前言
基于docker,使用两个GPU训练自定义模型(Keras子类)。
镜像分布式策略 MirroredStrategy
分布式策略有很多,这里只介绍一种,方便快速上手,实践证明一机多卡可行
其它分布式策略详见:https://blog.csdn.net/u010099177/article/details/106074932
tf.distribute.MirroredStrategy 支持在单机多GPU上的同步分布式训练。它在每个GPU设备上创建一个副本. 模型中的每个变量都将在所有副本之间进行镜像。这些变量一起形成一个称为MirroredVariable的概念上的变量。通过应用相同的更新,这些变量彼此保持同步。
高效的归约算法用于在设备之间传递变量更新。全归约通过对不同设备上的张量相加进行聚合, 并使他们在所有设备上可用。这是一种融合算法,非常有效,可以大大减少同步的开销。根据设备之间可用的通信类型,有许多归约算法和实现可用,默认使用NVIDIA NCCL。您可以从我们提供的其他选项中进行选择,也可以自己编写。
这是创建 MirroredStrategy 最简单的方法:
strategy = tf.distribute.MirroredStrategy()
这会创建一个 MirroredStrategy 实例,将会使用TensorFlow所有可见的GPU, 使用NCCL进行跨设备通信。
如果您只想使用计算机上的某些GPU,可以这样做:
strategy = tf.distribute.MirroredStrategy(devices=["/gpu:0", "/gpu:1"])
我们已经将 tf.distribute.Strategy 集成到 tf.keras 中。tf.keras 是一个构建和训练模型的高级API。通过集成到 tf.keras 后端, 用Keras训练框架写的程序可以无缝进行分布式训练。
您需要对代码中进行以下更改:
- 创建一个
tf.distribute.Strategy实例 - 将Keras模型的创建和编译过程挪到
strategy.scope中 - 支持各种类型的Keras模型:顺序模型、函数式模型和子类模型
下面是一个非常简单的Keras模型示例:
strategy = tf.distribute.MirroredStrategy()
with strategy.scope():
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))])
model.compile(loss='mse', optimizer='sgd')
只需要将你的模型创建部分、编译部分放到strategy.scope()里即可
实现代码
关键代码如下,使用0卡和1卡:
callbacks = [tf.keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=1e-8, patience=0, verbose=2)]
opt = optimizers.SGD(learning_rate=0.001, )
strategy = tf.distribute.MirroredStrategy(devices=["/gpu:0", "/gpu:1"])
with strategy.scope():
# 创建自定义model
model = FCINN(dense_feature_columns, sparse_feature_columns, len(dense_features), hidden_units=(512, 256, 128), activation='relu', dropout=(0.3, 0.2, 0.2),
k_vector=8, w_reg=0.01, v_reg=0.01, mode='inner',
filters=[16, 18, 22, 24], kernel_with=[7, 7, 7, 7], dnn_maps=[3, 3, 3, 3], pooling_width=[2, 2, 2, 2]
)
model.compile(
optimizer=opt,
loss='binary_crossentropy',
metrics=['AUC', 'Precision', 'Recall', 'accuracy']
)
model.fit(
train_dataset,
validation_data=val_dataset,
epochs=2,
verbose=2,
callbacks=callbacks,
)
docker run -d --gpus '"device=0,1"' \
--rm -it --name ctr_tf_tmp \
-v /data/wangguisen/ctr_note/new_thought:/ad_ctr/new_thought \
-v /data/wangguisen/ctr_note/data:/ad_ctr/data \
ad_ctr:3.0 \
sh -c 'python3 -u /ad_ctr/new_thought/moreGPU.py 1>>/ad_ctr/new_thought/log/moreGPU.log 2>>/ad_ctr/new_thought/log/moreGPU.err'
成功运行
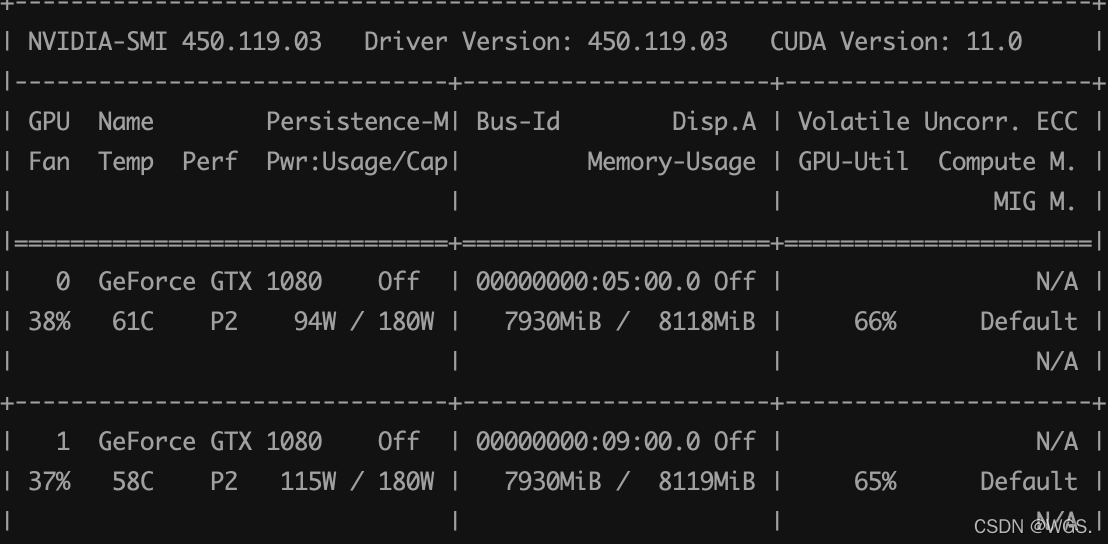
看使用率和内存占用,说明一机双卡成功运行。
一机单卡:

一机多卡:

参考:
docker指定使用某几张显卡:
https://blog.csdn.net/qq_21768483/article/details/115204043
tf2 Dataset使用:
https://blog.csdn.net/u012513618/article/details/109671774
使用 TensorFlow 2.0 进行分布式训练:
https://blog.csdn.net/u010099177/article/details/106074932