TF2 VAE原理及代码实现
VAE(Variational Autoencoder)
相关文章导航
损失函数
KL散度
相对熵(relative entropy),又称为KL散度(Kullback - Leibler divergence)
,信息散度,信息增益(information gain)。
KL散度是两个概率分布P和Q差别的非对称性的度量
KL散度是用来度量使用基于Q的编码来编码来自P的样本平均所需的额外的比特个数。 典型情况下,P表示数据的真实分布,Q表示数据的理论分布,模型分布,或P的近似分布。
根据shannon的信息论,给定一个字符集的概率分布,我们可以设计一种编码,使得表示该字符集组成的字符串平均需要的比特数最少。假设这个字符集是X,对x∈X,其出现概率为P(x),那么其最优编码平均需要的比特数等于这个字符集的熵: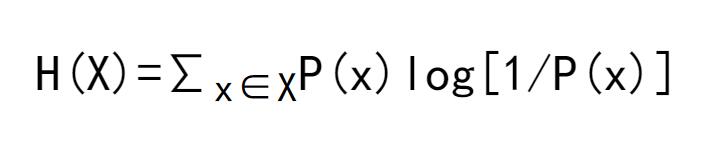
在同样的字符集上,假设存在另一个概率分布Q(X)。如果用概率分布P(X)的最优编码(即字符x的编码长度等于log[1/P(x)]),来为符合分布Q(X)的字符编码,那么表示这些字符就会比理想情况多用一些比特数。KL-divergence就是用来衡量这种情况下平均每个字符多用的比特数,因此可以用来衡量两个分布的距离。即:

由于-log(u)是凸函数,因此有下面的不等式

即KL-divergence始终是大于等于0的。当且仅当两分布相同时,KL - divergence等于0。
KL散度是两个概率分布P和Q差别的非对称性的度量。KL散度是用来度量使用基于Q的编码来编码来自P的样本平均所需的额外的位元数。
所以KL散度被运用在VAE中,它可以用来量度潜在变量的分布和单位高斯分布的差异。 被设计在了损失函数中。
但是KL散度在VAE的运用进行讲话,一下的公式的推导过程


tf代码表示损失函数
rec_loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=x, logits=x_rec_logits)
rec_loss = tf.reduce_sum(rec_loss) / x.shape[0]
# compute kl divergence (mu, var) ~ N (0, 1)
# https://stats.stackexchange.com/questions/7440/kl-divergence-between-two-univariate-gaussians
kl_div = -0.5 * (log_var + 1 - mu ** 2 - tf.exp(log_var))
kl_div = tf.reduce_sum(kl_div) / x.shape[0]
代码
在知道了VAE的损失函数后我们就可以开始逐步的更新网络接口来写代码了
数据集
数据集的我们选择tensorflow中自带的fashion_minist通过
tf.keras.datasets.fashion_mnist.load_data() 来加载即可
下面开始正式的写代码了
导入相关的模块
每次导入的模块都差不多,可以把这些代码固定在剪贴板上之后的时候直接复制过来就好
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import Sequential, layers
from PIL import Image
from matplotlib import pyplot as plt
from tensorflow.compat.v1 import ConfigProto
from tensorflow.compat.v1 import InteractiveSession
config = ConfigProto()
config.gpu_options.allow_growth = True
session = InteractiveSession(config=config)
tf.random.set_seed(2233)
np.random.seed(2233)
assert tf.__version__.startswith('2.')
定义一个保存图片的函数
为了看到网络训练的效果我们写一个拼接多张图片并保存到本地的一个函数
def save_images(imgs, name):
new_im = Image.new('L', (280, 280))
index = 0
for i in range(0, 280, 28):
for j in range(0, 280, 28):
im = imgs[index]
im = Image.fromarray(im, mode='L')
new_im.paste(im, (i, j))
index += 1
new_im.save(name)
加载数据集
这一部分没啥好说的,都快写臭了,但是要注意的是我们在构建数据集的时候不需要lable,只要给图片数据就可以了。
h_dim = 20
batchsz = 512
lr = 1e-3
(x_train, y_train), (x_test, y_test) = keras.datasets.fashion_mnist.load_data()
x_train, x_test = x_train.astype(np.float32) / 255., x_test.astype(np.float32) / 255
# we do not need label
train_db = tf.data.Dataset.from_tensor_slices(x_train)
train_db = train_db.shuffle(batchsz * 5).batch(batchsz)
test_db = tf.data.Dataset.from_tensor_slices(x_test)
test_db = test_db.batch(batchsz)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
z_dim = 10
搭建网络
根据这个图片来搭建网络,整体的搭建还是很简单的属于一个比较小型的网络,只有几十万个参数。

class VAE(keras.Model):
def __init__(self):
super(VAE, self).__init__()
# Encoders
self.fc1 = layers.Dense(128)
self.fc2 = layers.Dense(z_dim)
self.fc3 = layers.Dense(z_dim)
# Decoders
self.fc4 = layers.Dense(128)
self.fc5 = layers.Dense(784)
def encoder(self, x):
h = tf.nn.relu(self.fc1(x))
mu = self.fc2(h)
# get variance
log_var = self.fc3(h)
return mu, log_var
def decoder(self, z):
out = tf.nn.relu(self.fc4(z))
out = self.fc5(out)
return out
def reparameterize(self, mu, log_var):
eps = tf.random.normal(log_var.shape)
std = tf.exp(log_var) ** 0.5
z = mu + std * eps
return z
def call(self, inputs, training=None):
# [b,784] => [b,z_dim]
mu, log_var = self.encoder(inputs)
# reparameterization trick
z = self.reparameterize(mu, log_var)
x_hat = self.decoder(z)
return x_hat, mu, log_var
模型训练
模型在训练的时候,需要注意的就是损失函数的书写,这个在上面已经写过了我们就直接上代码了
model = VAE()
model.build(input_shape=(4, 784))
model.summary()
optimizer = tf.optimizers.Adam(lr=lr)
for epoch in range(1000):
for step, x in enumerate(train_db):
# [b,28,28] => [b,784]
x = tf.reshape(x, [-1, 784])
with tf.GradientTape() as tape:
x_hat, mu, log_var = model(x)
rec_loss = tf.losses.binary_crossentropy(x, x_hat, from_logits=True)
rec_loss = tf.reduce_mean(rec_loss)
# compute kl divergence (mu, var) ~ N(0,1)
kl_div = -0.5 * (log_var + 1 - mu ** 2 - tf.exp(log_var))
kl_div = tf.reduce_mean(kl_div) / x.shape[0]
loss = rec_loss + 1. * kl_div
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step % 100 == 0:
print(epoch, step, 'kl div', float(kl_div), 'rec loss', float(rec_loss))
# evaluation
z = tf.random.normal((batchsz, z_dim))
logits = model.decoder(z)
x_hat = tf.sigmoid(logits)
x_hat = tf.reshape(x_hat, [-1, 28, 28]).numpy() * 255.
x_hat = x_hat.astype(np.uint8)
save_images(x_hat, 'vae_imgs/sampled_epoch_%d.png' % epoch)
训练效果
在测试效果的时候我们使用的是完全随机的数字,下面让我们来看看效果怎么样
第一张 训练一个epoch

第二张 训练两个epoch

第三张 训练三个epoch

第6张, 训练6个epoch

第15张 训练15个epoch

第20张 训练20个epoch

第100 张, 训练100个epoch

可以看到这时候的效果已经不错了哦
第150张 第150个epoch

完整代码
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import Sequential, layers
from PIL import Image
from matplotlib import pyplot as plt
from tensorflow.compat.v1 import ConfigProto
from tensorflow.compat.v1 import InteractiveSession
config = ConfigProto()
config.gpu_options.allow_growth = True
session = InteractiveSession(config=config)
tf.random.set_seed(2233)
np.random.seed(2233)
assert tf.__version__.startswith('2.')
def save_images(imgs, name):
new_im = Image.new('L', (280, 280))
index = 0
for i in range(0, 280, 28):
for j in range(0, 280, 28):
im = imgs[index]
im = Image.fromarray(im, mode='L')
new_im.paste(im, (i, j))
index += 1
new_im.save(name)
h_dim = 20
batchsz = 512
lr = 1e-3
(x_train, y_train), (x_test, y_test) = keras.datasets.fashion_mnist.load_data()
x_train, x_test = x_train.astype(np.float32) / 255., x_test.astype(np.float32) / 255
# we do not need label
train_db = tf.data.Dataset.from_tensor_slices(x_train)
train_db = train_db.shuffle(batchsz * 5).batch(batchsz)
test_db = tf.data.Dataset.from_tensor_slices(x_test)
test_db = test_db.batch(batchsz)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
z_dim = 10
class VAE(keras.Model):
def __init__(self):
super(VAE, self).__init__()
# Encoders
self.fc1 = layers.Dense(128)
self.fc2 = layers.Dense(z_dim)
self.fc3 = layers.Dense(z_dim)
# Decoders
self.fc4 = layers.Dense(128)
self.fc5 = layers.Dense(784)
def encoder(self, x):
h = tf.nn.relu(self.fc1(x))
mu = self.fc2(h)
# get variance
log_var = self.fc3(h)
return mu, log_var
def decoder(self, z):
out = tf.nn.relu(self.fc4(z))
out = self.fc5(out)
return out
def reparameterize(self, mu, log_var):
eps = tf.random.normal(log_var.shape)
std = tf.exp(log_var) ** 0.5
z = mu + std * eps
return z
def call(self, inputs, training=None):
# [b,784] => [b,z_dim]
mu, log_var = self.encoder(inputs)
# reparameterization trick
z = self.reparameterize(mu, log_var)
x_hat = self.decoder(z)
return x_hat, mu, log_var
model = VAE()
model.build(input_shape=(4, 784))
model.summary()
optimizer = tf.optimizers.Adam(lr=lr)
for epoch in range(1000):
for step, x in enumerate(train_db):
# [b,28,28] => [b,784]
x = tf.reshape(x, [-1, 784])
with tf.GradientTape() as tape:
x_hat, mu, log_var = model(x)
rec_loss = tf.losses.binary_crossentropy(x, x_hat, from_logits=True)
rec_loss = tf.reduce_mean(rec_loss)
# compute kl divergence (mu, var) ~ N(0,1)
kl_div = -0.5 * (log_var + 1 - mu ** 2 - tf.exp(log_var))
kl_div = tf.reduce_mean(kl_div) / x.shape[0]
loss = rec_loss + 1. * kl_div
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step % 100 == 0:
print(epoch, step, 'kl div', float(kl_div), 'rec loss', float(rec_loss))
# evaluation
z = tf.random.normal((batchsz, z_dim))
logits = model.decoder(z)
x_hat = tf.sigmoid(logits)
x_hat = tf.reshape(x_hat, [-1, 28, 28]).numpy() * 255.
x_hat = x_hat.astype(np.uint8)
save_images(x_hat, 'vae_imgs/sampled_epoch_%d.png' % epoch)
参考书籍: TensorFlow 深度学习 — 龙龙老师
