训练模型时的收敛速度问题
众所周知,模型训练需要使用高性能的GPU,还要花费大量的训练时间。除了数据量大及模型复杂等硬性因素外,数据分布的不断变化使得我们必须使用较小的学习率、较好的权重初值和不容易饱和的激活函数(如sigmoid,正负两边都会饱和)来训练模型。这样速度自然就慢了下来。
下面先简单示例一下数据分布的不断变化为什么会带来这些问题,如图:
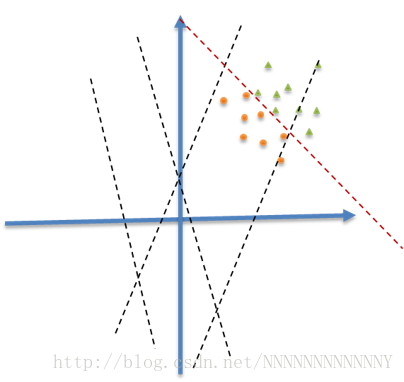
我们使用Wx+b=0对小黄和小绿进行分类。由于数据点仅落在第一象限中很小的区域里,那么如果我们随机初始化权重W,需要迭代很多次才会得到有效的分割,这势必会带来求解速率的下降,并且容易遇到局部最优解。
如果我们遇到的仅仅是这么一个简单的问题,大家用屁股都能想出来应该怎么做。均值归一化呀,把数据挪到原点附近,这样问题就解决了。但是在深度神经网络里,数据分布的不断变化至少来自两方面:a) 每批训练数据的分布各不相同(batch梯度下降),那么网络就要在每次迭代都去学习适应不同的分布。b) 网络中某一层输入数据的分布发生改变,后面几层就会被累积放大下去,这样模型就需要去不断适应学习新的数据分布。论文中把网络中间层在训练过程中,参数不断变化导致的各层输入分布的变化 称为 Internal Covariate Shift。
怎么办呢?这个时候我们可能就会想,如果在每一层输入的时候,再加个预处理操作那该有多好啊。好,BatchNormalization来了。
怎么加入归一化BatchNormalization
这里加入的BatchNormalization层可不想我们想象的那么简单,它是一个可学习、有参数的网络层。为什么呢?如果我们直接对网络某一层A的输出数据做归一化然后送入网络下一层B,这样会影响到本层所学习到的特征。(比如网络中某一层学习到的特征分布在S型激活函数的某一侧,你强制把它归一化到标准差为1内。)怎么办?论文引入了可学习的参数γ、β(文中把他称为变换重构)来保留其学习到的特征,公式如下:
接着论文中进一步证明了这一切参数都是可以链式求导的(具体见论文),因此γ、β也就可以像权重W那样不断迭代优化啦。另一个问题是BatchNormalization层加在哪?有两个落户地址:a) W x +b 之后,非线性激活函数之前 b) 非线性激活函数后。作者认为前者效果要更好一点,给出的解释是:前一个激活层是非线性输出,其分布很可能在训练中变化,而Wx+b更可能“more Gaussian”。(当然也有人简单尝试了一下Post-activation batch normalization,效果也还不错)
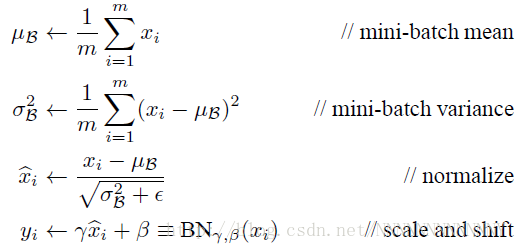
其他一切细节自己看论文吧。
BatchNormalization带来的好处
- 可以选择比较大的初始学习率,让你的训练速度飙涨。
- 移除或使用较低的drop out、L2正则项参数。
- b 可以忽略了,因为b 的作用其实被 β 代替了。
在tensorflow中应用Batch Normalization
A GENTLE GUIDE TO USING BATCH NORMALIZATION IN TENSORFLOW 这篇文章介绍的特别好,并且末尾的GITHUB代码里对全连接网络的No batch normalization、Standard batch normalization和Post-activation batch normalization三种方法进行了实现和对比。贴一张他的实验结果图:
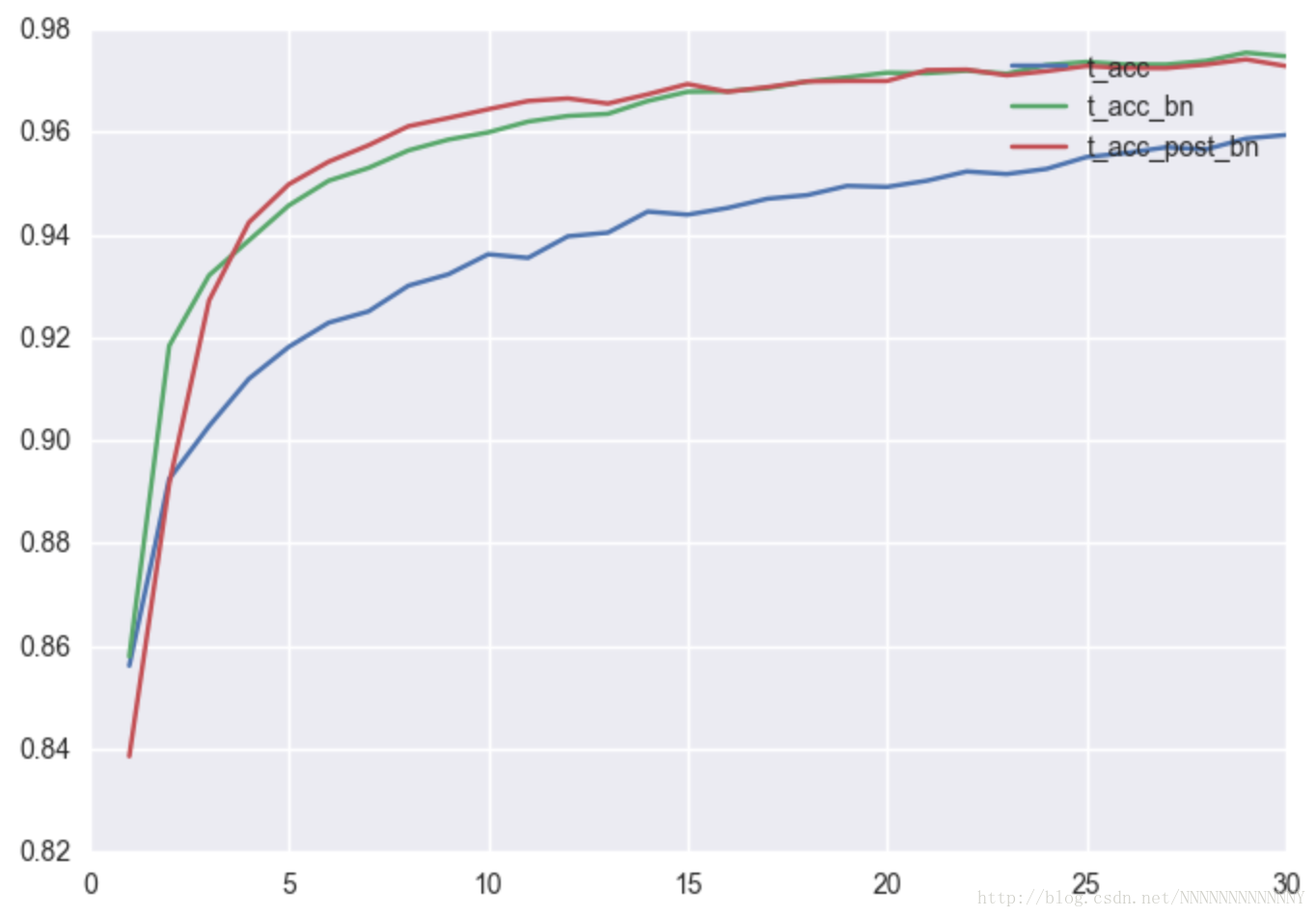
这里我对其Standard batch normalization进行了简单的修改,贴于此:
import numpy as np
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# define our typical fully-connected + batch normalization + nonlinearity set-up
def dense(x, size, scope):
return tf.contrib.layers.fully_connected(x, size,
activation_fn=None,
scope=scope)
def dense_batch_relu(x, phase, scope):
with tf.variable_scope(scope):
h1 = tf.contrib.layers.fully_connected(x, 100,
activation_fn=None,
scope='dense')
h2 = tf.contrib.layers.batch_norm(h1,
center=True, scale=True,
is_training=phase,
scope='bn')
return tf.nn.relu(h2, 'relu')
tf.reset_default_graph()
x = tf.placeholder('float32', (None, 784), name='x')
y = tf.placeholder('float32', (None, 10), name='y')
phase = tf.placeholder(tf.bool, name='phase')
h1 = dense_batch_relu(x, phase,'layer1')
h2 = dense_batch_relu(h1, phase, 'layer2')
logits = dense(h2, 10, 'logits')
with tf.name_scope('accuracy'):
accuracy = tf.reduce_mean(tf.cast(
tf.equal(tf.argmax(y, 1), tf.argmax(logits, 1)),
'float32'))
with tf.name_scope('loss'):
loss = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y))
def train(mnist):
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
# Ensures that we execute the update_ops before performing the train_step
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(loss)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
history = []
iterep = 500
for i in range(iterep * 30):
x_train, y_train = mnist.train.next_batch(100)
sess.run(train_step,
feed_dict={'x:0': x_train,
'y:0': y_train,
'phase:0': 1})
if (i + 1) % iterep == 0:
epoch = (i + 1)/iterep
tr = sess.run([loss, accuracy],
feed_dict={'x:0': mnist.train.images,
'y:0': mnist.train.labels,
'phase:0': 1})
t = sess.run([loss, accuracy],
feed_dict={'x:0': mnist.test.images,
'y:0': mnist.test.labels,
'phase:0': 0})
history += [[epoch] + tr + t]
print(history[-1])
return history
def main(argv=None):
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
train(mnist)
if __name__ == '__main__':
tf.app.run()
参考:
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
深度学习中 Batch Normalization为什么效果好?
Why does batch normalization help?
深度学习(二十九)Batch Normalization 学习笔记
论文笔记-Batch Normalization
《Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift》阅读笔记与实现
Implementing Batch Normalization in Tensorflow
A GENTLE GUIDE TO USING BATCH NORMALIZATION IN TENSORFLOW