前言
早在《mysql的扩展与高可用》就提出分库分表的数据库管理方式。ShardingSphere则是另一种解决方案。
核心思想
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar这3款相互独立的产品组成。《ShardingSphere 概览》
- ShardingSphere-JDBC:定位为轻量级 Java 框架,代理Java中的datasource,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架.
- ShardingSphere-Proxy:定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本
- ShardingSphere-Sidecar:定位为 Kubernetes 的云原生数据库代理,以 Sidecar 的形式代理所有对数据库的访问
三者比较:
| ShardingSphere-JDBC | ShardingSphere-Proxy | ShardingSphere-Sidecar | |
|---|---|---|---|
| 数据库 | 任意 | MySQL/PostgreSQL | MySQL/PostgreSQL |
| 连接消耗数 | 高 | 低 | 高 |
| 异构语言 | 仅 Java | 任意 | 任意 |
| 性能 | 损耗低 | 损耗略高 | 损耗低 |
| 无中心化 | 是 | 否 | 是 |
| 静态入口 | 无 | 有 | 无 |
数据分片
ShardingSphere 的 3 个产品的数据分片主要流程是完全一致的《 数据分片》。
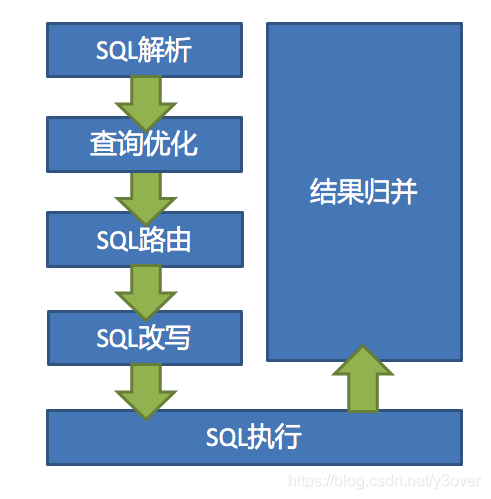
- SQL 解析:分为词法解析和语法解析《编译原理》。
public static void main(String[] args) {
SQLParserEngine sqlParserEngine = new SQLParserEngine("MySQL");
SelectStatement selectStatement = (SelectStatement) sqlParserEngine.parse("select id,name from users a left join shop b on a.shop_id = b.id where a.name = 'yoyo'", false);
System.out.println("--------------------- 表输出 --------------------");
selectStatement.getSimpleTableSegments().forEach(x-> System.out.println(x.getTableName().getIdentifier().getValue()));
System.out.println("--------------------- 条件输出 --------------------");
selectStatement.getWhere().get().getAndPredicates().forEach(x->{
x.getPredicates().forEach(y->{
System.out.println(y.getColumn().getQualifiedName());
System.out.println(((PredicateCompareRightValue)y.getRightValue()).getExpression());
});
});
System.out.println("--------------------- 列输出 --------------------");
selectStatement.getProjections().getProjections().forEach(x ->{
System.out.println(((ColumnProjectionSegment)x).getColumn().getQualifiedName());
});
}
- 执行器优化:合并和优化分片条件,如 OR 等。
- SQL 路由:根据解析上下文匹配用户配置的分片策略,并生成路由路径
ListRouteValue routeValue = new ListRouteValue("id", "users", Collections.singletonList(315));
ShardingStrategy shardingStrategy = ShardingStrategyFactory.newInstance(new InlineShardingStrategyConfiguration("id", "ds${id % 3}"));
// "ds0", "ds1", "ds2" 是目标集合
// 通过 ds${id % 3} groovyShell 算出结果,如果在目标集合中,则放入results
Collection<String> results = shardingStrategy.doSharding(Arrays.asList("ds0", "ds1", "ds2"), Collections.singletonList(routeValue), new ConfigurationProperties(new Properties()));
results.forEach(System.out::println);
- SQL 改写:将 SQL 改写为在真实数据库中可以正确执行的语句
public static void main(String[] args) {
SQLParserEngine sqlParserEngine = new SQLParserEngine("MySQL");
String sql = "select * from users where id = 315";
SQLStatement sqlStatement = sqlParserEngine.parse(sql, false);
SelectStatementContext sqlStatementContext = new SelectStatementContext((SelectStatement) sqlStatement, null, null,null, null);
List<TableToken> tokenList = new ArrayList<>();
for (SimpleTableSegment each : sqlStatementContext.getAllTables()) {
tokenList.add(new TableToken(each.getStartIndex(), each.getStopIndex(), each.getTableName().getIdentifier()));
}
Map<String, String> tableMaps = Maps.newHashMap();
tableMaps.put("users", "user1");
System.out.println(toSQL(sql, tokenList, tableMaps));
}
public static String toSQL(String sql, List<TableToken> tokenList, Map<String, String> tableMaps) {
Collections.sort(tokenList);
StringBuilder result = new StringBuilder();
result.append(sql.substring(0, tokenList.get(0).getStartIndex()));
for (int i = 0; i < tokenList.size() ; i++) {
TableToken each = tokenList.get(i);
String tableName = each.getIdentifier().getValue();
result.append(tableMaps.getOrDefault(tableName, tableName));
int start = each.getStopIndex() + 1;
int end = i == tokenList.size() - 1 ? sql.length() : tokenList.get(i+1).getStartIndex() ;
result.append(sql.substring(start, end));
}
return result.toString();
}
@Data
static class TableToken extends SQLToken{
private final int stopIndex;
private final IdentifierValue identifier;
public TableToken(int startIndex, int stopIndex, IdentifierValue identifier) {
super(startIndex);
this.stopIndex = stopIndex;
this.identifier = identifier;
}
}
- SQL 执行:通过多线程执行器异步执行。
- 结果归并:将多个执行结果集归并以便于通过统一的 JDBC 接口输出。
分布式事务
《分布式事务》
// todo
数据治理
// todo
实例构建
在java代码中快速构建ShardingSphere-JDBC用例
public class ShardingJdbcTest {
public static DataSource hikariDataSource(String name) throws SQLException {
HikariDataSource hikariDataSource = new HikariDataSource();
//driverClassName无需指定,除非系统无法自动识别
hikariDataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");
//database address
hikariDataSource.setJdbcUrl("jdbc:mysql://localhost/test"+name+"?logger=Slf4JLogger");
//useName 用户名
hikariDataSource.setUsername("sa");
//password
hikariDataSource.setPassword("sa");
//连接只读数据库时配置为true, 保证安全 -->
hikariDataSource.setReadOnly(false);
return hikariDataSource;
}
private static Map<String, DataSource> createDataSourceMap() throws SQLException {
Map<String, DataSource> result = new HashMap<>();
result.put("ds0", hikariDataSource("_gwb"));
result.put("ds1", hikariDataSource("_gwb2"));
return result;
}
public static void main(String[] args) throws SQLException {
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getBindingTableGroups().add("users");
shardingRuleConfig.getTableRuleConfigs().add(new TableRuleConfiguration("users", "ds${0..1}.users${0..1}"));
shardingRuleConfig.setDefaultDatabaseShardingStrategyConfig(new InlineShardingStrategyConfiguration("id", "ds${id % 2}"));
shardingRuleConfig.setDefaultTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("id", "users${id % 2}"));
Properties properties = new Properties();
properties.put(ConfigurationPropertyKey.SQL_SHOW, Boolean.TRUE);
DataSource dataSource = ShardingDataSourceFactory.createDataSource(createDataSourceMap(), shardingRuleConfig, properties);
Connection conn = dataSource.getConnection();
Statement stat = conn.createStatement();
ResultSet rs = stat.executeQuery("select * from users where id = 315");
//5.遍历结果集获取查询对象
while (rs.next()) {
String name = rs.getString("username");
System.out.println(name);
}
}
}