参考代码:https://blog.csdn.net/ccyyll1/article/details/126020585
softmax回归梯度计算方式,特别是i=j和i!= j时的计算问题,请看如下帖子中的描述,这个问题是反向传播梯度计算中的一个核心问题:反向传播梯度计算中的一个核心问题
直接上代码:
import torch
import torchvision
import torchvision.transforms as transforms
import numpy as np
#(2)下载并装载Fashion MNIST 数据集
mnist_train = torchvision.datasets.FashionMNIST(root='~/Datasets/FashionMNIST', train=True,
download=True, transform=transforms.ToTensor())
mnist_test = torchvision.datasets.FashionMNIST(root='~/Datasets/FashionMNIST', train=False,
download=True, transform=transforms.ToTensor())
#(3)构建迭代器
batch_size = 256
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False)
#(4)初始化学习参数
#初始化学习参数
num_inputs = 784
num_outputs = 10
w = torch.tensor(np.random.normal(0, 0.01, (num_inputs, num_outputs)), dtype=torch.float)
b = torch.zeros(num_outputs, dtype=torch.float)
w.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True)
#(5)定义相关函数
#定义Softmax决策函数
def softmax(x,w,b):
y = torch.mm(x.view(-1, num_inputs), w) + b
y_exp = y.exp()
y_sum = y_exp.sum(dim=1, keepdim=True)
return y_exp / y_sum
#定义交叉熵损失函数
def cross_entropy(y_hat, y):
#其中gather()就相当于是维度级高级的矩阵索引;并且真实值向量y中其他类别都为0所以不用考虑
return - torch.log(y_hat.gather(1, y.view(-1, 1)))
#定义梯度下降优化函数
def sgd(params, lr, batch_size):
for param in params:
param.data -= lr * param.grad / batch_size
#定义分类准确率
def accuracy(y_hat, y):
return (y_hat.argmax(dim=1) == y).float().mean().item()
#模型未训练前的准确率
def evaluate_accuracy(data_iter, net):
acc_sum, n = 0.0, 0
for X, y in data_iter:
acc_sum += (net(X , w ,b).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
#(6)开始训练并计算每轮损失
#开始训练并计算每轮损失
lr = 0.01
num_epochs = 20
net = softmax
loss = cross_entropy
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n = 0.0, 0.0, 0
for X, Y in train_iter:
l = loss(net(X, w, b), Y).sum()
l.backward()
sgd([w, b], lr, batch_size)
w.grad.data.zero_()
b.grad.data.zero_()
train_l_sum += l.item()
train_acc_sum += (net(X, w, b).argmax(dim=1) == Y).sum().item()
n += Y.shape[0]
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f'
% (epoch + 1, train_l_sum / n, train_acc_sum / n, test_acc))
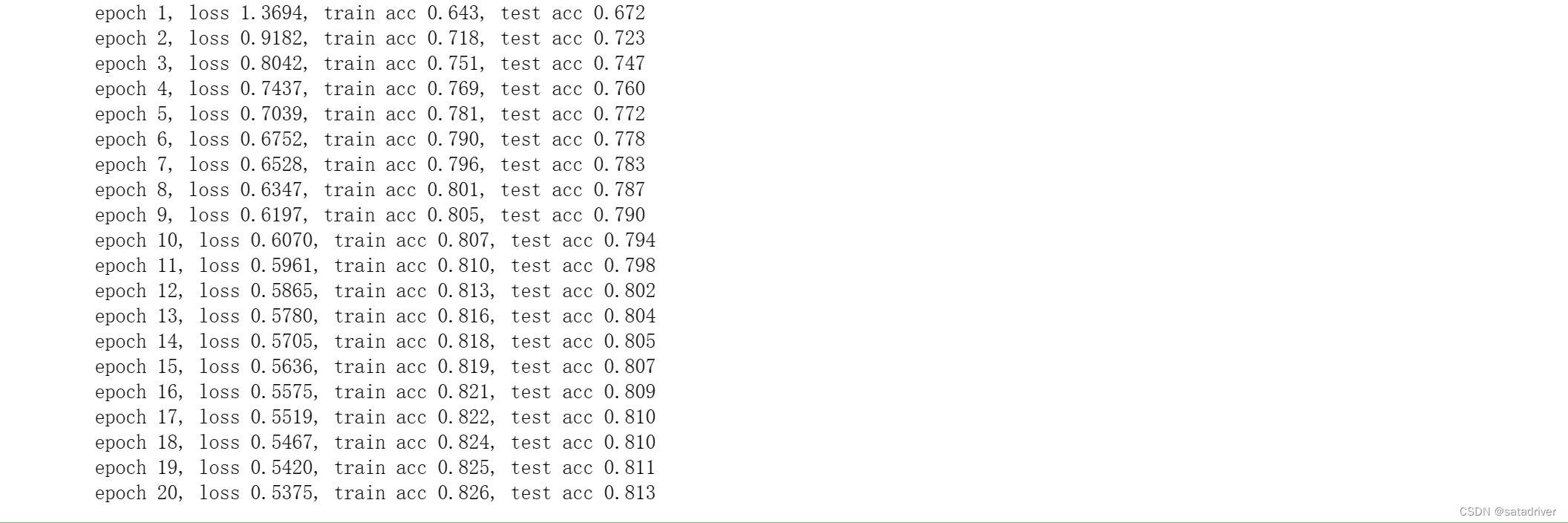
执行结果: