笔记总结于datawhalechina.github.io的强化学习教程
0x01 离散动作和连续动作
这个不需要说太多吧。
离散动作:比如atari里的向左、向右和开火
连续动作:比如PUBG手柄玩家在驾驶载具时控制方向盘的转向角
对于离散动作,网络输出的就是所有动作集的概率。一般在最后一层套上一个softmax
对于连续动作,网络输出的就是一个具体的数值。一般来说,这个输出套一个tanh会比较好。
0x02 DDPG(深度确定性策略梯度)
Deep Deterministic Policy Gradient(DDPG) 是连续控制领域的经典强化学习算法,是DQN的扩展版本。在训练中,它借鉴了DQN的技巧:目标网络和经验回放。但是在target network的更新这一块和DQN有不同之处。
- Deep:因为用了神经网络。
- Deterministic:表示输出的是确定性动作,可以用在连续动作中。
- Policy Gradient:使用了策略梯度。在每一个step后都会更新一次数据。
下面是DDPG的网络结构图。
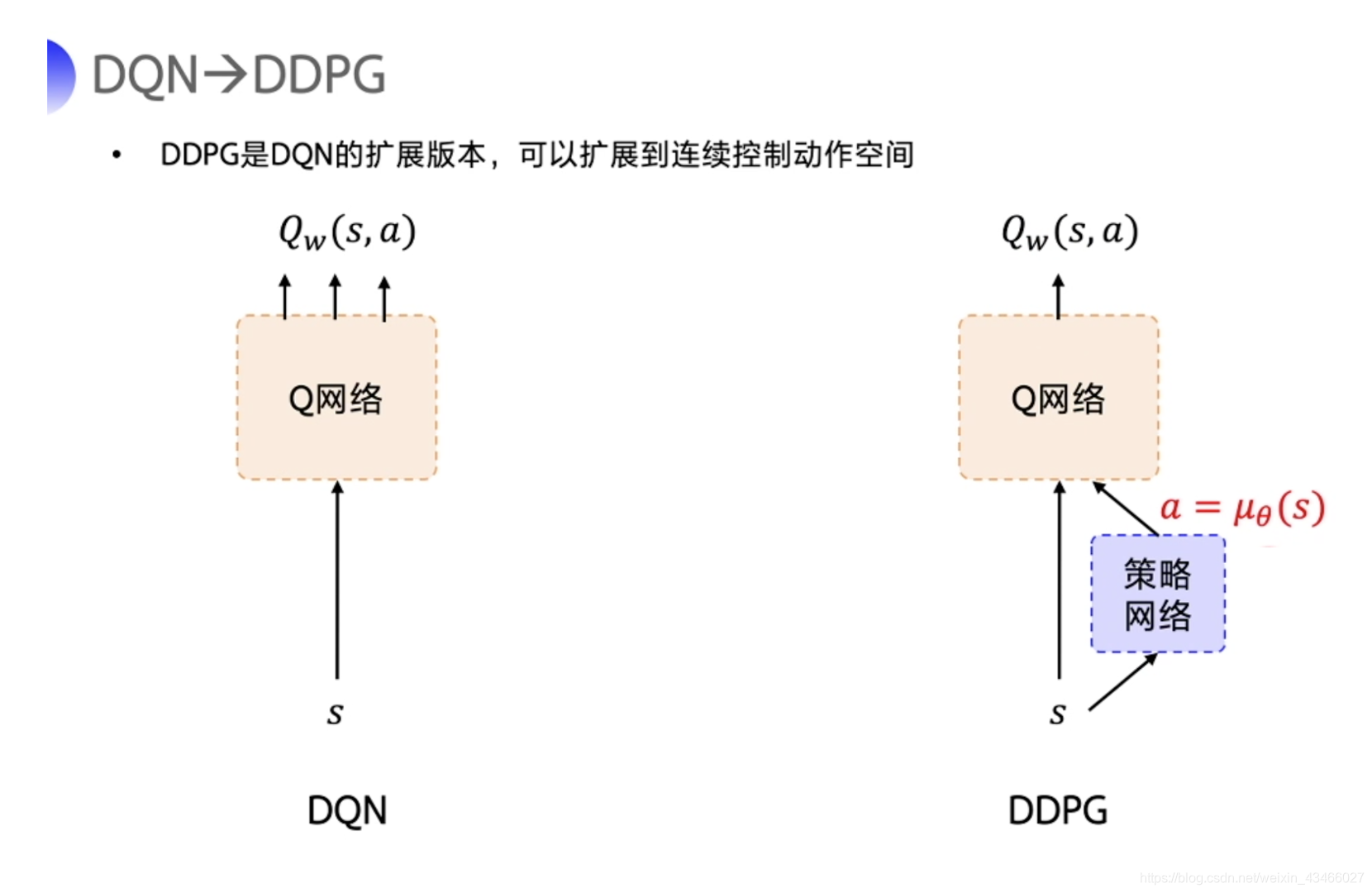
第一眼看上去的话,这个东西长得和演员评论家里的那个 Pathwise Derivative Policy Gradient 还是比较像的。
DDPG在DQN基础上加了一个actor(即策略网络)来直接输出动作值。因此,我们需要一边学习Q网络,一边学习策略网络。这也是actor-critic结构。
下面叙述一下这个网络结构干的事情:
- Q网络是critic,告知当前状态和动作之后,它会返回一个得分。
- actor网络会根据现在的状态选择下一步的动作。
- 在训练的时候,一开始Q网络瞎几把打分,actor网络也是瞎几把选动作。但是随着训练的进行,Q网络评判地越来越准,actor会逐渐选择回报高的动作来迎合Q网络。
和经典DQN的区别:连续情形
在经典的DQN中,Q网络的输出是离散的,我们会看哪个动作的Q值最高,然后我们就选哪个动作。但是连续情形下这个机制是失效的,因为我们的动作空间是连续的,再做穷举就不合适了。因此,我们不妨让网络学着怎么来找回报高的动作。
训练过程
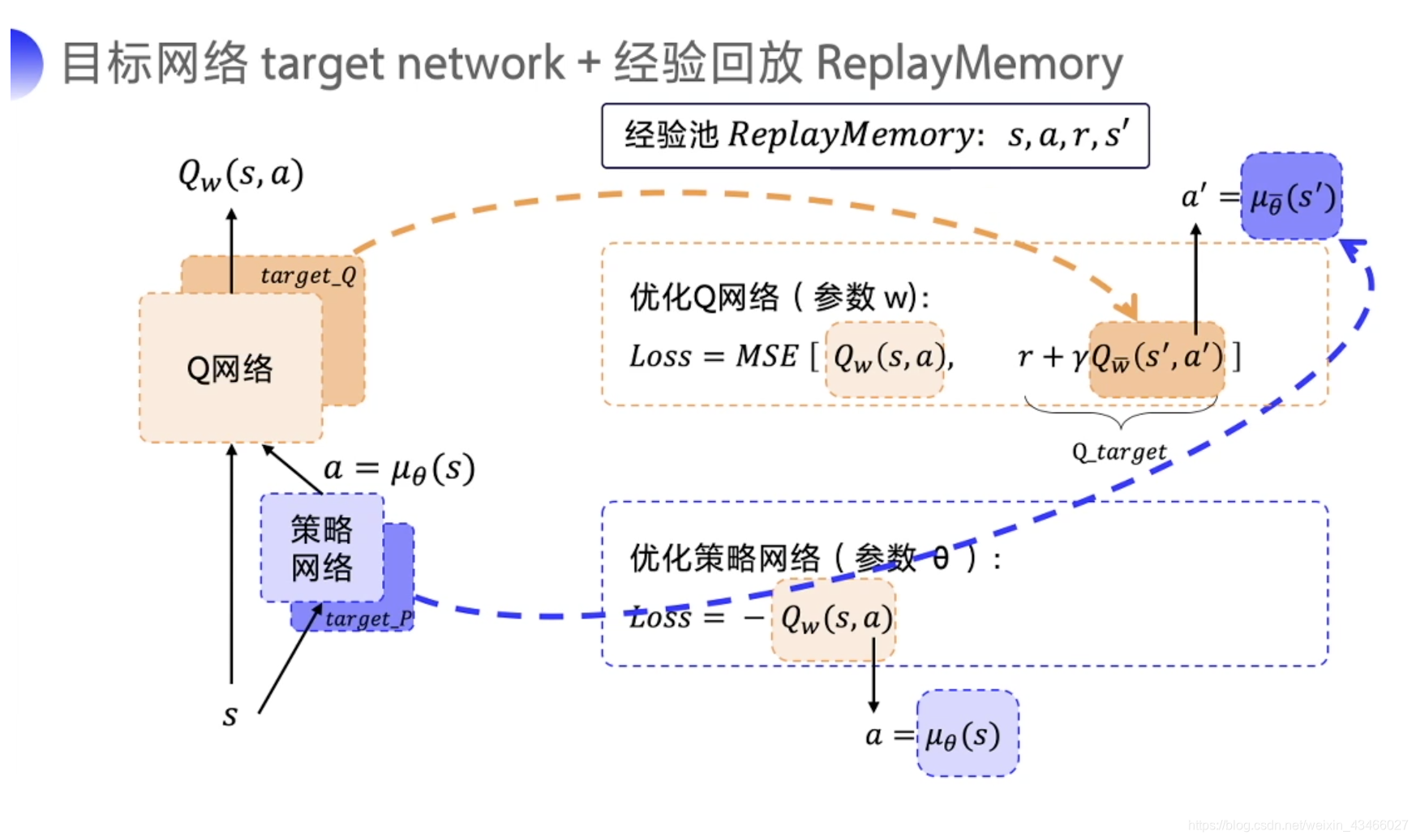
如上图,DDPG给两个网络都搭建了目标网络。
更新Q网络的步骤自然不必说,使用replay buffer和时序差分。
更新W网络的时候就是对它进行梯度上升。在训练Q网络的时候,W的参数不动。
Exploriation & Exploitation
因为策略是确定的,如果 actor 使用同策略来探索,在一开始的时候,它会很可能不会尝试足够多的 action 来找到有用的学习信号。因此,原作者构造了一个和时间相关的噪声OU noise。但是在实际操作中,我们发现高斯白噪声效果很好。随着训练的进行,可以不断减小噪声。
在测试的时候,为了查看actor的表现,我们不会在 action 中加噪音。
TD3: An optimization of DDPG
DDPG 常见的问题是已经学习好的 Q 函数开始显著地高估 Q 值,然后导致策略被破坏了,因为它利用了 Q 函数中的误差。
一个简单的想法是:可以用实际的Q值和网络输出的Q值对比。实际的Q值可以用MC来计算。比如咱们采上1000个样,用它来狠狠更新一下Q值。
双延迟深度确定性策略梯度(Twin Delayed DDPG,简称 TD3) 通过引入三个关键技巧来解决这个问题:
- 截断的双Q学习(clipped double-Q learning):TD3中用最小化均方误差同时学习两个Q网络。它们都用一个目标。两个Q网络中给出较小值的那个会被认为是target网络。
- 延迟策略更新:如果我们固定 actor 网络时,critic(即Q网络) 的效果会比较好;如果把 actor 和 critic 一起训练则效果比较烂。因此 TD3 算法以较低的频率更新 actor 网络,高频更新Q网络,通常每更新两次Q网络就更新一次actor。
- 目标策略平滑:TD3 在目标动作中加入噪音,通过平滑 Q 沿着动作的变化,使策略更难利用 Q 函数的误差。
其中,目标策略平滑的原理如下:
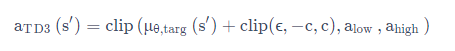
其中, ϵ \epsilon ϵ 本质上是一个噪声。
补充一点:
TD3作者自己实现的 DDPG(our DDPG) 和官方实现的 DDPG 的表现不一样,这说明 DDPG 对初始化和调参非常敏感。TD3 对参数不是这么敏感。