分布式索引的介绍
es分片机制:es提供了将索引细分为多个碎片的功能。创建索引时,只需定义所需的分片数量即可。每个分片本身就是一个功能齐全且独立的“索引”,
我们此时要预估 数据 比方1亿的数据 要建立多少个分片
es 有一个副本 re'plicas 用来响应取数据// 读数据
es副本越多 读取越快 主要处理并发
比方说此时我建立了 2个分片
此时要存入1,2,3,4 4条数据 会根据取余来判断 数据在那个分片中
[类似于分段锁机制]
如果调整了分片数 ,此时要重建索引
类似于CurrentHashMap一样 将key 存储在不同的节点上
分布式索引要最开始预估好数据量
我们使用命令
PUT test_index/ 创建索引 默认是分了5个分片 一个副本

我们可以用head工具查看
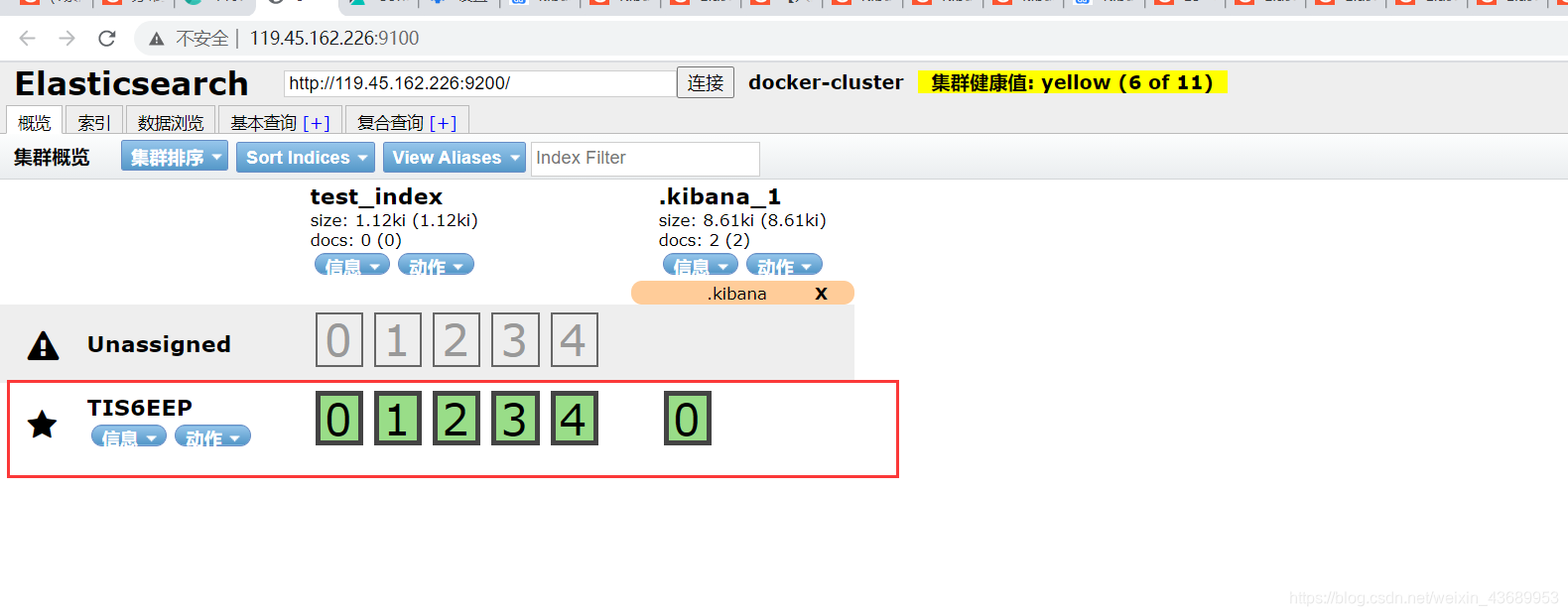
es集群的搭建 此时我们用命令 GET _cat/nodes?v 就可以看到哪一个是主节点 同样head插件也可以看到


==============================>
es当中的细节操作
1, es的数据最终是存在分片中的,集群中启动一个节点 就类似于对这个主分片建立一个副本,但是分片具体落在哪一节点是不确定的
分片的概念就类似于redis 的cluster将数据分别存储在不同的节点上
2.分片到底建立多少 如果你的这个服务器是8核CPU,一个分片不超过500G
3.es内部用的transport协议 用来做数据传输的
Es集群搭建
node1.elasticsearch.yml
#集群名字
cluster.name: myes
# 节点名字
node.name: node-1
#是否作为主机
#node.master: true
#是否作为数据节点
#node.data: false
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
# --------------------------------- 发现 ----------------------------------
# 其他节点的地址端口号,注意端口号为 节点通信端口
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300","127.0.0.1:9302", "127.0.0.1:9303"]
# 有资格作为master的节点的最小数量
#discovery.zen.minimum_master_nodes: 1
# 节点将会等待响应多久后超时
discovery.zen.fd.ping_timeout: 30s
# 跨域
http.cors.enabled: true
http.cors.allow-origin: "*"
node2.elasticsearch.yml
#集群名字
cluster.name: myes
# 节点名字
node.name: node-2
#是否作为主机
#node.master: true
#是否作为数据节点
#node.data: false
network.host: 0.0.0.0
http.port: 9202
transport.tcp.port: 9302
# --------------------------------- 发现 ----------------------------------
# 其他节点的地址端口号,注意端口号为 节点通信端口
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300","127.0.0.1:9302", "127.0.0.1:9303"]
# 有资格作为master的节点的最小数量
#discovery.zen.minimum_master_no#des: 1
# 节点将会等待响应多久后超时
discovery.zen.fd.ping_timeout: 30s
# 跨域
http.cors.enabled: true
http.cors.allow-origin: "*"
```bash
分布式索引的介绍
es分片机制:es提供了将索引细分为多个碎片的功能。创建索引时,只需定义所需的分片数量即可。每个分片本身就是一个功能齐全且独立的“索引”,
我们此时要预估 数据 比方1亿的数据 要建立多少个分片
es 有一个副本 re'plicas 用来响应取数据// 读数据
es副本越多 读取越快 主要处理并发
比方说此时我建立了 2个分片
此时要存入1,2,3,4 4条数据 会根据取余来判断 数据在那个分片中
[类似于分段锁机制]
如果调整了分片数 ,此时要重建索引
类似于CurrentHashMap一样 将key 存储在不同的节点上
分布式索引要最开始预估好数据量
我们使用命令
PUT test_index/ 创建索引 默认是分了5个分片 一个副本
我们可以用head工具查看
es集群的搭建 此时我们用命令 GET _cat/nodes?v 就可以看到哪一个是主节点 同样head插件也可以看到
==============================>
es当中的细节操作
1, es的数据最终是存在分片中的,集群中启动一个节点 就类似于对这个主分片建立一个副本,但是分片具体落在哪一节点是不确定的
分片的概念就类似于redis 的cluster将数据分别存储在不同的节点上
2.分片到底建立多少 如果你的这个服务器是8核CPU,一个分片不超过500G
3.es内部用的transport协议 用来做数据传输的
Es集群搭建
node1.elasticsearch.yml
#集群名字
cluster.name: myes
# 节点名字
node.name: node-1
#是否作为主机
#node.master: true
#是否作为数据节点
#node.data: false
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
# --------------------------------- 发现 ----------------------------------
# 其他节点的地址端口号,注意端口号为 节点通信端口
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300","127.0.0.1:9302", "127.0.0.1:9303"]
# 有资格作为master的节点的最小数量
#discovery.zen.minimum_master_nodes: 1
# 节点将会等待响应多久后超时
discovery.zen.fd.ping_timeout: 30s
# 跨域
http.cors.enabled: true
http.cors.allow-origin: "*"
#集群名字
cluster.name: myes
# 节点名字
node.name: node-3
#是否作为主机
#node.master: false
#是否作为数据节点
#node.data: true
network.host: 0.0.0.0
http.port: 9203
transport.tcp.port: 9303
# --------------------------------- 发现 ----------------------------------
# 其他节点的地址端口号,注意端口号为 节点通信端口
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300","127.0.0.1:9302", "127.0.0.1:9303"]
# 有资格作为master的节点的最小数量
#discovery.zen.minimum_master_nodes: 1
# 节点将会等待响应多久后超时
discovery.zen.fd.ping_timeout: 30s
# 跨域
http.cors.enabled: true
http.cors.allow-origin: "*"
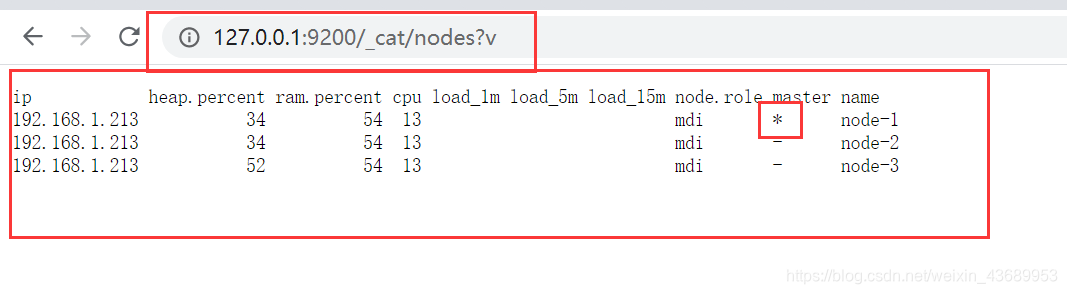
然后通过命令查看集群是否启动成功以及节点的信息
http://127.0.0.1:9200/_cat/nodes?v 查看集群节点的信息,*代表为主master
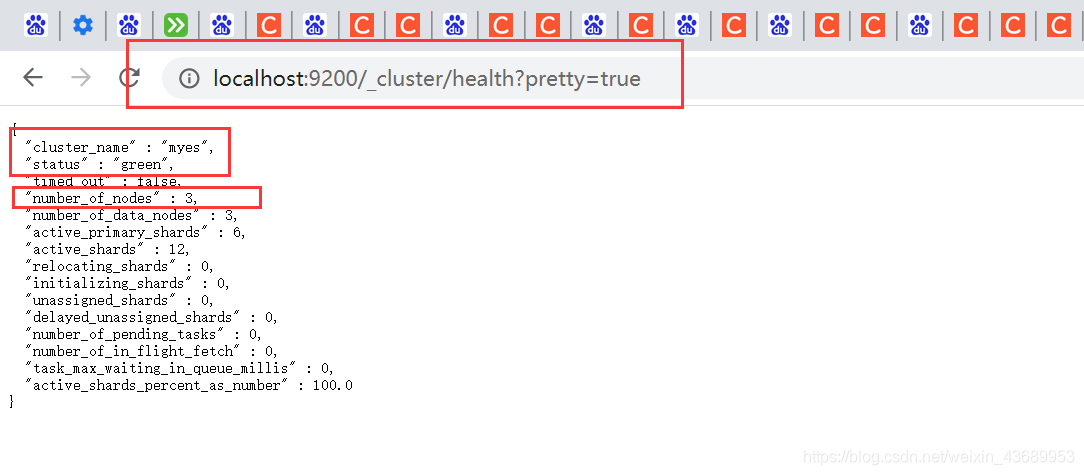
http://localhost:9200/_cluster/health?pretty=true 查看集群的健康状态 green 代表健康
然后可以下载个head插件用来查看信息
集群的状态
green 绿色 代表此时副本够用
yellow 黄色 代表此时有索引的副本不足,一个不足就会变为黄色
1.es的数据存储在分片中的,比方说2台机子集群, 设置5个分片 一个副本
此时比如说 0分片 在哪一个机子上,他的副本在哪一个机子上
2.集群状态为yellow 可以用head插件看是哪一个索引出现的问题
3.副本响应读操作,并发量大的时候一台机子有限,副本越多读取越快
4.es的副本 就饿类似于redis的从节点,es中的分片就类似于redis集群中的小主从的主节点一样
5.es默认5个分片 1个副本 代表此时有5个分片 ,将5个分片 复制一份作为副本,分片在那个node上这个是随机的 ,但是分片和副本不在一个node上 为了灾备,类似于下图 2个0 永远不会在一个机器上 ,比较粗的代表是分片 细的代表副本
6.如果是3个node进行集群 主分片5个 副本一个 ,[此时最多有2个副本],使用了1个,必然有一个副本的位置是空的 就像下面的图一样 也就是说 比如说此时进行读操作的的时候 访问node-1 会读不到有些分片的数据,因为此时副本数量 小于集群节点(node)的数量
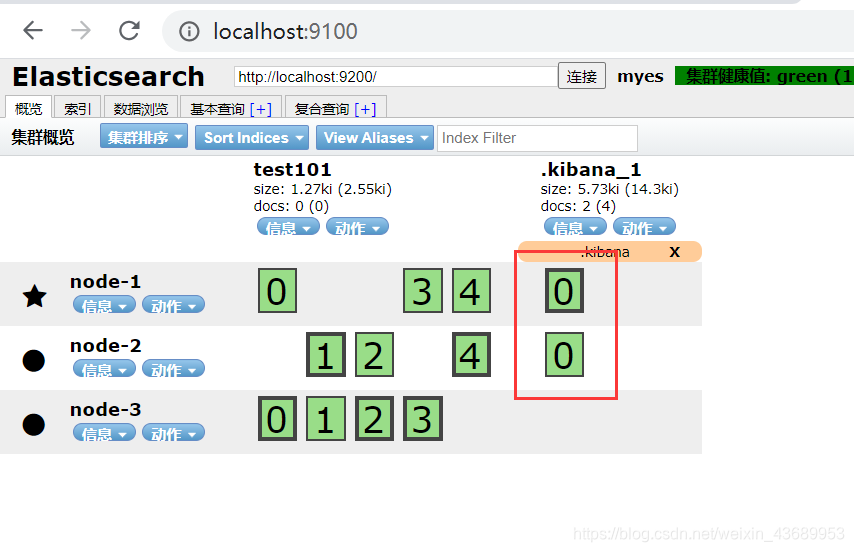

1>分布式索引分片数量是不能改变的,因为你数据存储在分片上,一旦改变,再次访问的时候 会访问不到 数据丢失
比如 id=1,2,3,4 4条数据2个分片
id 1,3 --->分片1
id 2,4 --->分片2
此时改变分片数据会丢失,因为改变之后再取是取不到数据的,所以说分片一旦建立就不能再修改
如果一定要改 就得要重建索引
比方说分片从2--->4,就要重建索引吧数据丢过来
es集群搭建成功后 head-->查看集群状态,黄色代表副本不足,绿色代表有足够的副本
// 接下来我们使用 put命令来创建索引
PUT /test101
{
}
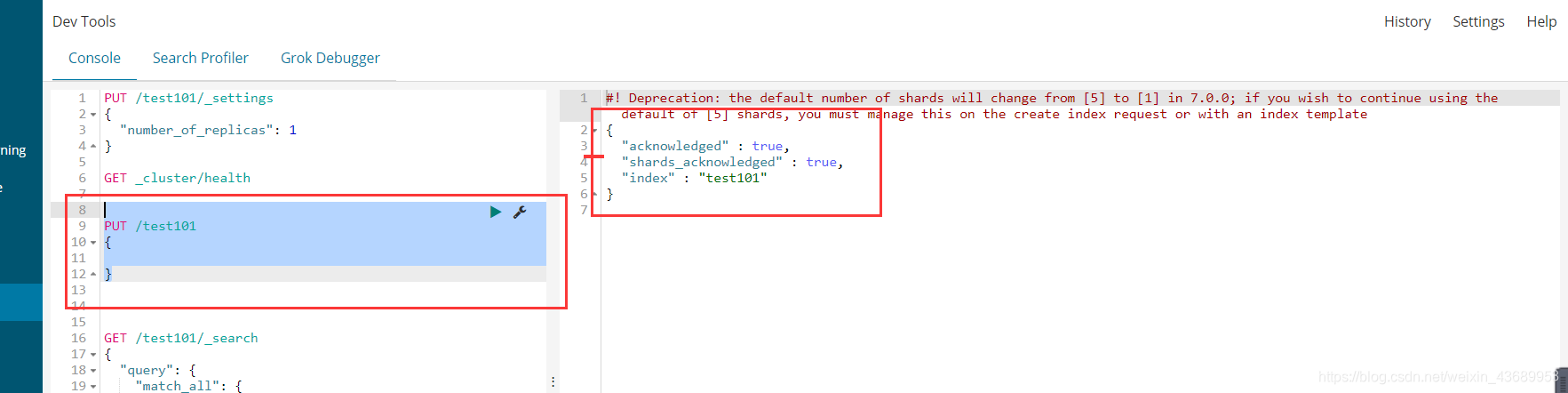
es6X版本默认创建了5个分片1 个副本
7版本 默认创建1个分片1个副本
还是这个图 0,1,2,3,4 就是5个分片,2个0 代表一个分片一个副本,分片和副本不在一个node上 ,分片是随机分的,0和0 永远不在一个node上, 如果分片和副本在一个node节点上,呢就吃一个node了,在2个机子上的目的是为了灾备,一个机器挂了 另一个机子还是可用的
如果在一起的话 我机子挂了 代表数据丢失 [灾备]
//
我们建立了 0,1,2,3,4 表示建立了5个分片 然后 有2个0就表示 一个分片一个副本
分片和副本不在一个机子上意味值灾备 如果分片和副本在一个机子上 机子挂了数据丢失
粗的代表主分片 细的就是副本 有粗有细

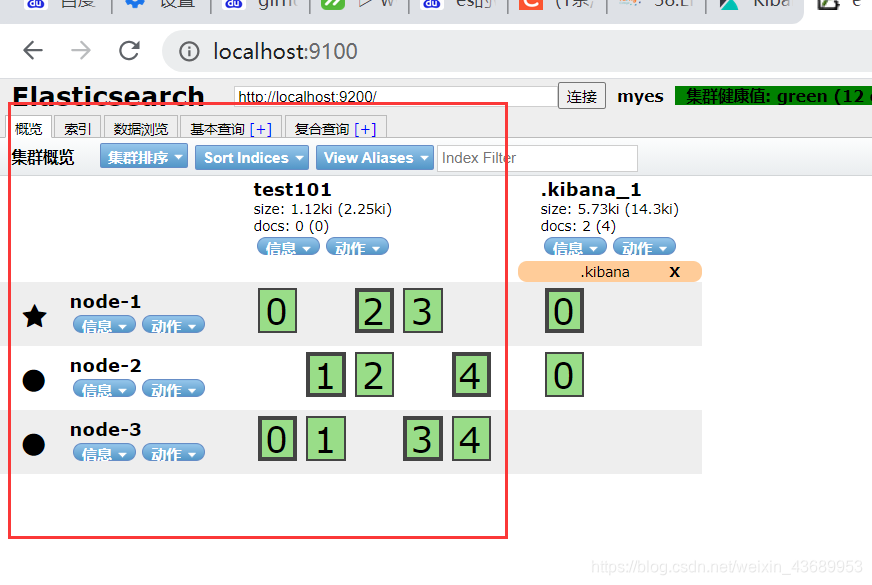

我们可以指定分片创建索引 比如说 我指定1个分片1个副本
PUT /test100
{
"settings":{
"number_of_shards": 1,
"number_of_replicas": 1
}
}
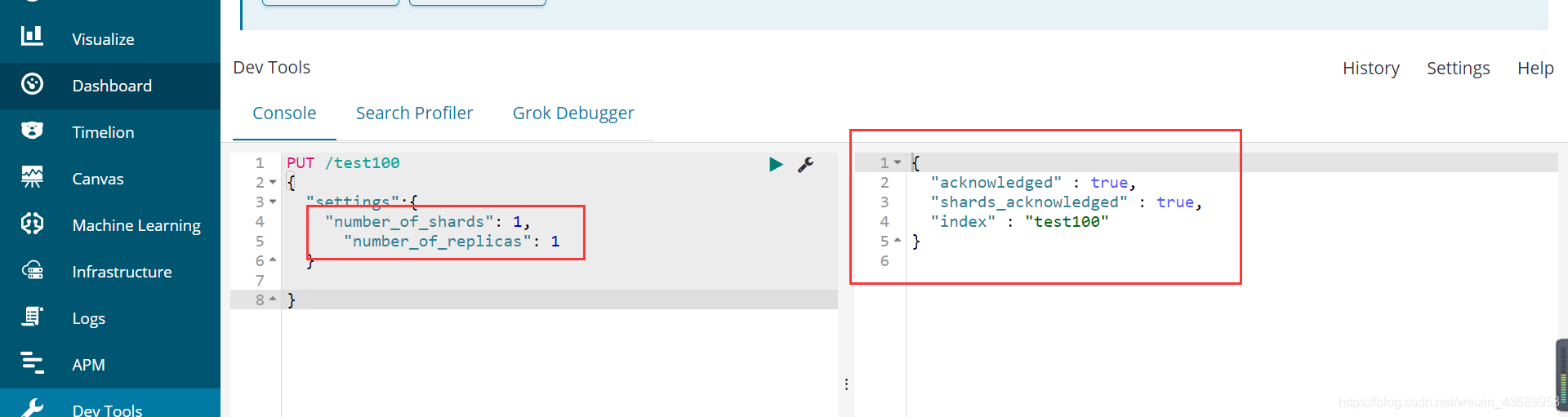
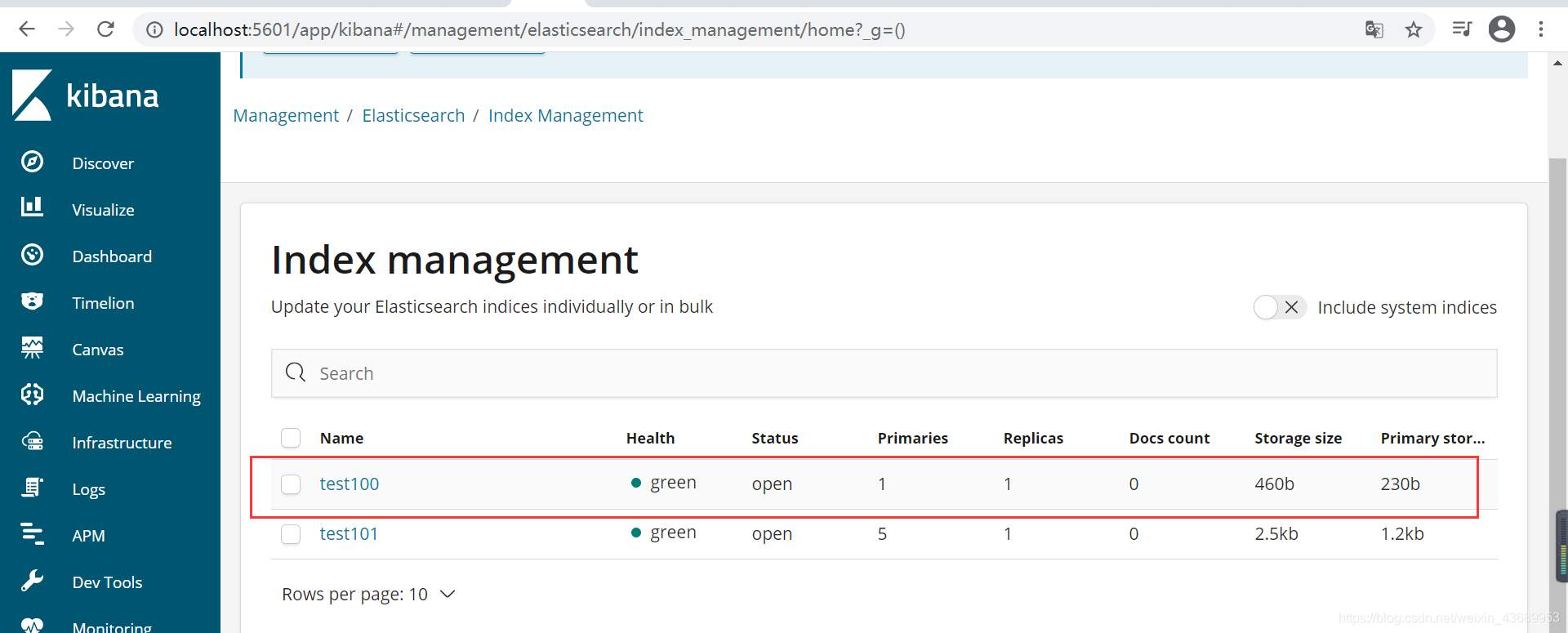
此时我们建立一个索引 1个分派你一个副本 在head中就可以观察到
es的分片是不能更改的 如果此时更改会报错
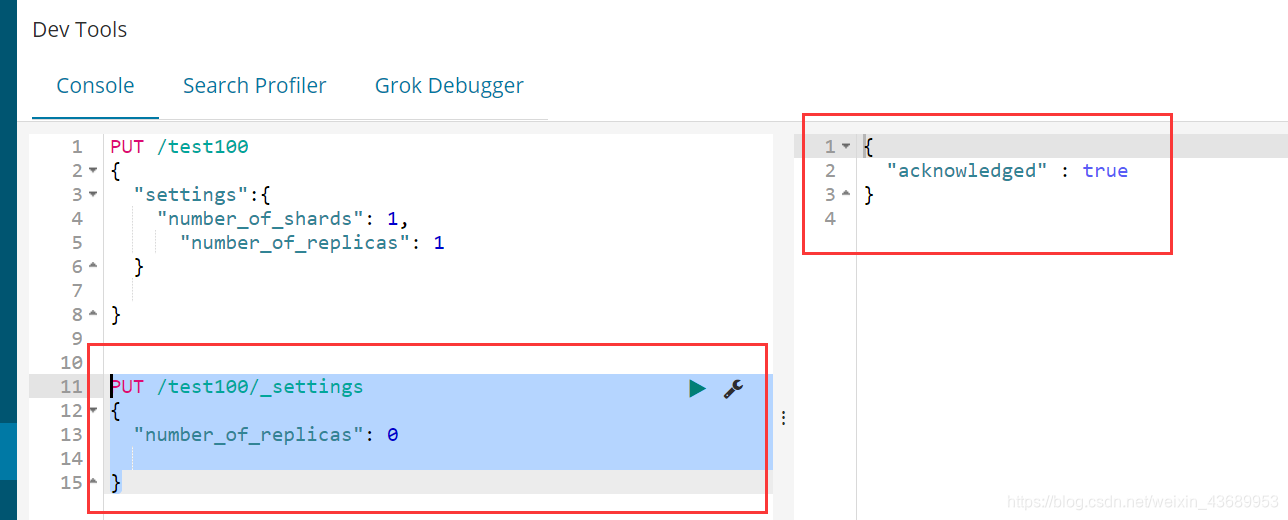
索引的主分片不能调整 []副本可以调整 更改副本
比如说此时我们把他的副本设置为0
PUT /test100/_settings
{
"number_of_replicas": 0
}
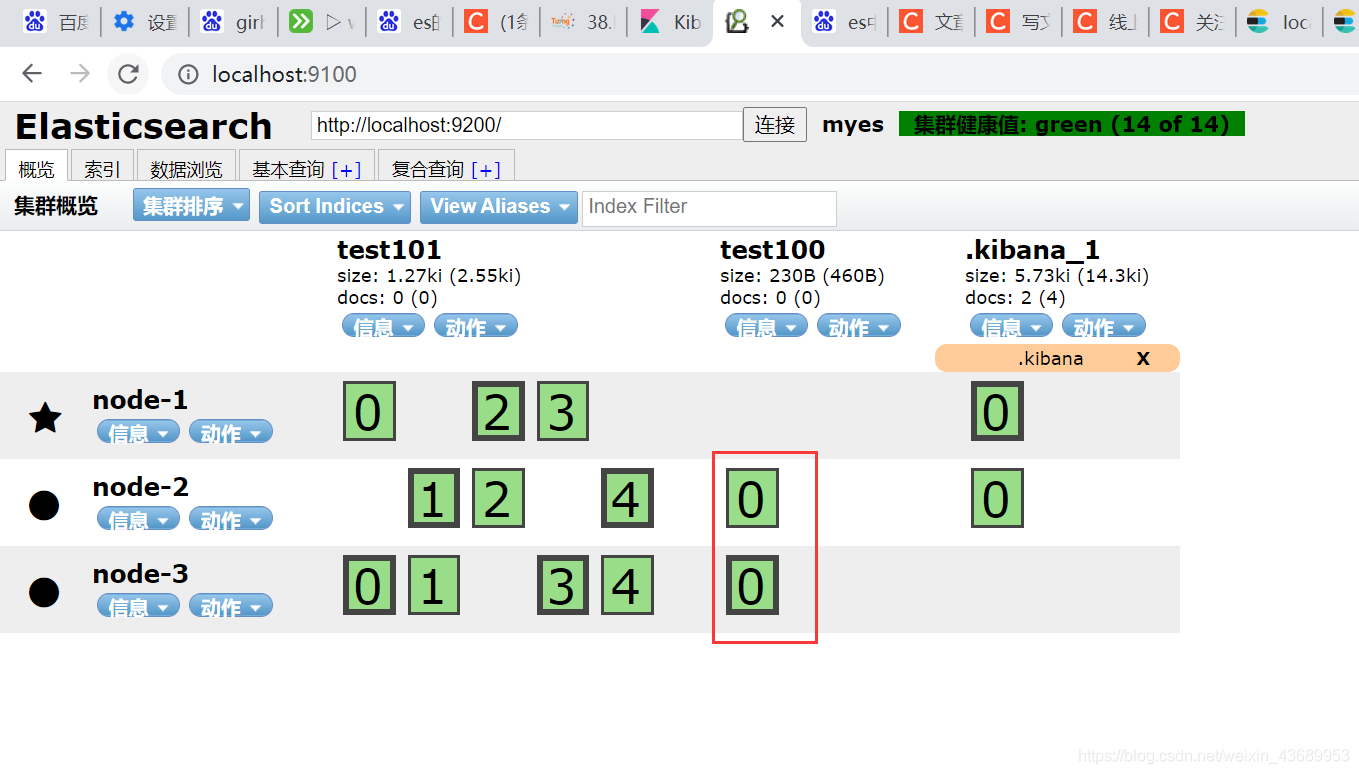
看到了把他就没有副本了 但是此时如果把他的副本设置为10 总之就是超过node的个数 因为此时我的node 是3会怎么样

-----------------------------------------
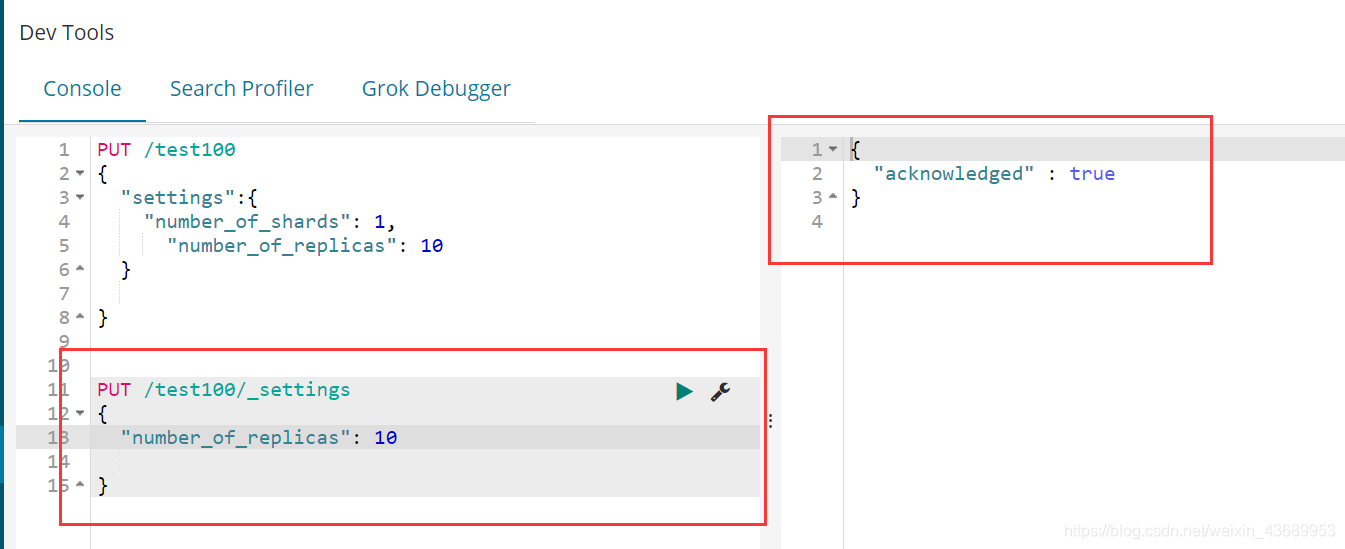

就会出现Unassigned数据
然后集群的的颜色就会变成黄色 代表此时副本不足 当集群的颜色变黄的时候 我们此时要排查是哪一个索引下的副本不足
他此时最多只有2个副本 因为只有2个节点, 多余的7个就在Unassigned 代表此时副本不足 或者说node 不足
副本不够--->缺少机器
修改shards 会报错 因为shards 不可以改变的
es中我们怎么进行写数据和读数据呢
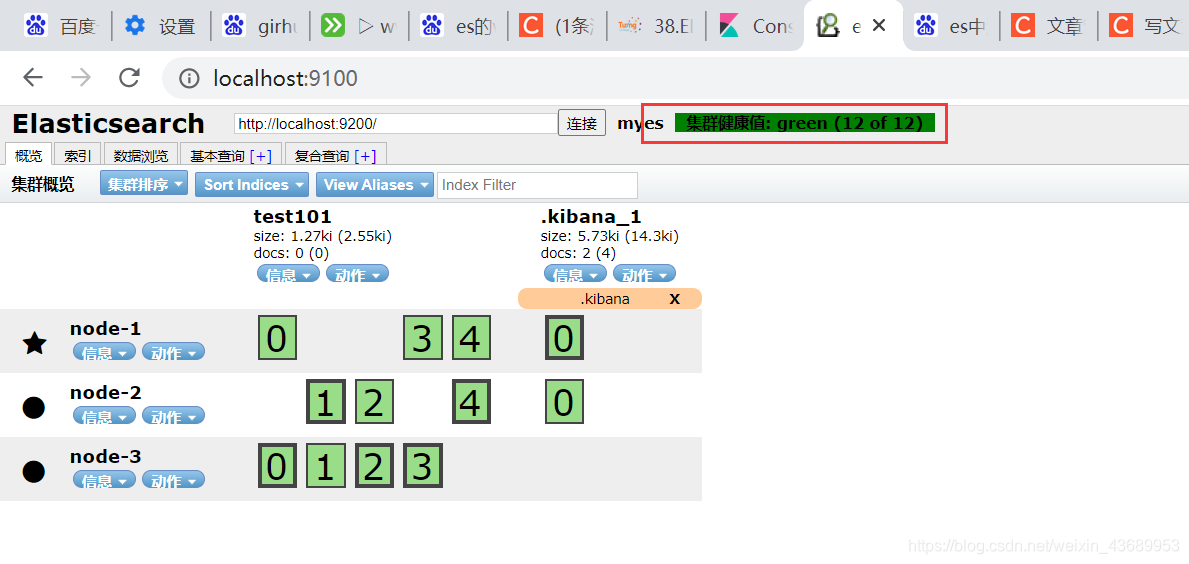
比方说此时把test101的副本改成了2
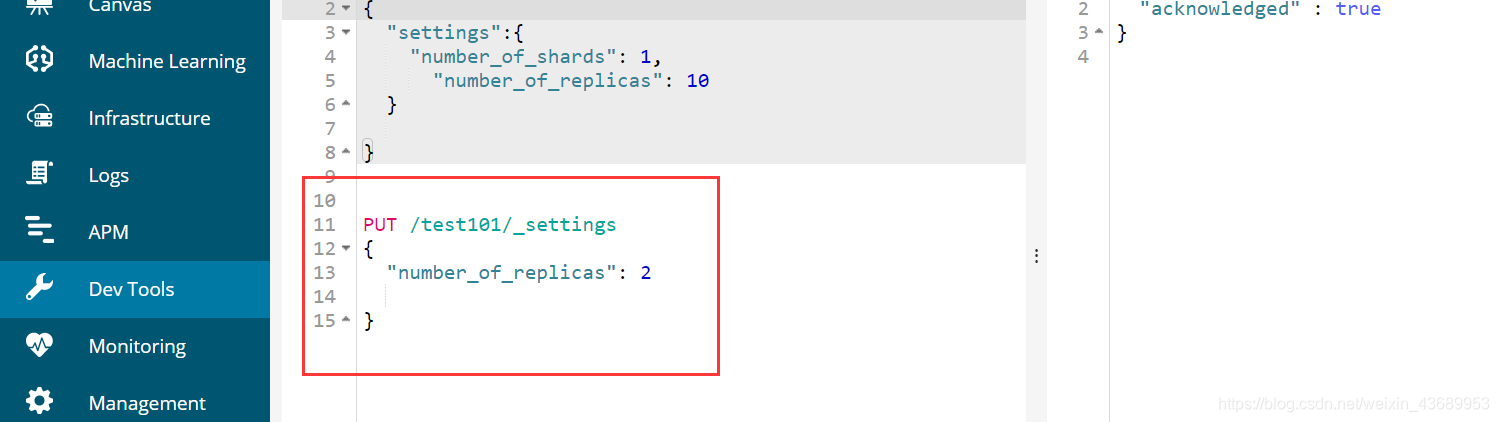
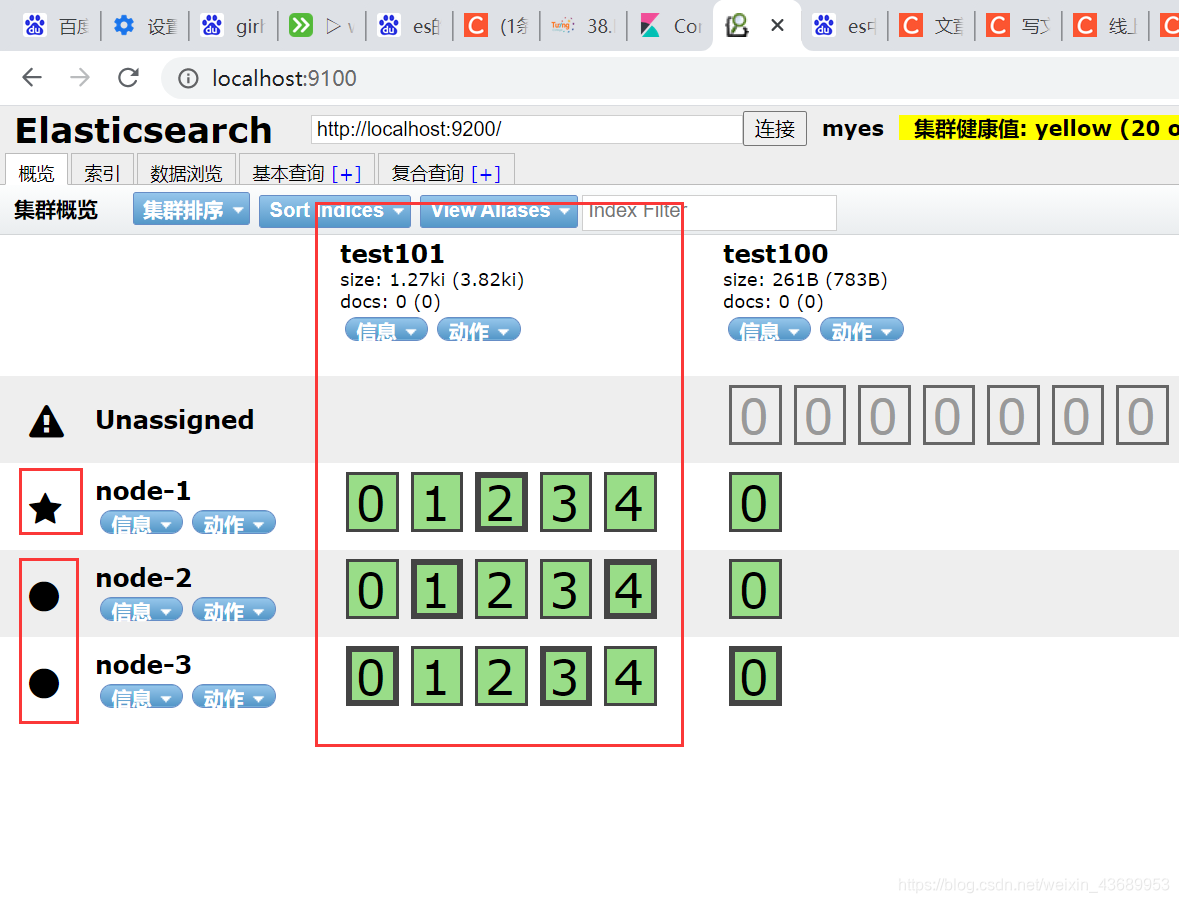
这样每一个node-1都会有0,1,2,3,4的分片或者说副本了
写数据的过程是怎么样呢,五角星代表此时是一个master节点,圈圈代表此时是一个从节点 master节点会干什么事情呢
master节点上面有副本也有分片
我们在给集群中写数据的时候,不管发送到node-1 还是node-2 还是node-3,也就是说我们可以给node-1 发送写的请求,也可以给node-2发送写的请求, 但是 他们都最终会把写请求丢到master节点上,master干了个什么事情,将数据进行分发,首先将数据分发到各个分片上,然后再看这个分片在那个node上
比如说当前这个请求应该放在2分片上,然后 --->2分片在哪一个node上,或者说哪一个节点上
主分片完成任务后 副本就会异步把数据进行同步 实时性有延时 因为是异步操作
//------------>
读请求 读请求在每一个机器上都可以操作 他不一定非要在主节点上进行操作,
因为看图每一个node都存有分片信息[node等于分片数 或者node小于副本数]
//3个node 6个副本 节点不足
//6个node 3个副本 访问不到
如果node 大于副本数 就会有空隙 意味着读取不到数据
所以说master的负载量很大 因为要确定doc在哪一个分片上
读在每一个node都可以处理
副本指的是分片的备份