本文内容源自百度强化学习 7 日入门课程学习整理
感谢百度 PARL 团队李科浇老师的课程讲解
文章目录
一、离散动作 VS 连续动作
1.1 区别
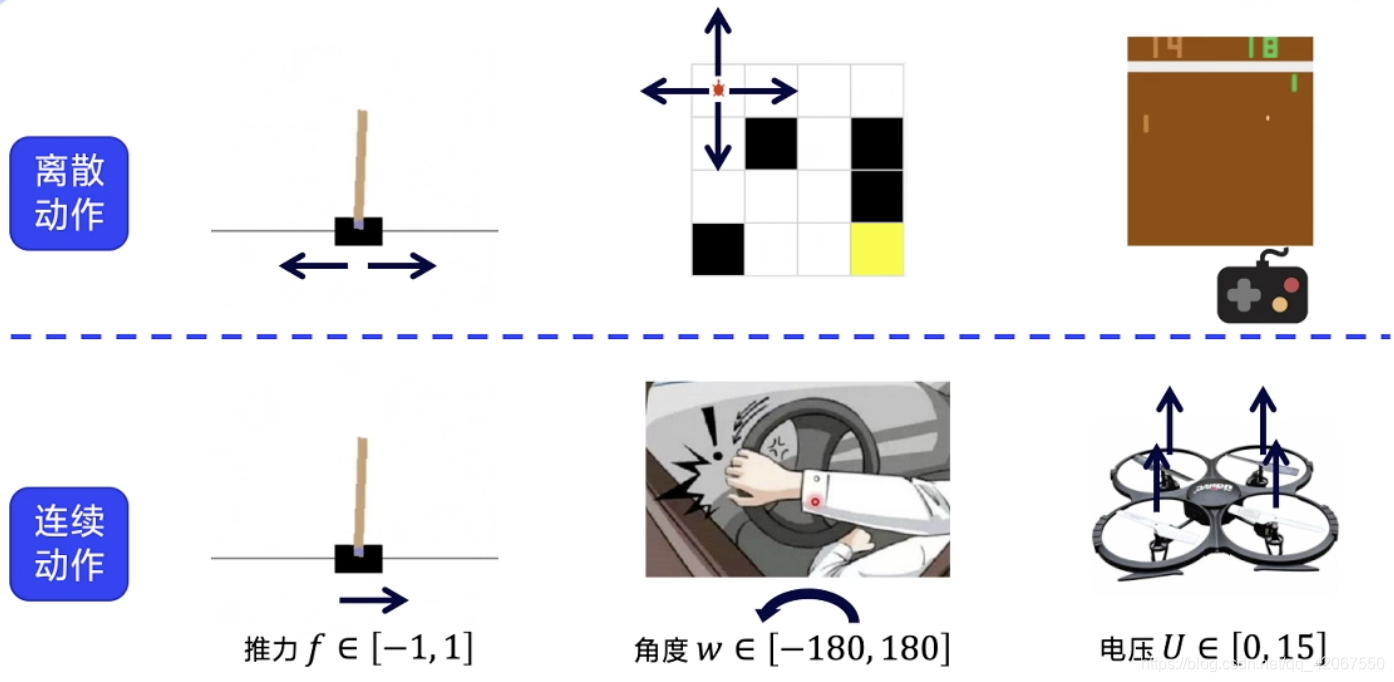
离散动作:
- 动作都是可数的
- 比如在 CartPole 环境中,向左推动小车,或者向右推动(力量是不变的)
- 比如在 FrozenLake 环境中,向上下左右 4 个方向移动
- 在 Atari 的 Pong 环境中,球拍上下移动
连续动作:
- 动作是连续的浮点数
- 比如在另一种 CartPole 环境中,设定推力为 -1~1,包含了方向又包含了力度
- 比如开车,方向盘的旋转角度:-180~180
- 四轴飞行器,控制马达的电压:0~15
1.2 神经网络修改
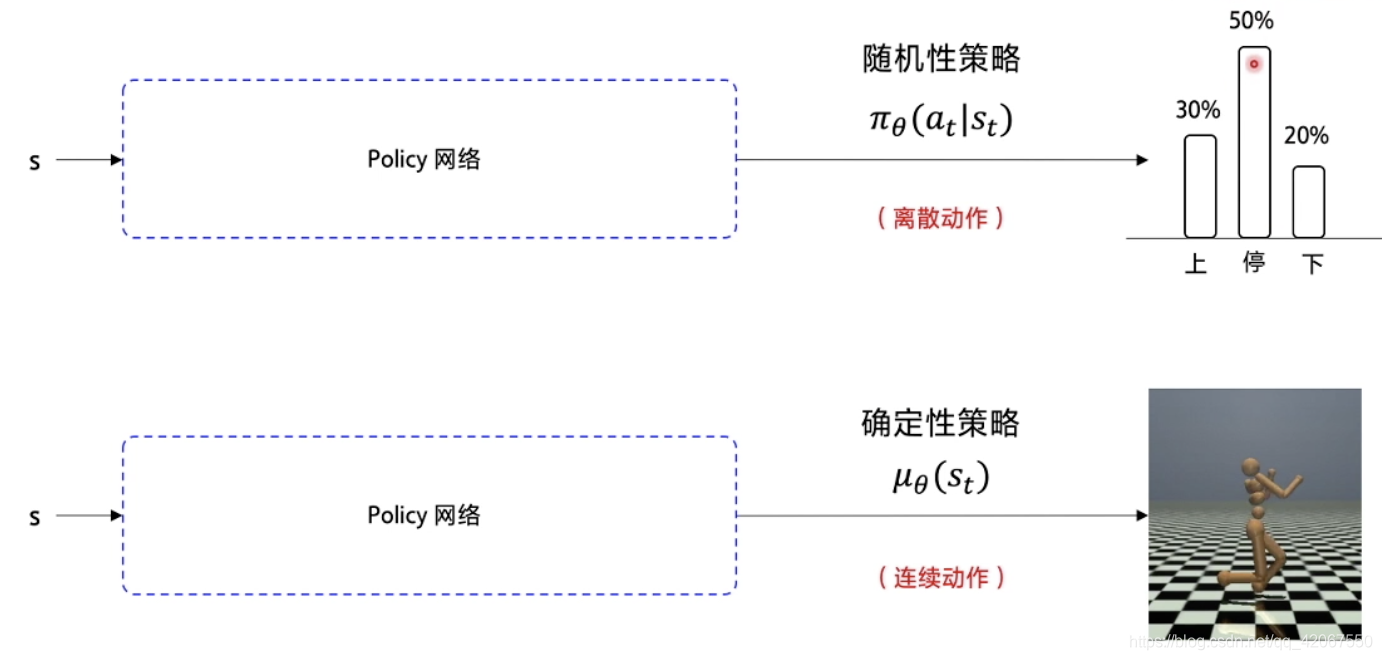
在连续动作空间中,Sarsa,Q-learning,DQN,Policy Gradient 都无法处理
所以我们要用一个替代方案:
- 在 Policy Gradient 中,输入状态 s,使用策略网络输出不同动作的概率
- 随机性策略:
- 在连续动作环境下,输出的是一个具体的浮点数,这个浮点数代表具体的动作(比如包含了方向和力的大小)
- 确定性策略:
1.3 激活函数选择
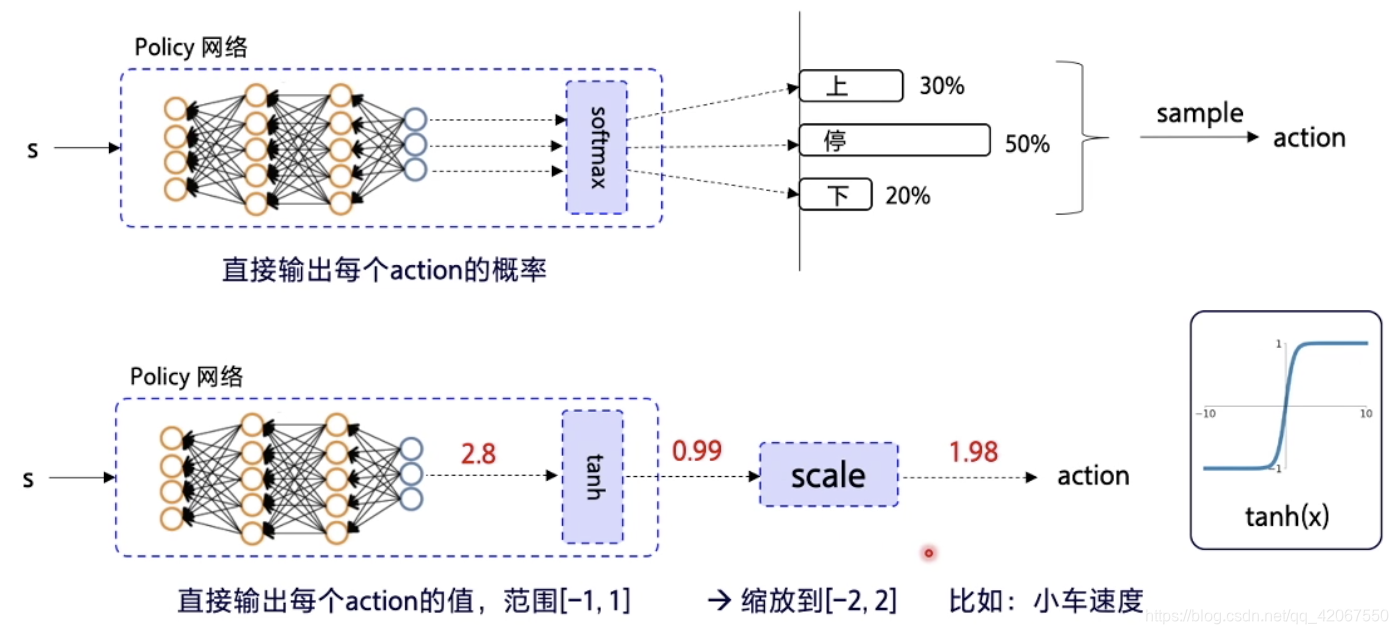
离散动作环境:
- 输出层使用 softmax,确保每个动作输出概率加总为 1
连续动作环境:
- 输出层使用 tanh,即输出为 -1~1 之间的浮点数
- 经过缩放,对应到实际动作
二、DDPG(Deep Deterministic Policy Gradient)
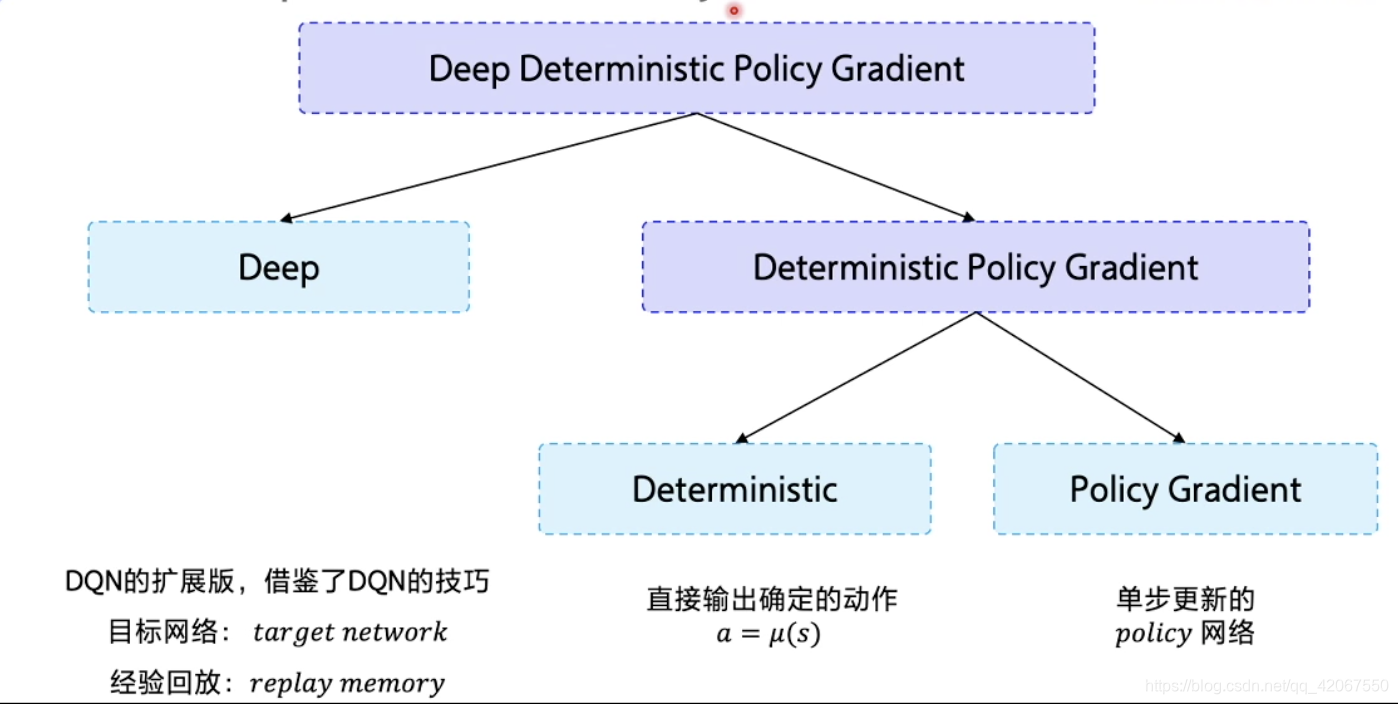
DDPG 算法可以理解为 DQN 在连续动作网络中的修正版本
- Deterministic:代表直接输出确定性动作
- Policy Gradient:是策略网络,但是是单步更新的策略网络
该算法借鉴了 DQN 的两个工程上的技巧:
- 目标网络:target network
- 经验回放:replay memory
2.1 从 DQN 到 DDPG
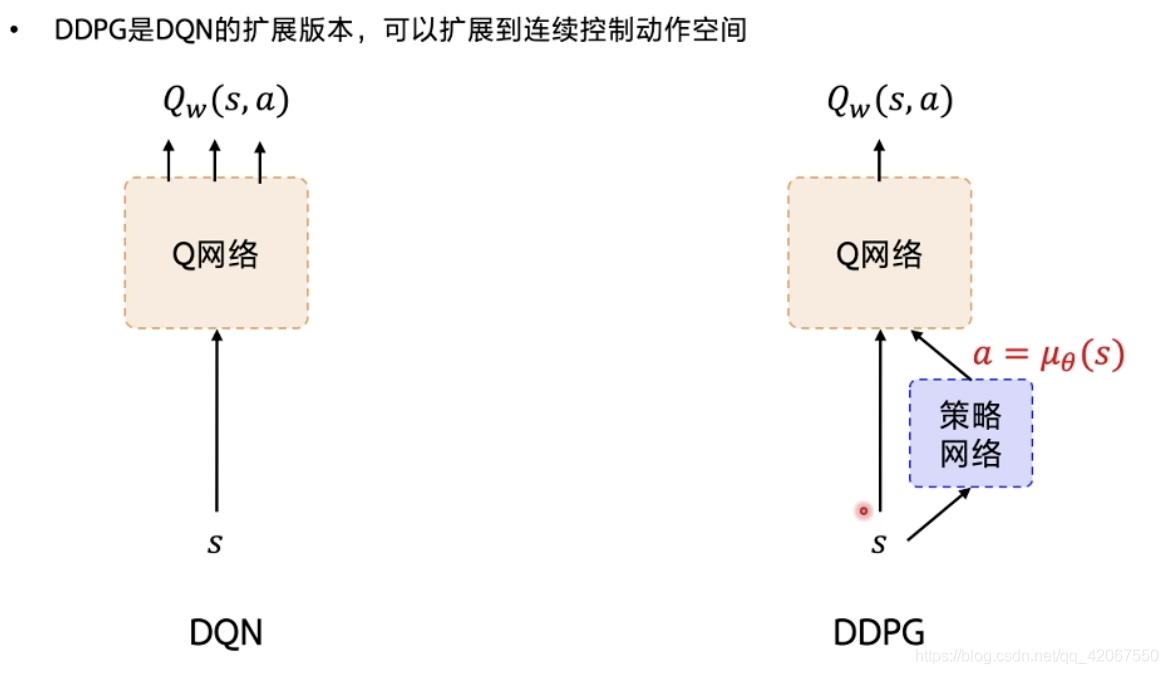
在 DQN 的基础上,加了一个策略网络 Policy Gradient,用来直接输出动作值
- 在 DQN 中,只有 Q 网络输出 不同动作对应的 Q 值
- 所以 DDPG 需要同时学习 2 个网络:Q 网络 和 策略网络
- Q 网络: ,其中参数为 w
- 策略网络: ,其中参数为 θ
- 这个结构叫做 Actor-Critic
2.2 Actor-Critic 结构

- 策略网络:扮演 Actor 的角色,负责对外展示输出
- Q 网络:评论家,每个 step 对输出动作打分,估计该动作的未来总收益(预期 Q 值)
- 策略网络 Actor 根据评委打分,来调整策略,即更新网络参数 θ,争取下次获得高分
- Critic 要根据观众的反馈来调整自己的打分策略,更新Q网络参数 w,目标是让每一步获得尽可能多的 reward(最大化未来总收益)
这种结构下,由于网络开始时候是随机的,所以一开始评委乱打分,演员乱表演,然后根据观众的反馈 reward ,Critic 的打分会越来越准确,进一步推动 Actor 的表现越来越好
2.3 DDPG 的优化目标和最佳策略
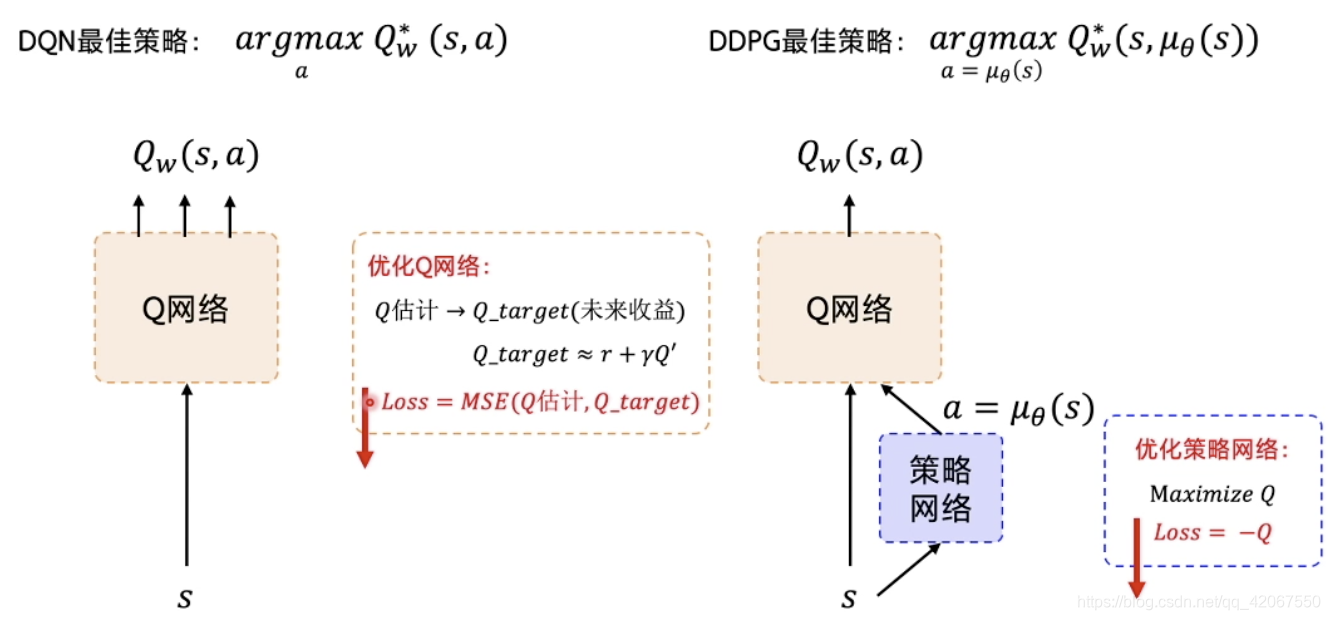
在 DQN 中,我们希望网络优化后可以求解最大的 Q 值
在 DDPG 中,我们希望网络优化后可以求解最大 Q 值对应的 action
- 策略网络的优化:最大化 Q 值,即
- Q 网络的优化:预测 Q 值 和 目标 Q 值 之间的差别最小化
- Q_target 是未来收益的总和
2.4 借鉴 DQN 中的目标网络 target network 和经验回放 ReplayMemory
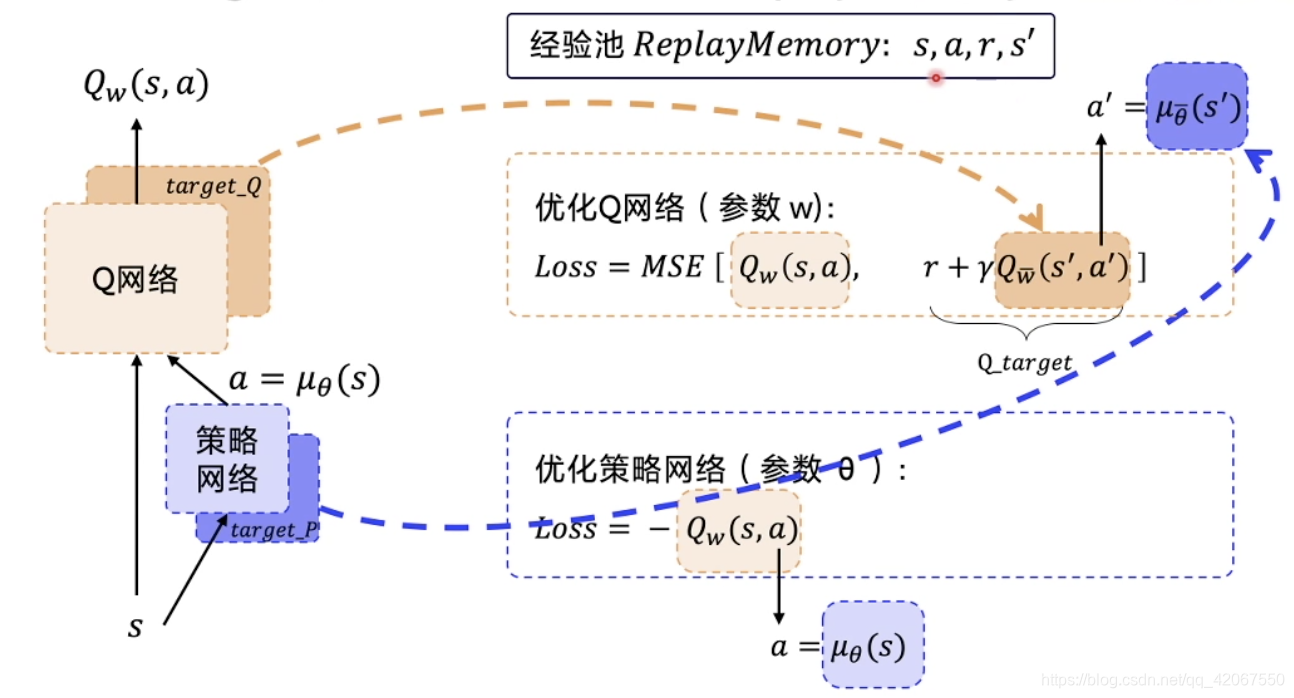
做算法更新最重要的一步,就是怎么计算
我们需要优化策略网络(参数 θ):
- 这里的 Loss 是个复合函数
- 其中 ,代入上面的 Loss 中
- 最终我们要优化的是参数 θ
还要优化 Q 网络(参数 w):
- 要优化预测 Q 和 目标 Q 的均方差
- 这里的 Loss 也是个复合函数
- KaTeX parse error: Got function '\overline' with no arguments as subscript at position 34: …),\ \ \ \ r+γQ_\̲o̲v̲e̲r̲l̲i̲n̲e̲{w}(s',a')]
- 其中 KaTeX parse error: Got function '\overline' with no arguments as subscript at position 6: a'=μ_\̲o̲v̲e̲r̲l̲i̲n̲e̲{θ}(s')
- 这里存在和 DQN 网络一样的问题,即 Q_target 的不稳定问题
- 所以我们需要固定 Q_target
为了固定 Q_target
- 我们需要给 Q 网络和 策略网络都搭建一个 target network
- target_Q 和 target_P
- 专门用于固定 Q_target
- 其中 target_P 用于固定 KaTeX parse error: Got function '\overline' with no arguments as subscript at position 6: a'=μ_\̲o̲v̲e̲r̲l̲i̲n̲e̲{θ}(s')
- 其中 target_Q 用于固定 KaTeX parse error: Got function '\overline' with no arguments as subscript at position 3: Q_\̲o̲v̲e̲r̲l̲i̲n̲e̲{w}(s',a')
- 为了用作区分,参数上面加了个横线: 和
训练网络所需的数据是:s,a,r,s’
所以经验池 ReplayMemory 中存储的就是这 4 组数据
三、 PARL 库中 DDPG 的结构
3.1 网络结构
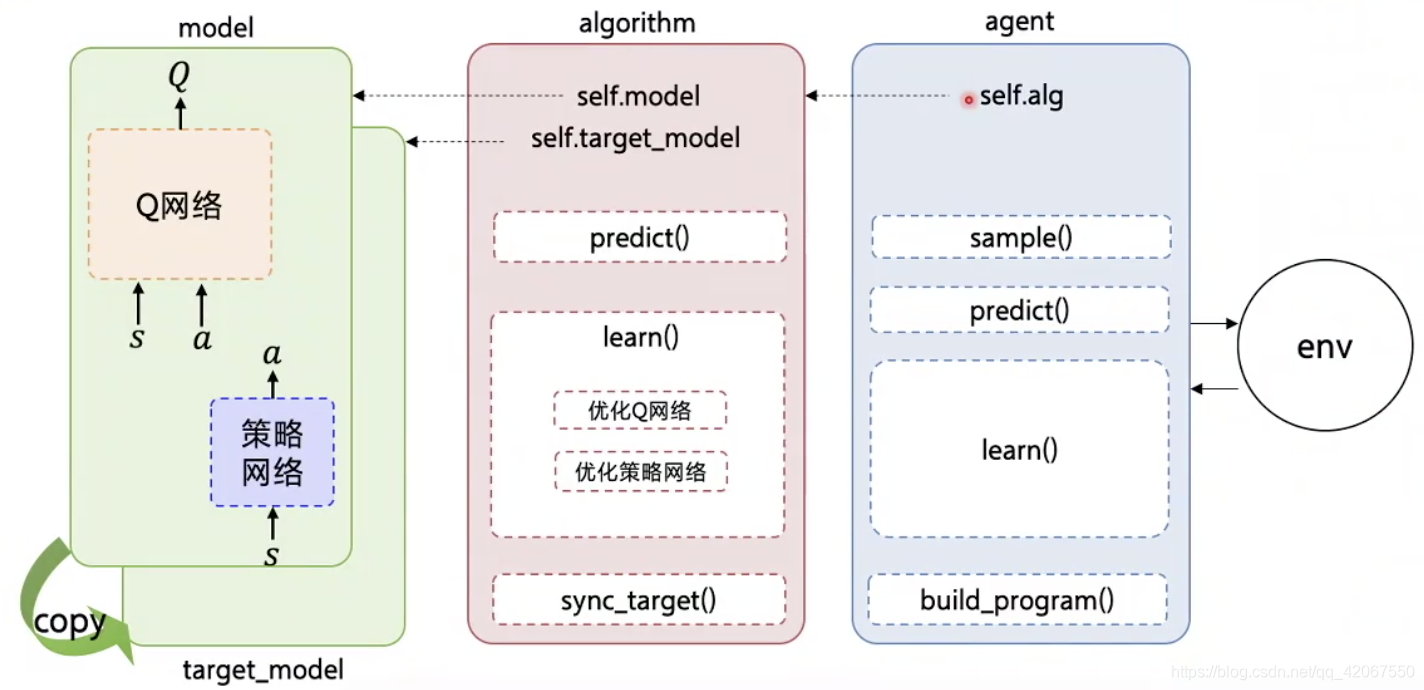
-
model:定义 Q 网络和 策略网络,及其对应的额 target_model
-
algorithm:定义损失函数,优化 Q 网络和 策略网络
-
agent:负责算法和环境的交互
3.2 核心函数
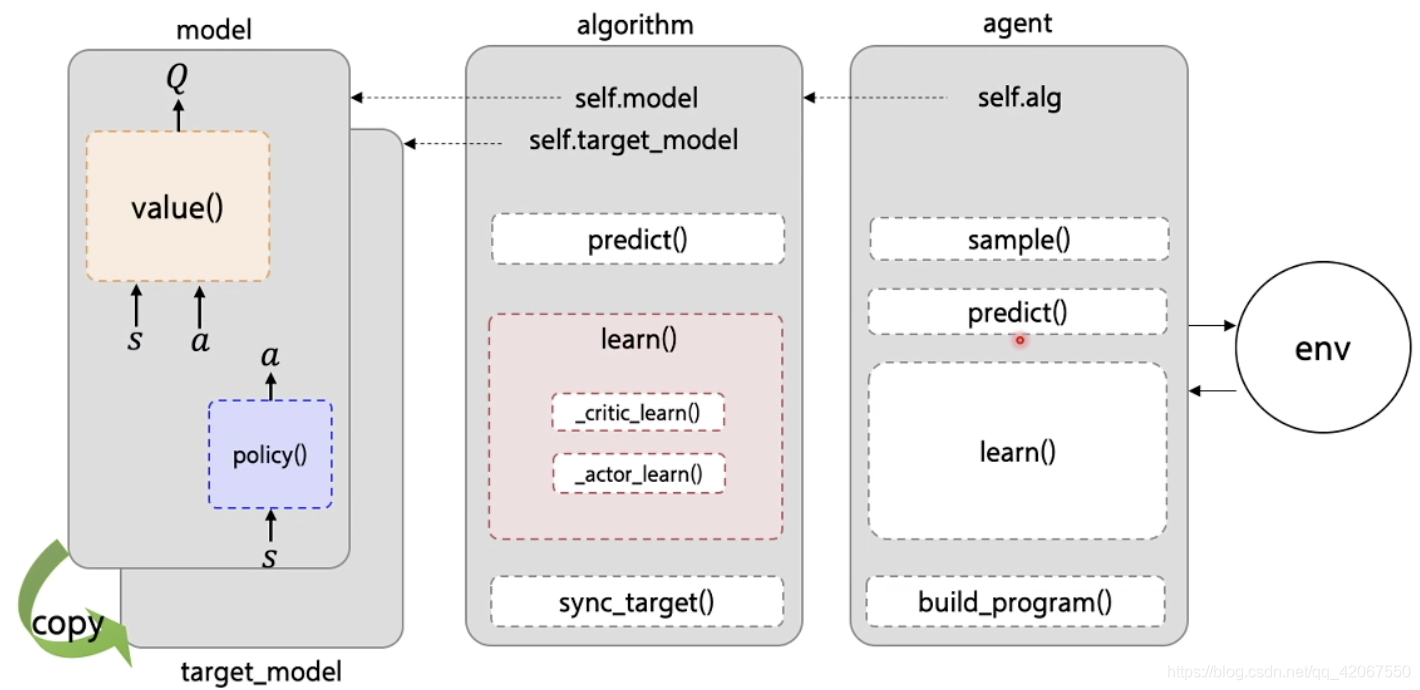
- model:
- value() 函数:形成 Q 网络的输出
- policy() 函数:表示 策略网络 的输出(动作)
- a lgorithm:
- _critic_learn():计算 Q 网路的 Loss
- _actor_learn():计算 策略网络 的 Loss
- target_model:
- 使用 deepcopy 实现
3.3 Model
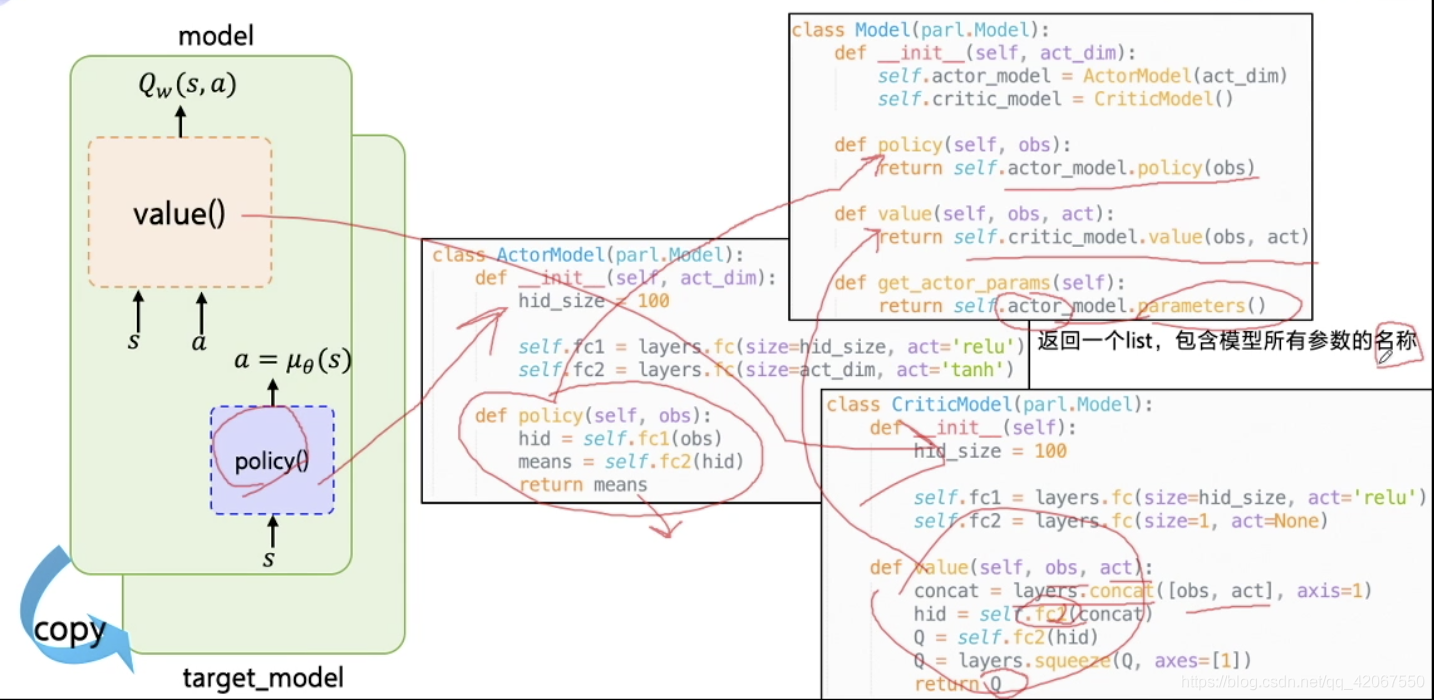
包含 3 个类:
- Model 类
- ActorModel 类
- CriticModel 类
调用的时候只需要调用 Model 这个类
- Model 下的 policy() 会自动调用 ActorModel 下的 policy() 函数
- Model 下的 value() 会自动调用 CriticModel 下的 value() 函数
注意点:
- value() 函数的输入是 obs 和 act,输出的是 Q 值
- 所以需要 layers.concat() 函数把这两个值进行拼接,然后才可以输入FC 网络
Model 类下的 get_actor_params() 方法:
- 用来获取 ActorModel 网络的 “参数名称”
- 这个在更新 Actor 网络的时候会需要使用
- 其中的 parameters() 函数已经由 PARL 在底层实现好
- 返回一个包含模型所有参数名称的 list
3.4 Critic 网络(Q网络)更新

Algorithm 中的 _critic_learn() 函数
- 这里的输入,是从经验池中 sample 出来的一个 batch 的数据
- 首先,通过 target_P 网络计算 next_action,这里输入的是 next_obs
- 然后,把 next_action 输入 target_Q 网络,计算 next_Q
- 加上 reward 以后就可以求的 Q_target
- 然后通过 Q 网络计算 预测 Q值,其与 Q_target 的均方差即为 cost
3.5 Actor 网络(策略网络)更新
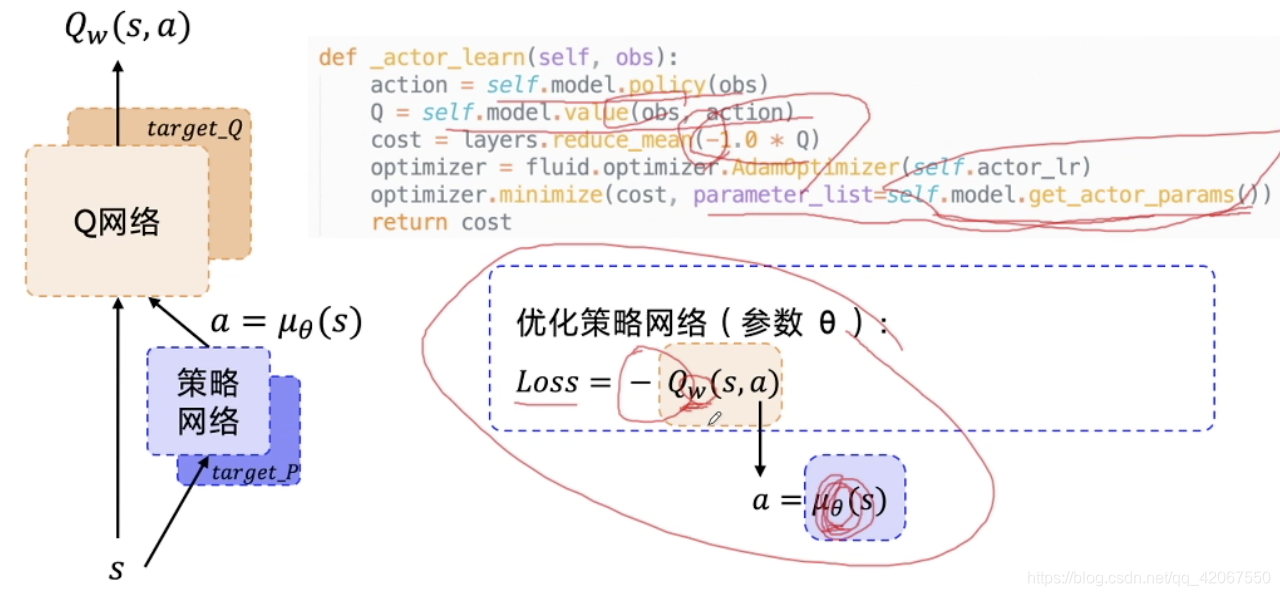
这里的计算非常简洁,不需要用到 target model
- 首先通过策略网络输出 action
- 然后通过 Q 网络输出 Q
- 计算 cost,即为 -Q
在这里需要注意的是,我们只希望这里跟新的是策略网络的参数 θ,而不是 Q 网络的参数 w
- 所以在最小化损失函数的过程中,要设定需要优化的参数是哪些
- 这里就用到了 get_actor_params() 函数
- 获得 actor 网络的参数名称,仅更新 actor 网络的参数
3.6 Target network 参数软更新
在 DQN 中,target 网络采用的是硬跟新,而在 DDPG 中,采用更平缓的软更新
- 设置参数 τ 来控制更新幅度
- 其中 w 和 θ 表示新参数
- 若 τ 取 0.001,即每次新参数只取 0.1% 的权重
- 这是工程上的一点小技巧
- PARL 库中的 sync_weights_to() 函数可以进行参数更新