基础知识掌握情况决定研究的高度,我们刚开始接触深度学习时,一般都是看到别人的概括,这个方法很好能让我们快速上手,但是也有一个很大的缺点, 知识理解的不透彻,导致我们对算法优化时一头雾水。我也是抱着知识总结的思想开始自己的深度学习知识精髓的探索,也希望能从中帮助到更多人。文章中间存在表述不清的地方希望各位研友(研究深度学习的朋友)提出,我会努力完善自己的文章。
一、BN算法产生的背景
做深度学习大家应该都知道,我们在数据处理部分,我们为了加速训练首先会对数据进行处理的。其中我们最常用的是零均值和PCA(白话)。首先我们进行简单介绍零均值带来的只管效果:
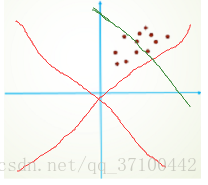
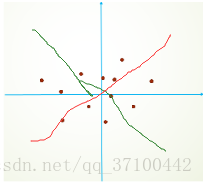
简单的划了一个草图。第一张图我们进行分析。由于我们对网络进行参数初始化,我们一般是采用零均值化。我们初始的拟合直线也就是红色部分。另外的一条绿色直线,是我们的目标直线。从图能够直观看出,我们应该需要多次迭代才能得到我们的需要的目标直线。我们再看第二张图,假设我们还是和第一张图有相同的分布,只是我们做了减均值,让数据均值为零。能够直观的发现可能只进行简单的微调就能够实现拟合(理想)。大大提高了我们的训练速度。因此,在训练开始前,对数据进行零均值是一个必要的操作。但是,随着网络层次加深参数对分布的影响不定。导致网络每层间以及不同迭代的相同相同层的输入分布发生改变,导致网络需要重新适应新的分布,迫使我们降低学习率降低影响。在这个背景下BN算法开始出现。 有些人首先提出在每层增加PCA白化(先对数据进行去相关然后再进行归一化),这样基本满足了数据的0均值、单位方差、弱相关性。但是这样是不可取的,因为在白化过程中会计算协方差矩阵、求逆等操作,计算量会很大,另外,在反向传播时,白化的操作不一定可微。因此,在此背景下BN算法开始出现。
二、BN算法的实现和优点
1、BN算法的产生
上面提到了PCA白化优点,能够去相关和数据均值,标准值归一化等优点。但是当数据量比较大的情况下去相关的话需要大量的计算,因此有些人提出了只对数据进行均值和标准差归一化。叫做近似白化预处理。
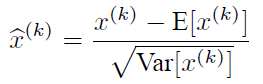
由于训练过程采用了batch随机梯度下降,因此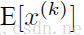
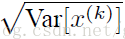
但是,这些应用到深度学习网络还远远不够,因为可能由于这种的强制转化导致数据的分布发生破话。因此需要对公式的鲁棒性进行优化,就有人提出了变换重构的概念。就是在基础公式的基础之上加上了两个参数γ、β。这样在训练过程中就可以学习这两个参数,采用适合自己网络的BN公式。公式如下:
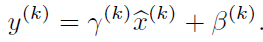
每一个神经元都会有一对这样的参数γ、β。这样其实当: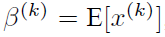
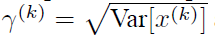
时,是可以恢复出原始的某一层所学到的特征的。引入可学习重构参数γ、β,让网络可以学习恢复出原始网络所要学习的特征分布。
总结上面我们会得到BN的向前传导公式:

2、BN算法在网络中的作用
BN算法像卷积层,池化层、激活层一样也输入一层。BN层添加在激活函数前,对输入激活函数的输入进行归一化。这样解决了输入数据发生偏移和增大的影响。
优点:
1、加快训练速度,能够增大学习率,及时小的学习率也能够有快速的学习速率;
2、不用理会拟合中的droupout、L2 正则化项的参数选择,采用BN算法可以省去这两项或者只需要小的L2正则化约束。原因,BN算法后,参数进行了归一化,原本经过激活函数没有太大影响的神经元,分布变得明显,经过一个激活函数以后,神经元会自动削弱或者去除一些神经元,就不用再对其进行dropout。另外就是L2正则化,由于每次训练都进行了归一化,就很少发生由于数据分布不同导致的参数变动过大,带来的参数不断增大。
3、 可以吧训练数据集打乱,防止训练发生偏移。
使用: 在卷积中,会出现每层卷积层中有(L)多个特征图。AxAxL特征矩阵。我们只需要以每个特征图为单元求取一对γ、β。
然后在对特征图进行神经元的归一化。