1、开放定址法(再散列法):
当关键字key的哈希地址p=H(key)出现冲突时,找出一个不冲突的哈希地址p[i] ,然后存入。
再散列函数形式:
Hi=(H(key)+di)MOD m di=1,2,…,m-1
其中H(key)为哈希函数,m ——表长,di——增量序列。增量序列的取值方式不同,再散列方式不同。
增量序列的取值方式
(1)线性探测再散列:
di=1,2,3,…,m-1
冲突发生时,顺序查看表中下一单元,直到找出一个空单元或查遍全表。
(2)二次探测再散列:
di=12,-12,22,-22,…,k2,-k2 ( k<=m/2 )
冲突发生时,在表的左右进行跳跃式探测,比较灵活。
(3)伪随机探测再散列:
di=伪随机数序列
具体实现时,应建立一个伪随机数发生器,(如i=(i+p) % m),并给定一个随机数做起点,每次去加上这个伪随机数++就可以了。
2、再哈希法
再哈希法:
为了消除原始聚集和二次聚集,可以使用另外一个方法:再哈希法,二次聚集产生的原因是,二次探测的算法产生的探测序列步长总是固定的:1,4,9,16…
关键字用不同的哈希函数再做一遍哈希花,用这个结果作为步长,对指定的关键字,步长在整个探测中是不变的,不过不同的关键字使用不同的步长,那么,不同的关键字即使映射到相同的数组下标,也可以使用不同的探测序列。
Hi=RH1(key) i=1,2,…,k
第二个哈希函数必须具备以下特点:
1.和第一个哈希函数不同
2.不能输出0.
例如:stepSize = constant * (key % constant)
缺点:每次冲突都要重新哈希,计算时间增加
3、链地址法 (HashMap的冲突处理方式)
连地址处理冲突:将产生冲突的值以链表的形式连起来
好处:不会产生堆积,适合无法确定表长的情况,但是会增加空间消耗(指针需要空间),链地址法适用于经常进行插入和删除的情况。
方法:采用结构体数组的方式,首先将结构体内每一个元素赋值 -1 NULL,然后采用插入的方式产生链表,同一个函数值得元素在一条链表上
4.建立公共溢出区
这种方法的基本思想是:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
5.不同处理冲突的平均查找长度
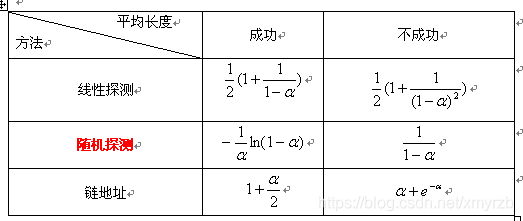
(1)线性探测法:
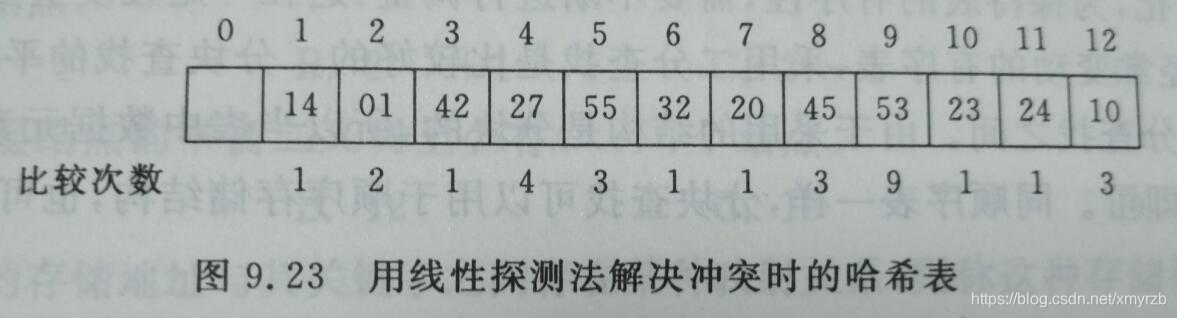
查找成功时的查找次数等于插入元素时的比较次数,查找成功的平均查找长度为:
ASL = (1+2+1+4+3+1+1+3+9+1+1+3)/12 = 2.5
查找不成功时的查找次数:第n个位置不成功时的比较次数为,第n个位置到第1个没有数据位置的距离:如第0个位置取值为1,第1个位置取值为2.
查找不成功的平均查找次数为:
ASL = (1+2+3+4+5+6+7+8+9+10+11+12)/ 13 = 91/13
(2).链地址法:
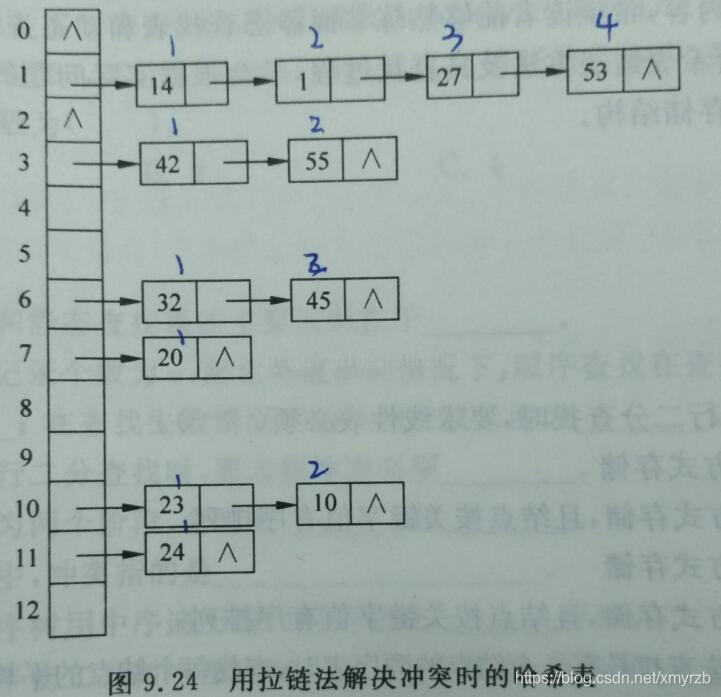
查找成功时的平均查找长度:
ASL = (16+24+31+41)/12 = 7/4
查找不成功时的平均查找长度:
ASL = (4+2+2+1+2+1)/13
注意:查找成功时。分母为哈希表元素个数,查找不成功时,分母为哈希表长度
部分转载于:https://blog.csdn.net/u011080472/article/details/51177412