今天我们来说下我们把mysql中的数据导入到Es中需要注意点什么
首先要对我们的es字段建立mapping
假设我们此时有这么一个表
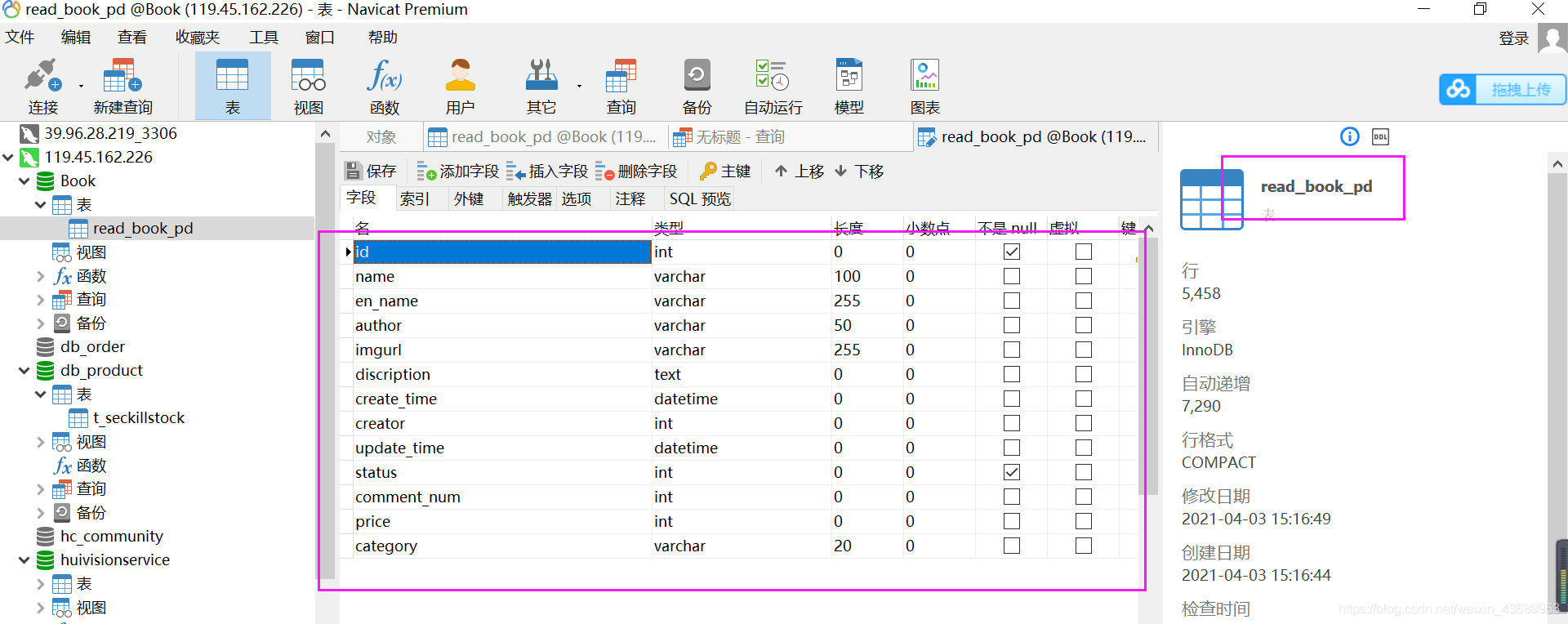
我们此时第一步就是让他建立mapping 然后 进行搜索啊
PUT /book
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 1
},
"mappings": {
"_doc": {
"properties": {
"bookId": {
"type": "integer"
},
"bookName": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"bookEnName": {
"type": "text",
"analyzer": "english"
},
"commentNum": {
"type": "integer"
},
"price": {
"type": "integer"
},
"author": {
"type": "keyword"
},
"imgurl": {
"type": "text"
},
"createTime": {
"type": "long"
},
"status": {
"type": "integer"
},
"discription": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}
}
在建立mapping的时候 要注意一点就是 有的字段需要建立分词 有的不必要建立分词 [也就是说此时如果建立分词的话 就会建立倒排索引]
在建立索引的时候 字段是有一个属性 的index ,如果index是true的话 代表此这个字段需要建立分词[默认],如果是false的话 则不需要建立分词
PUT /book
{
"settings": {
}
, "mappings": {
"properties": {
"bookId":{
"type": "text"
, "index": true
}
}
}
}
接下来我们的查询就是我们对我们的业务查询
-->比如说我们搜索童话故事大全就能搜索出来数据来
GET /book/_search
{
"query": {
"match": {
"bookName": "童话故事大全"
}
}
}
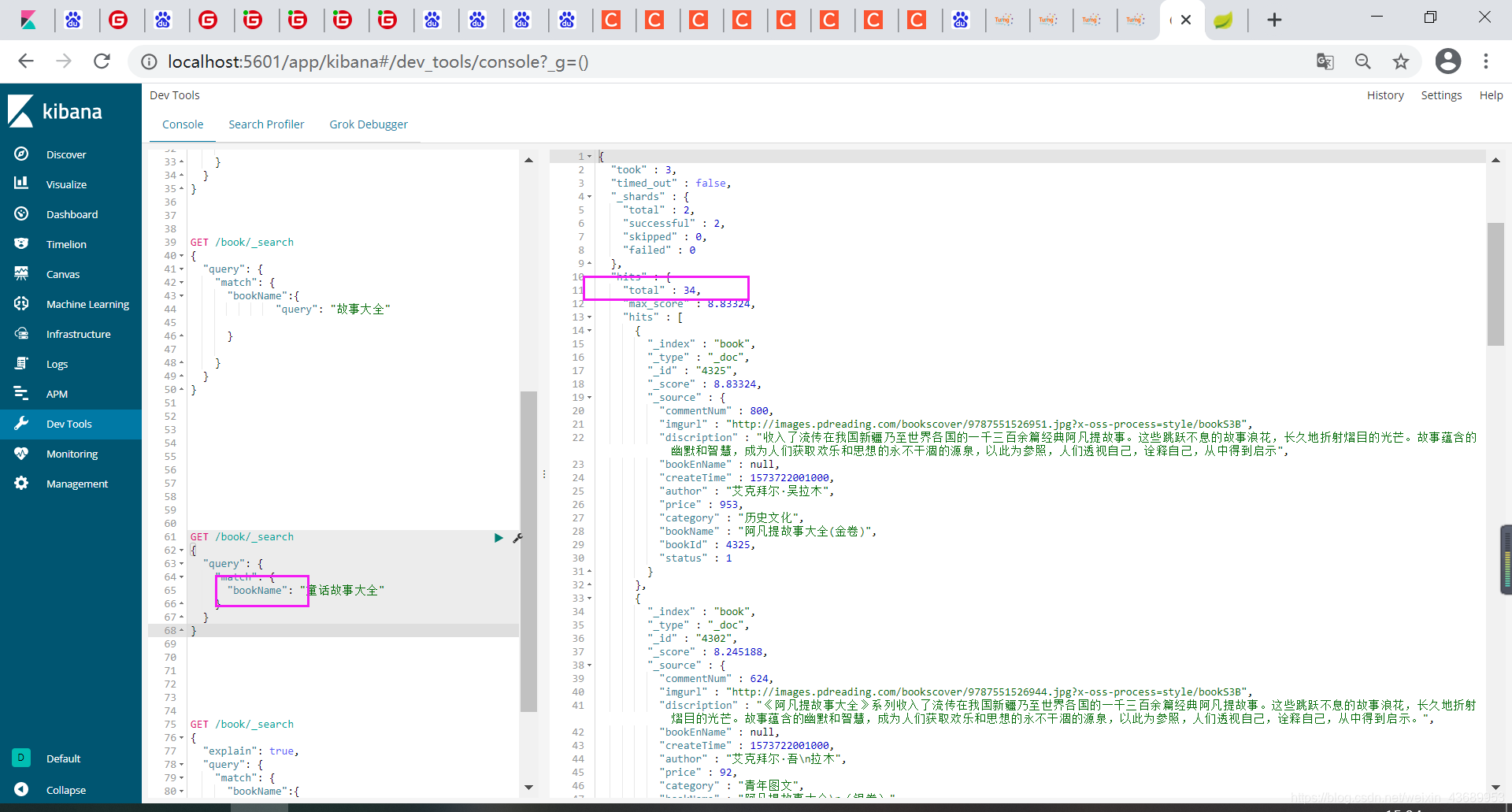
GET /book/_validate/query?explain
{
"query": {
"match": {
"bookName": "童话故事大全"
}
}
}
// 我们可以用他 query?explain语句查看
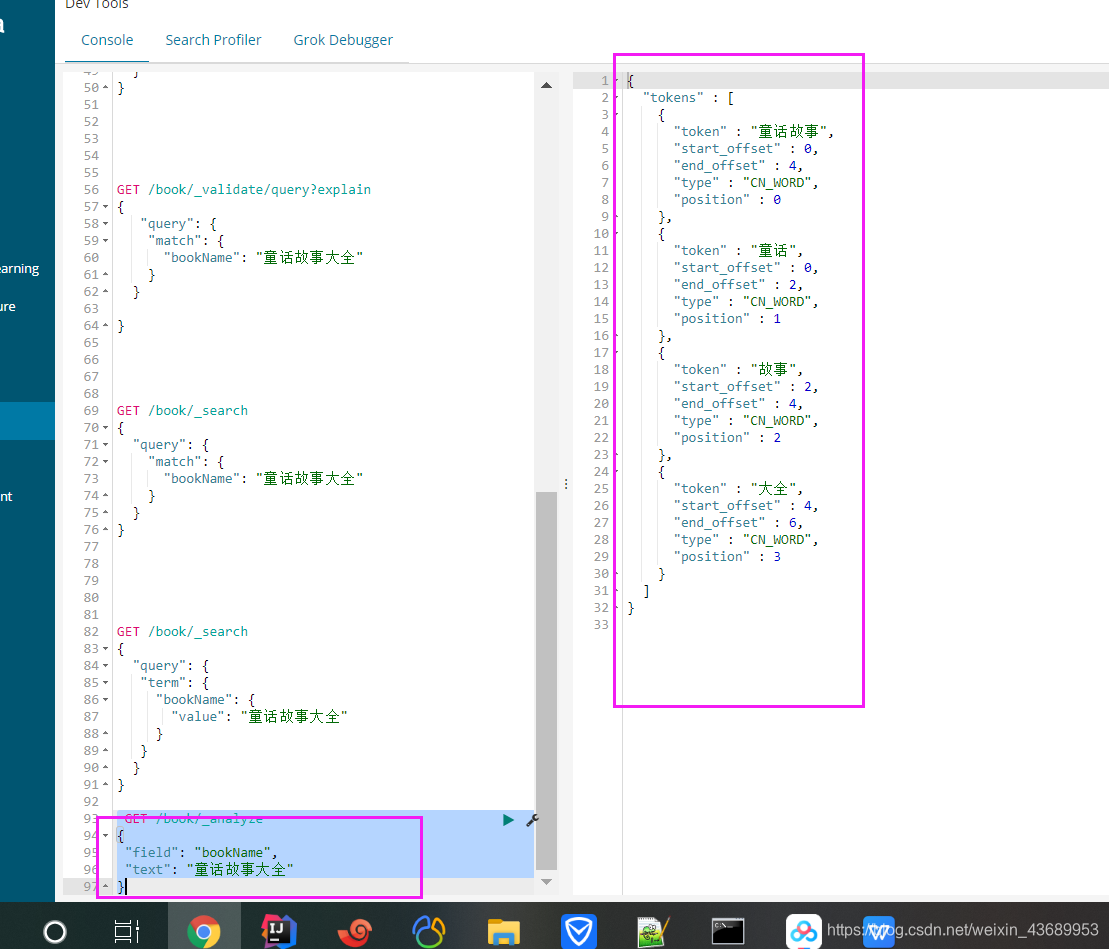
es此时会怎么查询这句话 意思是这个童话故事大全此时会分词[童话故事和大全] 也就是说他会拿着2个词
他会把这个词语分成 童话故事,大全2个词语 因为此时用的ik_smart
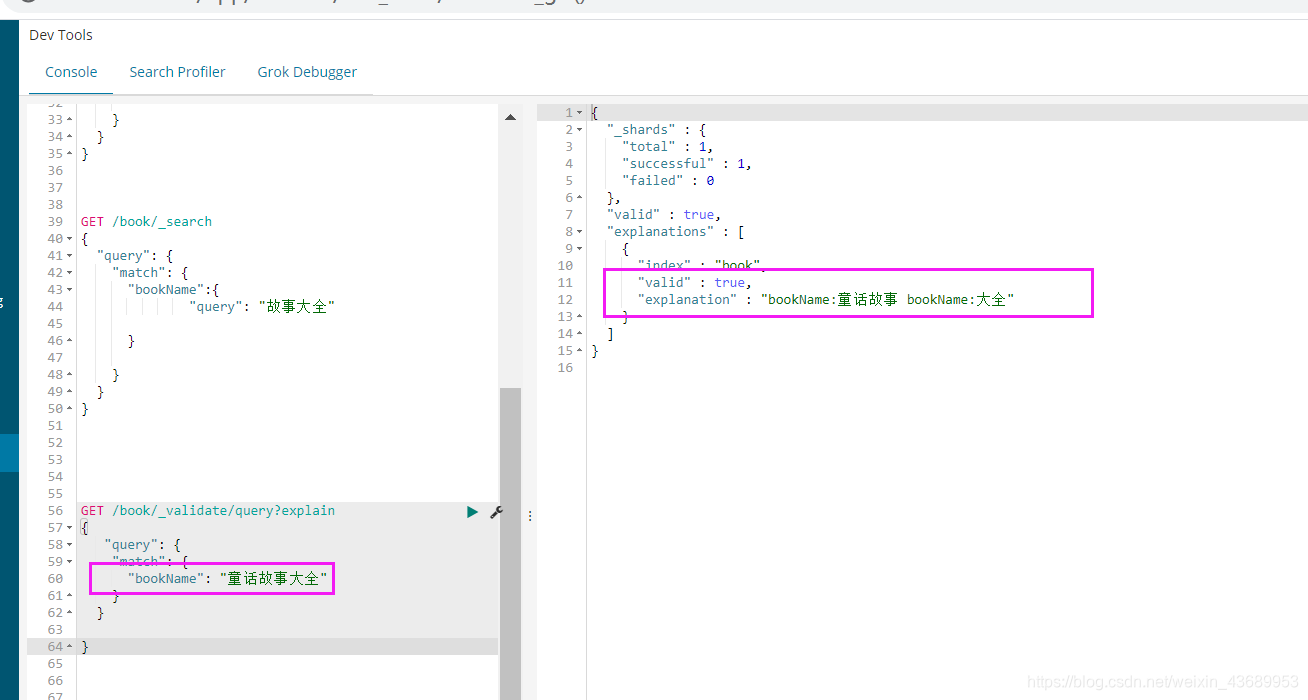
GET /book/_analyze
{
"field": "bookName",
"text": "童话故事大全"
}
//我们也可以用他 但是他只是根据你建立索引的时候查询得 因为我们建索引的时候用的ik_max_word
GET /book/_validate/query?explain
{
"query": {
"match": {
"bookName": "童话故事大全"
}
}
}
很显然
"explanation" : "bookName:童话故事 bookName:大全"
他是把2个只要有一个的就会搜索出来 也就是说or
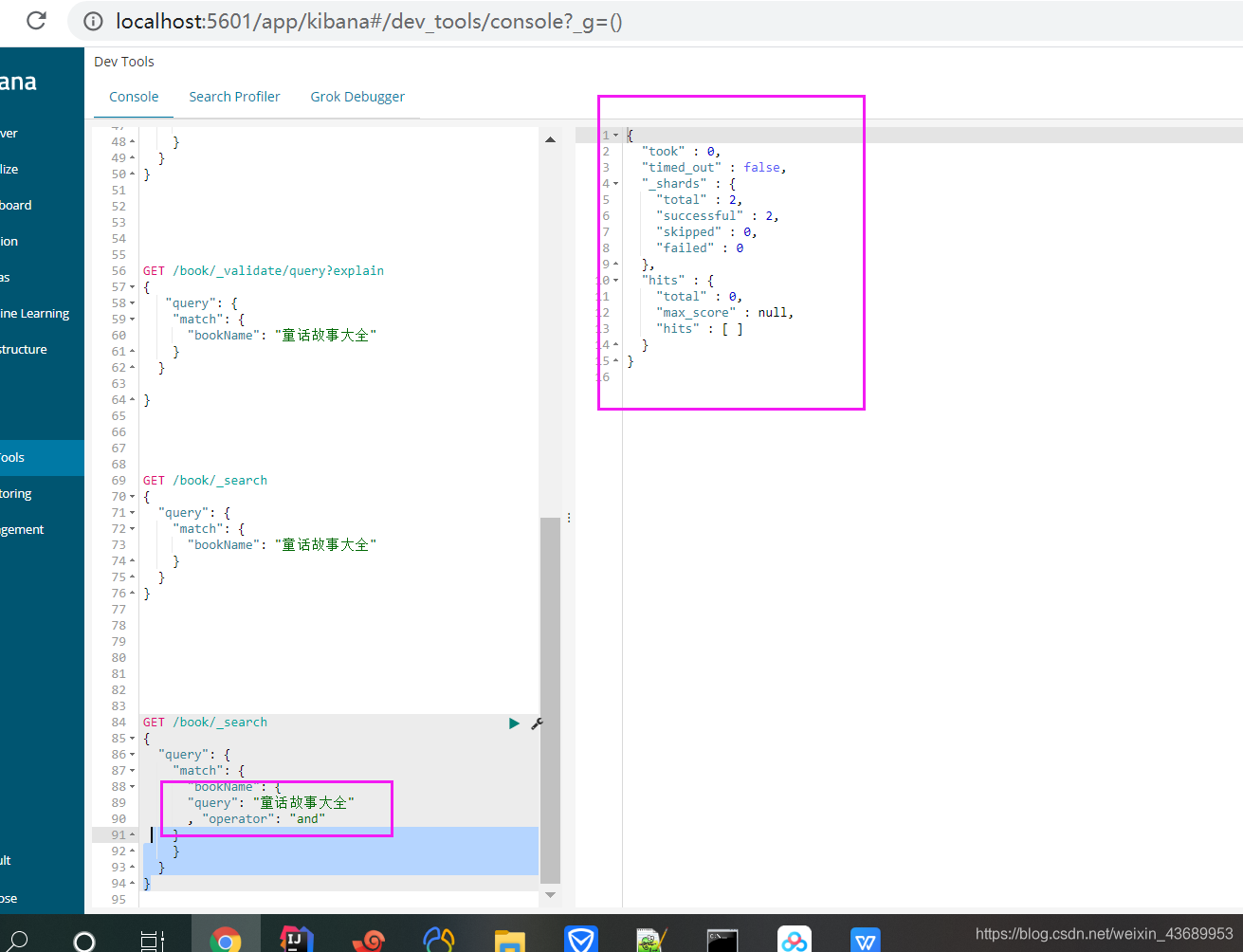
GET /book/_search
{
"query": {
"match": {
"bookName": {
"query": "童话故事大全"
, "operator": "and"
}
}
}
}
//我们可以这样搜索 标注为and 就是说2个都得有才可以搜索出来
//也可以换成or
默认操作是or
使用and 的操作 默认使用的是or match的操作
我终于明白了标签工厂一直让我拼接 operator and operator or 的json字符串 原来是 es命令啊
GET /book/_search
{
"query": {
"term": {
"bookName": {
"value": "童话故事大全"
}
}
}
}
// 我们也可以用term查询就是说[不分词],但是索引中必须要有[童话故事大全]
不会对他进行分词 类似于like [必须在索引里面包含童话故事大全[此时的查询不会分词]] [和like 不一样的地方]
被查询的value 不会被分词
但是必须在[分词中]
分词中肯定没有[童话故事大全]
匹配度分词 有时候我们有这种场景
比如说 使用Or 太多了
GET /book/_search
{
"query": {
"match": {
"bookName":{
"query": "安徒生的大自然童话故事"
, "operator": "or"
}
}
}
}
//-------->and 又一个都没有
GET /book/_search
{
"query": {
"match": {
"bookName":{
"query": "安徒生的大自然童话故事"
, "operator": "and"
}
}
}
}

"explanation" : "bookName:安徒生 bookName:的 bookName:大自然 bookName:童话故事"
在执行这条语句的时候会把这句话 拆分成4个词语
or的意思是只要有一个就会匹配上,也就是说会搜索出来
and 的意思是 4个都得有 才会匹配出来
我们可以稍微加一点控制
"minimum_should_match": 2
意思是至少有2个才可以搜索出来
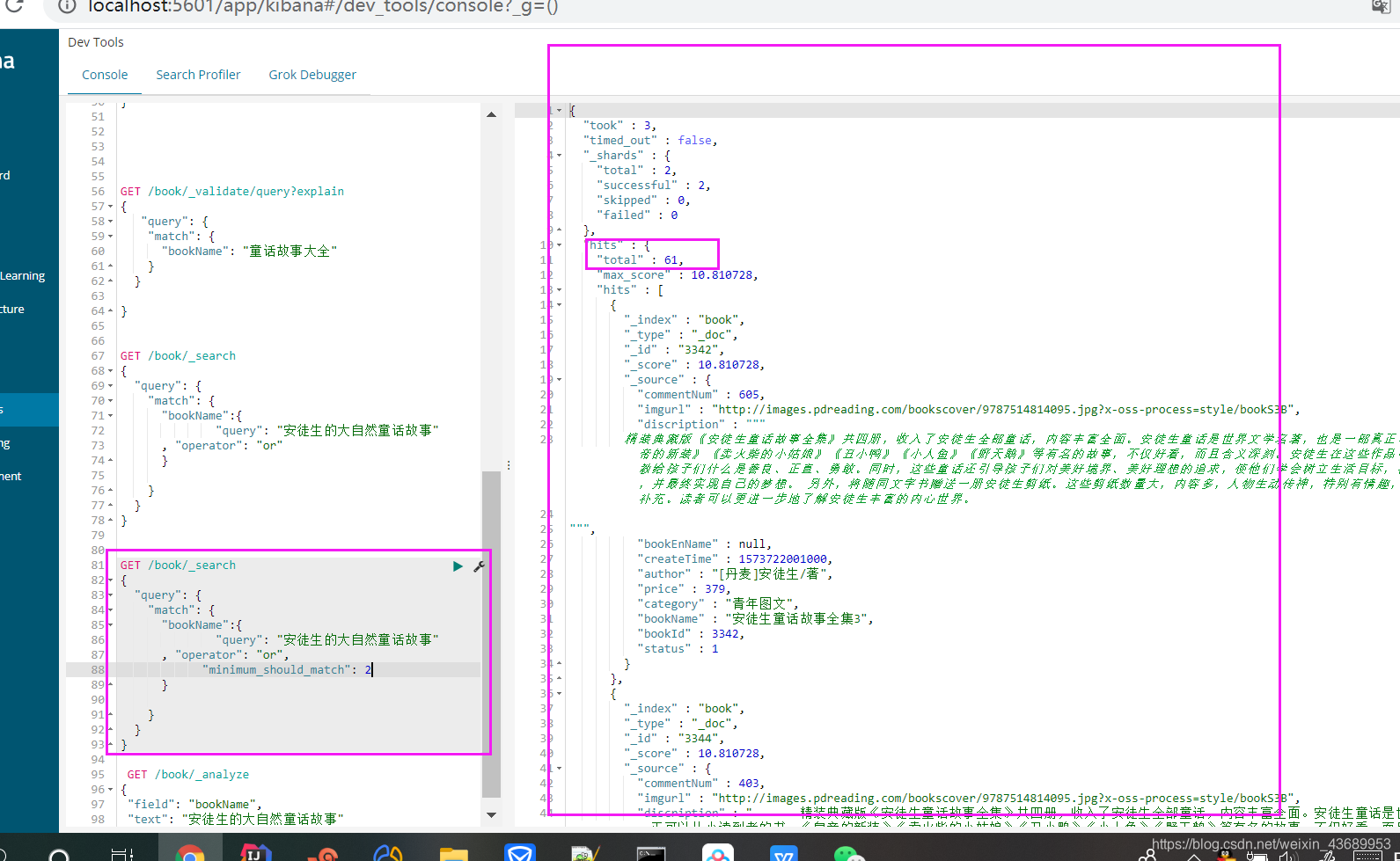
GET /book/_search
{
"query": {
"match": {
"bookName":{
"query": "安徒生的大自然童话故事"
, "operator": "or",
"minimum_should_match": 2
}
}
}
}
如果此时设置为 "minimum_should_match": 1 和不设置一样
因为本来就是默认至少有一个才可以被匹配出来啊
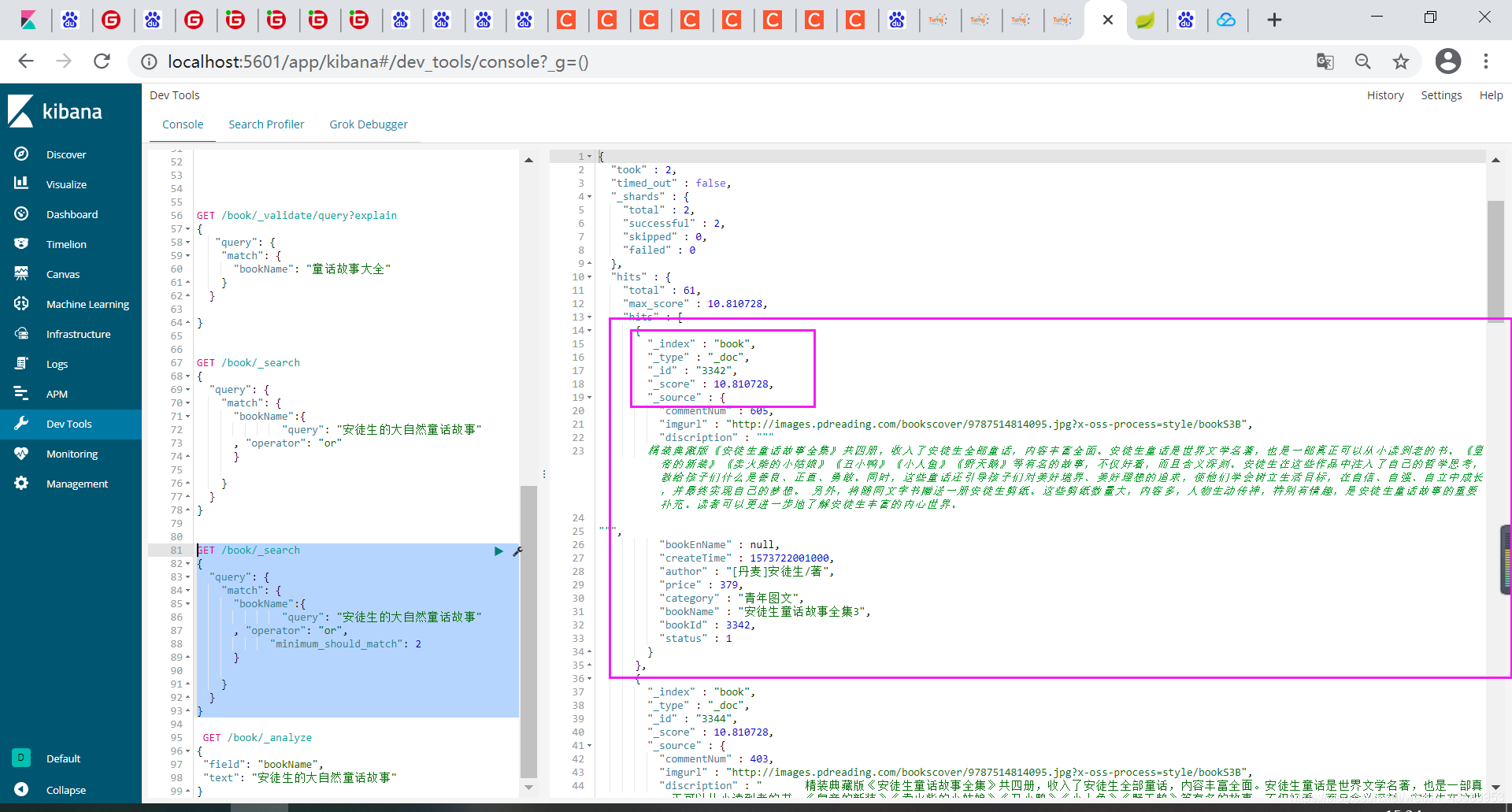
我们看搜索出来的结果
"_index" : "book",
"_type" : "_doc",
"_id" : "3342",
"_score" : 10.810728,
index 就是说此时使用的那个索引 id 就是他的排名
score叫做得分 就是之前的 df*idf 算出来的
他的score 越高代表此时这篇文章于搜索的词越相关
一般在查询的时候[] 比如说我们搜索这个[故事大全],你可能并不是只匹配这个[name],因为我们这里还有一个描述
有可能我们要在[描述中来匹配] 呢么此时怎么办
1.
第一种 我们可以把者2个字段加起来 建一个大的字段[此时 要 检索的字段放在一起],这样我只要查出来一个字段就可以了
第二种就是
GET /book/_search
{
"query": {
"multi_match": {
"query": "大自然的旅行故事",
"fields": ["discripdtion","bookName"]
}
}
}
此时我们可以指定bookName,还可以指定描述
//------->这样只要包含2个字段里面包含他的分词 都可以查出来
BookName 没有 但是描述中有就可以查出来了
只要 discripdtion 或者bookName 中有分词 就可以查询出来

看图 多字段查询
我们还可以用 query_string 来进行查询
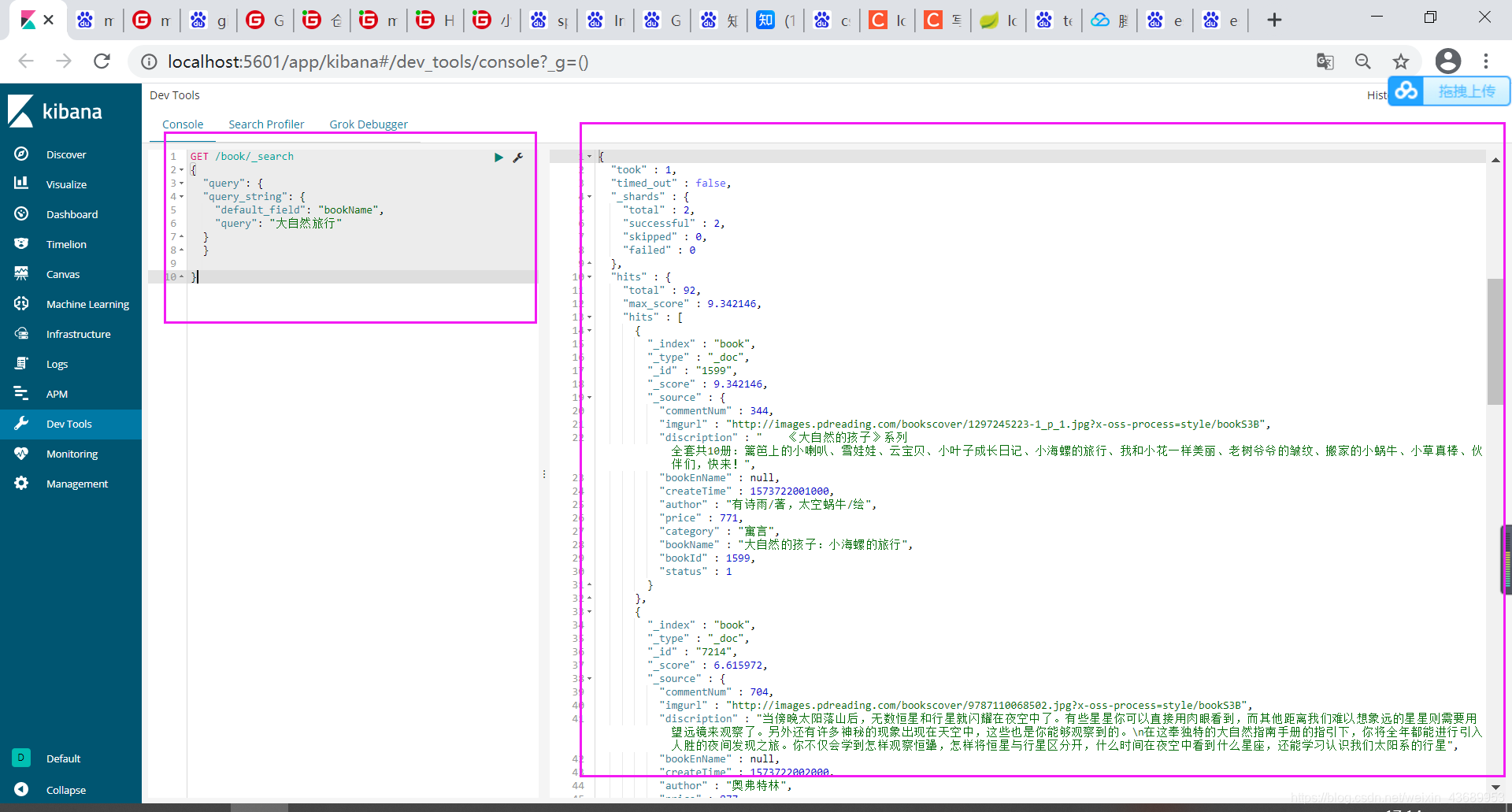
GET /book/_search
{
"query": {
"query_string": {
"default_field": "bookName",
"query": "大自然 AND 旅行"
}
}
}
和 此时也是默认为OR
----------------->
GET /book/_search
{
"query": {
"match": {
"bookName":{
"query": "大自然旅行"
, "operator": "and"
}
}
}
}
一样 这种情况下适合手动分词
es中还有一个布尔查询
GET /book/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"bookName": "安徒生"
}
},
{
"match": {
"discription": "丑小鸭"
}
}
]
}
}
}
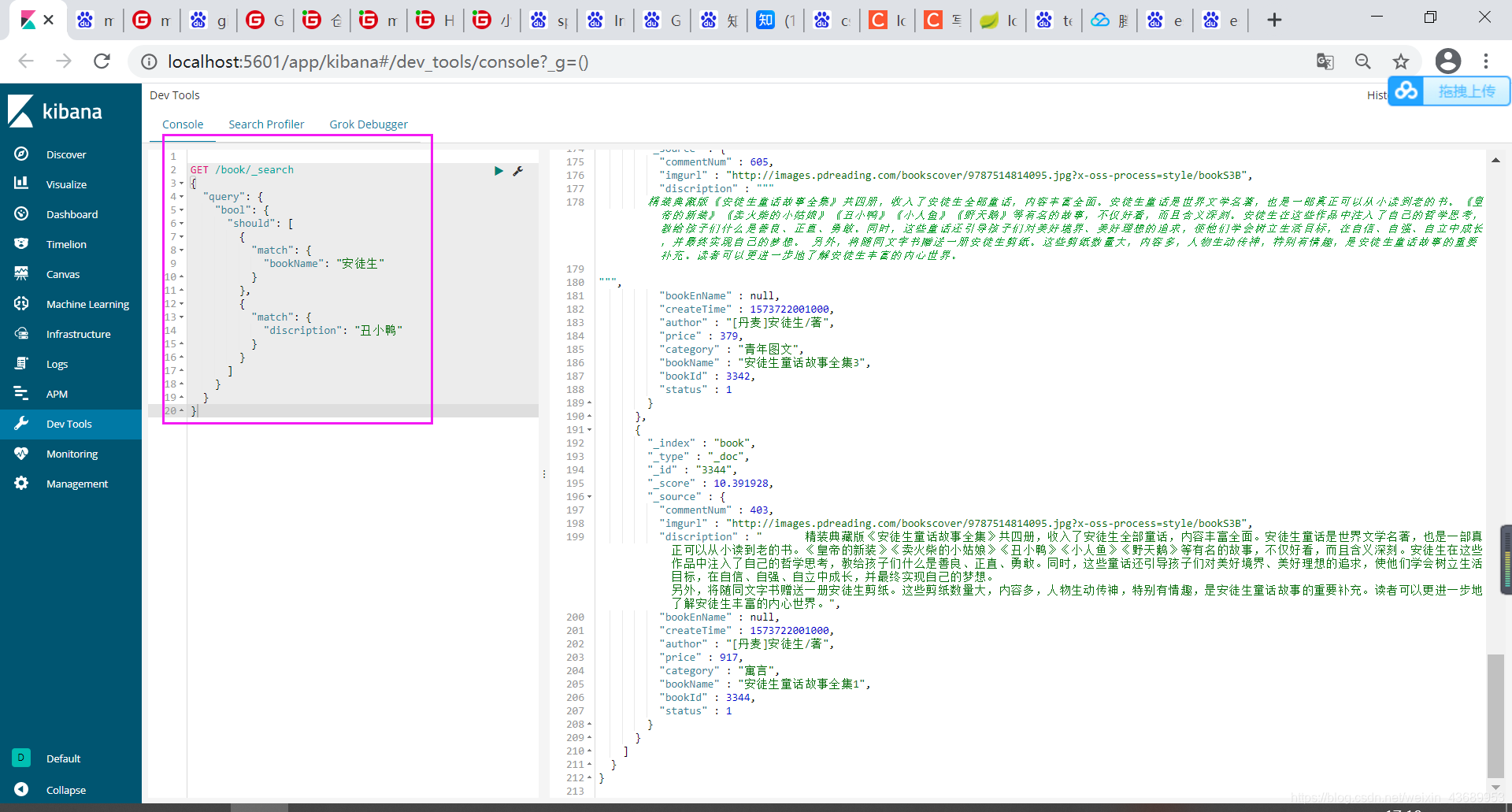
这里的should 就是说 or的意思,就是说只要 bookName 中有安徒生或者说 discription 中有丑小鸭 就可以查出来
GET /book/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"bookName": "安徒生"
}
},
{
"match": {
"discription": "丑小鸭"
}
}
]
}
}
}
// 也可以用must 意思是 bookName 为安徒生并且discription 为丑小鸭 才可以查出来
GET /book/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"bookName": "安徒生"
}
},
{
"match": {
"discription": "丑小鸭"
}
}
]
}
}
}
当然也有 must_not 一定没有