引言
计算机擅长处理那些能够通过一系列形式化的数学规则来描述的问题;人工智能的真正挑战在于处理那些对人来说很容易执行、但很难形式化描述的任务,人工智能的一个关键挑战就是如何将这些非形式化的知识传达给计算机。
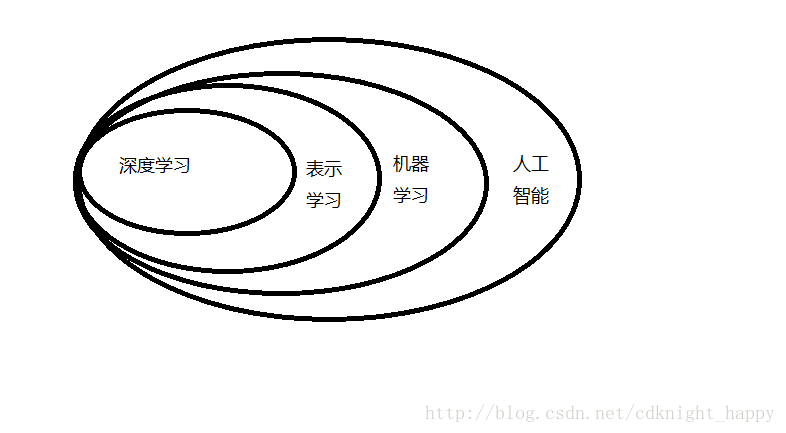
解决方案就是让计算机从经验中学习,并根据层次化的概念体系来理解世界,而每个概念则通过与某些相对简单的概念之间的关系来定义,这种方法即AI深度学习。
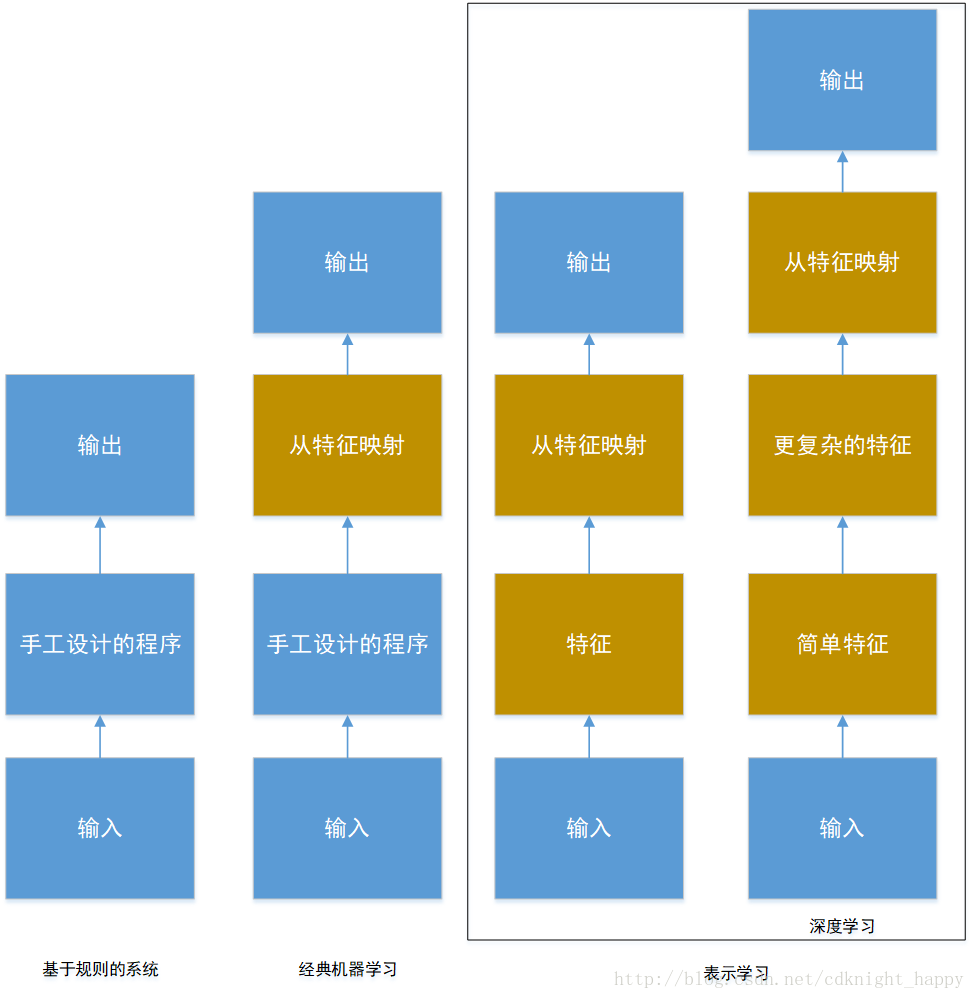
机器学习要输入的数据为原始信息的表示,表示的选择会对机器学习的性能产生巨大的影响;
使用机器学习来发掘表示本身,而不仅仅把表示映射到输出,这种方法称之为表示学习。表示学习学到的特征往往比手动设计的表示表现得更好。
表示学习最典型的的示例是自编码器。
深度学习通过其他较简单的表示来表达复杂表示,解决了表示中的核心问题,让计算机通过较简单的概念来构建复杂的概念。(层次化)
坚信机器学习可以构建出在实际复杂场景下运行的AI系统,并且是唯一可行的方法。深度学习是一种特定类型的机器学习,具有强大的能力和灵活性,它将大千世界表示为嵌套的层次概念体系(由较简单概念间的联系定义复杂概念、从一般抽象概括到高级抽象表示)。
深度学习的历史趋势
深度学习的发展经历了三次浪潮,第一次是20世纪40年代到60年代的控制论,出现了随机梯度下降算法,但是由于线性模型无法解决异或问题导致了神经网络第一次研究热潮的衰退;
第二次研究热潮是20世纪80年代到90年代,表现为联结主义,从人的大脑神经科学中收到了一些粗略的启发,发展出了分布式表示和反向传播算法。但是由于无法训练出比较大型的网络及其他机器学习技术取得的成果,造成了神经网络第二次研究热潮的衰退;
第三次研究热潮自2006年开始,并持续至今,开始着眼于新的无监督学习技术和深度模型在小数据集的泛化能力,但目前更多的兴趣点仍是比较传统的监督学习算法和深度模型充分利用大型标注数据集的能力。
深度学习当然快速的发展取决于大规模的数据集、高性能的计算机和能够训练更深网络的技术进步。
截止2016年,一个粗略的经验法则是,监督深度学习算法在每类给定约5000个标注样本情况下一般讲达到可以接受的性能,当至少有1000万个标注样本的数据集用于训练时,它将达到或超过人类表现。
目前神经网络的神经元数量仍然还是太少,比一个青蛙的神经网络还小。
由于更快的CPU、通用GPU的出现、更快的网络连接和更好的分布式计算的软件基础设施,模型规模随着时间的推移不断增加是深度学习历史中最重要的趋势之一。