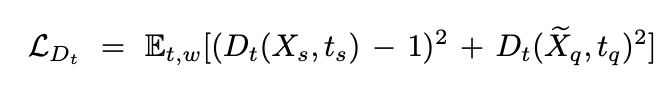文章目录
作者:Dongchan Min
单位:KAIST
会议:2021 ICML
abstract
拟解决的问题:目标说话人很少的数据完成语音合成的任务
方法:
- 提出Style-Adaptive Layer Normalization(SALN),从ref-audio的一句话中提取风格;
- 引入两个style prototypes训练的判别器将此引申为meta-style speech,以提升对新的说话人的风格适应能力。
1. introduction
现有的小数据TTS任务的方法及问题:
- base model + 小数据自适应,需要自适应的过程;
- 额外的编码器获得latent embedding without adaptation,高度依赖原始数据集中说话人的区分度,如果区分度不高的话,新的话说人性能就比较差;
Meta learning,也叫learning to learn,是强化学习的分支,主要用于few-shot 判别,也有用于few-shot生成。关于生成任务,之前在图像上有成功的应用(人脸生成),TTS上还没有。
贡献点:
- 提出StyleSpeech,可以从单句短的ref-audio中解耦风格信息,完成到新说话人的TTS;
- 将StyleSpeech扩展到Meta-StyleSpeech,使用style prototypes and an episodic meta-learning algorithm
分别训练基于phn和style的判别器,可以更好的适应unseen speaker;
3. StyleSpeech
3.1. Mel Style Encoder
输入ref-mel,编码说话人身份和韵律,网络结构:
- Spectral processing::全连接,将mel-spec编码成mel-embedding
- Temporal processing::gated CNNs,建模全局特征
- Multi-head self-attention
3.2. Generator
采用FastSpeech的结构,具体包括
- phn encoder:phn级别的编码
- variance adaptor:预测每个phn的时长,以及phn级别的pitch/energy信息;然后按照时长展开到frame-level;
- mel-spec decoder:生成mel谱。
为了完成多人TTS,不是把style embedding直接拼接在encoder output,提出一种新的方法:SALN。 - Style-Adaptive Layer Norm用于替换FastSpeech中的layer norm
给定输入 h h h,均值方差归一化成 y y y
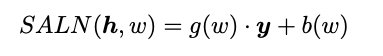
g ( w ) g(w) g(w)是gain, b ( w ) b(w) b(w):bias,根据给定的style vector w w w对引向量进行缩放和平移;是对 w w w过全连接之后得到的;
因此生成器可以根据给定的ref audio生成各种各样的多说话人语音。
Training
the generator and the mel-style encoder 都是用mel重建L1 loss优化
4. Meta-Style Speech
通过SALN,StyleSpeech可以完成多说话人TTS。但是对于unseen speaker时,泛化性仍然受到挑战。
提出meta-learning,使用episodic training(是meta-learning常用的训练手段)。
在每个训练episode中,选择一个support sample( X s , t s X_s, t_s Xs,ts),一个来自目标说话人的query text( t q t_q tq
目的是生成 t q t_q tq和风格 w s w_s ws对应的speech X q X_q Xq。
但问题是但是没有对应的target用于重建loss计算,为此引入判别器—风格判别器和phn判别器。
style discriminator Ds
判别生成的语音是否和目标说话人音色一致;从K个说话人中提取每个人的speaker embedding(style prototype 风格原型),在给定 w s w_s ws的前提下,风格原型 s i s_i si (第i个人的说话人特征表示)的计算方式:
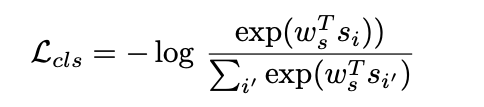
然后从生成的语音中再次提取特征 h ( X q ) h(X_q) h(Xq),和 s i s_i si 计算scalar,希望距离尽可能近。
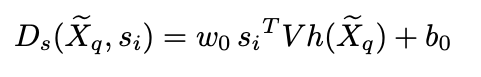
phoneme discriminator Dt
输入是 X q X_q Xq和 t q t_q tq,frame-level的进行计算,因为知道phn的时长,可以将帧级别的mel与对应的phn拼接;计算每一帧的scalar,求平均。
Dt的最终loss