
MPP数据库的优势与限制
俗话说,人多力量大。
对于数据库而言,则是「节点多、力量大」。
的确,在大多数情况下,我们可以通过增加节点来增加数据分析的性能和效力。熟知MPP数据库的小伙伴,大概都知道这一小技巧。
小知识:什么是MPP数据库?
MPP代表大规模并行处理,这是网格计算中所有单独节点参与协调计算的方法。如果你熟悉MPP数据库,就知道MPP数据库的节点完全对称的,每个节点都在并行的执行完全相同的任务,所以它能很高效地解决海量数据的处理和分析查询问题。

但是,当人类步入大数据+云计算时代后,这句旷古烁今的名言,似乎不再奏效了。
下面这个场景,很多人应该都深有体会:
月初/月末或周一/周五的时候,你被指派查询一些数据。在近期工作数据集不大(不超过10亿行)的 情况下,你用3~5个节点就解决了这个问题。
但是慢慢地,你当并发请求高的时候,你会发现随着节点再一步的增加,并发能力竟是出现了不升反降的现象。
造成这一现象的原因,是因为节点增加到一定程度后,额外增加的计算资源不足以抵得上协调更多节点的花销。在大数据平台上整合数据量越来越大的今天,分析查询的并发需求也随之水涨船高。我们已经很难利用云端的计算资源来提升动辄10TB/节点的级别的数据性能了。因为,扩充节点意味着数据库的重新分布,通常要等待数!个!小!时!
这,就是当下MPP数据库所面临的限制。
性能至上,只因源于Vertica
那么,我们该如何突破这一技术壁垒,让高性能的MPP分析数据库更好地弹性扩展吞吐能力,让集群能更快地弹性扩展呢?
Micro Focus Vertica 最新的9.1版本正式推出的 Eon 模式,可以从根源上彻底解决这一切难题。
让我们来看一看它都有哪些过人之处吧!
Eon模式是Vertica的新架构,既能与原来无共享MPP列式存储架构支撑的工作负载的性能需求匹配,也能支持新的工作负载。
以在Amazon EC2 计算和S3存储上运行为例,Eon模式表现出很好的性能、卓越的可扩展性和强健的可操作性。
Vertica提供了对按需消费计算和存储资源的支持,提供更高效的性能、吞吐能力和集群自身弹性扩展。
散列(Hash)分片的胜利
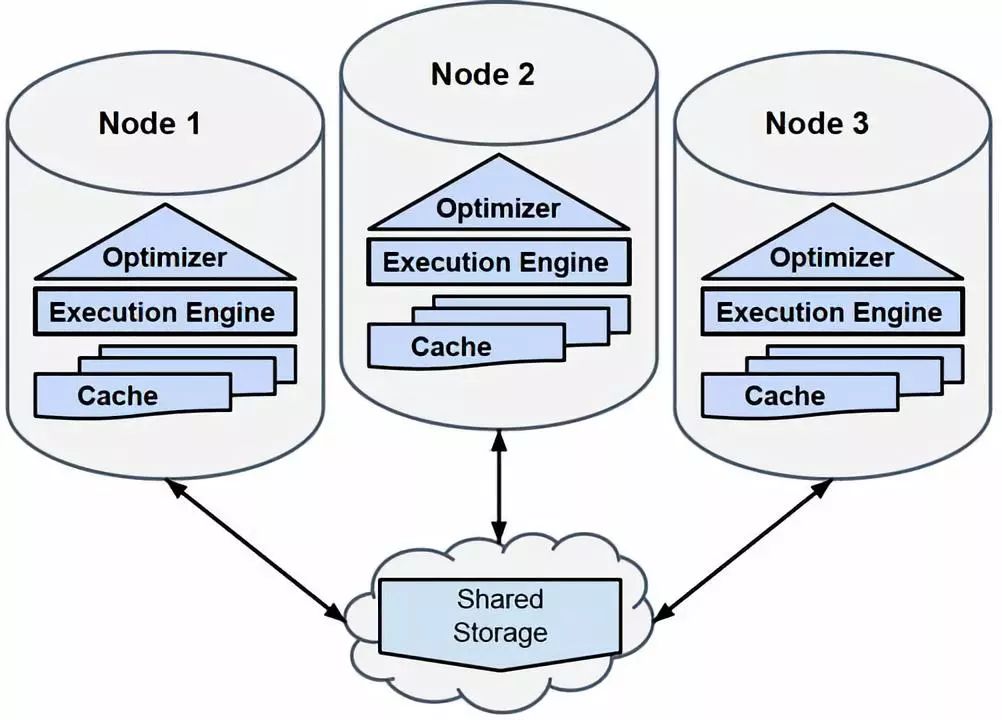
新模式将分片机制集成到Vertica现有架构中,同时实现弹性和查询性能。系统配置了一定数量的分片,其中每个分片负责哈希空间的一个区域。每个数据记录的键值都被散列(Hash)从而与拥有该哈希空间区域的分片相关联。数据加载时会被自动分割成片段写入共享存储。
从节点到分片的多对多映射表明哪些节点可以服务哪些分片。
在这个过程中(见下图),每个节点维护最近使用数据的缓存,其中节点到分片的相对静态映射确保每个节点的缓存只需要保持合理的静态数据子集。
跟“宕掉”说拜拜
Vertica的现有架构(企业模式)提供了Eon模式构建的基础。添加更多节点可提供更多节点来运行查询,从而提高吞吐能力。
当节点宕掉和复原(Recovery)时,它们只需获取自己所订阅分片的元数据更新副本,并可选择地从对等节点预热缓存。
在Eon模式下,许多在Vertica企业模式下与节点故障相关有挑战性的操作都变得很简单,因为分片永远不会宕掉。
本系列文章摘编自刘定强所著《从无共享MPP列式数据库到弹性的云原生分析平台》
想了解更多Vertica有关内容,请扫描下方二维码关注公众号实时资讯,或拨打热线电话联系我们↓↓↓
