【专栏:前沿进展】“结构重参数化”是清华大学丁霄汉博士近年来提出的一种通用深度学习模型设计方法论。在青源 Live 第 34 期中,丁霄汉博士分享了题为「结构重参数化与通用视觉模型的基本设计元素」的报告,介绍了结构重参数化的起源和发展,以及他基于这一思想在改进单分支模型性能、设计卷积模型组件、模型剪枝等方向的相关研究工作。

本文整理自青源 LIVE 第 34 期,视频回放链接:
https://hub.baai.ac.cn/live/?room_id=210
主讲:丁霄汉
整理:熊宇轩
审校:李梦佳

丁霄汉博士基于“结构重参数化”思想设计的 RepVGG 系列模型已被旷视力、腾讯优图、云从科技、京东等公司应用于计算机视觉业务。Speakin 公司也使用该模型在“VoxCeleb Speaker Recognition”语音识别挑战赛中获得了冠军。该模型还被广泛应用于“Real-Time Quantized Image Super-Resolution on Mobile NPUs”等比赛,取得了不俗的成绩。此外,丁博士开发的 ACNet 和 DBB 被商汤科技用于著名的人脸识别大赛 MFW 2021,并获得了该赛事的冠军。
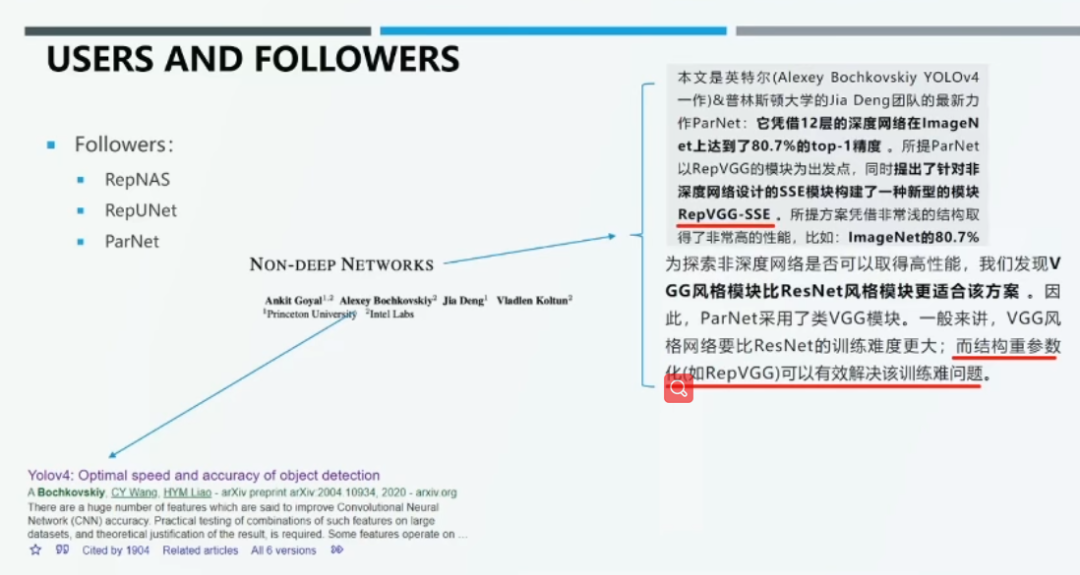
就学术界而言,结构重参数化思想近年来被广泛认可,研究者们将其应用于神经网络架构搜索(NAS)、语义分割等方面。例如,Yolov4 的作者 Alexey Bochkovskly 和 ImageNet 的作者 Jie Deng 教授在论文「Non-Deep Networks」中大量使用了结构重参数化方法。

以 RepVGG 为例,这种主干网络在精度和运算速度之间实现很好的折中,目前已获得 2100+ 的 Github stars。如上图所示,极简的 RepVGG 网络的准确率优于一些流行的主干网络。特斯拉研究总监Andrej Karpathy还在推特上推荐过RepVGG。

01
结构重参数化:以 RepVGG 为例

在这里,我们将从头到尾没有残差连接分支,仅仅由卷积层、激活函数层等部件串联组成的视觉主干模型称为「VGG 式」的模型。由于不存在残差连接分支,此类模型的并行度高、运行速度快。这是因为,在 FLOPS 相同的条件下,「大而整」的网络结构比「多而碎」的结构效率更高。VGG 式的单分支模型还可以节省显存。如上图所示,尽管残差模块并没有引入额外的计算量,但是它相较于单分支结构需要多占用一倍的显存。
此外,VGG 式的模型大量使用 3*3 卷积模块。目前,GPU 等硬件对此类模块的优化较好,计算效率较高。例如,3*3 卷积的理论计算密度是 1*1 卷积的近 4 倍。只包含简单的 3*3 卷积和激活函数等简单操作的网络对设计定制化的计算芯片更加友好,我们可以在芯片上大量集成同种计算单元,从而进一步提升计算效率。
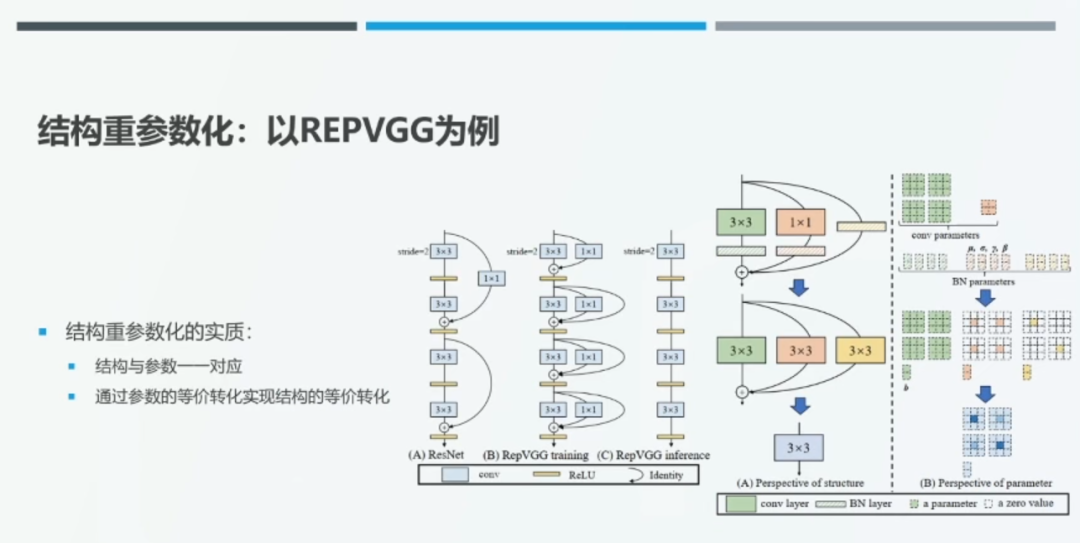
由于 ResNet 等带有残差连接分支的网络结构在训练时展现出一些优秀的性能,我们考虑为 VGG 式模型中的每一个 3*3 卷积层添加一个并行的 1*1 卷基层和恒等快捷连接(identity shortcut connection)。这种修改后的 VGG 模型在训练时具备多分支模型的优秀性质,得到较好的训练效果。在推理时,我们可以通过结构重参数化方法将修改后的 VGG 式模型转化为相应的单分支结构,实现较高的推理效率。
具体而言,我们通过参数的等价转化实现结构的等价转化。如上图右侧所示,在训练时,每一个卷积模块包含三个分支:(1)3*3 卷积+BN(2)1*1 卷积+BN(3)恒等快捷连接+BN。训练完之后,我们会得到一组确定的卷积模块的参数。我们不妨假设每一个卷积模块输入和输出的通道数都为 2,则 3*3 卷积分支的参数量为 2*2*3*3=36,1*1 卷积分支的参数为 2*2*1*1=4。
在推理时,BN 层的作用是进行一系列线性映射,因此我们可以将其转化为向卷积层添加偏置。恒等变换相当于以单位矩阵为卷积核的 1*1 卷积。此时,我们可以将卷积模块转化为一个 3*3 卷积分支和两个 1*1 卷积分支。通过零填充,我们可以进一步将所有的 1*1 卷积转化为 3*3 卷积,从而得到 3 个 3*3 卷积分支。最后,由于线性的卷积操作具有可加性,我们可以将三个分支的卷积核对应位置的元素相加,从而将 3 个 3*3 卷积融合在一起。至此,我们通过一系列参数变换将原始卷积模块中的三分支结构转化为了新的单分支 3*3 卷积结构。
02
结构重参数化研究进展
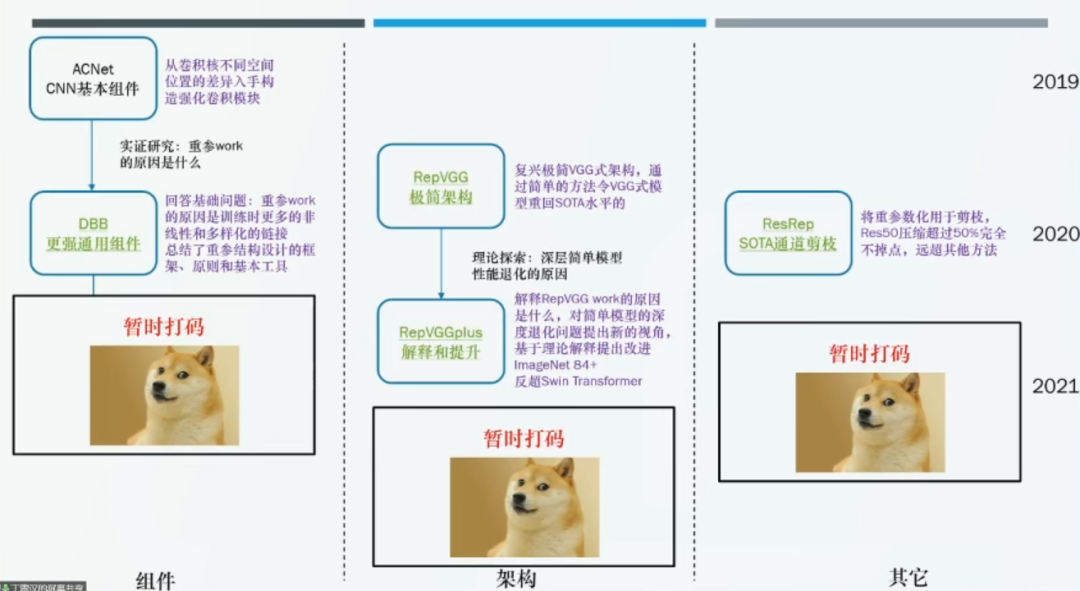
目前,丁霄汉博士已将结构重参数化方法应用于计算机视觉领域的多个任务中。其中,于 ICCV 2019 年发表的 ACNet 提出了新的 CNN 基本组件,从卷积核不同空间位置的差异入手构造了强化的卷积模块。于 CVPR 2021 发表的 DBB 解释了重参数化方法奏效的原因,并总结了重参数化结构设计的框架、原则和基本工具。
03
起源:ACNet
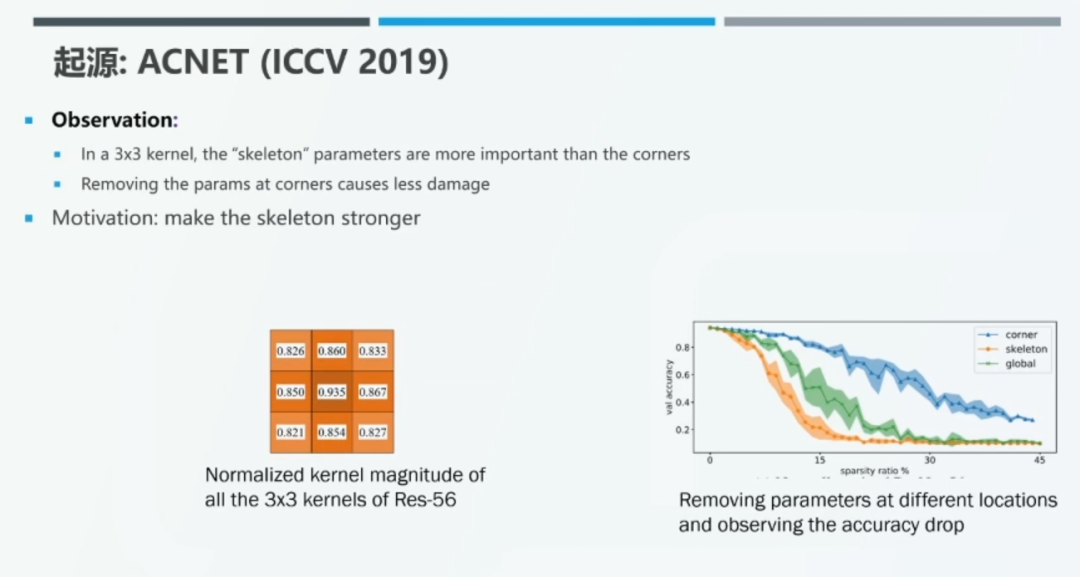
2019 年,丁霄汉博士发现,在 3*3 卷积核中,位于中心「十字」位置上的 5 个参数比位于四个角落的参数更重要。以 Res-56 为例,对于所有的 3*3 卷积核,我们根据其中的最大值对 9 个位置上的参数进行归一化。接着,我们将所有归一化后的卷积核按对应位置相加,并对求得的和再次进行归一化。我们发现,位于中心「十字」位置上的权值较大。
此外,我们对 3*3 卷积核进行非结构化剪枝,随机地将卷机和中某些位置上的权值置为零。如上图右侧所示,随着稀疏率的上升,将中心「十字」位置上的权值置为 0 的性能下降要比将位于四个角落位置上的权值置为 0 的性能下降更快。
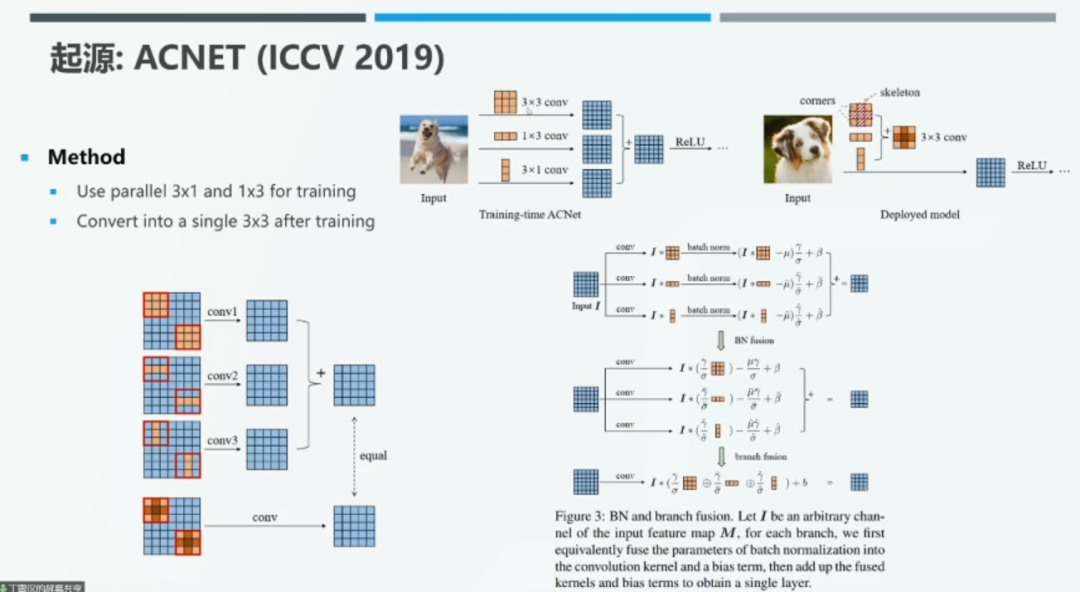
收到上述实验现象的启发,我们在训练时通过为每一个 3*3 卷积添加一个并行的 3*1 卷积和 1*3 卷积来增强模型的表示能力。在测试时,我们将 3*1 卷积和 1*3 卷积合并到 3*3 卷积中,从而增强中心「十字」位置上的权值。具体而言,我们首先将 3*3、3*1、1*3 卷积分别进行批归一化(BN)处理,再将 BN 操作合并到卷积核偏置项中。最后,我们将 1*3 和 3*1 卷积核与 3*3 卷积核中心「十字」位置上的参数相加,从而得到新的 3*3 卷积核。
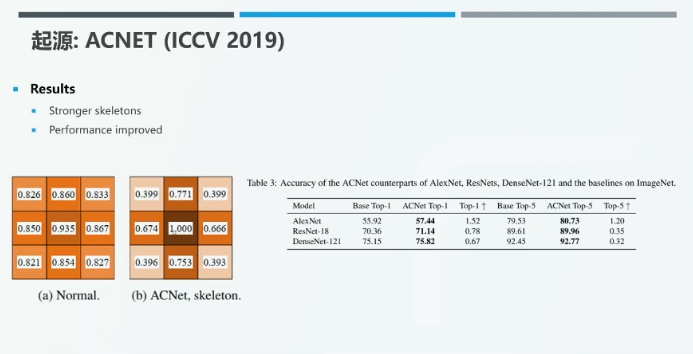
实验结果表明,中心「十字」位置上的参数确实得到了增强。如上图所示,中心点的权值被增强为 1.0。
04
DBB:结构重参数化奏效的原因
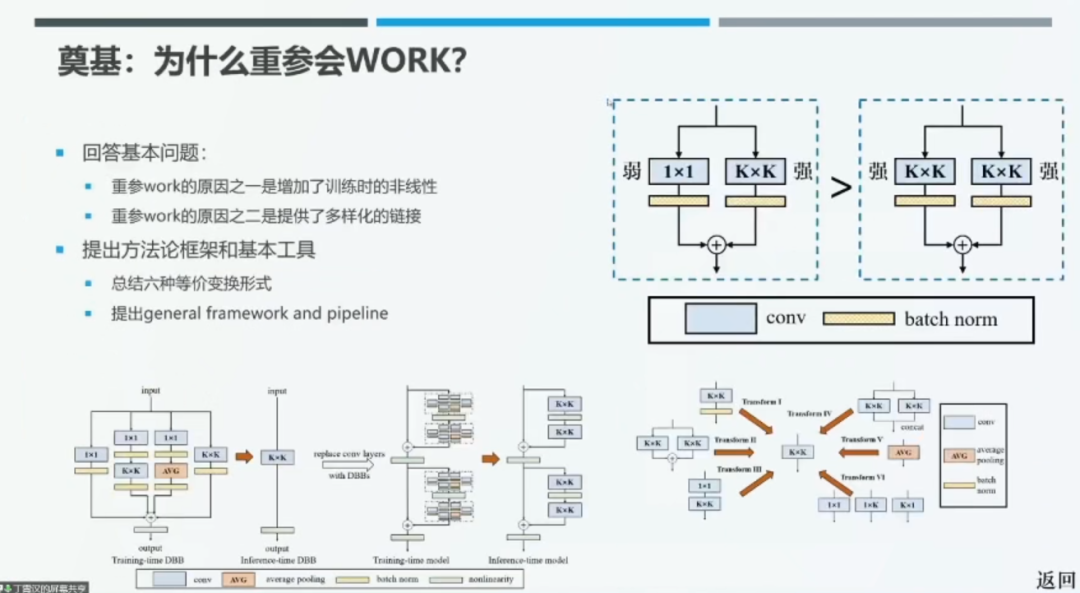
在 CVPR 2021 上发表的论文 DBB 中,丁霄汉博士将重参数化方法奏效的原因归结为:(1)增强了训练时的非线性(2)提供了多样化的链接。以 BN 层为例,BN 在测试时是线性操作,但在训练时却是非线性操作,可以有效增强模型的表征能力。如上图右上角所示,将 3*3 卷积替换为「3*3 卷积+1*1 卷积」的表征能力要强于将其替换为「3*3 卷积+3*3 卷积」。我们认为,整体架构的表征能力与使用组件的多样性息息相关。在本文中,丁博士总结了六种 K*K 卷积的等价变换形式,可以在训练时将其组合到类似于 Inception 的结构中,有效提升表征能力,并且在推理时通过重参数化技巧将复杂的结构整合到 K*K 卷积中,从而提升运算效率。该论文还提出了重参数化方法的通用框架和 pipeline。
05
拓展深度:克服 VGG 式模型的缺陷
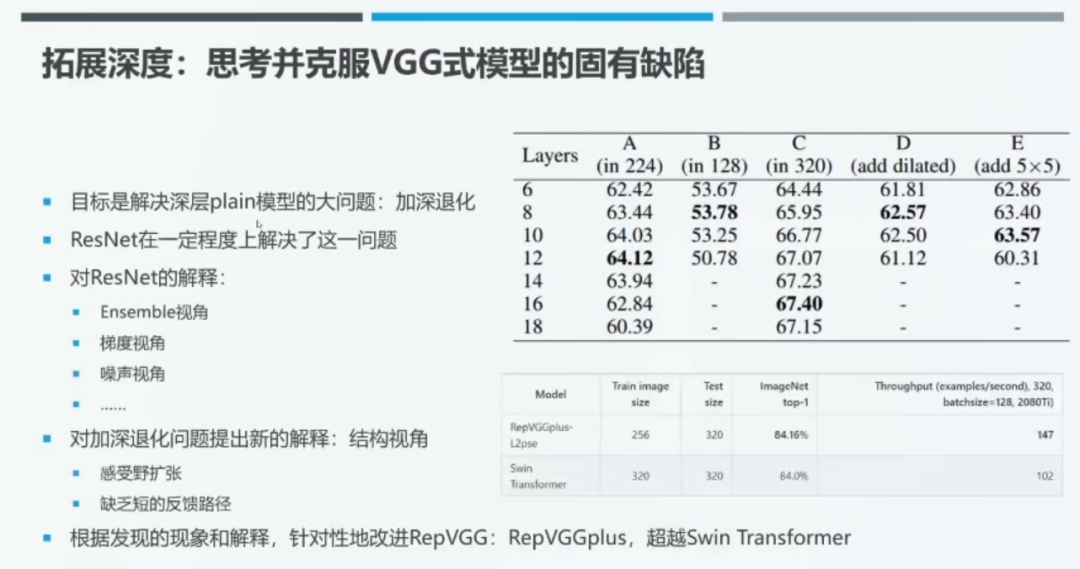
丁霄汉博士进一步思考了深层 VGG 式模型随着层数的增加性能会先上升后下降(加深退化)的原因。近年来,一些工作将 ResNet 奏效的原因归结为通过隐式的模型集成、对梯度、噪声稳定等因素。本文从结构化视角出发,将 VGG 式模型存在的加深退化问题归结为「感受野扩张」和「缺乏短的反馈路径」。
如上图所示,我们在 ImageNet 数据集上训练由 8 个 3*3 卷积组成的 VGG 式模型。在不同的实验设定下,我们将最后一个阶段的层数分别从 2 增加至 6、8、10、12、14、16、18 层,观察模型性能在何时会下降。
当输入图像分辨率为 224 时,实验选取的最后一个阶段的层数从 6 层逐渐递增,上升至 12 时模型的性能最优,当层数大于 12 层后,模型的性能开始下降。当输入图像分辨率为 128*128 时,最后阶段的层数设置为 8 时模型具备最优性能。当输入图像分辨率为 320 时,最优的模型性能出现在最后阶段层数为 16 时。
在实验设置 D 中,我们采用分辨率为 224*224 的图像作为输入,在最后一个阶段的 2 层 3*3 卷积后添加感受野为 5*5 的空洞卷积,此时模型的性能在最后阶段总层数为 8 时最优;类似地,在实验设置 E 中,我们在 2 层 3*3 卷积后添加 5*5 卷积,此时模型的性能在最后阶段总层数为 10 时最优。实验结果表明,模型的最优深度与输入图像的分辨率以及卷积层感受野的大小有关,并且模型的感受野并不一定是越大越好。
此外,VGG 式的模型缺乏短的反馈路径。因此,在 Inception 流行的年代,研究者们往往将模型切成许多段,为每一段加上一个辅助预测头,将这些头得到的损失函数值以一定的权重添加到最终的损失函数值上。
丁博士根据上述现象和解释针对性地改进了 RepVGG,得到了升级版的 RepVGGplus。在 ImageNet 数据集上,测试图像分辨率为 320*320 时,RepVGGplus 的 Top1 准确率为 84.16%,超过了 Swin Transformer,其吞吐量(运算速度)相较于 Swin Transformer 则高出了 40%。
06
拓展广度:ResReP
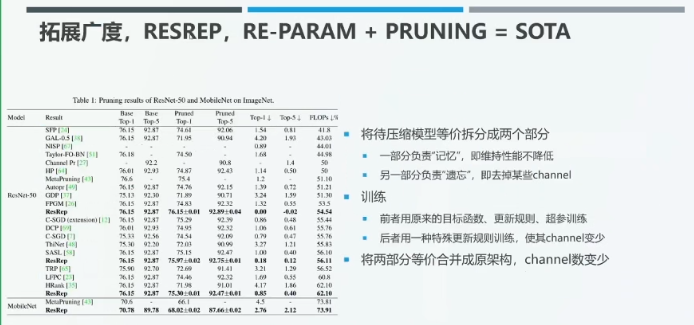
丁霄汉博士在 ICCV 2021 上发表的论文 ResReP 通过结构重参数化方法进行网络剪枝,在对FLOPs 的压缩率超过 50% 的情况下几乎完全不降低 ResNet-50 模型预测的准确率。
一些神经科学研究表明,人脑中负责「记忆」的部分与负责「遗忘」的部分是相对独立的。受此启发,我们试图将待压缩的模型等价地拆分成分别负责维持模型性能不降低的「记忆」模块,以及负责删除某些通道的「遗忘」模块。
对于记忆模块而言,我们需要保持其输出与原始网络一直,使用原来的目标函数、更新规则、超参数训练该模块,保持模型的准确率基本不下降。对于遗忘模块而言,我们将使用一种特殊的更新规则训练,去掉某些通道。结束训练后,我们将记忆和遗忘模块合并为原架构,并且减少了通道数,从而实现剪枝。
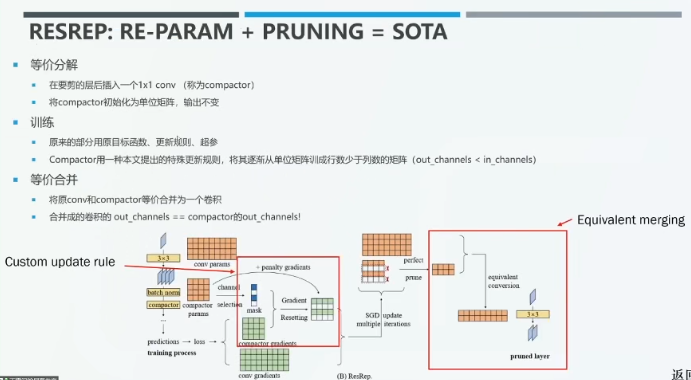
具体而言,我们在需要剪枝的层之后插入一个 1*1 卷积层(Compactor),并将 Compactor 初始化为单位矩阵,保持记忆模块与原始网络的输出一致。在训练过程中,我们采用原始网络的目标函数、更新规则、超参数训练,并且用特殊的更新规则训练 Compactor,将其逐渐从单位矩阵训练位行数少于列数的矩阵(即输出通道数小于输入通道数)。训练完成后,我们通过结构重参数化方法将原始的卷积层与相应的 Compactor 合并为同一个卷积,此时合并后的卷积的输出通道数被压缩为 Compactor 的输出通道数,从而实现剪枝。在该工作中,我们专门构造了一些额外的结构,使其承载一些特殊的操作。
07
结构重参数化与通用视觉模型的各种基本设计元素
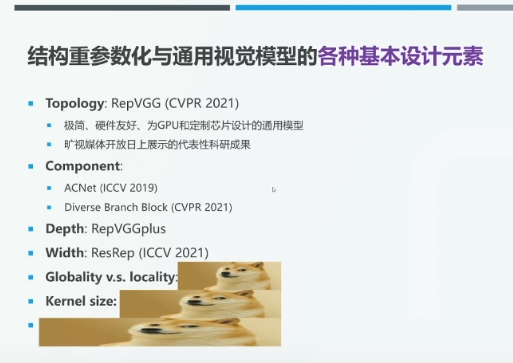
丁霄汉博士认为,结构重参数化是一种通用的方法论,可以被应用于深度学习模型的各个维度和各种设计元素。例如,RepVGG 体现了结构重参数化方法在模型拓扑结构改进上的作用;ACNet 和 DBB 则设计了帮助模型性能提升的组件;RepVGGplus 从模型深度的角度探究了 VGG 模型的缺点,并做出了相应的改进,进一步提升了模型性能;ResReP 将结构重参数化方法应用于模型剪枝,降低了模型宽度。
08
结语

通过基于结构重参数化开展的一系列研究,我们发现:人对于事务的认识并不是直线,而是螺旋式上升。在丁霄汉博士的相关工作中,RepVGG 提升了 VGG 式模型的训练效果,RepVGGplus 提供了解释单路模型深度退化问题的结构化视角;DBB 则基于 Inception 思想将每个卷积模块变为 Inception ,取得了一定的性能提升。