文章目录
前言
随着互联网技术的日新月异,互联网产业逐渐渗透到社会领域的方方面面,短短十年就改变了诸多人们的生活方式。过去的十年,是互联网发展最为迅速的时代,随着互联网的崛起、用户的激增和数据的爆炸性膨胀,全球的科技大厂积累了丰富的高可用和分布式的经验,大数据、云计算、区块链、人工智能这些高科技时代的产物也随之而来。
本文主要谈谈大数据、分布式系统以及分布式搜索引擎的相关概念。
大数据时代
麦肯锡全球研究所给出的大数据定义
一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四大特征。
这个定义也表明了大数据的主要三大特征:海量(Volume)、多样(Variety)、实时(Velocity),为了解决这些特征带来的问题,互联网技术需要实现三个需求:高并发、高可扩、高性能,这就是 3V 和 3高。
也正是因为大数据需要强大的算力和海量的存储支撑,传统的单机架构的软件体系已经无法满足大数据业务的需求,所以基于集群、分布式的软件架构体系应用而生。
单机、集群、分布式架构
-
单机架构
对于中小型系统业务,所有的代码都放在一个项目,然后这个项目部署在一台服务器,该项目所有的业务都由这台服务器提供,这就是单机结构。但是单机服务器的处理能力是有限的,当业务增长到一定程度的时候,单机的硬件资源将无法满足业务需求,此时便出现了集群模式。 -
集群架构
单机的项目实例复制部署到多台服务器上就形成了集群,每个服务器就是一个节点,每一个节点都相当于对实例的克隆,部署多个节点,处理业务的能力和节点数成正比,这些节点的集合就叫做集群。 -
分布式架构
分布式结构就是将一个完整的系统,按照业务功能,拆分成一个个独立的子系统,在分布式结构中,每个子系统就被称为“服务”,这些子系统能够独立运行在一台服务器中,多个服务之间通过RPC方式通信,每一个子系统也可以形成一个集群来提高服务性能。
虽然集群和分布式架构解决了 3高 的需求,但是事物都具有两面性,分布式和集群系统带来的缺点也很明显:
- 分布式架构是跨进程、跨实例、跨网络的,性能和可靠性容易受到网络环境的影响。
- 引入各种中间件、异步通信等模式大大增加了系统的复杂度。
- 分布式系统对数据的一致性需要在 C(一致性)A(可用性)P(分区容错性)中做出选择。
- 一个系统拆成了多个服务,每个服务都得配置,部署,监控,日志处理,提升运维难度。
什么是分布式系统
当单个节点的处理能力无法满足日益增长的计算、存储任务的时候,且硬件的提升(加内存、加磁盘、使用更好的CPU)高昂到得不偿失的时候,应用程序也不能进一步优化的时候,就考虑使用分布式系统。
分布式系统是由一组通过网络进行通信、为了完成共同的任务而协调工作的计算机节点组成的系统。分布式系统的出现是为了用廉价的、普通的机器完成单个计算机无法完成的计算、存储任务。其目的是利用更多的机器,处理更多的数据。
计算与存储是分布式系统主要解决的问题,海量数据需要强大的计算力支持,分布式系统分为分布式计算(computation)与分布式存储(storage)。
分布式系统需要一组计算机提供服务,将庞大的数据集和巨大的算力根据分而治之的思想分发给每一个计算机(分片)。对于计算,就是对计算任务进行切割,每个节点计算一部分,最终将计算结果汇总,这就是 MapReduce 的思想;对于存储,就是对海量数据进行切割,对数据进行分布式拆分,每个节点存一部分数据。
1. 分片和副本集
分布式系统使用分片(Partition)可以解决高并发和高性能,但是无法满足高可用的需求。因为在分布式系统中有大量的节点,这些节点通过网络通信,单个节点的故障(进程crash、断电、磁盘损坏)是个小概率事件,但整个系统的故障率会随节点的增加而增加,网络通信也可能出现断网、高延迟的情况。在这种“异常”情况下,分布式系统还是需要继续稳定地对外提供服务,即需要较强的容错性。最简单的办法,就是使用副本集(Replication),即多个节点负责同一个任务,多个节点存储同一份数据,单个节点故障可以使用其他相同节点继续提供服务,同时,Replication会带来性能的提升。
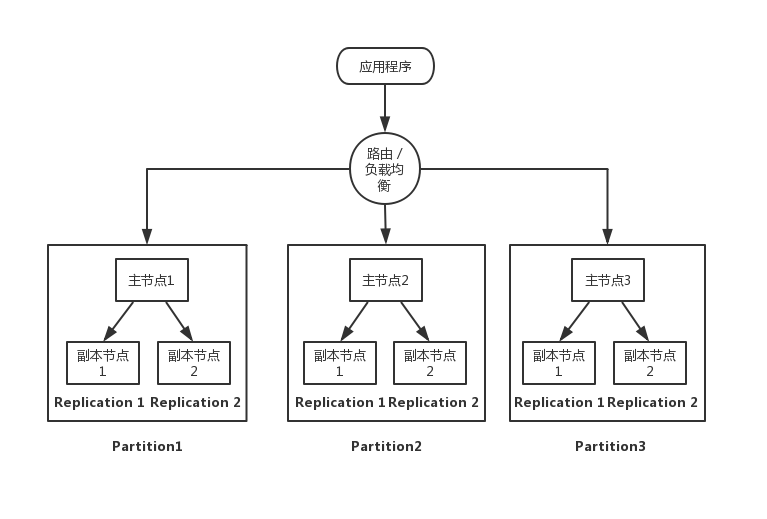
2. 分布式系统的衡量标准
- 可扩展性:当任务增加的时候,要比较方便的通过增加机器来应对数据量的增长,同时,当任务规模缩减的时候,可以撤掉一些多余的机器,实现弹性计算。
- 可用性与可靠性:可用性通过不可用时间与正常服务时间的必知来衡量;可靠性而是指计算结果正确、存储的数据不丢失。
- 高性能:专注于高并发和低延时。
- 一致性:为了提高可用性可靠性,一般会引入冗余(复制集)但需要保证这些节点上的状态一致。一致性越强,对用户越友好,但会制约系统的可用性;一致性等级越低,用户就需要兼容数据不一致的情况,但系统的可用性、并发性高很多。
分布式搜索引擎
搜索引擎(Search Engine)是指根据一定的策略、运用特定的计算机程序对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。
1. 倒排索引
假如不用搜索引擎,只使用数据库来存放和搜索一些数据,比如说放了一些文档,那么这个数据的格式大致如下:
| id | title | content |
|---|---|---|
| 1 | 《Java编程思想》 | 《Java编程思想》是2007年机械工业出版社出版的图书,作者是埃克尔,译者是陈昊鹏… |
| 2 | 《算法导论》 | 《算法导论》是基础算法方面最权威、最详细的著作之一,在很多国际著名大学被用于算法课的教材… |
| 3 | 《Java核心技术》 | Java领域有影响力和价值的著作之一,由拥有20多年教学与研究经验的Java技术专家撰写… |
假设有一个id字段标识了每个文档的数据,然后title字段是文档的标题,content字段是文档的内容。如果通过搜索引擎类的技术来存放文档的内容,它是可以建立倒排索引的。
倒排索引,就是把数据内容先分词,每句话分成一个一个的关键词,然后记录好每个关键词对应出现在了哪些id标识的数据里。
把上述的数据放到搜索引擎里,这个倒排索引的数据大致看起来如下:
| 关键词 | id |
|---|---|
| Java | [1,3] |
| 算法 | [2] |
| 著作 | [2,3] |
| 的 | [1,2,3] |
| … | … |
搜索包含“Java”关键词的文档,直接扫描这个倒排索引,在倒排索引里找到 “Java” 这个关键词对应的那些数据的 id 就OK,根据 id 就可以找到对应的数据,这个就是倒排索引的数据格式以及搜索的方式,这种利用倒排索引查找数据的方式,也被称之为全文检索。
2. 分布式搜索引擎原理
如果有100T甚至更多的数据需要搜索引擎实现检索的需求,往往单机很难实现,这时就需要分布式系统,也就是分布式搜索引擎。所谓的分布式搜索引擎就是把大量的索引数据拆散成多块,每台机器放一部分,然后利用多台机器对分散之后的数据进行并行搜索,所有操作全部是分布在多台机器上进行,形成了完整的分布式架构。
Lucene、Solr、ElasticSearch是当今主流的搜索引擎框架,利用搜索引擎高效的全文索引和分词算法,以及高效的数据检索实现,来解决数据库和传统的Cache系统完全无法解决的全文模糊搜索、分类统计查询等功能。下面以Elasticsearch举例。
Elasticsearch是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
基本概念
先看一下Elasticsearch的一些名词,用来描述它的一些数据结构。
- index
索引,类似于关系型数据库里一个数据库。 - type
一个index中包含多个type,类似于关系型数据库中的表。 - mapping
表结构定义,类似于关系型数据库中表结构定义。 - document
Elasticsearch 往index中的一个type中写入的一条数据,类似于关系型数据库中的记录。 - filed
document包含一个或多个filed,类似于关系型数据库中的表的字段。
下面就是一个document,这个document可以写到 index 里去,算是 index 里的一条数据。
写到 Elasticsearch 之后,这条数据的内容就会拆分为倒排索引的数据格式来存储:
| id | title | content |
|---|---|---|
| 1 | 《Java编程思想》 | 《Java编程思想》是2007年机械工业出版社出版的图书,作者是埃克尔,译者是陈昊鹏… |
Shard 数据分片
如果需要检索的数据量特别大,就必须支持这个index的数据分布式存储在多台机器上,利用多台机器的磁盘空间来承载这么大的数据量。保证每台机器上对这个index存储的数据量不要太大,因为控制单台机器上这个index的数据量,可以保证搜索性能更高。
shard是Elasticsearch数据存储的最小单位,index的存储容量为所有shard的存储容量之和。Elasticsearch集群的存储容量则为所有index存储容量之和。
每个index都可以指定创建多少个shard,每个shard就是一个数据分片,会负责存储这个index的一部分数据,一个Elasticsearch索引是分片的集合。 Elasticsearch在索引中搜索时,它发送查询到每一个属于索引的分片,然后合并每个分片的结果到一个全局的结果集。
比如说指定一个index里有占据3TB数据。然后这个index可以设置了3个shard,那么每个shard就可以包含一个1TB大小的数据分片,每个shard在集群里的一台机器上,这样就形成了利用3台机器来存储一个index的分布式系统。(这里的数据分配只代表示例)
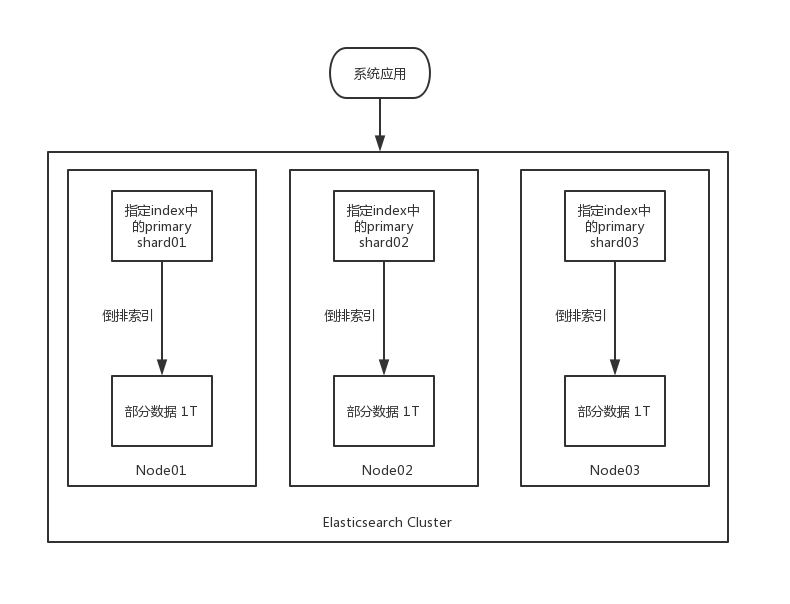
分片的其中一个作用在于实现负载均衡,当然这个前提在于分片合理分布在各个节点中。如果分片分布的不合理,就算节点数量足够,也会陷入“一核有难,九核围观”的困境。
Replica 副本
上述的Cluster有一个严重的问题,假如说3台机器中的其中一台宕机,这个 index 的3TB数据的1/3就丢失了,所以为了实现高可用需要使用Replica副本机制。
Elasticsearch支持对每个 index 的 shard 设置一个 replica 副本的数量。初始的 shard 就是主分片 primary shard,副本分片是 replica shard ,而且 primary shard 和 replica shard 不会放在一台机器上。
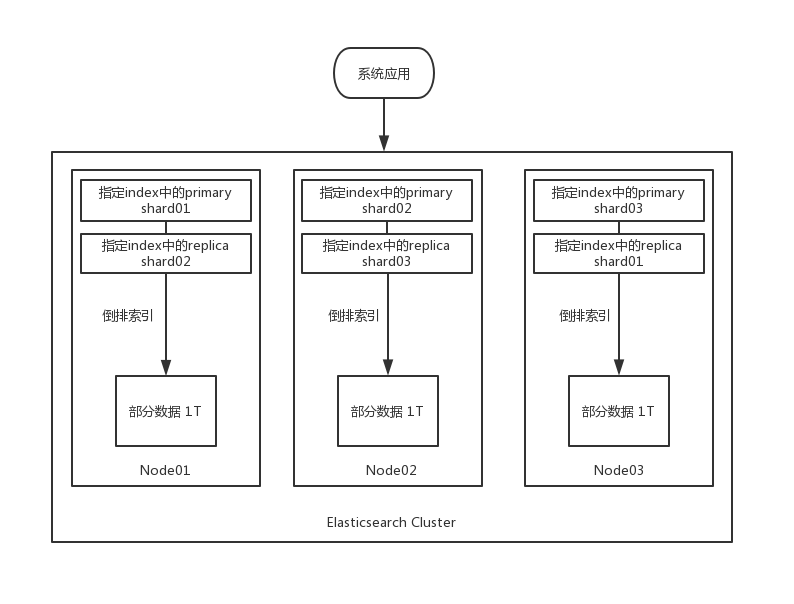
Elasticsearch默认是支持每个index是5个primary shard(在Elasticsearch 7.0 中默认是1个),每个primary shard有1个replica shard作为副本。副本的增加不会导致index容量的增加。
总结
介绍了分布式的基本概念,分布式系统的架构日益完善和成熟,分布式搜索引擎的应用愈来愈广泛,分布式搜索引擎的版本和技术也在快速迭代,逐渐超越了其最初的纯搜索引擎的角色。个人认为,分布式体系架构的主要原因还是在于目前经典计算机的算力和存储瓶颈,如果量子计算机投入商用,绝对是是人类科技的又一次颠覆性革命。
学海无涯。
