定义
- Ripley 的著作《模式识别与神经网络》(Pattern Recognition and Neural Networks)中,训练集、验证集和测试集的定义如下:
训练集:用来学习的样本集,用于分类器参数的拟合。
验证集:用来调整分类器超参数的样本集,如在神经网络中选择隐藏层神经元的数量。
测试集:仅用于对已经训练好的分类器进行性能评估的样本集。
- 详细解释
训练数据集(Training Set):
是一些我们已经知道输入和输出的数据集训练机器去学习,通过拟合去寻找模型的初始参数。例如在神经网络(Neural Networks)中, 我们用训练数据集和反向传播算法(Backpropagation)去每个神经元找到最优的比重(Weights)。
验证数据集(Validation Set):
也是一些我们已经知道输入和输出的数据集,通过让机器学习去优化调整模型的参数,在神经网络中, 我们用验证数据集去寻找最优的网络深度(number of hidden layers),或者决定反向传播算法的停止点;在普通的机器学习中常用的交叉验证(Cross Validation) 就是把训练数据集本身再细分成不同的验证数据集去训练模型。
测试数据集(Test Set):
用户测试模型表现的数据集,根据误差(一般为预测输出与实际输出的不同)来判断一个模型的好坏。
验证集和测试集的区别
-
验证集和测试集的对比
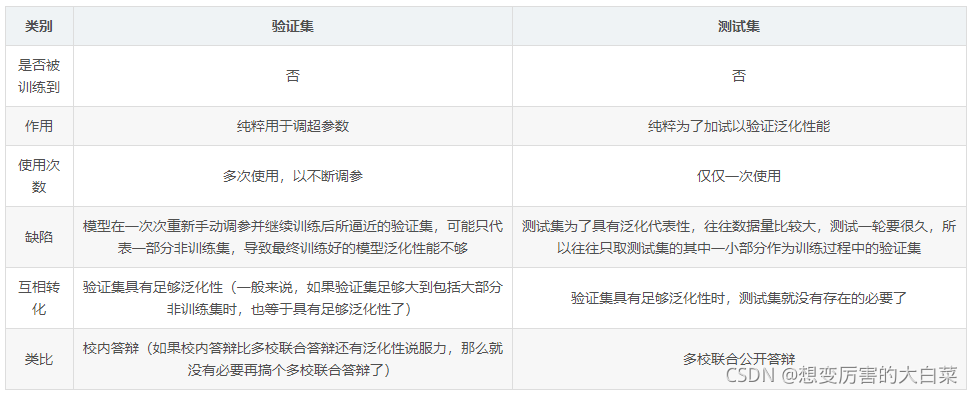
-
验证集的作用:
使用验证集是为了快速调参,也就是用验证集选择超参数(网络层数,网络节点数,迭代次数,学习率这些)。
另外用验证集还可以监控模型是否异常(过拟合啦什么的),然后决定是不是要提前停止训练。
验证集的关键在于选择超参数,我们手动调参是为了让模型在验证集上的表现越来越好,如果把测试集作为验证集,调参去拟合测试集,就有点像作弊了。
而测试集既 不参与参数的学习过程,也不参与参数的选择过程,仅仅用于模型评价。 -
验证集的正确打开方式:
验证集可以看做参与了 “人工调参” 的训练过程。
一般训练几个 epoch 就跑一次验证看看效果(大部分网络自带这个功能)。
这样做的第一个好处是:可以及时发现模型或者参数的问题,比如模型在验证集上发散啦、出现很奇怪的结果啦(Inf)、mAP不增长或者增长很慢啦等等情况,这时可以及时终止训练,重新调参或者调整模型,而不需要等到训练结束。
另一个好处是验证模型的泛化能力,如果在验证集上的效果比训练集上差很多,就该考虑模型是否过拟合了。同时,还可以通过验证集对比不同的模型。扫描二维码关注公众号,回复: 13581089 查看本文章
为什么验证数据集和测试数据集两者都需要?
因为验证数据集(Validation Set)用来调整模型参数从而选择最优模型,模型本身已经同时知道了输入和输出,所以从验证数据集上得出的误差(Error)会有偏差(Bias)。
但是我们只用测试数据集(Test Set) 去评估模型的表现,并不会去调整优化模型。
在传统的机器学习中,这三者一般的比例为training/validation/test = 50/25/25, 但是有些时候如果模型不需要很多调整只要拟合就可时,或者training本身就是training+validation (比如cross validation)时,也可以training/test =7/3.
但是在深度学习中,由于数据量本身很大,而且训练神经网络需要的数据很多,可以把更多的数据分给training,而相应减少validation和test。