什么是哈希表
哈希表用的是 数组支持按照下标随机访问数据的特性 ,所以哈希表其实就是数组的一种扩展,由数组演化而来。 可以说,如果没有数组,就没有散列表。 哈希表存储的是由键(key)和值(value)组成的数据。 —-知乎
根据设定的哈希函数H(key)和处理冲突的方法将一组关键字影像到一个有限的连续的地址集(区间)上,并以关键字在地址集中的‘像’作为记录在表中的存储位置,这种表就是哈希表。这一个映像的过程就是哈希造表或散列,所得到的存储位置就是哈希地址或散列地址
哈希冲突:所谓哈希冲突,简单来说,指的是 key1 != key2 的情况下,通过哈希函数处理, hash (key1) == hash (key2) ,这个时候,我们就说发生了哈希冲突。
哈希函数的构造方法
什么是好的哈希函数?(If you can not measure, you can not improve)
如果对于关键字集合中的任意一个关键字,经过哈希函数映像到地址集合中任何一个地址的概率是相等的,就称为这类哈希函数为均匀的(Uniform)。就是使其均匀分布,最大程度减少冲突。
1.直接定址法
取关键字或者关键字的某个线性值为哈希地址:H(key)=a*key+b
例如我们要统计全市的人口(以年龄为分隔),那我们就可以根据年龄作为地址,50岁的放在第50个单位,18岁放在第18 个单位上….如果我们需要找25岁的,直接定位到第25项就行。
优点:
- 地址集合与关键字集合大小相同,不会发生冲突
- 索引很简单,清晰明了
缺点:
- 实际中能够用直接定值法的情况很少
2.除留余数法(最常用)
取关键字被某一个不大于哈希表表长(m)的数p除后所得到的余数为哈希地址
H(key)=key % p , p<=m
对于p的选择一般是选择素数

处理字符串的时候我们可以对每一个字符对应的ASCII码进行除留余数,在创建的时候将每一位字符就对应到最终数字的每一位上面
int Hash(const char *Key, int TableSize){
unsigned int h = 0;
while(*Key != '\0'){
h = (h << 5) + *Key++;
}
return h % TableSize;
}数字分析法:
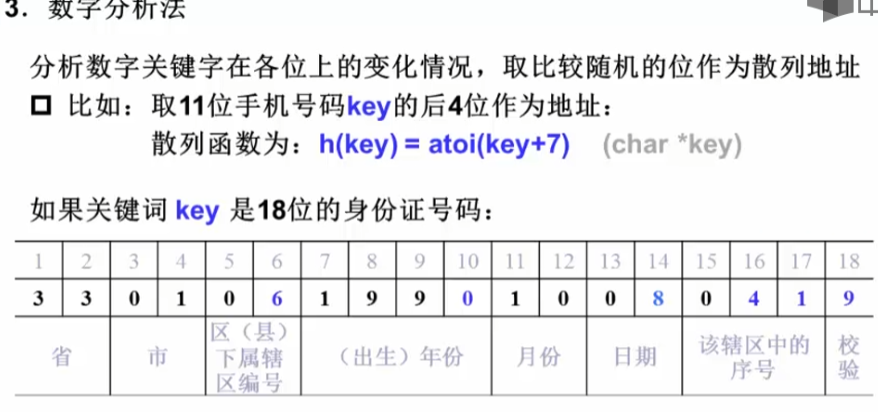
身份证中的区号、年份最后一位、日期、辖区序号都是比较随机的,因此我们选取这几位作为哈希地址

3.折叠法与平方取中法

我们所有的做法目的都是要使得最终的index的取值足够随机,避免哈希冲突
处理哈希冲突的方法
1.开放地址法
Hi = (Hi(key) + di) % m i = 1,2,3,4,,,,k(k <= m-1)
di为递增序量,当出现哈希冲突的时候就在所得的index基础上加上di,如果仍然是冲突di+1,再进行探索地址
#include<iostream>
#include<vector>
#include<cstring>
using namespace std;
const int MAX = 31;
const int VALUE= -1;//值初始化为-1
vector<int>HashTable(MAX);//创建哈希表,暂定31
int Hash(int x) {
return x % MAX;
}
void InitHashTable(vector<int>&HashTable){//如果值为-1就代表没有填充过
for(int i=0; i<MAX; i++) {
HashTable[i] = VALUE;
}
}
int hash(int x) {
return x % MAX;
}
bool find(int a,vector<int>& hashtable) {
int position = hash(a);
int hashkey = hash(a);
int d = 1;//增量初始化为1
while(hashtable[position] != a && hashtable[position] != -1) {
position = hash(hashkey + d);//加上增量\
d++;
}
if(hashtable[position] == a) return true;
if(hashtable[position] == VALUE) return false;//如果说没有填充过就代表没找到
}
int Insert(int a,vector<int> & hashtable) {
int position = hash(a);
int hashkey = hash(a);
int d = 1;//增量初始化为1
if(find(a,hashtable)){
cout<<"The vlaue has already exist!" <<endl;
return -1;
}
//如果已经被占用了就加上递增分量
while(hashtable[position] != VALUE) {
position = hash(hashkey + d);
d++;//递增分量自加
}
hashtable[position] = a;//将值插入进哈希表中、
return position;
}
int main()
{
InitHashTable(HashTable);//初始化哈希表
while(true) {
cout<<"请输入学号后四位,如果不想继续建表请输入'0'\n";
int number;
cin>>number;
int position = Insert(number,HashTable);
cout<<"学号后四位为"<<number<<"的在哈希表中的位置为:"<<position<<endl;
}
}二次探测再散列(平方探测法):di = 1^2, -(1^2), 2^2, -(2^2),。。。错开查找
定理:如果TableSize是4k+1的一个素数形式,平方探测法可以探查到整个散列表的空间
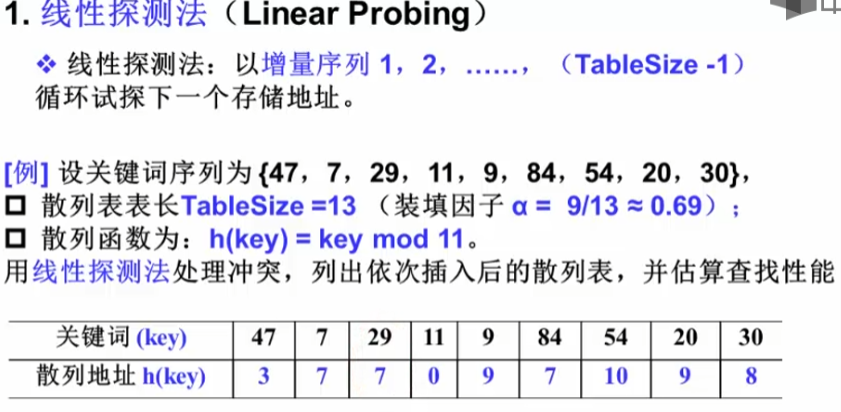

以插入84为例子,84%11 = 7 所以本来应该是放到地址为7的空间,但是已经被占据了di = 1,同样地址为8,9也被占据了 因此di=3,最终放到了10的位置
问题:
如果在某一些部分出现了冲突,那么很有可能出现冲突的聚集,因为每一次出现冲突我都是将新的加入到这个连续的冲突区间中
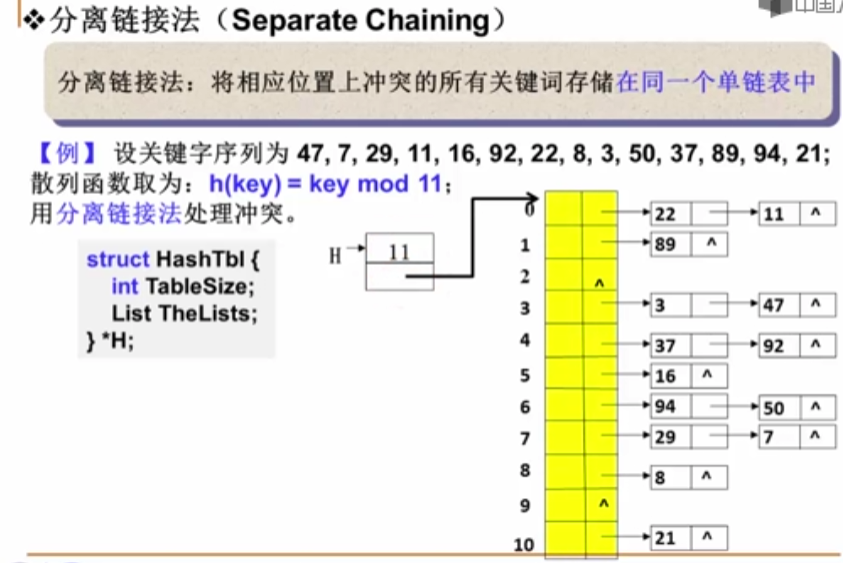
链地址法:
将冲突的所有元素单独的用一个链表进行各自的存放
例题:PAT1145
#include<bits/stdc++.h>
using namespace std;
/*
哈希表:H(key)求余数、二次平方探测法解决冲突、求平均查找长度AVL = All/n
*/
const int maxn = 1e5+5;
int Tsize,n,m;
int a[maxn];
int b[maxn];
int hashTable[maxn];
bool isPrime(int x){
if(x < 2) return false;
for(int i=2;i<=sqrt(x);i++){
if(x%i == 0) return false;
}
return true;
}
int HashKey(int key){
return key%Tsize;
}
int main(){
memset(hashTable,-1,sizeof(hashTable));
cin>>Tsize>>n>>m;
while(isPrime(Tsize) == false) Tsize++; //哈希表的表长度不是素数就加到成为素数为止
for(int i=0;i<n;i++) cin>>a[i];
for(int i=0;i<m;i++) cin>>b[i];
//插入
for(int i=0;i<n;i++){
bool flag = false;
for(int j=0;j<Tsize;j++){
int idx = (HashKey(a[i]) + j*j) % Tsize;//平方探测法解决冲突
if(hashTable[idx] == -1){
hashTable[idx] = a[i];
flag = true;
break;
}
}
if(flag == false){
printf("%d cannot be inserted.\n",a[i]);
}
}
//查找
int cnt = 0;
for(int i=0;i<m;i++){
bool flag = false;
for(int j=0;j<Tsize;j++){
cnt++;
int idx = (HashKey(b[i]) + j*j) % Tsize;//平方探测法解决冲突 查找下标
if(hashTable[idx] == b[i] || hashTable[idx] == -1 ){
flag = true;
break;
}
}
if(flag == false) cnt++;
}
printf("%.1f",cnt*1.0/m);
return 0;
}性能分析

成功分析:例如找30 他的因子di是6 那么它找了7次才放到位置
不成功分析:例如找22 他的首个索引是0,0不是继续向下找,找到2后发现是空的,那么查找次数就是3