Pytorch-YOLOv5
1 Inference
- fork YOLOv5 https://github.com.cnpmjs.org/ultralytics/yolov5.git
- 环境配置好后,使用最小的模型进行inference
python detect.py --source data/images --weights yolov5s.pt --conf 0.25

2 模型结构
2.1 简单网络结构
- 在
models/yolo.py文件中添加代码,运行yolo.py
# Create model
model = Model(opt.cfg).to(device)
torch.save(model, "m.pt") # 保存模型权重文件
# model.train() 原始训练
- YOLOv5直接在命令行打印网络结构了,结果如下
C:\WorkPlace\anaconda3\envs\pytorch\python.exe "C:/Users/Vanessa Ni/Desktop/indus/yolov5/models/yolo.py"
YOLOv5 2021-4-14 torch 1.7.1 CUDA:0 (GeForce MX230, 2048.0MB)
from n params module arguments
0 -1 1 3520 models.common.Focus [3, 32, 3]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 1 156928 models.common.C3 [128, 128, 3]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 1 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 656896 models.common.SPP [512, 512, [5, 9, 13]]
9 -1 1 1182720 models.common.C3 [512, 512, 1, False]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 229245 Detect [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model Summary: 283 layers, 7276605 parameters, 7276605 gradients, 17.1 GFLOPS
Process finished with exit code 0
- 使用netron可视化
直接网页版的就可以,pip install有时候脑抽出问题,怪麻烦的
https://lutzroeder.github.io/netron/

太帅了!!!家人们快用起来。还可以去github链接里下载window.exe版本的,非常好用
2.2 模型详细架构
# Create model
model = Model(opt.cfg).to(device)
x = torch.randn(1, 3, 384, 640).cuda() # 定义输出张量的形状
# 从标准正态分布(均值为0,方差为1,即高斯白噪声)中抽取的一组随机数
script_models = torch.jit.trace(model,x)
script_models.save("m.jit")
- 保存为jit格式的,直接重命名为pt格式,netron就可以支持了
- 模型的一小部分如下
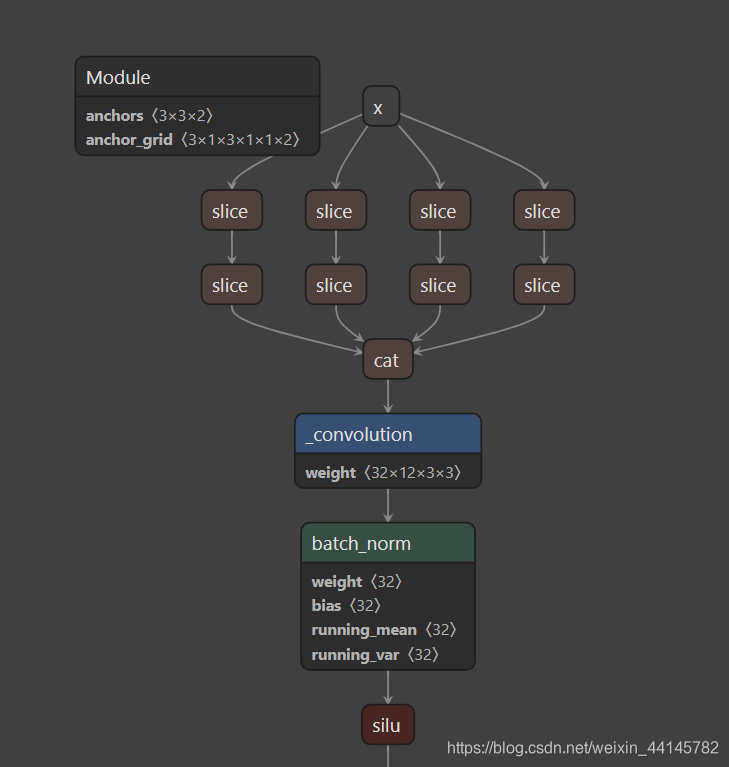
2.3 模型配置文件 yolov5s.yaml
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
-
[-1, 1, Focus, [64, 3]], # 0-P1/2[[-1, 6], 1, Concat, [1]]
① -1代表动态计算上一层的通道数(-2代表计算上两层的通道数),设计的原因是一层一层下来的,但存在残差路由结构;[-1,6]代表把上一层与第六层cat起来。
② [64,3]:网络第一层输出是32个通道(把模型打印出来可以看到),但这里是64,这就与采样率有关:64乘以width_multiple=32,与网络第一层输出一致。
3代表这一层复制3次,3乘以depth_multiple等于1,即1层。最少也要有1层。 -
width_multiple: 0.50这个参数与网络设计有关,现在设计网络一般都不设计一个网络,如yolov3-tiny,yolov3-darknet53,yolov3-spp,但都是单独设计,不太好;如果我们设计几种网络,一般设计常规网络(不大不小),进行训练,效果不错我们再进行缩放,包含深度缩放depth_multiple和宽度缩放width_multiple(通道数),这样的网络被证明效果是不错的,所以可以得到n个网络,减轻了设计负担。
-
缩放规则:r^2βw<2,r(分辨率)β(深度即层数)w(通道数),希望网络的这些参数变大1倍,但计算量小于2。
2.4 网络子结构 models/common.py
这部分我们需要根据 yolov5s.yaml 配置文件查看主干网backbone和侦测网head查看不同的子结构。
Conv与Focus
class Conv(nn.Module): # 自定义卷积块:卷积_BN_激活。类比yolov4里的CBL结构
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
# return self.conv(self.contract(x))
References
- DeepLearing—CV系列(十四)——YOLOv5理论详解+Pytorch源码解析
https://blog.csdn.net/wa1tzy/article/details/106954989