的网站,全英文,编程人员交流的网站。
第 2 章 ElasticSearch 入门
环境准备
Elastic 官网:开源搜索:Elasticsearch、ELK Stack 和 Kibana 的开发者 | Elastic
ElasticSearch 镜像下载地址:https://mirrors.huaweicloud.com/elasticsearch/
Windows 版的 Elasticsearch 压缩包,解压即安装完毕,解压后的 Elasticsearch 的目录结构如下 :
| 目录 | 含义 |
|---|---|
| bin | 可执行脚本目录 |
| config | 配置目录 |
| jdk | 内置 JDK 目录 |
| lib | 类库 |
| logs | 日志目录 |
| modules | 模块目录 |
| plugins | 插件目录 |
解压后,进入 bin 文件目录,点击 elasticsearch.bat 文件启动 ES 服务 。
9300 端口为 Elasticsearch 集群间组件的通信端口, 9200 端口为浏览器访问的 http 协议 RESTful 端口。
打开浏览器,输入地址: http://localhost:9200,测试返回结果,返回结果如下:
以下是 Mac 电脑 的返回结果
{
"name": "air.local",
"cluster_name": "elasticsearch",
"cluster_uuid": "Zf7_bFjkSC6COYPBgeybTw",
"version": {
"number": "7.8.0",
"build_flavor": "default",
"build_type": "tar",
"build_hash": "757314695644ea9a1dc2fecd26d1a43856725e65",
"build_date": "2020-06-14T19:35:50.234439Z",
"build_snapshot": false,
"lucene_version": "8.5.1",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}
RESTful & JSON
REST 指的是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就是 RESTful。
几个应该知道的点:
POST不是幂等性的,PUT是幂等性的。POST是创建,PUT是更新。
RESTFul 是个比较抽象且需要理解的概念,建议多查阅相关资料,加深理解。
JSON: JavaScript Object Notation(JavaScript 对象表示法)
- JSON 是存储和交换文本信息的语法,类似 XML。
- JSON 比 XML 更小、更快,更易解析。
{
"sites": [
{
"name":"百度" , "url":"www.baidu.com" },
{
"name":"google" , "url":"www.google.com" },
{
"name":"微博" , "url":"www.weibo.com" }
]
}
Postman / ApiPost
如果直接通过浏览器向 Elasticsearch 服务器发请求,那么需要在发送的请求中包含 HTTP 标准的方法,而 HTTP 的大部分特性且仅支持 GET 和 POST 方法。所以为了能方便地进行客户端的访问,可以使用 Postman 软件。
Postman 是一款强大的网页调试工具,提供功能强大的 Web API 和 HTTP 请求调试。
后面我们向 ES 服务器发送请求都会使用以上两个工具。
索引操作
倒排索引(理解)
正排索引(传统):
| id | content |
|---|---|
| 1001 | my name is zhang san |
| 1002 | my name is li si |
倒排索引:
| keyword | id |
|---|---|
| name | 1001, 1002 |
| zhang | 1001 |
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。
为了方便理解,将 Elasticsearch 里存储文档数据和关系型数据库 MySQL 存储数据的概念进行一个类比:

Type 的概念已经被逐渐弱化:
- Elasticsearch 6.X 中,一个 index 下已经只能包含一个 type
- Elasticsearch 7.X 中,Type 的概念已经被删除了。
创建索引 - PUT
对比关系型数据库,创建索引就等同于创建数据库。
在 ApiPost 中,向 ES 服务器发 PUT 请求 : http://127.0.0.1:9200/shopping
请求后,服务器返回响应:
{
"acknowledged": true, // 响应结果
"shards_acknowledged": true, // 分片结果
"index": "shopping" // 索引名称
}
后台日志:
[2022-03-09T21:41:00,928][INFO ][o.e.c.m.MetadataCreateIndexService] [air.local] [shopping] creating index, cause [api], templates [], shards [1]/[1], mappings
如果重复发 PUT 请求 : http://127.0.0.1:9200/shopping 添加索引,会返回错误信息:
{
"error": {
"root_cause": [
{
"type": "resource_already_exists_exception",
"reason": "index [shopping/8g4CcOYrRneyo-XSmAFs1Q] already exists",
"index_uuid": "8g4CcOYrRneyo-XSmAFs1Q",
"index": "shopping"
}
],
"type": "resource_already_exists_exception",
"reason": "index [shopping/8g4CcOYrRneyo-XSmAFs1Q] already exists",
"index_uuid": "8g4CcOYrRneyo-XSmAFs1Q",
"index": "shopping"
},
"status": 400
}
查询单个索引 - GET
向 ES 服务器发 GET 请求:http://127.0.0.1:9200/shopping
{
"shopping": {
// 索引名
"aliases": {
}, // 别名
"mappings": {
}, // 映射
"settings": {
// 设置
"index": {
// 设置 - 索引
"creation_date": "1617861426847", // 设置 - 索引 - 创建时间
"number_of_shards": "1", // 设置 - 索引 - 主分片数量
"number_of_replicas": "1", // 设置 - 索引 - 主分片数量
"uuid": "J0WlEhh4R7aDrfIc3AkwWQ", // 设置 - 索引 - 主分片数量
"version": {
// 设置 - 索引 - 主分片数量
"created": "7080099"
},
"provided_name": "shopping" // 设置 - 索引 - 主分片数量
}
}
}
}
查询所有索引 - GET
向 ES 服务器发 GET 请求:http://127.0.0.1:9200/_cat/indices?v](http://127.0.0.1:9200/_cat/indices?v)
请求路径中的 _cat 表示查看的意思,indices 表示索引,所以整体含义就是查看当前 ES服务器中的所有索引,就好像 MySQL 中的 SHOW TABLES 的感觉,服务器响应结果如下 :
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open shopping 8g4CcOYrRneyo-XSmAFs1Q 1 1 0 0 208b 208b
| 表 | 含义 |
|---|---|
| health | 当前服务器健康状态: green(集群完整) yellow(单点正常、集群不完整) red(单点不正常) |
| status | 索引打开、关闭状态 |
| index | 索引名 |
| uuid | 索引统一编号 |
| pri | 主分片数量 |
| rep | 副本数量 |
| docs.count | 可用文档数量 |
| docs.deleted | 文档删除状态(逻辑删除) |
| store.size | 主分片和副分片整体占空间大小 |
| pri.store.size | 主分片占空间大小 |
删除索引 - DELETE
向 ES 服务器发 DELETE 请求:http://127.0.0.1:9200/shopping
返回结果如下:
{
"acknowledged": true
}
再次查看所有索引,GET http://127.0.0.1:9200/_cat/indices?v,返回结果如下:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
文档基本操作
创建文档 - POST
假设索引已经创建好了,接下来我们来创建文档,并添加数据。
这里的文档可以类比为关系型数据库中的表数据,添加的数据格式为 JSON 格式。
Content-Type选择application/json
向 ES 服务器发 POST 请求:http://127.0.0.1:9200/shopping/_doc,请求体 JSON 内容为:
{
"title":"小米手机",
"category":"小米",
"images":"http://www.gulixueyuan.com/xm.jpg",
"price":3999.00
}
注意,此处发送请求的方式必须为
POST,不能是PUT,否则会发生错误。
{
"_index": "shopping", // 索引
"_type": "_doc", // 类型-文档
"_id": "ANQqsHgBaKNfVnMbhZYU", // 唯一标识,可以类比为 MySQL 中的主键,随机生成
"_version": 1, // 版本
"result": "created", // 结果,这里的 create 表示创建成功
"_shards": {
// 分片
"total": 2, // 分片 - 总数
"successful": 1, // 分片 - 总数
"failed": 0 // 分片 - 总数
},
"_seq_no": 0,
"_primary_term": 1
}
上面的数据创建后,由于没有指定数据唯一性标识(ID),默认情况下, ES 服务器会随机生成一个。
如果想要自定义唯一性标识,需要在创建时指定:http://127.0.0.1:9200/shopping/_doc/1001,请求体 JSON:
{
"title":"小米手机",
"category":"小米",
"images":"http://www.gulixueyuan.com/xm.jpg",
"price":3999.00
}
返回结果:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1001", // 自定义唯一标识
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 1
}
如果增加数据时明确数据主键,那么请求方式也可以为
PUT,没有明确必须为POST。
主键查询 - GET
查看文档时,需要指明文档的唯一性标识,类似于 MySQL 中数据的主键查询。
向 ES 服务器发 GET 请求:http://127.0.0.1:9200/shopping/_doc/1001
返回结果如下:
这种查询方式只能查询一条数据。
{
"_index": "shopping",
"_type": "_doc",
"_id": "1001",
"_version": 4,
"_seq_no": 6,
"_primary_term": 1,
"found": true,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
}
查询一个不存在的数据,向 ES 服务器发 GET 请求:http://127.0.0.1:9200/shopping/_doc/1111
返回结果如下:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1111",
"found": false
}
全查询 - GET
查看索引下所有数据,向 ES 服务器发 GET 请求:http://127.0.0.1:9200/shopping/_search
返回结果如下:
{
"took": 133,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "AlsTb38BaAVJP39iKv8b",
"_score": 1,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_score": 1,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "1001",
"_score": 1,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
}
]
}
}
全量修改 - PUT
由于是 全量修改,所以结果是幂等的,可以使用
PUT
和新增文档一样,输入相同的 URL 地址请求,如果请求体变化,会将原有的数据内容覆盖(全部信息)。
向 ES 服务器发 POST 请求:http://127.0.0.1:9200/shopping/_doc/1001
请求体的内容为:(全部信息将会被覆盖)
{
"title":"华为手机",
"category":"华为",
"images":"http://www.gulixueyuan.com/hw.jpg",
"price":1999.00
}
修改成功后,服务器响应结果:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1001",
"_version": 5,
"result": "updated", // 数据被更新
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 7,
"_primary_term": 1
}
局部修改 - POST
由于是 局部修改,不能保证幂等,所以使用
POST
修改数据时,也可以只修改某一给条数据的局部信息。
向 ES 服务器发 POST 请求:http://127.0.0.1:9200/shopping/_update/1001
请求体的 JSON:(只会修改局部信息)
{
"doc": {
"title":"小米手机",
"category":"小米"
}
}
返回结果:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1001",
"_version": 6,
"result": "updated", // 数据被更新
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 8,
"_primary_term": 1
}
删除 - DELETE
删除一个文档不会立即从磁盘上移除,它只是被标记成已删除(逻辑删除)。
向 ES 服务器发 DELETE 请求:http://127.0.0.1:9200/shopping/_doc/1001
返回结果:
{
"_index": "shopping",
"_type": "_doc",
"_id": "1001",
"_version": 7,
"result": "deleted", // 删除成功
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 9,
"_primary_term": 1
}
文档查询操作 - GET
条件查询
URL 带参查询
示例:查找 category 为小米的文档
向 ES 服务器发 GET 请求:http://127.0.0.1:9200/shopping/_search?q=category:小米
_search?q=key:value表示以 key、value 的形式查询
URL 带参数形式查询,容易让不善者心怀恶意,或者参数值出现中文会出现乱码情况。为了避免这些情况,可以用使用带 JSON 请求体请求进行查询。
带请求体方式查询
示例:查找 category 为小米的文档
向 ES 服务器发 GET 请求:http://127.0.0.1:9200/shopping/_search,附带 JSON 请求体如下:
{
"query":{
"match":{
"category":"小米"
}
}
}
带请求体方式的查找所有内容
示例:查询所有文档内容。
向 ES 服务器发 GET 请求:http://127.0.0.1:9200/shopping/_search,附带 JSON 请求体如下:
{
"query":{
"match_all":{
}
}
}
分页查询
示例:每页有 2 条数据,查询第 1 页的内容。
向 ES 服务器发 GET请求:http://127.0.0.1:9200/shopping/_search,附带 JSON 请求体如下:
{
"query":{
"match_all":{
}
},
"from":0,
"size":2
}
查询排序
示例:通过排序查出价格最高的手机。
向 ES 服务器发 GET 请求:http://127.0.0.1:9200/shopping/_search,附带 JSON 请求体如下:
{
"query":{
"match_all":{
}
},
"sort":{
"price":{
"order":"desc"
}
}
}
多条件查询
示例:查询出小米手机,并且价格为 3999 元。
向 ES 服务器发 GET 请求:http://127.0.0.1:9200/shopping/_search,附带 JSON 请求体如下:
must相当于&&操作
{
"query":{
"bool":{
"must":[{
"match":{
"category":"小米"
}
},{
"match":{
"price":3999.00
}
}]
}
}
}
示例:查询出小米或华为牌子的手机。
向 ES 服务器发 GET 请求:http://127.0.0.1:9200/shopping/_search,附带 JSON 请求体如下:
should相当于||操作
{
"query":{
"bool":{
"should":[{
"match":{
"category":"小米"
}
},{
"match":{
"category":"华为"
}
}]
}
}
}
范围查询
MARK:这个查询有问题!!!!!!
示例:找出小米或华为的牌子,价格大于 2000 的手机。
向 ES 服务器发 GET 请求:http://127.0.0.1:9200/shopping/_search,附带 JSON 请求体如下:
{
"query":{
"bool":{
"should":[{
"match":{
"category":"小米"
}
},{
"match":{
"category":"华为"
}
}],
"filter":{
"range":{
"price":{
"gt":2000
}
}
}
}
}
}
全文检索
match 是拆分后进行模糊查询。
示例:像搜索引擎那样,如品牌输入 “小华”,返回结果带回品牌有 “小米” 和 “华为” 的。
向 ES 服务器发 GET 请求:http://127.0.0.1:9200/shopping/_search,附带 JSON 请求体如下:
{
"query":{
"match":{
"category" : "小华"
}
}
}
完全匹配
match_phrase 是一个整体的模糊查询。
示例:输入 “小华” 只匹配 “小华” 相关的内容,而不是拿 “小” 和 “华” 去匹配。
向 ES 服务器发 GET 请求:http://127.0.0.1:9200/shopping/_search,附带 JSON 请求体如下:
{
"query":{
"match_phrase":{
"category" : "小华"
}
}
}
高亮查询
向 ES 服务器发 GET 请求:http://127.0.0.1:9200/shopping/_search,附带 JSON 请求体如下
{
"query":{
"match":{
"category" : "小米"
}
},
"highlight":{
"fields":{
"category":{
} // <----高亮这字段
}
}
}
响应结果:注意看 highlight 字段
{
"took": 98,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.9400072,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "AlsTb38BaAVJP39iKv8b",
"_score": 0.9400072,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
},
"highlight": {
"category": [
"<em>小</em><em>米</em>"
]
}
}
]
}
}
聚合查询
聚合允许使用者对 es 文档进行统计分析,类似与关系型数据库中的 GROUP BY,当然还有很多其他的聚合,例如取最大值 max、平均值 avg 等等。
示例:按 price 字段进行分组
向 ES 服务器发 GET 请求:http://127.0.0.1:9200/shopping/_search,附带 JSON 请求体如下:
{
"aggs":{
//聚合操作
"price_group":{
//名称,随意起名
"terms":{
//分组
"field":"price"//分组字段
}
}
}
}
响应结果:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "shopping",
"_type": "_doc",
"_id": "AlsTb38BaAVJP39iKv8b",
"_score": 1,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "1",
"_score": 1,
"_source": {
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
},
{
"_index": "shopping",
"_type": "_doc",
"_id": "1001",
"_score": 1,
"_source": {
"title": "苹果手机",
"category": "苹果",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 4999
}
}
]
},
"aggregations": {
"price_group": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 3999,
"doc_count": 2
},
{
"key": 4999,
"doc_count": 1
}
]
}
}
}
上面返回结果会附带原始数据的。若想要不附带原始数据的结果,JSON 请求体如下:
{
"aggs":{
"price_group":{
"terms":{
"field":"price"
}
}
},
"size":0
}
响应结果:
{
"took": 13,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"price_group": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 3999,
"doc_count": 2
},
{
"key": 4999,
"doc_count": 1
}
]
}
}
}
查询映射
有了索引库,等于有了数据库中的 database。
接下来就需要建索引库 (index) 中的映射了,类似于数据库 (database) 中的表结构 (table)。
创建数据库表需要设置字段名称,类型,长度,约束等;索引库也一样,需要知道这个类型下有哪些字段,每个字段有哪些约束信息,这就叫做映射 (mapping)。
创建一个索引:
# PUT http://127.0.0.1:9200/user
创建映射:
# PUT http://127.0.0.1:9200/user/_mapping
{
"properties": {
"name":{
"type": "text",
"index": true
},
"sex":{
"type": "keyword", // 注意,无法模糊匹配
"index": true
},
"tel":{
"type": "keyword", // 注意,无法模糊匹配
"index": false // 注意,查询时会报错
}
}
}
追加数据:
#PUT http://127.0.0.1:9200/user/_create/1001
{
"name":"小米",
"sex":"男的",
"tel":"1111"
}
示例:查询 name 含有 “小” 的数据:(可以查到结果)
#GET http://127.0.0.1:9200/user/_search
{
"query":{
"match":{
"name":"小"
}
}
}
示例:查找 sex 含有 “男” 的数据:(查不到结果 )
# GET http://127.0.0.1:9200/user/_search
{
"query":{
"match":{
"sex":"男"
}
}
}
- 找不想要的结果,是因为创建映射时 “sex” 的类型为
keyword keyword必须完全匹配,“sex” 只能完全为 “男的”,才能得出原数据
查询电话:
# GET http://127.0.0.1:9200/user/_search
{
"query":{
"match":{
"tel":"11"
}
}
}
返回结果如下:
{
"error": {
"root_cause": [
{
"type": "query_shard_exception",
"reason": "failed to create query: Cannot search on field [tel] since it is not indexed.",
"index_uuid": "ivLnMfQKROS7Skb2MTFOew",
"index": "user"
}
],
"type": "search_phase_execution_exception",
"reason": "all shards failed",
"phase": "query",
"grouped": true,
"failed_shards": [
{
"shard": 0,
"index": "user",
"node": "4P7dIRfXSbezE5JTiuylew",
"reason": {
"type": "query_shard_exception",
"reason": "failed to create query: Cannot search on field [tel] since it is not indexed.",
"index_uuid": "ivLnMfQKROS7Skb2MTFOew",
"index": "user",
"caused_by": {
"type": "illegal_argument_exception",
"reason": "Cannot search on field [tel] since it is not indexed."
}
}
}
]
},
"status": 400
}
报错是因为创建映射时 “tel” 的 “index” 为 false。