文章目录
召回
- 定义:“推荐”其实就是没有检索词输入时的搜索,推荐系统的召回就是要根据用户画像、内容画像等各种信息,为用户提供他感兴趣的相关内容。
- 召回策略:
- 基于内容的召回:将用户画像和内容画像进行匹配,比如用户画像是“杨幂的粉丝”,可以给他推荐杨幂主演的电影;
- 基于知识匹配(升级版):喜欢绣春刀1,根据知识图谱,推荐绣春刀2
- 评价:召回率高,但准确率较低(标签匹配不一定表明用户感兴趣),推荐的内容比较单一,适合冷启动场景;
第2章 前深度学习时代–推荐系统的经典算法
协同过滤 (collaborative filtering CF)
- 定义:目前业内常用
- 分类:
- 基于用户的协同推荐(userCF):相似的人会有相同的喜好
- 用户相似度计算:余弦相似度、皮尔逊相关系数, etc; 理论上任何合理的相似度计算方法都可以使用(比如考虑不同用户、不同物品的权重)
- 最终结果排序:拿到和当前用户最为相似的top n用户以后,对于某个特定的商品,对top n用户的喜好进行综合评价,进而预测当前用户对该物品的喜好;
- 问题:(1)需要维护用户相似度矩阵以计算出top n用户,而随着用户数大量增长,用户矩阵n^2增长,消耗大量的存储和计算资源;(2)对于历史信息很少的用户,比较难计算到他的相似用户;
- 适用场景:社交属性明确;适用于新闻热点推荐;
- 基于项目的协同推荐(itemCF):喜欢一个物品的用户会喜欢相似的物品,过往的相似记录信息给当前用户推荐
- 计算过程:
- 构建用户m物品n的共现矩阵;计算共现矩阵中两两列向量的相似性,构建物品nn的物品相似度矩阵;获得用户历史行为数据的正反馈物品列表;找出相似物集合top k;相似物集合中的物品进行打分排序,生成最终的推荐列表;
- 适用场景:兴趣变化比较稳定的场景,电商购物,兴趣视频推荐;
- 计算过程:
- 基于模型的协同过滤(model-based):基于样本的用户喜好信息,训练一个推荐模型,然后根据实时的用户喜好的信息进行预测推荐。
- 评价:实际运用中,采用单一召回策略的推荐结果实际会非常粗糙,通用的解决方法是将规则打散,将上述几种召回方式中提炼到的各种细小特征赋予权重,分别打分,并计算总分值,预测CTR(click through rate, 广告系统的推荐点击率)。
- 协同过滤的缺点:头部效应比较明显(热门商品容易被推荐给更多的人),尾部商品由于特征稀疏,很少被推荐。
- 基于用户的协同推荐(userCF):相似的人会有相同的喜好
矩阵分解算法
- 定位:解决协同过滤头部效应的问题
- 步骤:
- 把CF的“共现矩阵” 进行分解,用户m物品n的矩阵被拆分成用户矩阵U(mk)和物品矩阵(kn);计算用户u对于物品i的预估评分;得到一个空间隐向量表示(kk),则空间中相邻的向量对应用户喜欢的物品生成推荐列表;
- 根据真实场景和业务,会加入更多的bias,因而改变了目标函数;
- k值:k是需要反复计算,找到推荐准确度和工程开销的折衷点;k值越大,隐向量表征能力越强,但模型的泛化能力减弱;而且k取值大小和矩阵分解的求解复杂度正相关;
- 矩阵分解算法:
- 特征值分解:只能用于方阵,不适合用户*物品的场景;
- 奇异值分解:要求共现矩阵稠密,而互联网场景下用户-物品的矩阵非常稀疏;计算复杂度O(mn^2),不适合海量商品的场景
- 梯度下降
- 目标函数:U*I逼近原始共现矩阵
- 正则化:避免模型过拟合,减少波动;在模型损失函数的基础上+ lambda*W—模型权重越大,损失函数越大,不是模型的收敛方向,因此良好的收敛方向是 损失函数变小(拟合数据集)+模型权重比较小(输出波动比较小),从而让模型更稳定。
- 梯度下降求得用户矩阵U和物品矩阵I,对某个用户进行推荐时,将该用户的隐向量与所有物品的隐向量求积,得到该用户对所有物品的打分,然后排序得到最终的列表。
- 优点:
- 更强的泛化性:隐向量是用共现矩阵的全局信息生成的;对于协同过滤而言,如果两个人没有相同的历史行为,或者两个物品没有相同的人购买,那么计算的人和物品的相似度都是0;而矩阵分解可以将人对所有物品计算相关度(还是更好的泛化全局信息);
- 空间复杂度低:只需要存储用户和空间隐向量,复杂度由n^2降低为(n+m)*k
- 更好的扩展性和灵活性:矩阵分解产生了用户隐向量和物品隐向量,便于与其他特征进行拼接组合;
- 缺点:
- 不方便加入用户、物品、上下文特征;(CF也是)
- 缺乏用户历史行为;
逻辑回归LR
- 定位:能够综合用户、物品、上下文等多种特征;将推荐问题转换为分类问题;
- 步骤:
- 用户的年龄、性别、物品属性、描述等转化成特征向量;
- 确定模型的优化目标,比如“点击率”,(CTR, click throgh rate);
- 训练模型,在infer阶段输入特征向量,预测用户对某种物品点击的概率;
- 根据点击概率对候选物品排序,得到推荐列表;
- 优点:
- 数学含义明确:用户是否点击是一个伯努利分布,而逻辑回归符合CTR模型的假设;
- 可解释强:加权+sigmoid
- 工程化简单:易于并行,模型简单,训练开销小;
- 缺点:表达能力不强,无法进行特征交叉、特征筛选等高级操作,因此会造成特征的浪费;
自动特征交叉
POLY
-
定义:对所有特征进行两两交叉,并赋予权重;
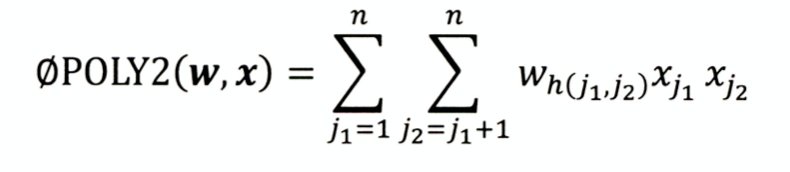
-
缺点:onehot编码的特征本身很稀疏,特征交叉后矩阵更加稀疏,难以训练收敛;权重参数n—n^2,复杂度大大增加;
-
W个数= n*(n-1)/2 ~n^2
FM模型(Factorization Machines,因式分解机)
- 用两个向量内积代替单一权重参数
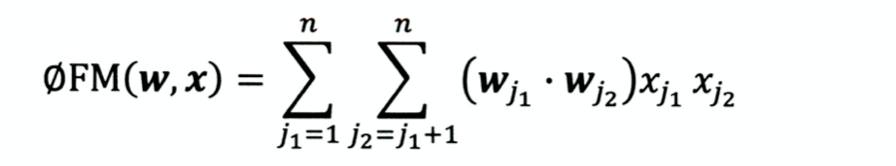
- 权重个数 W=n*k(k是隐向量维度),类似于将共现矩阵分解为说话人矩阵和物品矩阵;
- 优点:更好的解决了矩阵稀疏的问题;泛化能力大大提高;丢失了部分具体特征组合的表示能力;
FFM模型(Field-aware Factorization Machines)
- 定义:引入域(field)的概念,模型的表达能力更强;
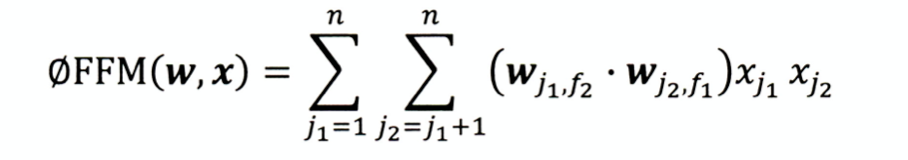

- 复杂度 k n 2 kn^2 kn2




- 由于组合爆炸的问题,三阶FM无论在权重数量和训练复杂度上都非常大,工程难以实现
组合模型
- 定义:解决FM/FFM只能做二阶特征交叉的痛点;
GBDT ----- 特征工程化
- GBDT(Gradient Boosting Decision Tree)梯度提升决策树
- 定义:基本结构是决策树组成的森林,学习方式是梯度提升
- 步骤:
- 利用GBDT进行特征筛选和组合,进而生成新的离散特征;
- 一个样本输入决策树,每个子树最终只会有一个叶子节点置为1,其他都是0;所有子树的特征向量拼接形成后续使用的离散特征向量;
- 特征向量当作LR模型输入,预估CTR

- 利用GBDT进行特征筛选和组合,进而生成新的离散特征;
- 决策树的深度决定了特征交叉的阶数,比如决策树深度为4,则经过三次节点分裂,实际对应三阶特征融合;
- 缺点: 容易过拟合,这种处理方式丢失了大量的特征数值信息,因此交叉能力强不代表着效果好;
- 优点: 特征工程完全交给模型完成,实现真正的end-to-end;是现在embedding层方法的起源;
- 之前的方法:
- 人工/半人工的特征组合和筛选:人力要求高;
- 改进模型结构+增加特征交叉项:模型设计能力门槛;
LS-PLM (Large scale piece-wise linear model)大规模分段线性模型 阿里
-
又叫MLR(mixed logistic regression,混合逻辑回归)
-
做法:先用pai函数对样本进行聚类,再对每个分类进行逻辑回归预测CTR,然后将两者相乘后求和
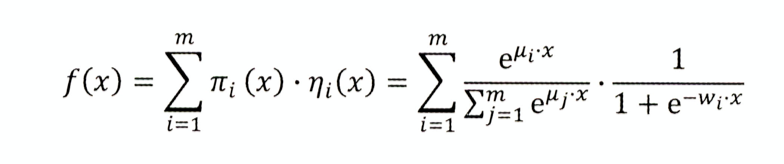
-
分类数m: m=1,退化为基本的LR模型;m越大,模型的拟合能力越强,参数规模也线性增长;

-
优点:
- 端到端的非线性学习能力:样本分片的设计挖掘出数据中存在的非线性模式,节省样本处理时间;端到端的训练模式,可以用一个全局模型对不同领域、业务场景统一建模。
- 模型稀疏能力强:引入L1/L2范数进行稀疏化,使得模型具有较高的稀疏度,模型部署更加轻量级,推断效率也更高;
L1范数比L2范数更容易产生稀疏解
- 损失函数
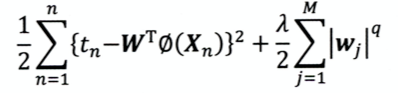
- 令loss=0,绘制曲线

第3章 深度学习在推荐系统的应用
autorec结构
- 2015年 澳大利亚国立大学提出

- 三层结构:输入层,隐层,输出层;
- 目标函数

- 也分为基于用户的(U-based autorec)和基于物品的(I-based autorec);其中U-based autorec的优势在于只需要输入一次用户对物品的打分,缺点是用户向量的稀疏性会影响模型效果;
DeepCrossing模型
- 微软bing搜索广告场景的应用:用户在搜索关键词时,在返回搜索结果的同时会返回一些搜索词相关的广告;目的是增加用户对广告的点击率;
- 要解决的问题:
- 解决稀疏特征向量稠密化的问题–onehot转成emb;
- 特征自动交叉—交给神经网络自动完成,不是FM/FFM的二阶交叉,而是神经网络完成的深度交叉;(首次引入resnet结构)
- 输出层完成设定目标
- 模型结构

NeuralCF
- 2017年新加坡国立大学提出
- 核心思想:用神经网络模拟将共现矩阵分解为用户矩阵和物品矩阵的过程;最终的得分相当于将分解得到的用户矩阵和物品矩阵再次相乘;
- 模型结构:因为传统的矩阵分解分解模型过于简单,使得最终模型也处于欠拟合的状态;为了模型具有更好的表现力,多层NN代替简单矩阵分解后求内积的步骤。NN将用户向量矩阵和物品向量矩阵多次随意互操作的过程,称为“广义矩阵分解”模型。

softmax与交叉熵
- softmax多分类目标函数:各个类别概率求和=1;凸显最大值,并远远抑制较小值;
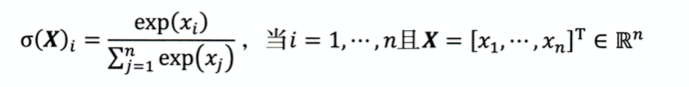
- 交叉熵:主要用于度量两个概率分布间的差异性信息 ;



优点:特征自动深层次交叉;网络灵活,便于修改;
缺点:基于协同过滤的思想,因此没有引入其他类型的特征,会浪费部分信息。互操作的种类解释性不强。
PNN模型—加强特征交互的能力
- 2016年上海交大提出, product-based
- 思想:任何向量的交互计算都可以代替协同过滤的内积操作---------广义矩阵分解模型;
- 模型结构:将deepcross的拼接层换成了乘积层;

- 外积会将计算复杂度上升到 M 2 M^2 M2,为了减少模型计算量,使用叠加矩阵的操作降维。叠加矩阵类似于一个平均池化层,在实际应用中,平均池化层更适合作用同类型embedding上,对不同类型embedding做平均池化,会模糊掉很多有效信息,因此操作需要谨慎。
- 优点:相比于deep cross无差别的拼接后过全连接层,PNN模型的内积和外积操作更有助于不同特征的交互,更有利于建模特征的交叉信息。
- 缺点:对所有特征无差别的交叉,会在一定程度忽略原始数据的有效信息,并且计算量也比较大;
Wide&Deep模型
- 2016 谷歌提出,应用于谷歌应用商店,单层wide(记忆能力)+多层deep(泛化能力)
- 模型的记忆能力:是指直接学习并利用原始数据中物品或者特征“共现频率”的能力。协同过滤、逻辑回归等简单模型具有较强的记忆能力(共现频率对应的权重会比较大),但是神经网络因为多层网络&处理了很多交叉特征,对于部分强特征的记忆反而没有那么深刻。
- 模型的泛化能力:模型发掘稀疏甚至从未出现过的稀有特征与最终标签相关性的能力。矩阵分解比协同过滤的泛化更好,因为矩阵分解引入隐向量,是的数据稀少的用户或物品也能生成隐向量,将全局数据传递到稀疏物品上。
- 模型结构


- 评价:是基于对业务的深层理解作出的改进,融合了传统模型的记忆能力和深度学习模型的泛化能力;模型并不复杂,易于工程实现、训练上线。
Wide&Deep模型的进化 ---- Deep&Cross模型(DCN)
- 2017 谷歌&斯坦福提出,核心思想是用cross网络代替原来的wide部分 (PNN模型思想的引入,两两向量交叉)
- 模型结构:

- cross子网络部分


FM与深度学习模型的融合
- 思想:神经网络引入做特征交叉
- FM 模型结构

DeepFM —用FM代替wide部分
- 2017 哈工大&华为提出
- 模型结构:

NFM ----FM的神经网络化
- 2017 新加坡国立
- 核心思想:用神经网络代替原来的二阶FM,使得可以实现更强的表达能力;


注意力机制在推荐模型的应用
- 2017年浙大 提出的AFM & 阿里巴巴提出的DIN
- 思想:更多的模型层面的尝试,FM的特征交叉是无差别的交叉,消解了大量有效的信息;attention可以关注到不同交叉特征对于结果不同程度的影响
AFM模型


DIN—Deep Interest Network
- 阿里巴巴电商广告推荐场景,attention在实际业务场景的成功尝试 (author :周国睿)
- 模型结构

DIEN—Deep Interest Evolution Network
- 2019年阿里巴巴,(author:周国睿)
- 核心思想:用户的兴趣是时间相关的,将序列建模的思想引入到推荐系统
- 模型结构

- 兴趣抽取层实际上已经可以预测下一个兴趣状态向量;
- 兴趣进化层的意义:在模拟兴趣进化的过程中,考虑与目标广告的相关性;在电商推荐场景,用户可能会同时购买多件商品,比如同时在看机械键盘和衣服(两个类别),如果广告目标是电子商品,那么机械键盘的兴趣演化路径会比衣服的兴趣路径重要(attention会根据广告目标类别对用户兴趣进行筛选,某种程度上会引导用户兴趣,促进成交)。
- 评价:序列化建模的训练复杂度比较高,线上串行推断,延迟比较大,工程化难度也会比较大。
强化学习和推荐系统的结合
-
2018年宾夕法尼亚州立大学 & 微软提出的
-
强化学习的思想:行动–反馈–系统更新;
-
评价: 优点在于可以在线学习,根据用户反馈及时调整;
-
步骤

DRN—Deep Reinforcement Learning Framework
- author :Guanjie Zheng, 上交大
- 关键步骤:

- 微更新的具体操作

第4章 embedding在推荐系统的应用
- embedding在空间的位置,embedding之间的距离都有通用的表示含义;
- 优势:
- 稀疏特征向量稠密化;
- 可以对任何信息进行编码;
- 可用于粗排,快速对海量物品进行初筛;embedding对物品,用户相似度的计算是推荐系统常用的召回技术。
word2vec
- 2013年谷歌提出
- 相关讲解

- CBOW比Skip-gram训练速度快,训练过程更加稳定,原因是CBOW使用上下文average的方式进行训练,每个训练step会见到更多样本。而在生僻字(出现频率低的字)处理上,skip-gram比CBOW效果更好,原因是skip-gram不会刻意回避生僻字。
- 负样本采样 :将多分类问题简化为一个近似二分类问题, 简化计算复杂度
- skip gram:输入一个词,embedding编码后解码预测一个embedding,与四个位置求综合loss最小;
L = l o g ( W 1 , W 2 , W 4 , W 5 ∣ W 3 ) L=log(W_1,W_2,W_4,W_5|W_3) L=log(W1,W2,W4,W5∣W3)
Item2Vec
- 2016年微软提出
- 定义:物品序列是由特定用户的浏览、购买记录等行为产生的历史记录序列;没有时间窗口,认为任意两个物品都相关;
广义的Item2Vec ----双塔模型
-
定义:任何可以生成物品向量的方法都可以被称为Item2Vec,典型的比如百度、facebook的双塔模型,和前边讲的阿里的电商广告类似。

-
优点:任何序列数据都可以生成embedding向量;扩大了word2vec的应用场景;
-
缺点:只能利用序列化数据,对于海量的网络化数据则需要gragh2vec的方法。
Graph Embedding
DeepWalk

- graph embedding和序列embedding的过渡;有向图随机跳转生成序列表示,然后输入word2vec模型生成embedding;
- 注意:有向图,有跳转权重;
Node2Vec —同质性和结构性的权衡
- 同质性:相邻节点的embedding尽量相似,比如同一类商品;
- 结构性:结构上相似的节点embedding尽量相似,比如都是各自局域网络的中心节点;对应各个品类的爆款商品;

跳转概率
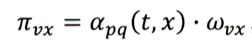

其中 w v x w_{vx} wvx是边vc的权重; a p q ( t , x ) a_{pq}(t,x) apq(t,x)是设定的值, p p p是返回参数,p越小,游走回节点t的概率越大,Node2Vec更注重结构性; q q q是进出参数,q越小,游走到远方节点的可能性越大,更注重网络的同质性;
EGES:Enhanced Graph Embedding with Side Information
- 2018年阿里巴巴
- 目的:DeepWalk的升级版,deepwalk在遇到新商品加入,或者与其他商品很少互动的“长尾”商品时,就会遇到推荐系统的冷启动问题。EGES通过更多的补充信息(side information)来丰富embedding的来源。

- 实际应用中采用的是 e a j e^{a_j} eaj,而不是 a j {a_j} aj,是为了避免权重为0,且 e a j e^{a_j} eaj有利于梯度传导。
embedding与深度学习推荐系统的结合
embedding的应用:
- 高维稀疏向量到低维稠密特征向量的转换:输入和全连接层之间加入embedding层;
- embedding层的参数量非常大,会大大拖累网络的训练速度,因此一般使用预训练的embedding;
- 实际上embedding的更新频率不需要很高(因为用户的兴趣、物品的属性不可能在几天内发生巨变),而上层神经网络需要尽快抓住最新数据的趋势,需要高频训练甚至实时训练。
- 作为预训练的embedding,与其他特征向量一起作为神经网络的输入特征;
- 直接作为推荐系统的召回层或者召回策略之一,用于计算物品或者用户的相似度。
- embedding本身强的表达能力, 不需要部署整个模型,直接通过embedding内积运算+排序的方式得到输出物品排序,取序列top N作为召回的候选集合。
局部敏感哈希
- embedding作为召回策略,则计算一个用户的top N召回物品序列,需要的计算量非常大;实际上这个问题是在高维embedding空间寻找最近邻值,针对提出局部敏感哈希(locality sensitity Hashing, LSH) 的算法。
- 先验知识:在高维空间中距离相近的点,压缩到低维空间后距离仍然相近。但是原本距离远的点,也有一定概率变成相近的点。
- LSH核心思想:构建“桶”的概念,让距离相近的点落入一个桶中,这样在搜索时只需要搜索一个桶或者相邻桶即可。
- 具体做法

- 多桶策略:前边说了高维到低维的映射存在一定偏差,因此一般会采用m个哈希函数同时进行分桶,这样在不同的哈希函数中同一个桶中的两点,其在高维空间相近的概率大大增加。这里会根据最终准确率和召回率的折衷,决定到底使用几个哈希函数,以及 采用“与策略”/“或策略”。
- “与策略”:点A和点B同时在哈希函数1/2的同一个桶中,这时A/B是近邻点的准确率提高,但是会漏掉一些近邻点(比如分桶边界的点)。
- “或策略”:点A和点B在哈希函数1或者哈希函数2的同一个桶中,生成候选集,近邻点的召回率提高,但是候选集变大,计算开销大。
- 除了常用的欧式距离计算以外,还有余弦相似度、曼哈顿距离等,因而对应的局部敏感哈希用法有所不同,但是核心思想是一致的。
第5章 多角度审视推荐系统
特征工程
- 因为推荐系统的特征非常多,避免garbage in garbage out,对特征处理的时候,要尽量保留有效信息(避免有效信息的过滤)同时摈弃冗余信息
- 用户的行为数据可以分为显式的和隐式的。处理方式:(1)代表用户行为的物品id转换成multi-hot向量(每个特征对应一维,可能会同时点亮多维);(2)预训练好物品的embedding,通过平均或者类似DIN模型的方法生成历史行为embedding表示。
- 用户关系数据人与人的关系也分为强关系(好友/关注)和弱关系(喜欢同一类物品,关注同一个主播)。
- 属性、标签类数据包括用户的和物品的
- 内容类数据属性标签的延伸
- 上下文信息尽可能的保存推荐行为发生的时间地点等场景信息,比如发现用户喜欢早上看新闻,晚上看轻松的电影;
- 统计类特征统计方法计算得到的,比如历史CTR, 历史CVR(conversion rate),一般是连续性的特征;
- 组合类特征比如性别+年龄组合成新特征,可以是人工组合,也可以交给模型组合。
- 特征数据可以分成连续型和离散型两大类。
- 其中年龄、统计类特征等属于连续型特征(原有数值连续),一般会对他们进行归一化、离散化、加非线性函数等方式处理。
- 离散型特征:可以用one-hot/multi-hot(同一特征域的非唯一类别选择)表示;还有embedding的方法。
召回层的主要策略
- 推荐系统主要分为两个阶段:召回阶段和排序阶段。

- 召回阶段考虑的是计算速度 & 召回率的折中。
多路召回策略
- 方法:多种简单的召回策略分别召回一些候选集,然后混合在一起供后续排序模型使用。
- 召回策略的选择与业务强相关,各个策略拉回的候选集中样本数量K是一个超参数,需要经过离线评估 & A/B测试确定合理的取值范围。
- 缺点:从策略的选择到候选集的大小都需要人工参与,且各个策略彼此割裂,无法衡量多个策略对一个物品的影响。
基于embedding的召回
- 方法:实际在在用的时候是生成embedding,然后局部敏感哈希计算embedding的距离;这时候会多路召回策略作为附加信息(side information)。
- 多路召回中不同召回策略的结果不具有可比性,因此无法确定每个召回策略候选集的大小,而embedding的召回都可以通过计算向量之间的相似度,因此可以随意设定召回候选集的大小。
推荐系统的实时性
- 意义:(1)推荐系统更新的越快,说明最近用户兴趣更新的越快,越能为用户进行有效推荐;(2)推荐系统更新的越快,模型越容易捕捉最新流行的数据模式,进行流行推荐。
- 客户端的实时特征:用户端(客户端)和服务器端一个session的交互时间(假设3min),由于延迟问题,可能无法把一个session内的用户行为传给服务器,这样就会造成推荐系统无法针对性实时更新。希望客户端能够缓存session信息,和上下文特征一起送给服务器。
- 流计算平台的准实时特征处理:流计算平台(比如storm、spark streaming、flink)将收到的日志以流的形式仅凭小批量微处理,然后立刻缓存到特征数据库,供推荐模型使用,虽然不是绝对的实时更新,但是延迟在分钟级别。
- 分布式批处理平台的全量特征处理:有时候用户的各种数据,比如曝光、点击、转化是互相相关,但是会在不同的时间段到达服务器(有的间隔甚至小时级别,HDFS hadoop分布式文件系统)。因此使用分布式批处理平台,在全量数据特征准备好以后,再进行后续操作,无法保证推荐实时更新,但是兼顾了推荐系统特征的全面性,为了用户下次登陆更准确的推荐。
- 推荐系统模型的实时性

- 全量更新:部分时期的数据对模型进行更新;实时性较差;
- 增量更新:较短时期内收集到的特征对模型进行更新; 实时性好,但是容易陷入局部最优而错过全局最优;一般会在几轮增量更新以后,选择业务量较小的窗口进行全量更新;
- 在线学习:获得一个新的样本即更新模型。工程化要求比较高,但是容易导致模型的稀疏性不好(大量小权重),增大模型体积,增大部署难度。有关于兼顾在线学习模型效果&稀疏性的研究(FOBOS、FTBL)。还有方法:强化学习的竞争梯度下降用于在线学习。
- 局部更新:降低训练效率低的部分的更新频率,提高训练效率高的部分的更新频率。(比如GBDT+LR模型)。对于基于embedding的模型,embedding层低频更新,以上层高频更新。

不存在推荐系统的银弹解法
- 在推荐系统优化中,比模型调参更重要的是对业务场景的理解后作出的针对性优化。比如DIEN模型在阿里巴巴电商场景取得很好的收益,那是否能够照搬到其他公司业务中?答案当然是否定的,熟悉要明确DIEN建模的问题核心:(1)应用场景存在“兴趣的进化”,(2)用户兴趣进化的过程能够被完整的捕捉建模。那么以长视频推荐系统为例,用户的观看场景可能是跳跃的,比如在youtube上跳到第三方软件,那么用户的行为和兴趣都无法获取,兴趣的进化路径当然也不完整甚至会出错。核心是找到当前业务下推荐系统最短的那块板,木桶理论
冷启动
- 在数据从无到有的过程中,如何有效的推荐,叫做冷启动。分为用户冷启动(新用户)、物品冷启动(新加入的商品)、系统冷启动。
- 解决方法:
- 基于规则的冷启动:热门排行榜是一个常用的方法。在用户注册的时候获取一些比如性别、地域、喜好等信息,寻找对应决策树上的冷启动榜单;或者让用户对物品进行描述(筛选),比如租房的价格、面积、朝向等,聚类定位。
- 丰富冷启动过程可获得的用户和物品特征:除了用户填写的年龄、性别,还可以获得很多其他的信息,比如手机型号推测收入,ip地址获得定位等等。
第7章 推荐系统的评估
离线评估
- holdout检验:分为训练集、验证集,对于pre-trained的模型,在验证集上测试,但是可能会因为抽检样本较少,得到的结论具有随机性。
- 交叉检验:k-fold交叉验证,数据集分成k份,每次取k-1作为训练,轮流都会成为验证集合。
- 自助法:对于n个样本,进行n次有放回的抽样,组成大小为n的训练集,对于没有抽到的样本,作为验证集。
离线评估指标
- 准确率:可解释性强,但是对于数据分布不均衡时,占比较大的类型成为影响准确率的主要因素。
- 精确率(正样本的分类准确率):分类正确的正样本占分类器判别为正样本个数的比例;
- 召回率:分类正确的正样本占所有正样本个数的比例。

直接评估推荐序列的离线指标
- 上一小节讲的评估指标大多是对CTR的预测,而不是一个排序模型。而实际上推荐系统最终输出的结果是一个排序列表。
PR曲线
- 计算PR曲线和坐标轴围成的曲线下面积(AUC, area under curve),面积越大,排序模型性能越好。移动模型的正样本阈值,获得曲线的移动。

ROC曲线
- 定义:the reciever operating characteristic,受试者工作特征曲线

- 截断点:当正样本的阈值设为某个数时,样本中只会有一个被判断为正样本,这个阈值点称为截断点。

平均精确度 mAP
- mean average precision, AP是对精确率的平均, meanAP是对所有用户精确率平均的再平均。
接近线上环境的离线评估方法—replay
- 评判一个模型好坏的方法是其在商业/业务场景的线上A/B测试中表现良好。而线下测试的目的就是为了让测试的结果尽量逼近线上系统。

- 步骤:将线上收集到的数据按照时间进行排序,然后时间上切片(注意在模拟真实线上数据流的时候,要求处理的样本数据不能包含有"未来信息")。
A/B测试与线上评估指标
- 定义:将用户分为A、B两个对照组,一个组使用新的模型,一个组使用老模型,对比结果。
- 由于线上会同时做多种实验的A/B,因此在实验流量分层和分流的时候要考虑
- 层与层之间流量“正交”:实验中每组流量穿越过该层后,会被再次随机打散,均匀的分布在下层实验的每个实验组中;
- 同层之间流量“互斥”:同层之间开展多项A/B测试,要求不同测试之间的流量是不重叠的。

- 线上测试直接关注业务指标(这也是线下测试无法实现的)

快速线上评估方法----interleaving
- 意义:线上A/B会消耗大量的资源,甚至会损伤用户体验,因此需要快速迭代
- 有时候某一个物品的喜好者只占全部用户的小部分,而随机分配A、B组的时候,微小的不平衡可能会对结果造成比较大的影响。
- interleaving:不区分A、B组,直接讲不同的被测试对象同时提供给受测者,最后根据受测者的喜好得出评估结果。但是这时候注意,不能让其中一种被测试对象重复出现,而是注意两种被测试对象交替出现。

灵敏度比较
- 希望interleaving方法可以用更少的用户得到可靠的测试结论。
interleaving结果与A/B测试的相关性
- 两者的测试结果有很强的相关性,说明interleaving方法也可以得到准确的测试结果。
- 但是interleaving方法给用户展示的结果是A/B模型完全混排的结果,无法获得某个算法真实的效果,这时候还要依赖A/B测试。而且工程实现比A/B测试复杂很多。
