1. 正则表达式
- 参考 菜鸟教程:python正则表达式:http://www.runoob.com/python/python-reg-expressions.html
菜鸟教程:正则表达式 - 语法:http://www.runoob.com/regexp/regexp-syntax.html
-
1. 正则表达式基础
-
-
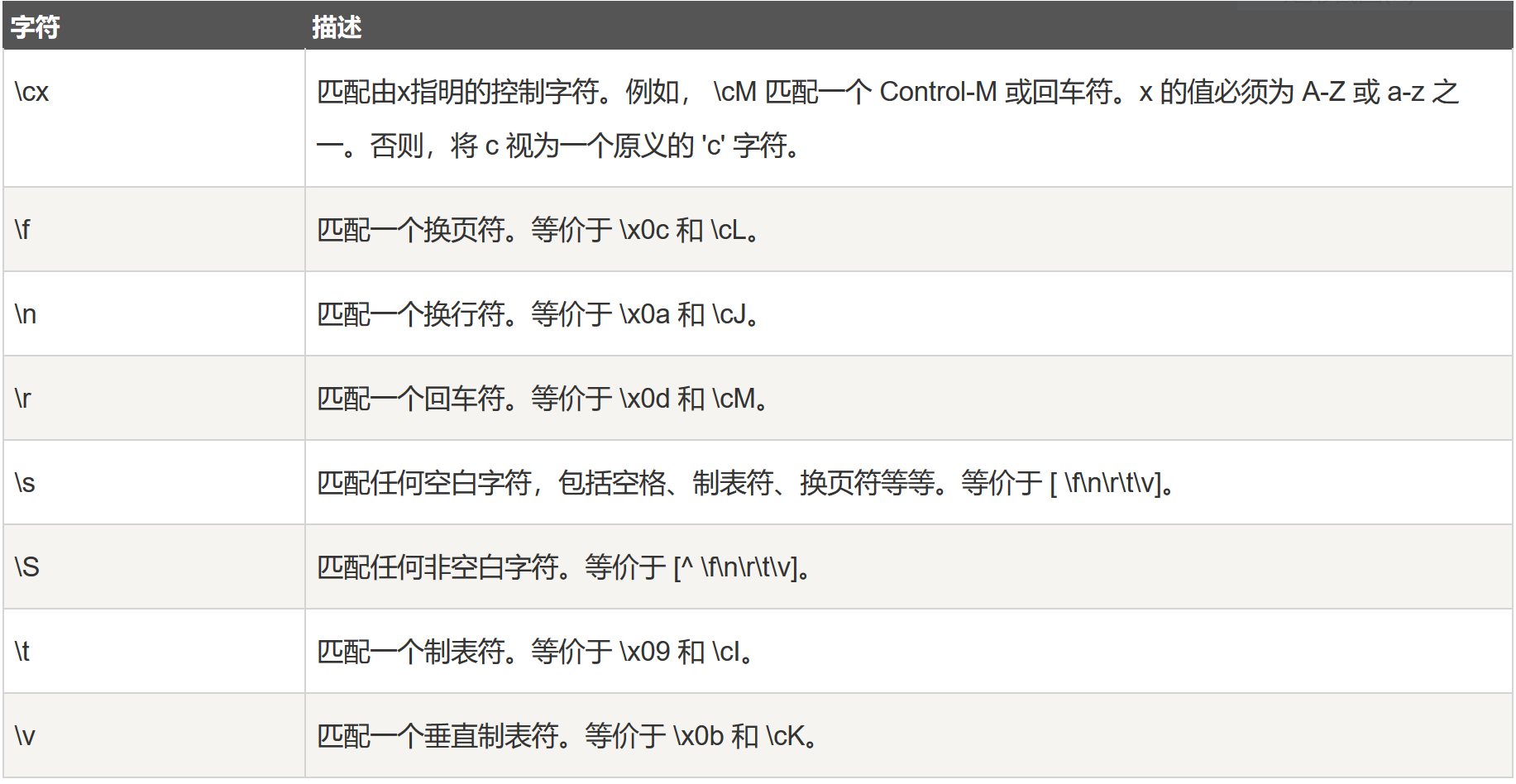
非打印字符 :
-
-
- 特殊字符:
- 限定符: 注意, *、+限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个?就可以实现非贪婪或最小匹配。
- 特殊字符:


-
- 定位符:
- 选择:
- 反向引用:
- 定位符:



-
2. Python正则表达式基础语法
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。
re 模块使 Python 语言拥有全部的正则表达式功能。
compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
-
-
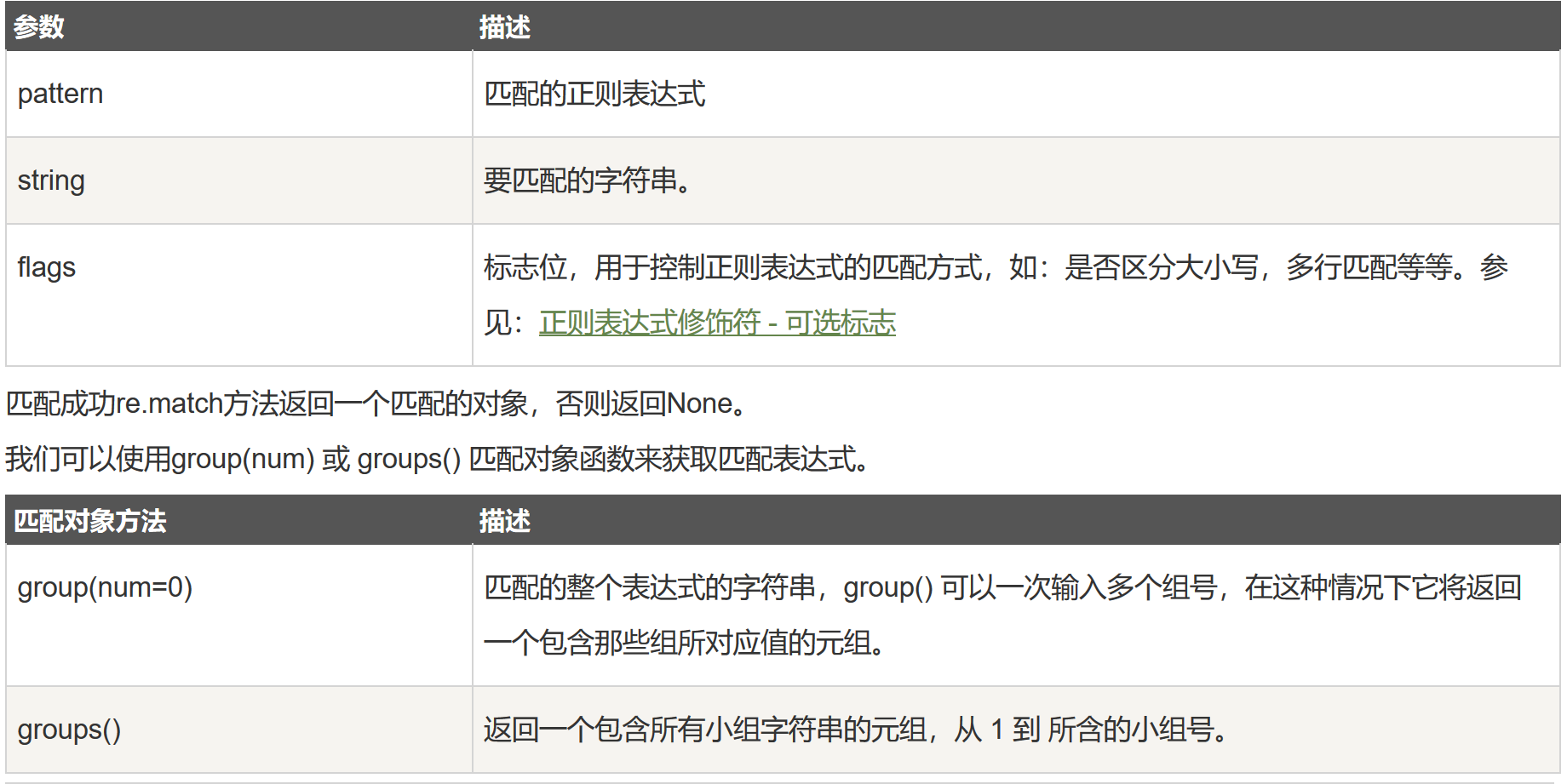
re.match函数:re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
- 函数语法:re.match(pattern, string, flags=0)
- 函数参数说明:
-
-
- re.search函数:re.search 扫描整个字符串并返回第一个成功的匹配。
- 函数语法:re.search(pattern, string, flags=0)
- 函数参数说明:
- re.match与re.search的区别:
- re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
- re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
- 检索和替换:Python 的 re 模块提供了re.sub用于替换字符串中的匹配项。
- 函数语法:re.sub(pattern, repl, string, count=0, flags=0)
- 函数参数:
- re.compile函数:compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
- 函数语法:re.compile(pattern[, flags])
- 函数参数:

- 其中,当匹配成功时返回一个 Match 对象,包含以下方法:
- findall 函数: 在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。 注意: match 和 search 是匹配一次,而 findall 匹配所有。
- 函数语法:findall(string[, pos[, endpos]])
- 函数参数:
- re.finditer函数:和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
- 函数语法:re.finditer(pattern, string, flags=0)
- 函数参数:
- re.split 函数 :split 方法按照能够匹配的子串将字符串分割后返回列表。
- 函数语法:re.split(pattern, string[, maxsplit=0, flags=0])
- 函数参数:
- 正则表达式对象 :
- re.RegexObject :re.compile() 返回 RegexObject 对象。
- re.MatchObject :group() 返回被 RE 匹配的字符串。
- 正则表达式修饰符 - 可选标志:正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。
- 修饰符,如下所示:
- 修饰符,如下所示:
- 正则表达式模式 :
- 模式字符串使用特殊的语法来表示一个正则表达式:
- re.search函数:re.search 扫描整个字符串并返回第一个成功的匹配。




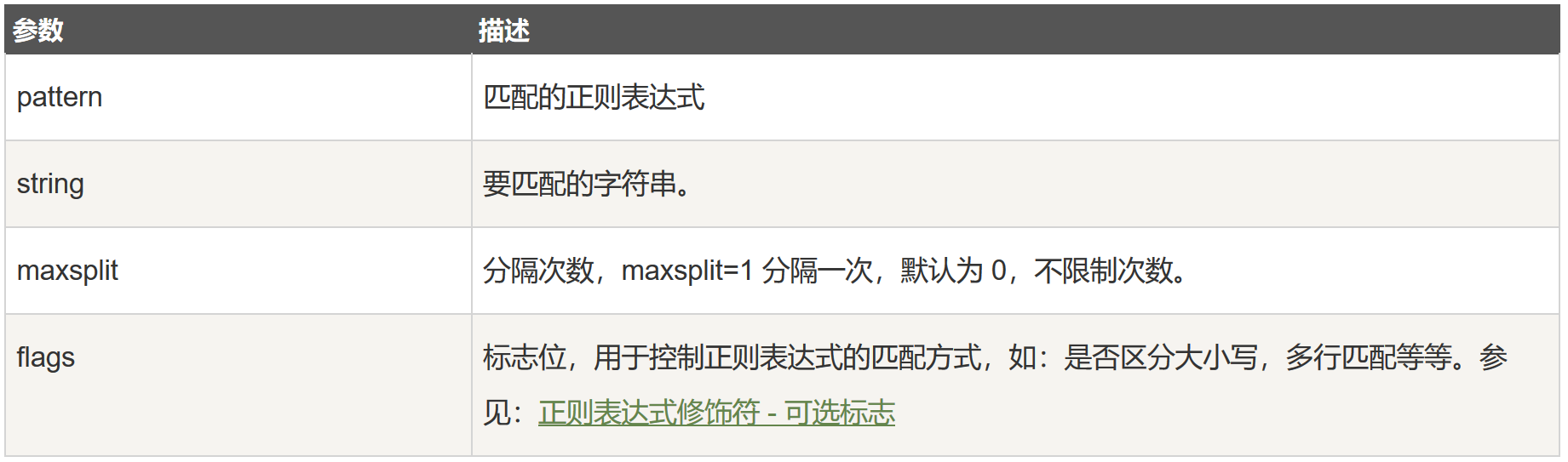


1. 字母和数字表示他们自身。
2. 一个正则表达式模式中的字母和数字匹配同样的字符串。
3. 多数字母和数字前加一个反斜杠时会拥有不同的含义。
4. 标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
扫描二维码关注公众号,回复:
1531788 查看本文章

5. 反斜杠本身需要使用反斜杠转义。
6. 由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。
-
-
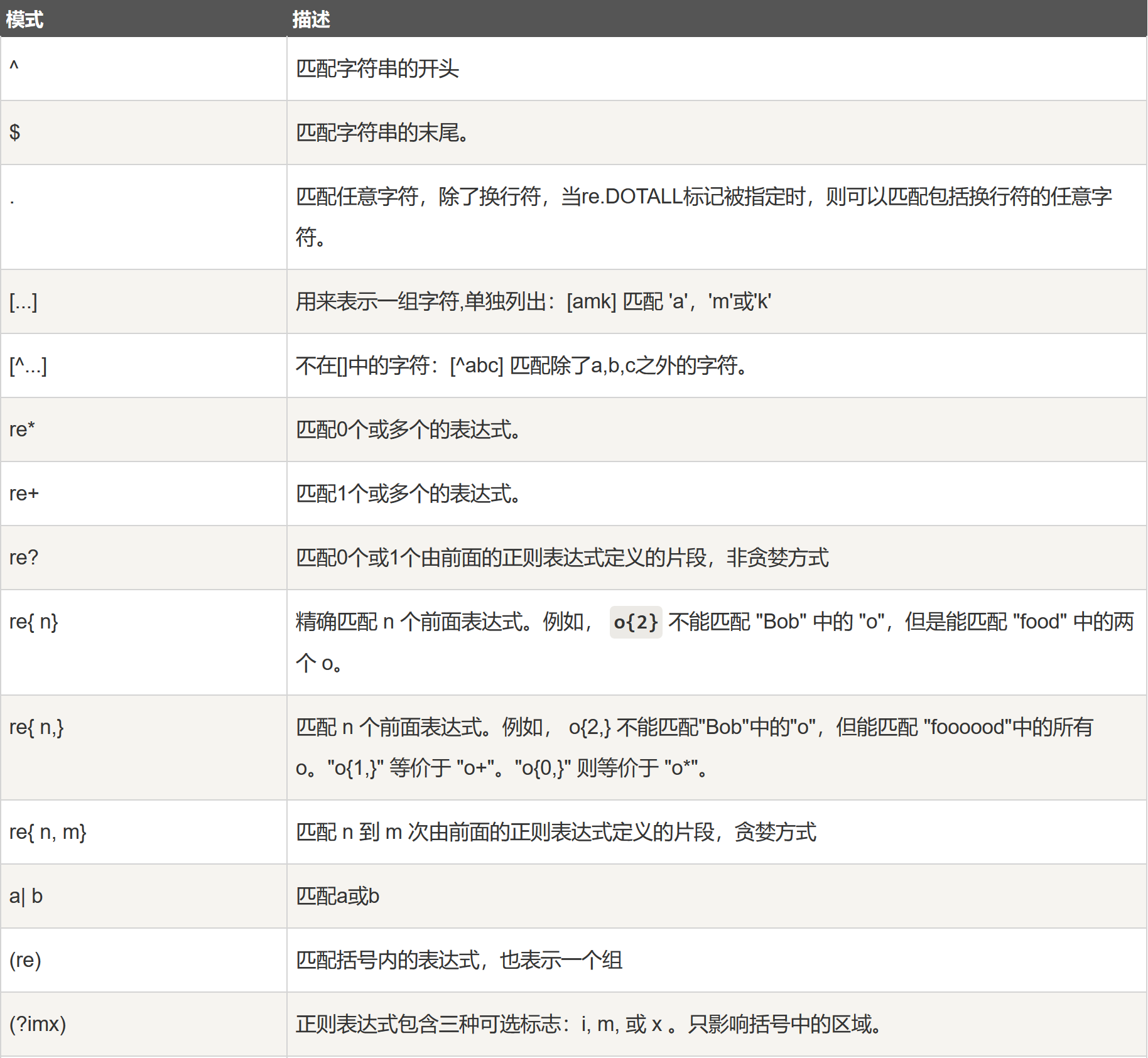
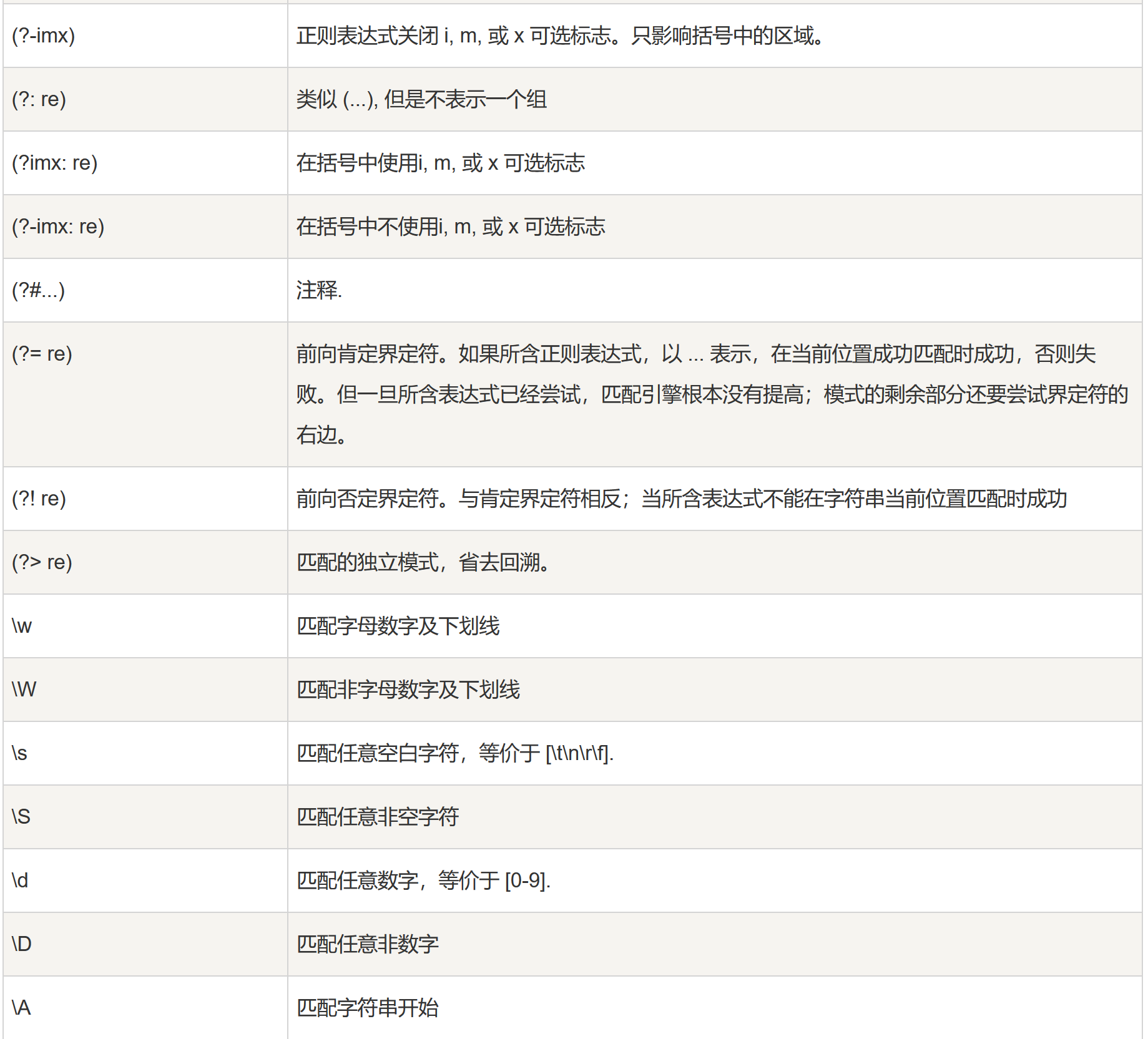
- 下表列出了正则表达式模式语法中的特殊元素:注意 ,如果你使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变。
- 下表列出了正则表达式模式语法中的特殊元素:注意 ,如果你使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变。
-

-
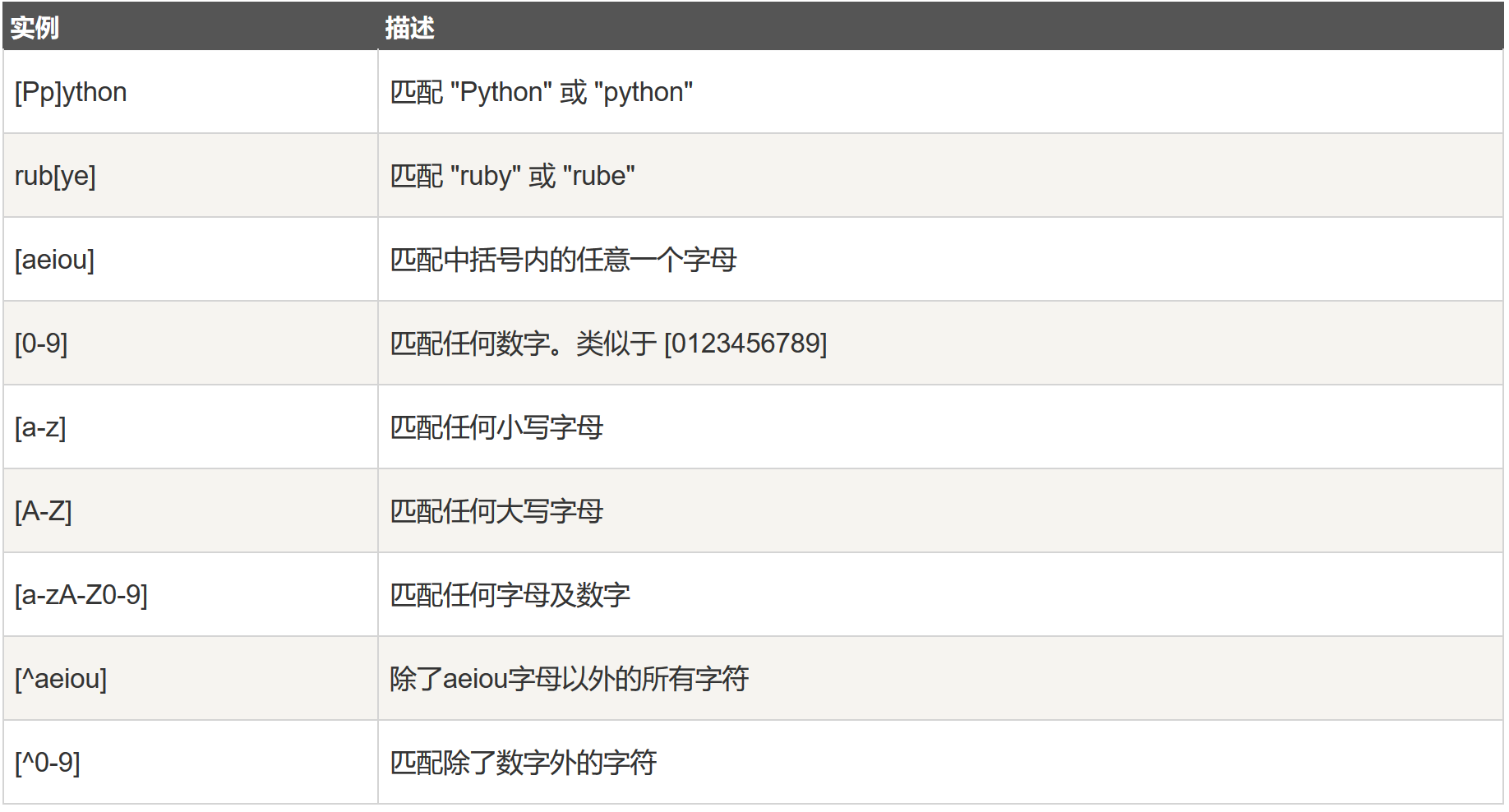
- 正则表达式实例:
- 字符匹配:
- 字符类:
- 特殊字符类:
- 字符匹配:
- 正则表达式实例:


-
3. python正则表达式识别出生日期
- python代码样例如下:
-
# _*_ coding : utf_8 _*_ _author_ = 'lxr' # 将line中每个元素中的 出生日期 提取输出 import re line = ["xxx出生于1995年4月", "xxx出生于1995年04月", "xxx出生于1995年4月24日", "xxx出生于1995年04月24日", "xxx出生于1995/4", "xxx出生于1995/04", "xxx出生于1995/4/24", "xxx出生于1995/04/24", "xxx出生于1995-4", "xxx出生于1995-04", "xxx出生于1995-4-24", "xxx出生于1995-04-24", ] l = "xxx出生于1995年4月24日" # regex_str = ".*出生于(\d{4}[年/-]\d{1,2}($|月$|[/-]\d{1,2}$|月\d{1,2}日$))" # 老师范例 regex_str = ".*出生于(\d{4}[年/-]\d{1,2}([月/-](\d{1,2}(日|$)|$)|$))" # 自己改进,结构更清晰 # 结构如下 -->:表示对应于 # 第 1 级结构 : xxx出生于(第2级结构) --> .*出生与(第2级结构) # 第 2 级结构 : 1995年04(第3级结构),1995年4(第3级结构), # 1995/04(第3级结构), 1995/4(第3级结构), # 1995-04(第3级结构), 1995-4(第3级结构) --> (\d{4}[年/-]\d{1,2}(第3级结构)) # 第 3 级结构 : 月(第4级结构) ,/(第4级结构),-(第4级结构),结束 --> [月/-](第4级结构)|$ # 第 4 级结构 : 结束,24(第 5 级结构) --> \d{1,2}(第5级结构)|$ # 第 5 级结构 : 结束,日 --> 日|$ for date in line: match_obj = re.match(regex_str, date) if match_obj: print(match_obj.group(1))
-
- python代码样例如下:
2. 深度优先,广度优先算法的python实现
- 代码实现如下,详细请看注释:
- (参考博客:https://www.cnblogs.com/PrettyTom/p/6677993.html,https://blog.csdn.net/zhaobig/article/details/78649059?locationNum=2&fps=1)
-
class Node: def __init__(self,elem): self.elem = elem self.lchild = None self.rchild = None class Tree: def __init__(self): self.root = None def add(self, elem): node = Node(elem) if self.root is None: self.root = node else: q = [self.root] while True: pop_node = q.pop(0) if pop_node.lchild is None: pop_node.lchild = node return elif pop_node.rchild is None: pop_node.rchild = node return else: q.append(pop_node.lchild) q.append(pop_node.rchild) # python 实现 深度优先 算法 : 利用 递归 def deep_search(root): # 深度遍历 核心:递归 result1.append(root.elem) if root.lchild: deep_search(root.lchild) if root.rchild: deep_search(root.rchild) return result1 # python 实现 广度优先 算法 :利用 队列 def level_queue(root): if root is None: return my_queue = [] node = root my_queue.append(node) while my_queue: node = my_queue.pop(0) result2.append(node.elem) if node.lchild: my_queue.append(node.lchild) if node.rchild: my_queue.append(node.rchild) return result2 t = Tree() for i in range(10): t.add(i) result1 = [] # 保存深度优先遍历结果 result2 = [] # 保存广度优先遍历结果 print("深度遍历:",deep_search(t.root)) print('广度遍历:',level_queue(t.root))
3. URL的5种去重策略和优劣分析
原因:不去重复,爬虫会陷入URL循环中,跳不出来
-
1. 将访问过的URL保存到数据库中
- 分析:
- 优点:最简单
- 缺点:效率最低。虽然数据库有缓存,当由于每个URL都需要从数据库中查询,效率最低。
- 分析:
-
2. 将访问过的URL保存到set中,只需要O(1)的代价就可以查询UR
- 分析:
- 优点:将URL保存到内存,也就是set中,几乎不用花费时间,就可以很快取到。
- 缺点:内容的占用会越来越大 。 以一亿条URL为例,需要占用9G的内存。
- 例如,1亿条URL,Unicode编码2byte,长度位50个字符,则内存计算如下:
- 100000000 * 2byte * 50个字符 / 1024 /1024 / 1024 = 9G
- 分析:
-
3. URL 经过 MD5 等方法哈希后保存到set中 (Scrapy就采用这是方法)
- 分析:
- 优点:可以将任意长度的URL进行MD5编码,使每一个URL变成固定长度的MD5不重复字符串,一个URL占用16个byte,较第2种方法的100byte,进行了成倍的压缩。
- 分析:
-
4. 用 bitmap方法,将访问过的URL通过hash函数映射到某一位
- 分析:
- 优点:申请8个bit 位,即一个byte字节,每个URL对应1个bit位,1个字节可以存放8个URL,更进一步压缩了URL
- 缺点:在同一个hash函数上,多个不同的URL极有可能映射到同一位上,冲突可能性会非常高。
- 分析:
-
5. bloomfilter方法对bitmap进行改进,多重hash函数降低冲突
- 分析:
- 优点:既达到bitmap的减少内存的作用,同时有降低了hash函数的冲突
- 分析:
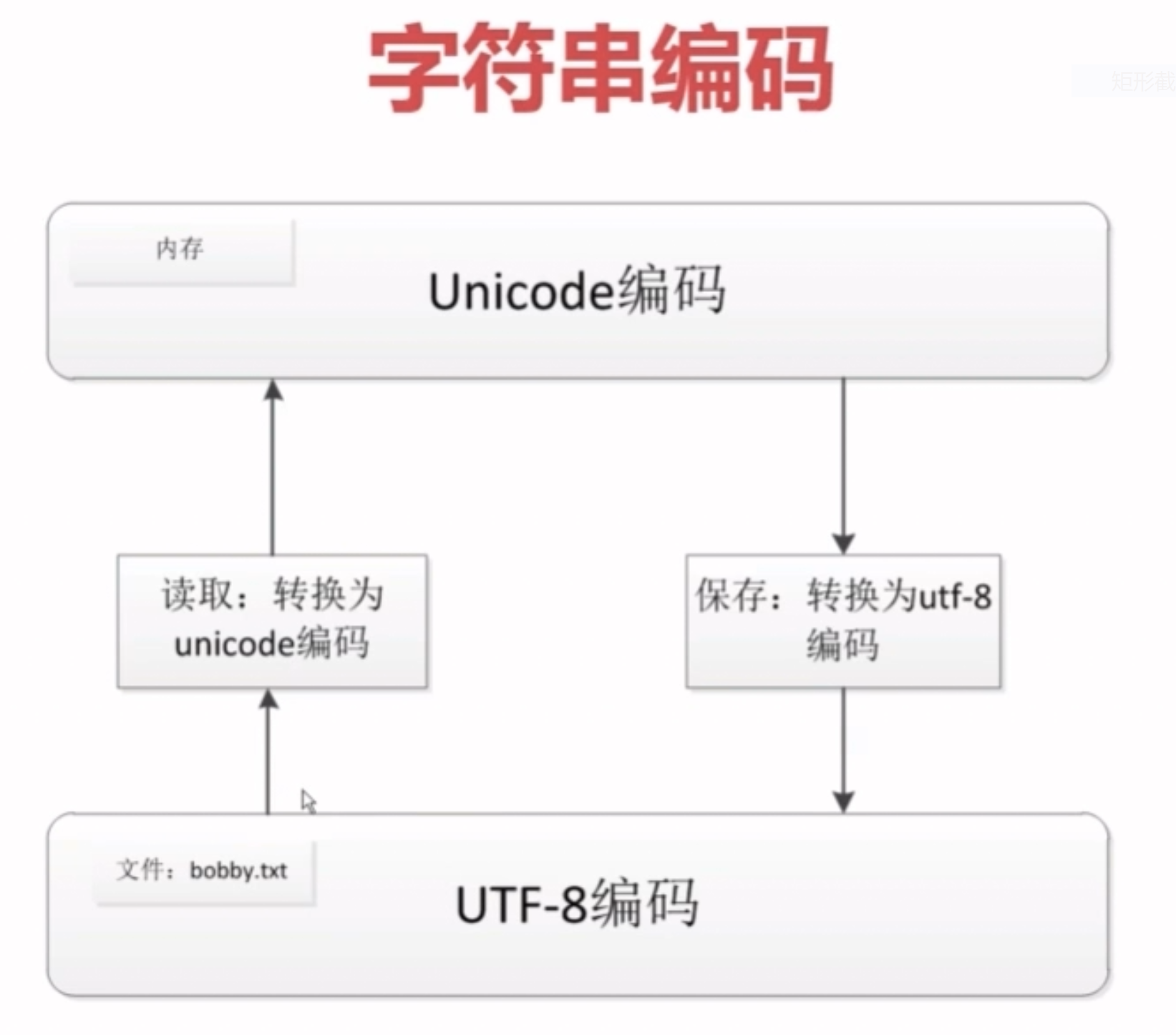
4. Unicode 和 UTF8 的差别分析
-
Unicode :
- 优点:定长编码,把所有编码统一到一套编码种,解决了乱码问题;且由于编码长度固定,在内存中处理时,编程简单
- 缺点:由于编码长度长,如果内容为英文,比使用ASCII编码需要多一倍的存储空间,不易存储
-
UTF-8:
- 优点: 可变长编码,在网络传输种,可大大减少传输流量
- 缺点:由于编码长度不一定,放在内容中进行编码时,内存处理将非常困难。
-
使用方法:
- 常用做法:存储文件时,出于节省空间的原因,把Unicode转换成UTF-8编码 ; 当需要从内存读取文件时,出于编程的考虑,将UTF-8转换为Unicode编码