在超分辨率重建过程中引入边缘信息,以保留图像的高频细节。本工作通过在卷积操作中使用特定的卷积核,将边缘信息与图像的低频信息相结合。更好地保留边缘细节,同时提高图像的清晰度和细节。
结构重参数化方法打造边缘设备部署的实时超分模型
论文名称:Edge-oriented Convolution Block for Real-time Super Resolution on Mobile Devices
论文地址:
https://www4.comp.polyu.edu.hk/~cslzhang/paper/MM21_ECBSR.pdf
VGG 式模型的优势
结构重参数化方法最早是有丁霄汉大神的 RepVGG[1]首先提出。
结构重参数化方法一作解读 (RepVGG):
RepVGG:极简架构,SOTA性能,让VGG式模型再次伟大(CVPR-2021)
https://zhuanlan.zhihu.com/p/344324470
结构重参数化方法用于剪枝 (ResRep[2]):
ResRep:剪枝SOTA!用结构重参数化实现CNN无损压缩(ICCV)
https://zhuanlan.zhihu.com/p/402106979
结构重参数化方法用于设计 MLP 网络 (RepMLPNet[3]):
热点讨论:MLP,RepMLP,全连接与“内卷”
https://zhuanlan.zhihu.com/p/375422742
结构重参数化方法用于设计大核卷积网络 (RepLKNet[4]):
RepLKNet作者解读:超大卷积核,大到31x31,越大越暴力,涨点又高效!(CVPR 2022)
https://zhuanlan.zhihu.com/p/481445076
"VGG式" 模型指的是:
1. 拥有像 VGG 那样的 plain 或 feed-forward 架构,没有任何分支,意味着每一层都以它上一层的输出为输入,并且输出只传递给下一层。
2. 仅使用 3x3 卷积和 ReLU 作为激活函数。
3. 模型的详细架构 (包括深度和通道数) 不经过架构搜索或者人工微调等过程。
RepVGG 模型的基本架构:将20多层 3x3 卷积堆起来,分成5个 stage,每个 stage 的第一层是 stride=2 的降采样,每个卷积层用 ReLU 作为激活函数。
3×3 卷积的优势:
3×3 卷积的优势是已经被现代计算库 (如 NVIDIA cuDNN[5]) 进行了高度的优化。下图1是 NVIDIA 1080Ti 上不同大小卷积核的理论计算量,运行时间和理论的计算密度 (Batch size=32,Input channel=output channel=2048,resolution=56×56,stride=1,cuDNN 7.5.0)。TFLOPS 是指 Tera FLoating-point Operations Per Second,即某种操作的计算密度。3×3 conv 的理论计算密度约为其他的4倍,这表明理论的运算量 FLOPs 并不能代表不同架构的实际速度。 图1:NVIDIA 1080Ti 上不同大小卷积核的理论计算量,运行时间和理论的计算密度 (Batch size=32,Input channel=output channel=2048,resolution=56×56,stride=1,cuDNN 7.5.0)
图1:NVIDIA 1080Ti 上不同大小卷积核的理论计算量,运行时间和理论的计算密度 (Batch size=32,Input channel=output channel=2048,resolution=56×56,stride=1,cuDNN 7.5.0)
"VGG" 这种极简架构的优势是:
-
运算速度快: VGG-16 是 EfficientNet-B3 计算量的8.4倍,但是在 1080 Ti 的运行速度却是后者的1.8倍,这意味着前者的计算密度是后者的约15倍。运行速度的提升除了受益于 Winograd 算法本身之外,还得益于内存访问成本 (Memory Access Cost, MAC) 和并行度。MAC 表示内存使用量,即运行这个操作占用多少内存。比如多分支操作 Inception,ResNet 的 MAC 很大。比如尽管多分支操作所需的计算量可以忽略,但是 MAC 特别高。此外,高并行度的模型在相同的 FLOPs 时比低并行度的模型速度快。
-
节约内存占用: 多分支架构之所以是内存低效的,是因为在计算多路分支输出的过程中,在没有把多路的计算结果最终加起来之前,各个分支的结果都要存在内存里面,导致了较高的内存占用。下图2说明这个问题,加了残差连接之后,内存占用峰值变为了原来的2倍 (假设每一层的特征大小不变)。
-
灵活性: 单路架构灵活性更好。残差连接要求最终输出的张量维度与输入是同等大小,这就为模型的设计带来了限制。此外,plain 的架构容易改变各层的宽度 (如剪枝) 。但是多分支模型不容易对每层进行剪枝,也会导致显著的性能下降或低加速比。相比之下,简单的架构允许我们灵活地配置每个 conv 层以获得最佳的性能-效率 trade-off。
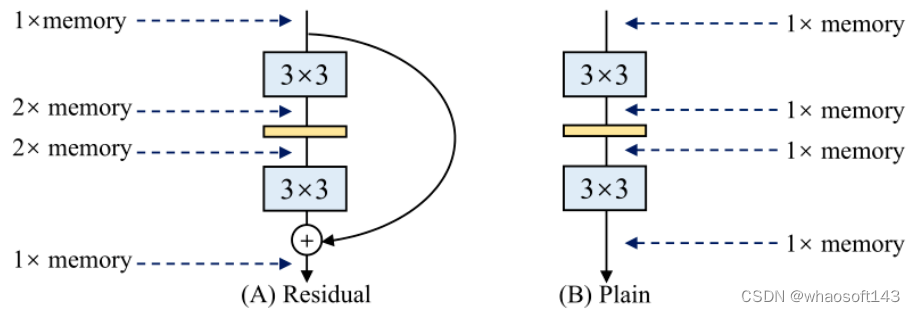 图2:residual 模型和 plain 模型的内存占用:残差模型在没有把多路的计算结果最终加起来之前,各个分支的结果都要存在内存里面,导致了较高的内存占用
图2:residual 模型和 plain 模型的内存占用:残差模型在没有把多路的计算结果最终加起来之前,各个分支的结果都要存在内存里面,导致了较高的内存占用
结构重参数化方法简介
结构重参数化方法的思想是借助多分支架构和单分支架构各自的优势。多分支架构 (如 ResNet,Inception,DenseNet,各种 NAS 架构) 和单分支结构 (VGG 式模型) 相比各有什么优劣呢?
-
多分支架构训练更加稳定且容易,比如 ResNet 的残差连接就能够很好地解决 gradient vanishing 的问题。但是推理速度慢,占用的内存大。
-
单分支结构推理速度快,节省内存。但是训练比较困难,训练的性能较低。
结构重参数化具体的做法如下图3所示。
在训练的时候如图3 (b) 所示,为每个3×3的卷积层添加平行的 1x1 卷积分支和恒等映射分支,构成一个 RepVGG Block。这种设计是借鉴 ResNet 的做法,区别在于 ResNet 是每隔两层或三层加一分支,而作者是每层都加。加完之后模型就变成了个多分支的模型,作者利用多分支架构训练的稳定性来训练这个多分支架构。
在部署的时候如图3 (c) 所示,使用重参数化方法拿着图3 (b) 的权重,对模型作等价变换,直接变成图3 (c) 的 VGG 式架构。 图3:RepVGG 架构
图3:RepVGG 架构
这个等价转换的策略就如下图4所示。利用的原理是卷积操作的齐次性,具体而言:
-
1x1 卷积是相当于一个特殊 (卷积核中有很多0) 的 3x3 卷积。
-
恒等映射是一个特殊 (以单位矩阵为卷积核) 的 1x1 卷积,因此也是一个特殊的 3x3 卷积。
所以我们只需要:
1. 把 1x1 卷积等价转换为 3x3 卷积,多余的部分使用0填充。
2. 把 Identity 操作转换为 1x1 卷积,只要构造出一个以单位矩阵为卷积核的 1x1 卷积。 合并之后卷积就成为了:
合并之后卷积就成为了:
 图4:RepVGG Block 结构重参数化的过程。为了便于可视化,取 C_out=C_in=2,所以 3×3 卷积和 1×1 卷积分别包含4个 3×3 矩阵和4个 1×1 矩阵
图4:RepVGG Block 结构重参数化的过程。为了便于可视化,取 C_out=C_in=2,所以 3×3 卷积和 1×1 卷积分别包含4个 3×3 矩阵和4个 1×1 矩阵
从 RepVGG 到 ECBSR
超分模型的前向推理速度是现实世界超分应用的瓶颈。尽管当前的工作已经提出了许多具有较少 FLOPs 的轻量级网络设计,但它们在实际应用中可能不会运行得更快,因为 FLOPs 不能精确反映实际速度,如上文所论述的那样,VGG-16 是 EfficientNet-B3 计算量的8.4倍,但是在 1080 Ti 的运行速度却是后者的1.8倍,这意味着前者的计算密度是后者的约15倍。而且,超分模型中广泛存在的 skip 和 Dense 连接会引入额外的 GPU 内存开销。plain 类的模型能够充分利用 GPU 的并行计算加速能力。
因此,在本文中作者想要设计 plain 类型的超分模型,但是直接训练这样的模型总会得到比较差的性能,因此作者希望借助重参数化技术,在超分模型训练时使用多分支架构,训练好以后转化成 plain 的模型用于部署和推理。具体来说,ECBSR 使用多个分支的线性组合来训练模型,并在推理阶段将它们合并为标准的 3×3 卷积。训练效率提高了,但是没有牺牲推理速度。ECBSR 在设计训练时的模型时结合了经典方向和边缘滤波器的领域知识。
RepSR 基本模型架构
ECBSR 基本模型架构如下图5 (a) 所示,为了保持较低的计算成本和内存消耗,ECBSR 推理时包含一系列的 3×3 卷积和激活函数 (PReLU)。在模型的末尾使用 PixelShuffle 操作和最近邻插值的上采样操作。这样由最基本的操作组成的基础模型是为了确保商用移动设备上的高推理速度和跨设备部署。
虽然复杂的拓扑结构,如 multi-branch[6] 和 Dense connection[7] 可以丰富特征表示,但这种拓扑结构会导致更高的存储器访问成本 (MAC) 并牺牲并行度,从而严重降低推理速度。具有 plain 网络结构的 FSRCNN[8] 比具有复杂拓扑结构的 IMDN-RTC[9] 具有更高的 FLOPs,但在 SnapDragon 865 上运行速度快两个数量级,可实现 540p 至 1080p 的扩展。 图5:(a) ECBSR 基本模型架构。(b) ECB 块:包含一个正常的 3×3 卷积支路,Expand-and-Squeeze Convolution 支路,卷积和 Sobel 滤波器分支,卷积和 Laplacian 滤波器分支
图5:(a) ECBSR 基本模型架构。(b) ECB 块:包含一个正常的 3×3 卷积支路,Expand-and-Squeeze Convolution 支路,卷积和 Sobel 滤波器分支,卷积和 Laplacian 滤波器分支
BN 操作对于超分任务而言并不友好,ECBSR 方法通过删去 BN 操作,并借助手工设计的复杂模块 (包含 Sobel 和 Laplacian 滤波器) 来缓解这一问题。具体而言,ECB 在训练时的结构包含下面4部分:
一个正常的 3×3 卷积支路: 不使用 BN 操作。写成公式为:
 输出特征输入非线性激活函数。
输出特征输入非线性激活函数。
ECBSR 结构重参数化方法
第1步: 融合 1×1 卷积和 3×3 卷积。
 ECBSR 实验结果
ECBSR 实验结果
作者进行了大量的实验,以验证 ECBSR 模型在五个 SR 基准数据集上的优越性能及其在两个典型硬件上的高效性。训练集使用 DIV2K,验证集使用 Set5,Set14,BSD100,Urban100,DIV2K 验证集,使用 L1 Loss 训练,优化器使用 Adam,700 epochs,初始学习率设置为 5e-4,将 RGB 转换为 YCbCr 格式后在 Y 通道上计算PSNR 和 SSIM。
作者将 RepSR 与具有代表性的 SR 方法进行比较,包括 SRCNN,FSRCNN,ESPCN,VDSR,LapSRN,CARN ,MoreMNAS-{B,C},FALSR-{B,C},TPSR-NoGAN,EDSR,IMDN。
值得注意的是评价指标除了 #Params, FLOPs 之外,还有激活次数 #Acts (M)。 图6:ECBSR 实验结果
图6:ECBSR 实验结果
ECBSR-M4C8 作为模型的最小版本,在所有五个基准测试中优于 SRCNN 和 ESPCN,同时参数量少了约 12×/10× 倍,FLOPs 少了 92×/9× 倍,激活次数少了 9×/2× 倍。ECBSR-M4C8 只需要多一点计算和内存,就可以获得比双三次上采样好得多的性能。ECBSRM4C16,ECBSR-M10C16 和 ECBSR-M10C32 在大多数情况下在性能和模型复杂度上都明显优于竞争对手。更复杂的 SR 模型 ECBSR-M16C64 在所有五个数据集上以大幅度超过 VDSR。ECBSR-M16C64 可以获得与 EDSR-R16C64、CARN-M 和 IMDN 相当的性能,但它更小、更轻。虽然进一步提高 ECBSR 的块和特征通道的数量可以带来更好的性能,但是对于移动设备来说,计算和存储成本将会太大。
下图是超分的可视化结果,由于 ECBSR 专注于移动设备上的实时 SR,所以只比较能达到实时或接近实时速度的 SR 模型,包括双三次上采样、FSRCNN、ESPCN、ECBSR-M4C8、ECBSR-M4C16、ECBSR-M10C16 和ECBSRM10C32。如下图7所示为来自 Urban100 的两幅典型示例图像的 ×2 SR 结果。可以看出,ESPCN、FSRCNN 和 ECBSR-M4C8 仅具有比双三次上采样稍好的视觉质量,它们都不能在 image033 上恢复足够清晰的边缘。通过改善深度和宽度,ECBSR-M4C16、ECBSR-M10C16 和 ECBSR-M10C32 实现了一致的更好的视觉质量,边缘更清晰,纹理更清晰。ECBSR-M10C32 在所有模型中表现最好,忠实地还原了网格的结构和边缘细节。 图7:超分的可视化结果
图7:超分的可视化结果
作者进一步评估了它们在两个移动设备上的真实运行速度,作者选取了两款有代表性的旗舰移动 SoC 进行评测,Dimensity 1000+ 的 GPU 和 SnapDragon 865 的 DSP。由于 SDK 对推理速度也有重要作用,所以作者在相同的设置下用相同的 SDK 运行所有模型。作者使用 AI benchmark app 进行 model execution。选择 TFLITE GPU和 Hexagon NN 作为推理机的代表。此外,所有模型都量化为 8 bit。下图8是在 ×2 和 ×4 任务中将图像放大到1080p 分辨率的运行速度。 图8:两款旗舰移动设备将图像放大到 1920×1080 的 SR 模型硬件运行速度比较 (红色代表少于30 fps,即实时。蓝色代表 15 到 30 fps 之间,即近乎实时)whaosoft aiot http://143ai.com
图8:两款旗舰移动设备将图像放大到 1920×1080 的 SR 模型硬件运行速度比较 (红色代表少于30 fps,即实时。蓝色代表 15 到 30 fps 之间,即近乎实时)whaosoft aiot http://143ai.com
可以看出,ECBSR-M4C8 和 ECBSR-M4C16 效率极高,可在两款器件上实现实时推理。ECBSR-M10C16 和 ECBSR-M10C32 在大多数情况下也可以达到接近实时的性能,而 ECBSR-M16C64 对于这两种移动设备来说都太重了。虽然 SRCNN 使用模型架构简洁,但由于其预上采样策略,速度要慢得多,这大大增加了内存和计算消耗。即使使用轻量级版本,EDSR-R5C32 和 IMDN-RTC 也无法在两种设备上达到接近实时的速度,因为它们的密集连接和多分支拓扑结构引入了太多的 MAC,降低了并行度。
作为对比实验,作者尝试了 ECB 块使用不同分支带来的影响,结果如下图9所示。可以看出,使用这三个组件中的任何一个都可以提高基线模型的性能,而删除 ECB 中的任何一个组件都会降低其性能。这意味着 ECB 中的所有组件都有助于 SR 任务,并且这些组件是互补的。 图9:ECB 块使用不同分支带来的影响
图9:ECB 块使用不同分支带来的影响
总结
本文中作者想要借助重参数化技术设计 plain 类型的超分模型。ECBSR 使用多个分支的线性组合来训练模型,并在推理阶段将它们合并为标准的 3×3 卷积。BN 操作对于超分任务而言并不友好,ECBSR 方法通过删去 BN 操作,并借助手工设计的复杂模块来缓解这一问题。具体而言,ECB 在训练时的结构包含一个正常的 3×3 卷积支路,Expand-and-Squeeze Convolution 支路,卷积和 Sobel 滤波器分支,卷积和 Laplacian 滤波器分支。在两款有代表性的旗舰移动 SoC 的评测结果表明,ECBSR 可在两款器件上实现实时推理。ECBSR 也能够在实时超分任务上实现更好的视觉质量。