问题1:商店客流量数据可视化
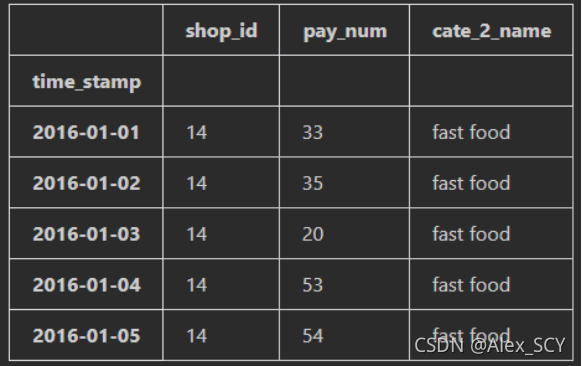
1.0 文件读取
1.shop = pd.read_csv('dataset/shop_payNum_new.csv', index_col=0, parse_dates=True)
2.shop.head()
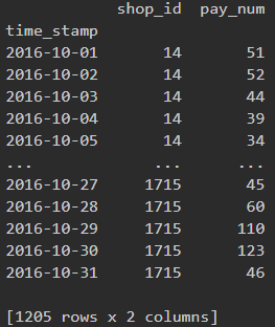
1.1绘制所有便利店的10月的客流量折线图。
第一步:筛选出所有10月的数据,并且保留shop_id和pay_num
1.Octobor_shop = shop.iloc[shop.index.month == 10, :2]
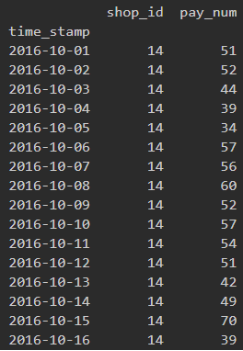
第二步:根据shop_id进行分组
df = pd.DataFrame(Octobor_shop).groupby('shop_id')
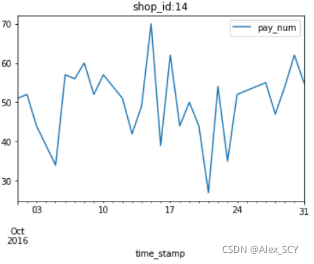
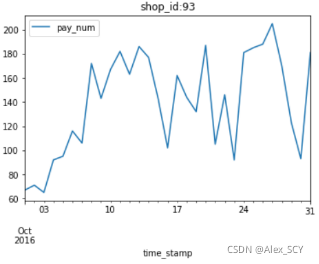
第三步:展示所有便利店的客流量数据图(一共40张图,放在一张图里过于拥挤,因此分开展示)
展示数据为pay_num,图表类型为line,标题为每一个店的ID
1.for name, group in df:
2. group.plot(y=['pay_num'], kind='line', title='shop_id:' + str(name))
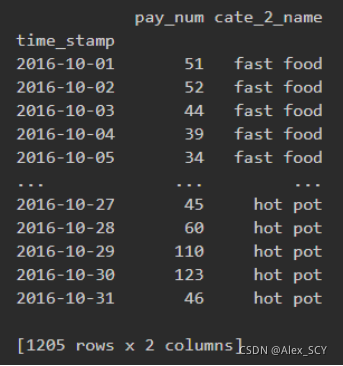
1.2绘制每类商家10月份的日平均客流量折线图。
第一步:筛选出所有10月的数据,并且保留cate_2_name和pay_num
1.Octobor_mean_shop = shop.iloc[shop.index.month == 10].drop(columns=['shop_id'])
第二步:根据商家类型进行分组
1.df = Octobor_mean_shop.groupby(['cate_2_name'])
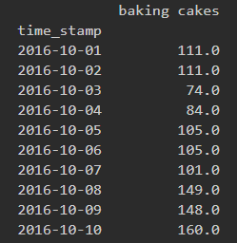
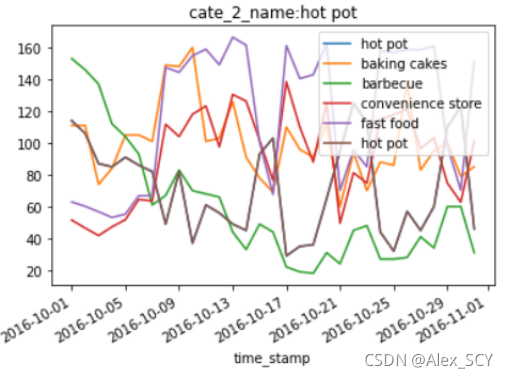
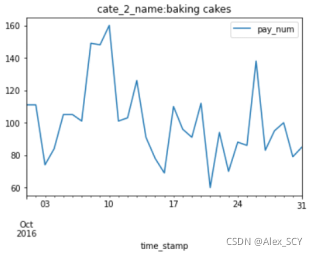
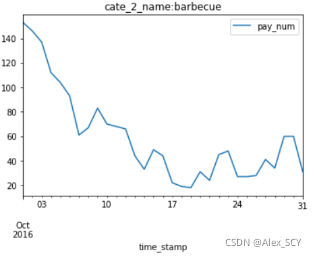
第三步:将所有信息展示在同一张表内。(一共5种类型,打印在同一张画板中,即设置参数ax=ax)
1.ax=group.plot()
2.for name, group in df:
3. group = group.groupby('time_stamp').mean()
4. group.plot(y=['pay_num'], kind='line', title='cate_2_name:' + name,ax=None)
5. group.columns=[name]
6. group.plot(ax=ax, y=[name], kind='line', title='cate_2_name:' + name)
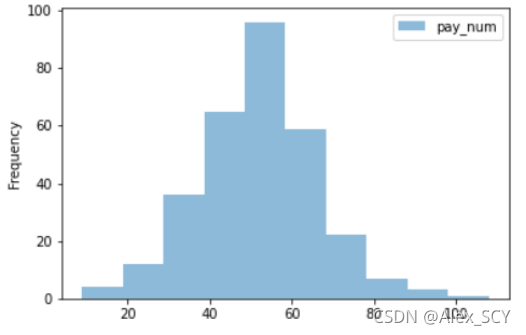
1.3选择一个商家,绘制客流量直方图。
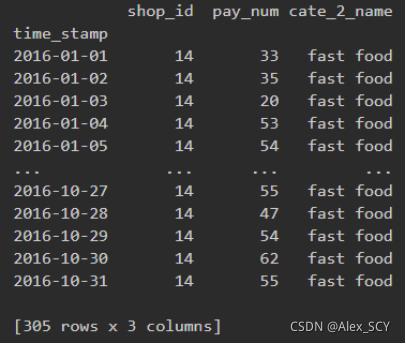
第一步:根据指定shop_id筛选出数据
1.shop_id = 14
2.people_hist = shop[shop['shop_id'] == shop_id]
第二步:打印直方图
people_hist.plot(y='pay_num', kind='hist', alpha=0.5)
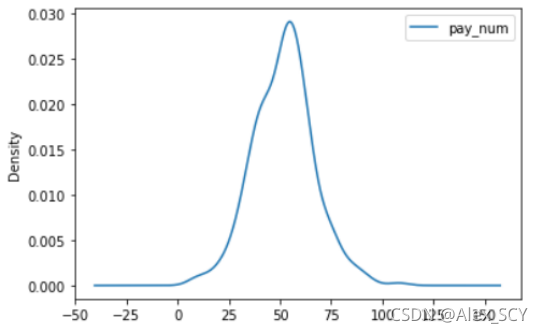
1.4选择一个商家,绘制客流量密度图。
第一步:根据指定shop_id筛选出数据
1.shop_id = 14
2.people_kde = shop[shop['shop_id'] == shop_id]
第二步:打印密度图
people_kde.plot(y='pay_num', kind='kde')
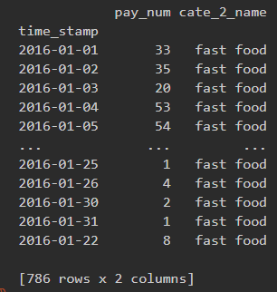
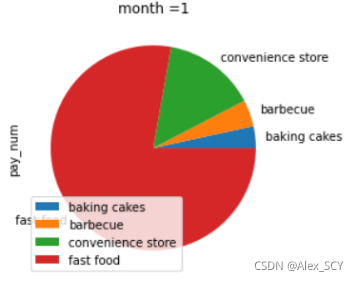
1.5统计某个月各个类别商店总客流量占该月总客流量的比例,绘制饼图。
第一步:根据指定month筛选出数据
1.month = 1
2.month_pie = shop.iloc[shop.index.month == month].drop(columns=['shop_id'])
第二步:根据商店类别进行分组,并计算所占比例
1.month_sum = month_pie.groupby('cate_2_name').sum()
2.month_rate = month_sum / month_sum.sum()
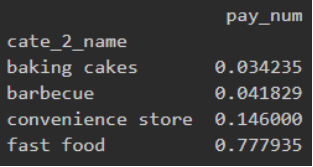
第三步:打印饼图
1.month_rate.plot(kind='pie', y='pay_num', title='month =' + str(month))
问题2:皮马印第安人糖尿病数据可视化
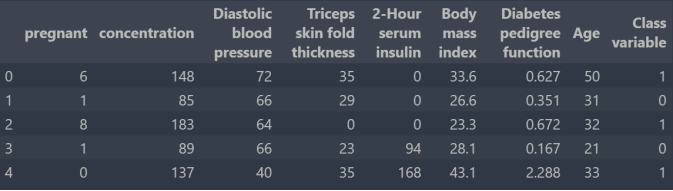
2.0 读取数据
1.data=pd.read_csv('dataset/pima.csv',header=None,
2. names=['pregnant','concentration',
3. 'Diastolic blood pressure',
4. 'Triceps skin fold thickness',
5. '2-Hour serum insulin',
6. 'Body mass index',
7. 'Diabetes pedigree function',
8. 'Age','Class variable'])
9.data.head()
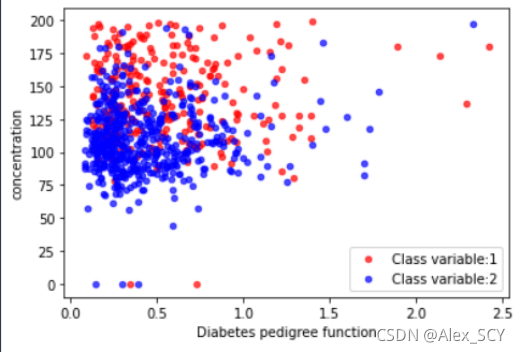
2.1 任选两个字段绘制散点图。
1.ax = data[data['Class variable']==1].plot(x='Diabetes pedigree function', y='concentration', kind='scatter', c='red', ax=None,alpha=0.7, label='Class variable:1')
2.data[data['Class variable']==0].plot(x='Diabetes pedigree function', y='concentration',kind='scatter', c='blue', ax=ax,alpha=0.7, label='Class variable:2')
根据Diabetes pedigree function和Concentration为横纵坐标,进行绘制。统计展示出Class variable两种的数据分布。
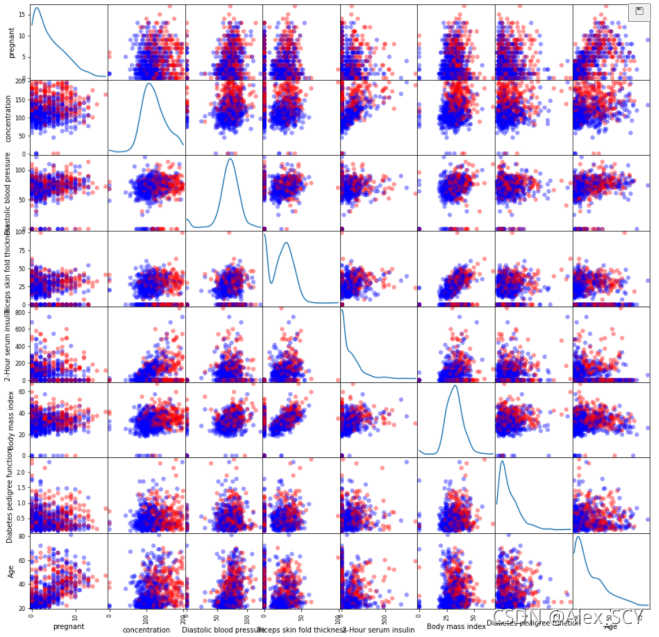
2.2 使用全部或者部分特征绘制散布图。
1.color = {
1:'red', 0:'blue'}
2.pd.plotting.scatter_matrix(data.iloc[:,:-1], figsize=(9, 9), diagonal='kde', marker='o', s=40, alpha=0.4, c=data['Class variable'].apply(lambda x: color[x]))
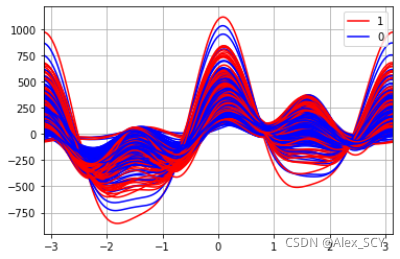
2.3 绘制调和曲线图。
1.from pandas.plotting import andrews_curves
andrews_curves(data, 'Class variable', color=['red','blue'])