先来看假数据
colsdi = {
'suuid': ['JFOWJNlfwajlfj-falf-wa', 'lanfwlkwfNKLFNWlFA-FAL', 'P09283UJFLAWFNLF', 'P09283UJFLAWFNLF', 'P0929HAWKFNK', 'P0929HAWKFNK'],
'advertisement': ['P098', 'UFAOIJ', 'P2839', 'P0000', 'P1728', 'FAWFK;K'],
'user_modelMake': ['XIAOMI', 'HUAWEI', 'XIAOMI', 'HUAWEI', 'IPHONE', 'CHUIZI']}
data = pd.DataFrame(colsdi)
print(data.head(10))
suuid advertisement user_modelMake
0 JFOWJNlfwajlfj-falf-wa P098 XIAOMI
1 lanfwlkwfNKLFNWlFA-FAL UFAOIJ HUAWEI
2 P09283UJFLAWFNLF P2839 XIAOMI
3 P09283UJFLAWFNLF P0000 HUAWEI
4 P0929HAWKFNK P1728 IPHONE
5 P0929HAWKFNK FAWFK;K CHUIZI
比如suuid这一列,数据源就是字符串。现在想通过embedding的方式喂给模型训练。
思路:将suuid这个字符串类型的特征,通过编码转为数值类型,然后再做embedding。
先label编码数值化,再embedding
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
data['suuid'] = le.fit_transform(data['suuid'])
print(data.head(10))
suuid advertisement user_modelMake
0 0 P098 XIAOMI
1 3 UFAOIJ HUAWEI
2 1 P2839 XIAOMI
3 1 P0000 HUAWEI
4 2 P1728 IPHONE
5 2 FAWFK;K CHUIZI
通过Keras做成4维embedding,然后就可以将embedding向量作为网络的第一层使用了。
suuid_input = data[['suuid']].values
suuid_embedding = tf.keras.layers.Embedding(input_dim=len(suuid_input)+1, output_dim=4)(suuid_input)
print(suuid_embedding.numpy())
[[[ 0.02551505 -0.0435617 -0.01704413 -0.00040112]]
[[ 0.03567817 0.04994842 0.02742194 0.00932414]]
[[-0.01260977 -0.00216963 0.02565731 0.04551598]]
[[-0.01260977 -0.00216963 0.02565731 0.04551598]]
[[-0.04556284 -0.0307326 0.01235704 0.02867082]]
[[-0.04556284 -0.0307326 0.01235704 0.02867082]]]
先转为ascii码,再embedding
大家可能会说,为什么不用label编码,反而费劲转ASCII呢?
上例中,当我们线上预测的时候,避免不了会有新用户的suuid,即在训练样本空间里没有出现过的suuid,也就是说我们的label编码规则中没有出现过的suuid,对于这些新的suuid,再对他label编码,它的值只是我们的len+1。
所以将每个字符的ASCII码累加作为这个字符串的数值,能够避免这种问题。
# 利用卷积原理,将每个字符的ascii码相加作为字符串的数值
data['suuid'] = data['suuid'].apply(lambda x: sum([ord(i) for i in x]))
print(data.head(10))
suuid_input = data[['suuid']].values
suuid_embedding = tf.keras.layers.Embedding(input_dim=max(suuid_input)[0]+1, output_dim=4)(suuid_input)
print(suuid_embedding.numpy())
suuid advertisement user_modelMake
0 2025 P098 XIAOMI
1 1935 UFAOIJ HUAWEI
2 1093 P2839 XIAOMI
3 1093 P0000 HUAWEI
4 814 P1728 IPHONE
5 814 FAWFK;K CHUIZI
[[[ 0.01271845 -0.0119845 0.01830694 0.01822853]]
[[-0.03141724 0.03663817 -0.04579194 -0.00381688]]
[[-0.03575712 -0.03187815 -0.04065803 0.02061805]]
[[-0.03575712 -0.03187815 -0.04065803 0.02061805]]
[[-0.04784937 -0.02503971 0.02464626 0.01624311]]
[[-0.04784937 -0.02503971 0.02464626 0.01624311]]]

Keras Embedding 原理
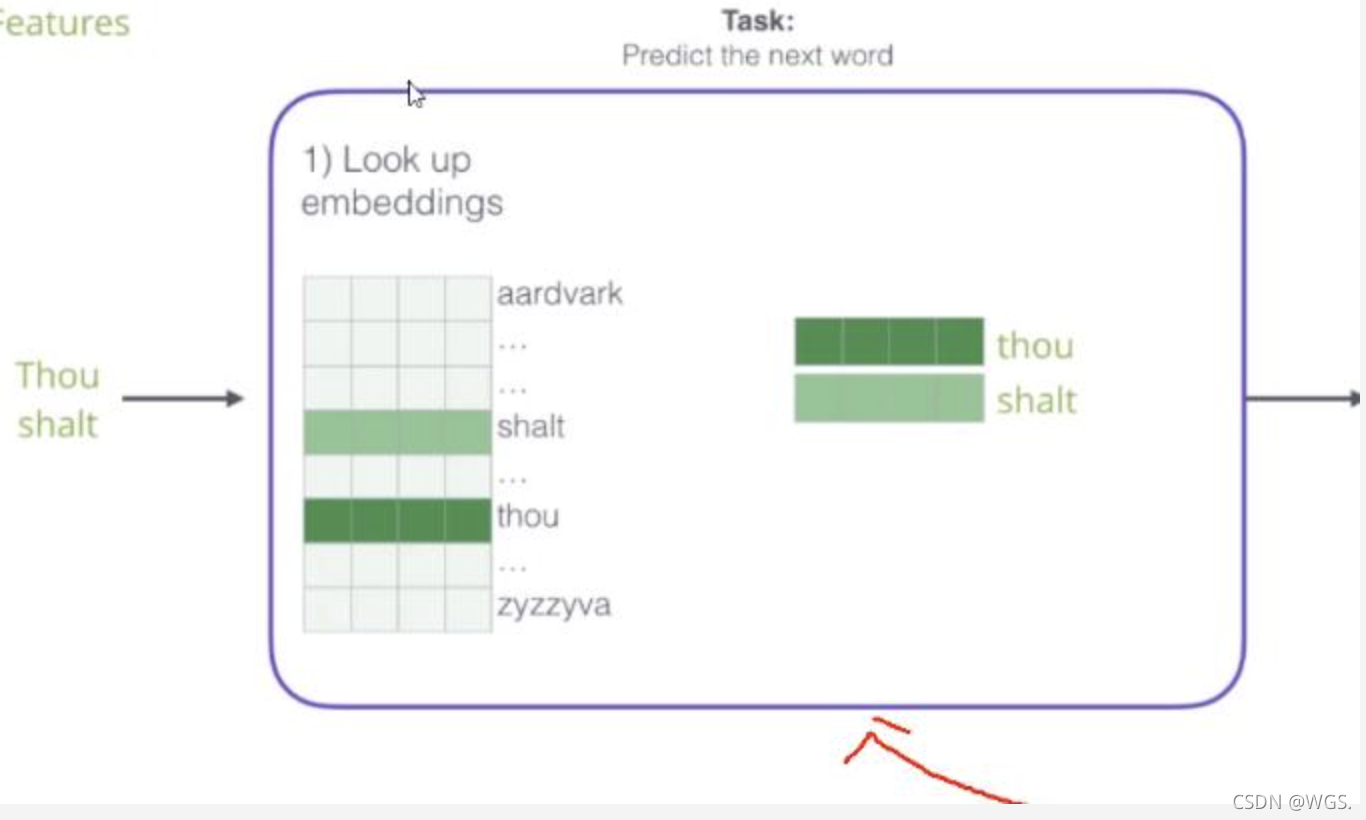
Embedding初始化后,会创建一个(input_dim, output_dim)维的embedding矩阵(随机初始化),这是作为网络第一层去学习的,和其它隐层一样通过反向传播更新权重参数。
如果要获得某个词的embedding向量,比如上图,要获得‘Thou’和‘shalt’,获取embedding矩阵行索引为2和4的数值向量,拼接然后输出(shape = [2, 4])。
https://blog.csdn.net/weixin_41845265/article/details/104124079