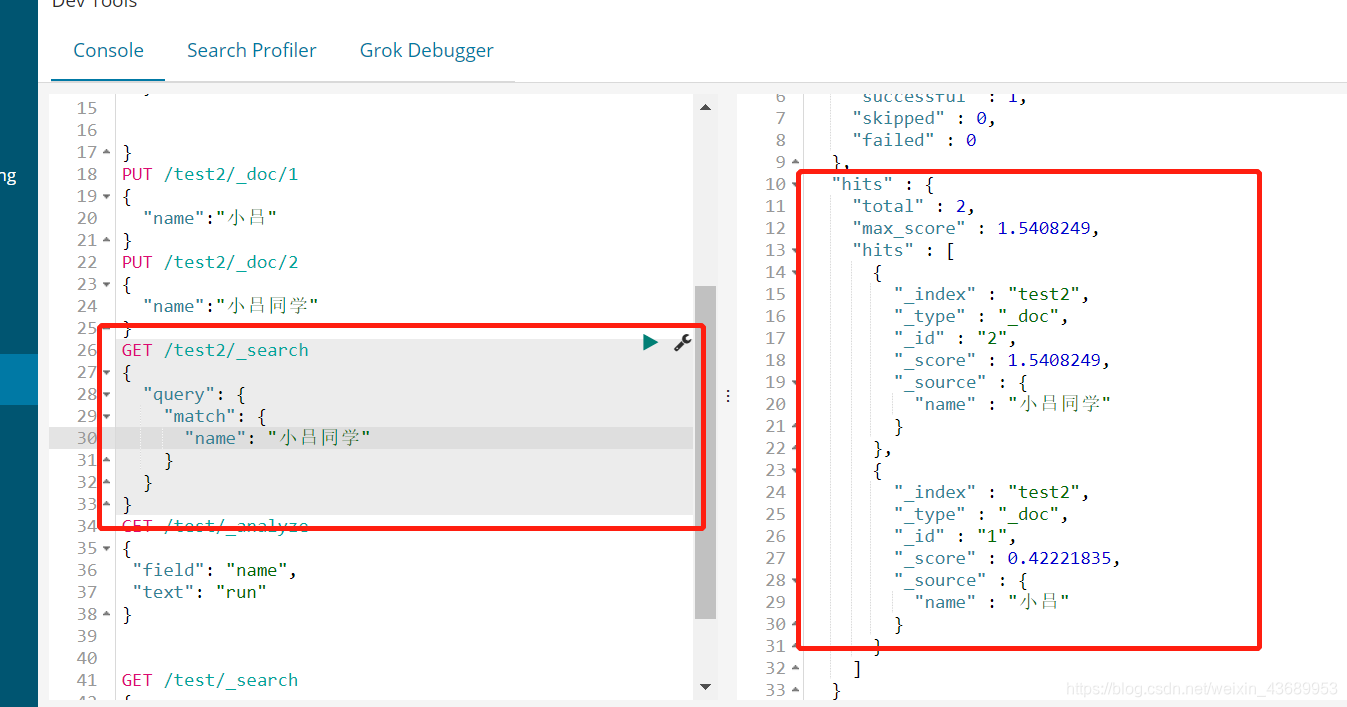
当我搜索小吕同学的时候,此时为什么小吕也能出现,我们知道 如果在数据库中 搜索小吕同学的时候
select * from db where name like '%小吕同学%'
这样是搜索不到小吕的
这就涉及到es中的分词机制
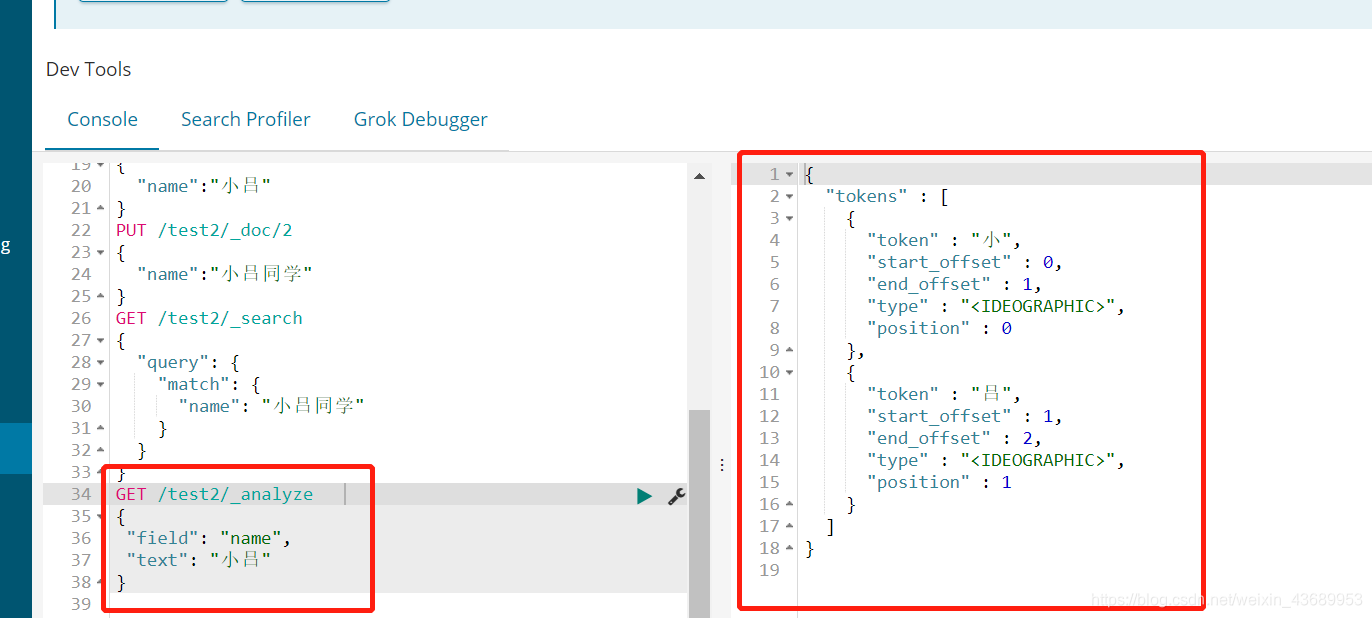
GET /test2/_analyze // 得到索引下的 某个字段的分词配置
{
"field": "name",
"text": "小吕"
}
// 我们可以看下es把我们的name 分成了什么
在我们存的时候 es把我们的name分成了"小","吕",在进行搜索的时候 es 把我们的搜索项分词成了"小","吕","同","学",所以说 在进行搜索的时候 只要能匹配上 就可以搜索到
这个就是es中的Standard 分词器,
其实此时就用了Es的默认分词器 Standard 把每一个字都分开 不论此时输入多少东西
此时只要有一个字匹配得到就可以搜索得到,但是这样有一个问题
第一就是占内存, 或者说吃性能, 他分词分的越多,倒排索引就会越多
建立索引就慢 我上次也说了es中的数据结构其实就是倒排索引, es先将文章进行分词 然后再进行倒排索引 存入es中
第二就是 比如说我搜索小吕同学, 他把但凡有吕的文章都搜索出来了 ,也不是我想要的啊
建立索引的时候 会进行分词。 搜索的时候会进行分词来进行匹配,一般建立索引用什么分词机制,搜索的时候也会用什么分词机制
es中还有一个分词叫做英文分词
[
// 创建建立分词 倒排索引入库
搜索的时候 建立分词 有的话就拿出来了
]
"enname":{
"type":"text","analyzer":"english"},
GET /test2/_analyze
{
"field": "enname",
"text": "my name is lvhao and i eating and running"
}
------------------------------->
{
"tokens" : [
{
"token" : "my",
"start_offset" : 0,
"end_offset" : 2,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "name",
"start_offset" : 3,
"end_offset" : 7,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "lvhao",
"start_offset" : 11,
"end_offset" : 16,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "i",
"start_offset" : 21,
"end_offset" : 22,
"type" : "<ALPHANUM>",
"position" : 5
},
{
"token" : "eat",
"start_offset" : 23,
"end_offset" : 29,
"type" : "<ALPHANUM>",
"position" : 6
},
{
"token" : "run",
"start_offset" : 34,
"end_offset" : 41,
"type" : "<ALPHANUM>",
"position" : 8
}
]
}
1. 我们设置英文分词器 在properties中设置,
2. 我们可以查my name is lvhao and i eating and running 这句话 看es究竟给我们分成了什么,英文分词 默认会去掉is 然后会给我们标准化,也就是说 ing 什么的都没有了
3. 此时我们再搜索的时候 用eating 就可以搜索到, 因为搜索的时候会先建立分词 然后再进行匹配
接下来我们再看 所谓的中文分词 ik 分词
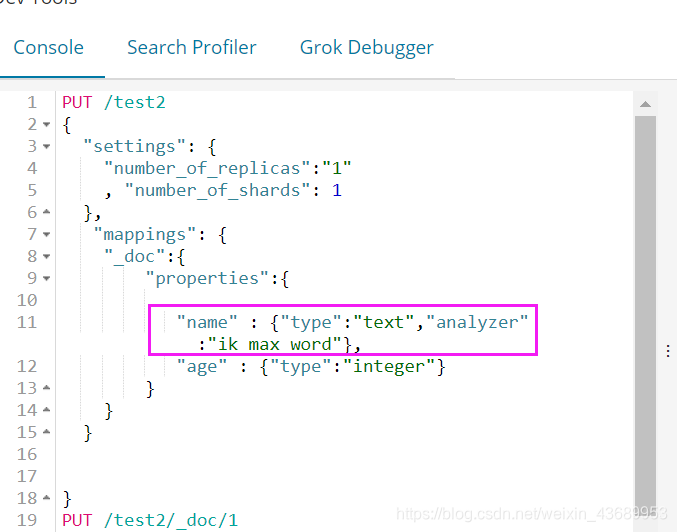
PUT /test2
{
"settings": {
"number_of_replicas":"1"
, "number_of_shards": 1
},
"mappings": {
"_doc":{
"properties":{
"name" : {
"type":"text","analyzer":"ik_max_word"},
"age" : {
"type":"integer"}
}
}
}
}
// 此时我把name 的分词器设置为ik 并且为
ik_max_word
然后再往里面加一条数据
PUT /test2/_doc/1
{
"name":"武汉市长江大桥"
}
然后使用
GET /test2/_analyze
{
"field": "name",
"text": "武汉市长江大桥"
}
///---------->查询一下这个分词效果
{
"tokens" : [
{
"token" : "武汉市",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "武汉",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "市长",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "长江大桥",
"start_offset" : 3,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "长江",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "大桥",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 5
}
]
}
ik_max_word 这种分词机制把 这个分词器里面main中所包含的全部搜索出来了
他会把我们能拆分的词都拆出来
我们再试试
ik_smart

这种ik_smart分词机制使用了贪心算法 尽可能给你分长 的词语
ik_max_word 和ik_smart 有啥用
为啥这么操作
武汉市长江大桥建索引的时候 我用max_word 也就是说 所有的这些词 理论上都可以找到这篇文档
我们在查询的时候 我只要分成武汉市 我就可以找到他 分成长江大桥也可以找到他
[]--->我们在查询的时候只需要查着2个词就可以了
我们不需要查所有的词
这样一来对我们的查询就是一个很大的优化
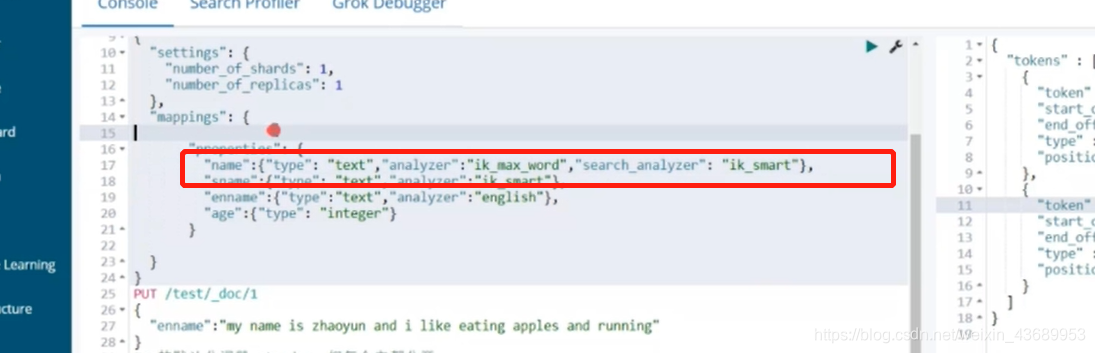
所以一般建立索引的时候用ik_max_word 搜索的时候用ik_smart