一、elasticsearch文档操作是什么?
我们都知道,在数据库里面,有很多的查询语句,插入数据,更新数据,删除数据等等,那么同理,在elasticsearch当中,也有类似的操作,只不过语法跟数据库不同罢了,那么究竟怎么使用呢?下面我们来看下。
二、使用步骤
1.添加数据
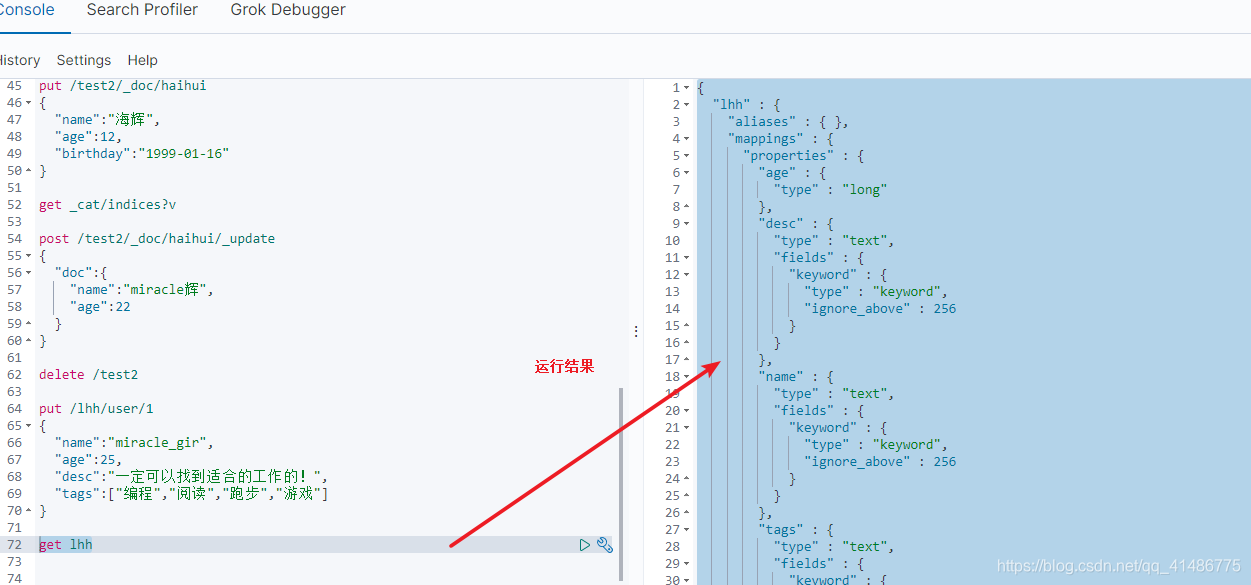
#往索引lhh里面加入一条信息
put /lhh/user/1
{
"name":"miracle_gir",
"age":25,
"desc":"一定可以找到适合的工作的!",
"tags":["编程","阅读","跑步","游戏"]
}

get lhh
#运行结果
{
"lhh" : {
"aliases" : {
},
"mappings" : {
"properties" : {
"age" : {
"type" : "long"
},
"desc" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"tags" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"settings" : {
"index" : {
"creation_date" : "1614345848042",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "3quPlmFTTiGToEZql-BBmA",
"version" : {
"created" : "7060299"
},
"provided_name" : "lhh"
}
}
}
}
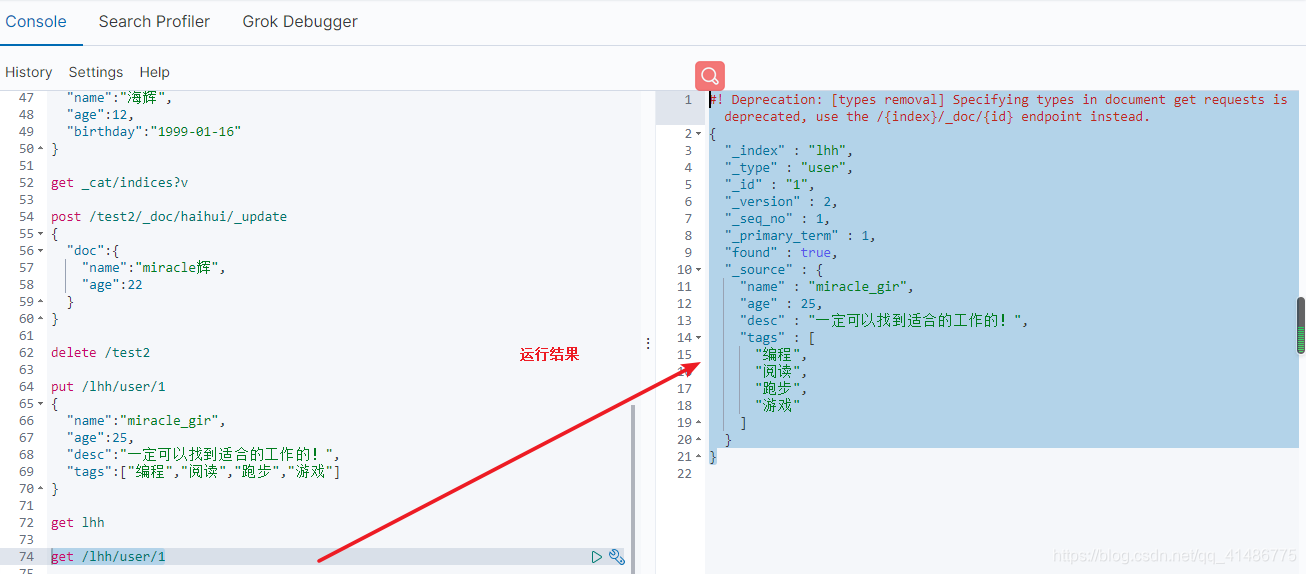
2.获取数据
#获取1号用户
get /lhh/user/1
#运行结果
#! Deprecation: [types removal] Specifying types in document get requests is deprecated, use the /{index}/_doc/{id} endpoint instead.
{
"_index" : "lhh",
"_type" : "user",
"_id" : "1",
"_version" : 2,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "miracle_gir",
"age" : 25,
"desc" : "一定可以找到适合的工作的!",
"tags" : [
"编程",
"阅读",
"跑步",
"游戏"
]
}
}
3.更新数据
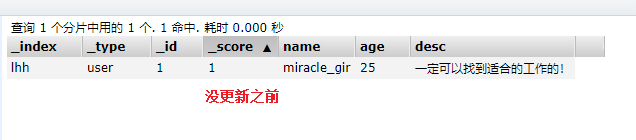
put /lhh/user/1
{
"name":"lhh_mir_gir",
"age":26,
"desc":"我慢慢爱上写代码了,不知道这是不是真的!"
}
#运行结果
#! Deprecation: [types removal] Specifying types in document index requests is deprecated, use the typeless endpoints instead (/{index}/_doc/{id}, /{index}/_doc, or /{index}/_create/{id}).
{
"_index" : "lhh",
"_type" : "user",
"_id" : "1",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}

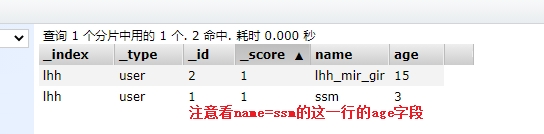
但是我们现在不全部填充字段,我们只设置两个字段,那么会发生什么呢?
put /lhh/user/1
{
"name":"lhh_mir_gir",
"age":3
}
#运行结果
#! Deprecation: [types removal] Specifying types in document index requests is deprecated, use the typeless endpoints instead (/{index}/_doc/{id}, /{index}/_doc, or /{index}/_create/{id}).
{
"_index" : "lhh",
"_type" : "user",
"_id" : "1",
"_version" : 4,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}
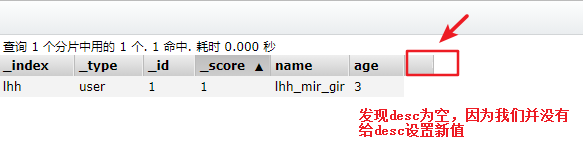
结论:put /索引/类型/文档id文档id相同的情况下会覆盖掉之前的数据。
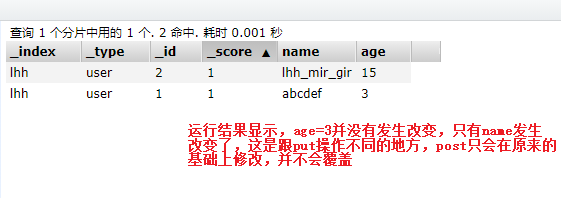
于是还有另外一种更新的操作,那就是post操作。
post /lhh/user/1/_update
{
"doc":{
"name":"abcdef"
}
}
#运行结果
#! Deprecation: [types removal] Specifying types in document update requests is deprecated, use the endpoint /{index}/_update/{id} instead.
{
"_index" : "lhh",
"_type" : "user",
"_id" : "1",
"_version" : 6,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 6,
"_primary_term" : 1
}
4.查询语句
假设我们的lhh索引里面有这些数据。
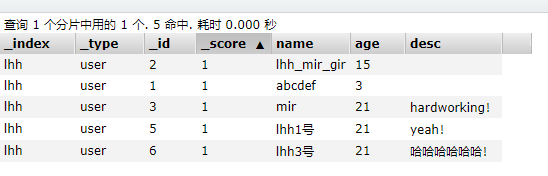
标题简单查询语句
get lhh/user/_search?q=name:lhh1号
#运行结果,其中的score就代表权重,权重越大,代表查询越精确。
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.924373,
"hits" : [
{
"_index" : "lhh",
"_type" : "user",
"_id" : "5",
"_score" : 1.924373,
"_source" : {
"name" : "lhh1号",
"age" : 21,
"desc" : "yeah!",
"tags" : [
"女生",
"音乐"
]
}
},
{
"_index" : "lhh",
"_type" : "user",
"_id" : "6",
"_score" : 0.744874,
"_source" : {
"name" : "lhh3号",
"age" : 21,
"desc" : "哈哈哈哈哈哈!",
"tags" : [
"女生"
]
}
}
]
}
}
标准查询语句
#只支持单一字段查询
get lhh/user/_search
{
"query":{
"match": {
"age": 21
}
}
}
#运行结果如下,可见当查询age=21岁时,他们的score权重是一致的。
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "lhh",
"_type" : "user",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "mir",
"age" : 21,
"desc" : "hardworking!",
"tags" : [
"编程",
"阅读",
"音乐"
]
}
},
{
"_index" : "lhh",
"_type" : "user",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "lhh1号",
"age" : 21,
"desc" : "yeah!",
"tags" : [
"女生",
"音乐"
]
}
},
{
"_index" : "lhh",
"_type" : "user",
"_id" : "6",
"_score" : 1.0,
"_source" : {
"name" : "lhh3号",
"age" : 21,
"desc" : "哈哈哈哈哈哈!",
"tags" : [
"女生"
]
}
}
]
}
}
#按照结果的过滤显示出来,只显示name字段与desc字段
get lhh/user/_search
{
"query":{
"match": {
"age": 21
}
},
"_source":["name","desc"]
}
#查询21岁的,并且只查询name和desc字段,然后按照年龄进行升序排行
get lhh/user/_search
{
"query":{
"match": {
"age": 21
}
},
"_source":["name","desc"],
"sort":[
{
"age":{
"order":"asc"
}
}
]
}
#运行结果.
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "lhh",
"_type" : "user",
"_id" : "3",
"_score" : null,
"_source" : {
"name" : "mir",
"desc" : "hardworking!"
},
"sort" : [
21
]
},
{
"_index" : "lhh",
"_type" : "user",
"_id" : "5",
"_score" : null,
"_source" : {
"name" : "lhh1号",
"desc" : "yeah!"
},
"sort" : [
21
]
},
{
"_index" : "lhh",
"_type" : "user",
"_id" : "6",
"_score" : null,
"_source" : {
"name" : "lhh3号",
"desc" : "哈哈哈哈哈哈!"
},
"sort" : [
21
]
}
]
}
}
#查询名字为lhh1号的用户,并且年龄升序排序,且只筛选3条数据(0,1,2)
get lhh/user/_search
{
"query":{
"match": {
"name":"lhh1号"
}
},
"_source":["name","desc"],
"sort":[
{
"age":{
"order":"asc"
}
}
],
"from":0,
"size":3
}
#根据运行结果来看,并没有搞懂这是什么,目前的理解是,相当于and操作。
get /lhh/user/_search
{
"query":{
"bool":{
"must":[
{
"match":{
"name":"lhh一号"
}
},
{
"match":{
"age":21
}
}
]
}
}
}
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.4499946,
"hits" : [
{
"_index" : "lhh",
"_type" : "user",
"_id" : "5",
"_score" : 1.4499946,
"_source" : {
"name" : "lhh1号",
"age" : 21,
"desc" : "yeah!",
"tags" : [
"女生",
"音乐"
]
}
},
{
"_index" : "lhh",
"_type" : "user",
"_id" : "6",
"_score" : 1.4499946,
"_source" : {
"name" : "lhh3号",
"age" : 21,
"desc" : "哈哈哈哈哈哈!",
"tags" : [
"女生"
]
}
}
]
}
}
#也不理解为什么运行结果多出来那么多,按照常理应该是or操作,只要两者当中的一者满足即可,但是这里连都不匹配的结果也显示出来了,难道es当中多条件查询可能类似于mysql中的like模糊查询?
get /lhh/user/_search
{
"query":{
"bool":{
"should":[
{
"match":{
"name":"lhh1号"
}
},
{
"match":{
"age":23
}
}
]
}
}
}
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 2.0871933,
"hits" : [
{
"_index" : "lhh",
"_type" : "user",
"_id" : "5",
"_score" : 2.0871933,
"_source" : {
"name" : "lhh1号",
"age" : 21,
"desc" : "yeah!",
"tags" : [
"女生",
"音乐"
]
}
},
{
"_index" : "lhh",
"_type" : "user",
"_id" : "7",
"_score" : 1.4499946,
"_source" : {
"name" : "lhh5号",
"age" : 23,
"desc" : "哈哈哈!",
"tags" : [
"女生"
]
}
},
{
"_index" : "lhh",
"_type" : "user",
"_id" : "6",
"_score" : 0.4499945,
"_source" : {
"name" : "lhh3号",
"age" : 21,
"desc" : "哈哈哈哈哈哈!",
"tags" : [
"女生"
]
}
},
{
"_index" : "lhh",
"_type" : "user",
"_id" : "8",
"_score" : 0.4499945,
"_source" : {
"name" : "lhh7号",
"age" : 25,
"desc" : "嘿嘿嘿!!",
"tags" : [
"男生"
]
}
},
{
"_index" : "lhh",
"_type" : "user",
"_id" : "9",
"_score" : 0.4499945,
"_source" : {
"name" : "hhl10号",
"age" : 28,
"desc" : "嘻嘻嘻!!",
"tags" : [
"女生"
]
}
}
]
}
}
#把不是21岁的用户全部打印出来。
get /lhh/user/_search
{
"query":{
"bool":{
"must_not": [
{
"match": {
"age": "21"
}
}
]
}
}
}
#运行结果
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 0.0,
"hits" : [
{
"_index" : "lhh",
"_type" : "user",
"_id" : "2",
"_score" : 0.0,
"_source" : {
"name" : "lhh_mir_gir",
"age" : 15
}
},
{
"_index" : "lhh",
"_type" : "user",
"_id" : "1",
"_score" : 0.0,
"_source" : {
"name" : "abcdef",
"age" : 3
}
},
{
"_index" : "lhh",
"_type" : "user",
"_id" : "7",
"_score" : 0.0,
"_source" : {
"name" : "lhh5号",
"age" : 23,
"desc" : "哈哈哈!",
"tags" : [
"女生"
]
}
},
{
"_index" : "lhh",
"_type" : "user",
"_id" : "8",
"_score" : 0.0,
"_source" : {
"name" : "lhh7号",
"age" : 25,
"desc" : "嘿嘿嘿!!",
"tags" : [
"男生"
]
}
},
{
"_index" : "lhh",
"_type" : "user",
"_id" : "9",
"_score" : 0.0,
"_source" : {
"name" : "hhl10号",
"age" : 28,
"desc" : "嘻嘻嘻!!",
"tags" : [
"女生"
]
}
}
]
}
}
#筛选出年龄大于等于10岁,小于等于20岁的用户
get lhh/user/_search
{
"query":{
"bool":{
"filter": [
{
"range": {
"age": {
"gte": 10,
"lte": 20
}
}
}
]
}
}
}
#运行结果
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.0,
"hits" : [
{
"_index" : "lhh",
"_type" : "user",
"_id" : "2",
"_score" : 0.0,
"_source" : {
"name" : "lhh_mir_gir",
"age" : 15
}
}
]
}
}
- lt小于
- lte小于等于
- gt大于
- gte大于等于
#多条件匹配,只要满足其中一个,即可显示出来,当然满足的条件越多,那么权重就越高。
get lhh/user/_search
{
"query":{
"bool":{
"must": [
{
"match": {
"tags": "音乐 女生"
}
}
]
}
}
}
#运行结果
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 6,
"relation" : "eq"
},
"max_score" : 2.413166,
"hits" : [
{
"_index" : "lhh",
"_type" : "user",
"_id" : "5",
"_score" : 2.413166,
"_source" : {
"name" : "lhh1号",
"age" : 21,
"desc" : "yeah!",
"tags" : [
"女生",
"音乐"
]
}
},
{
"_index" : "lhh",
"_type" : "user",
"_id" : "3",
"_score" : 1.4613955,
"_source" : {
"name" : "mir",
"age" : 21,
"desc" : "hardworking!",
"tags" : [
"编程",
"阅读",
"音乐"
]
}
},
{
"_index" : "lhh",
"_type" : "user",
"_id" : "6",
"_score" : 0.79083616,
"_source" : {
"name" : "lhh3号",
"age" : 21,
"desc" : "哈哈哈哈哈哈!",
"tags" : [
"女生"
]
}
},
{
"_index" : "lhh",
"_type" : "user",
"_id" : "7",
"_score" : 0.79083616,
"_source" : {
"name" : "lhh5号",
"age" : 23,
"desc" : "哈哈哈!",
"tags" : [
"女生"
]
}
},
{
"_index" : "lhh",
"_type" : "user",
"_id" : "9",
"_score" : 0.79083616,
"_source" : {
"name" : "hhl10号",
"age" : 28,
"desc" : "嘻嘻嘻!!",
"tags" : [
"女生"
]
}
},
{
"_index" : "lhh",
"_type" : "user",
"_id" : "8",
"_score" : 0.2792403,
"_source" : {
"name" : "lhh7号",
"age" : 25,
"desc" : "嘿嘿嘿!!",
"tags" : [
"男生"
]
}
}
]
}
}
两种分词的方式
- keyword
- standard
#keyword
get _analyze
{
"analyzer":"keyword",
"text":"lhh,你好帅呀"
}
#运行结果显示,该text并没有被分析
{
"tokens" : [
{
"token" : "lhh,你好帅呀",
"start_offset" : 0,
"end_offset" : 8,
"type" : "word",
"position" : 0
}
]
}
#standard
get _analyze
{
"analyzer":"standard",
"text":"lhh,你好帅呀"
}
#text,被分析成这么多字了
{
"tokens" : [
{
"token" : "lhh",
"start_offset" : 0,
"end_offset" : 3,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "你",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "好",
"start_offset" : 5,
"end_offset" : 6,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "帅",
"start_offset" : 6,
"end_offset" : 7,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "呀",
"start_offset" : 7,
"end_offset" : 8,
"type" : "<IDEOGRAPHIC>",
"position" : 4
}
]
}
#高亮显示查询字段(跟百度查询显示红字类似的效果)
get lhh/user/_search
{
"query":{
"term": {
"name": "lhh1号"
}
},
"highlight":{
"fields": {
"name": {
}
}
}
}
总结
特别需要注意下标点符号,字段与字段之间需要用,隔开.
还有一点:
- term,直接查询精确的
- match,会使用分词器解析,先分析文档,然后通过分析的文档进行查询