一、ShardingSphere
ShardingSphere是一款起源于当当网内部的应用框架。2015年在当当网内部诞生,最初就叫ShardingJDBC。2016年的时候,由其中一个主要的开发人员张亮,带入到京东数科,组件团队继续开发。ShardingSphere包含三个重要的产品,ShardingJDBC、ShardingProxy和ShardingSidecar。其中sidecar是针对service mesh定位的一个分库分表插件,目前在规划中。ShardingJDBC是用来做客户端分库分表的产品,而ShardingProxy是用来做服务端分库分表的产品。
ShardingJDBC:
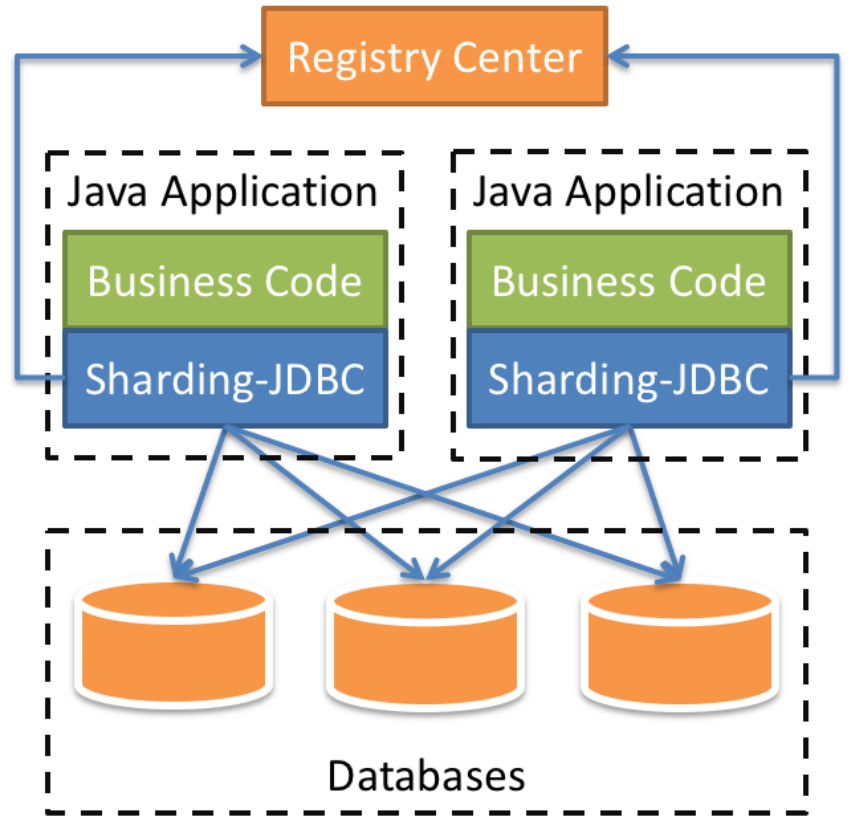
shardingJDBC定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。它使⽤客户端直连数据库,以 jar 包形式提供服务,⽆需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
ShardingProxy:
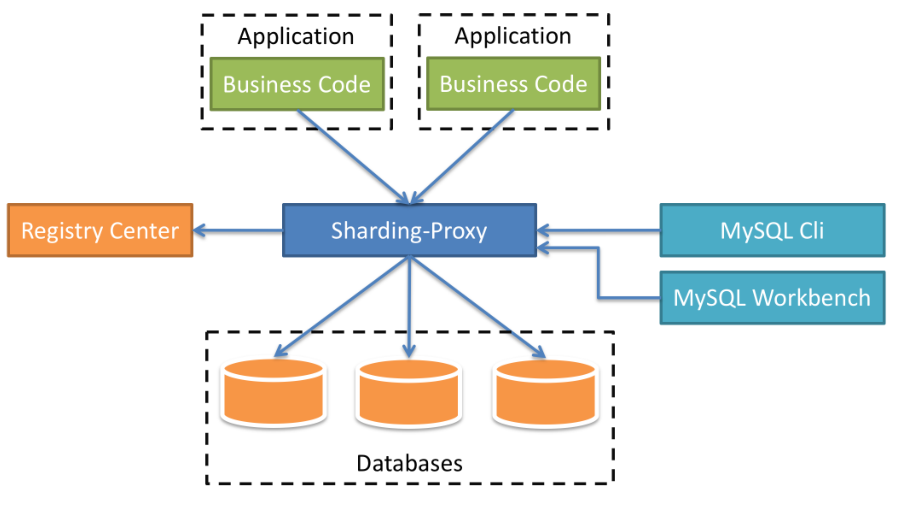
ShardingProxy定位为透明化的数据库代理端,提供封装了数据库⼆进制协议的服务端版本,⽤于完成对异构语⾔的⽀持。⽬前提供 MySQL 和 PostgreSQL 版本,它可以使⽤任何兼容 MySQL/PostgreSQL 协议的访问客⼾端。
那这两种方式有什么区别呢?
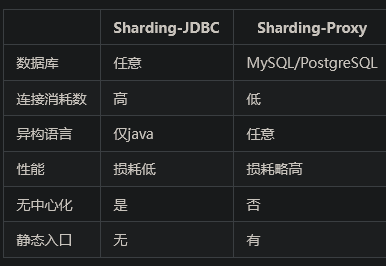
ShardingJDBC只是客户端的一个工具包,可以理解为一个特殊的JDBC驱动包,所有分库分表逻辑均由业务方自己控制,所以他的功能相对灵活,支持的数据库也非常多,但是对业务侵入大,需要业务方自己定制所有的分库分表逻辑。而ShardingProxy是一个独立部署的服务,对业务方无侵入,业务方可以像用一个普通的MySQL服务一样进行数据交互,基本上感觉不到后端分库分表逻辑的存在,但是这也意味着功能会比较固定,能够支持的数据库也比较少。这两者各有优劣。
二、ShardingJDBC实战
shardingjdbc的核心功能是数据分片和读写分离,通过ShardingJDBC,应用可以透明的使用JDBC访问已经分库分表、读写分离的多个数据源,而不用关心数据源的数量以及数据如何分布。
1、核心概念
逻辑表:水平拆分的数据库的相同逻辑和数据结构表的总称
真实表:在分片的数据库中真实存在的物理表。
数据节点:数据分片的最小单元。由数据源名称和数据表组成
绑定表:分片规则一致的主表和子表。
广播表:也叫公共表,指素有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中都完全一致。例如字典表。
分片键:用于分片的数据库字段,是将数据库(表)进行水平拆分的关键字段。SQL中若没有分片字段,将会执行全路由,性能会很差。
分片算法:通过分片算法将数据进行分片,支持通过=、BETWEEN和IN分片。分片算法需要由应用开发者自行实现,可实现的灵活度非常高。
分片策略:真正用于进行分片操作的是分片键+分片算法,也就是分片策略。在ShardingJDBC中一般采用基于Groovy表达式的inline分片策略,通过一个包含分片键的算法表达式来制定分片策略,如t_user_$->{u_id%8}标识根据u_id模8,分成8张表,表名称为t_user_0到t_user_7。
2、测试项目介绍
测试项目参见配套的ShardingDemo项。首先我们对测试项目的结构做下简单的梳理:
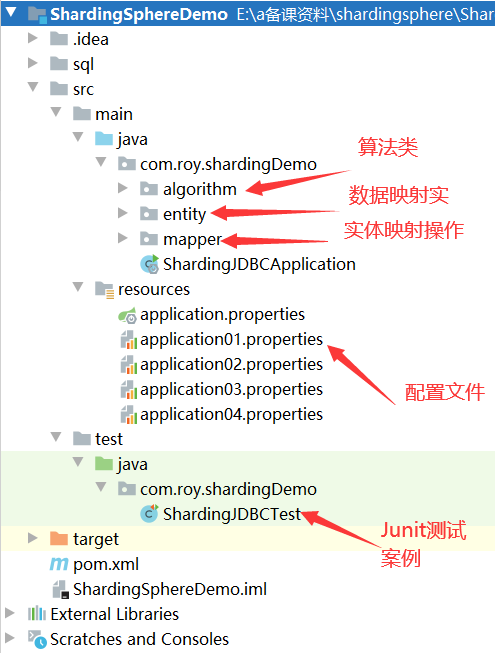
注:1、引入MyBatisPlus依赖,简化JDBC操作,这样我们就不需要在代码中写SQL语句了。
2、entity中的实体对象就对应数据库中的表结构。而mapper中的接口则对应JDBC操作。
3、所有操作均使用JUnit的测试案例执行。 后续所有测试操作都会配合application.properties中的配置以及JUnit测试案例进行。
4、关于ShardingSphere版本,由于目前最新的5.0版本还在孵化当中,所以我们使用已发布的4.1.1版本来进行学习。
3、快速实战
我们先运行一个简单的实例,来看下ShardingJDBC是如何工作的。
在application.properties配置文件中写入application01.properties文件的内容:
#垂直分表策略
# 配置真实数据源
spring.shardingsphere.datasource.names=m1
# 配置第 1 个数据源
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/coursedb?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=root
# 指定表的分布情况 配置表在哪个数据库里,表名是什么。水平分表,分两个表:m1.course_1,m1.course_2
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m1.course_$->{1..2}
# 指定表的主键生成策略
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
#雪花算法的一个可选参数
spring.shardingsphere.sharding.tables.course.key-generator.props.worker.id=1
#使用自定义的主键生成策略
#spring.shardingsphere.sharding.tables.course.key-generator.type=MYKEY
#spring.shardingsphere.sharding.tables.course.key-generator.props.mykey-offset=88
#指定分片策略 约定cid值为偶数添加到course_1表。如果是奇数添加到course_2表。
# 选定计算的字段
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column= cid
# 根据计算的字段算出对应的表名。
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid%2+1}
# 打开sql日志输出。
spring.shardingsphere.props.sql.show=true
spring.main.allow-bean-definition-overriding=true
1、首先定义一个数据源m1,并对m1进行实际的JDBC参数配置
2、spring.shardingsphere.sharding.tables.course开头的一系列属性即定义了一个名为course的逻辑表。
actual-data-nodes属性即定义course逻辑表的实际数据分布情况,他分布在m1.course_1和m1.course_2两个表。
key-generator属性配置了他的主键列以及主键生成策略。ShardingJDBC默认提供了UUID和SNOWFLAKE两种分布式主键生成策略。
table-strategy属性即配置他的分库分表策略。分片键为cid属性。分片算法为course_$->{cid%2+1},表示按照cid模2+1的结果,然后加上前面的course__ 部分作为前缀就是他的实际表结果。注意,这个表达式计算出来的结果需要能够与实际数据分布中的一种情况对应上,否则就会报错。
sql.show属性表示要在日志中打印实际SQL
3、coursedb的表结构见示例中sql文件夹中的sql语句。
然后我们执行测试案例中的addcourse案例。
 执行后,我们可以在控制台看到很多条这样的日志:
执行后,我们可以在控制台看到很多条这样的日志:
.......
2020-12-15 18:35:16.426 INFO 22412 --- [ main] ShardingSphere-SQL : Logic SQL: INSERT INTO course ( cname,
user_id,
cstatus ) VALUES ( ?,
?,
? )
2020-12-15 18:35:16.427 INFO 22412 --- [ main] ShardingSphere-SQL : SQLStatement: InsertStatementContext(super=CommonSQLStatementContext(sqlStatement=org.apache.shardingsphere.sql.parser.sql.statement.dml.InsertStatement@1cbc5693, tablesContext=org.apache.shardingsphere.sql.parser.binder.segment.table.TablesContext@124d26ba), tablesContext=org.apache.shardingsphere.sql.parser.binder.segment.table.TablesContext@124d26ba, columnNames=[cname, user_id, cstatus], insertValueContexts=[InsertValueContext(parametersCount=3, valueExpressions=[ParameterMarkerExpressionSegment(startIndex=59, stopIndex=59, parameterMarkerIndex=0), ParameterMarkerExpressionSegment(startIndex=62, stopIndex=62, parameterMarkerIndex=1), ParameterMarkerExpressionSegment(startIndex=65, stopIndex=65, parameterMarkerIndex=2), DerivedParameterMarkerExpressionSegment(super=ParameterMarkerExpressionSegment(startIndex=0, stopIndex=0, parameterMarkerIndex=3))], parameters=[java, 1001, 1])], generatedKeyContext=Optional[GeneratedKeyContext(columnName=cid, generated=true, generatedValues=[545674405561237505])])
2020-12-15 18:35:16.427 INFO 22412 --- [ main] ShardingSphere-SQL : Actual SQL: m1 ::: INSERT INTO course_2 ( cname,
user_id,
cstatus , cid) VALUES (?, ?, ?, ?) ::: [java, 1001, 1, 545674405561237505]
.....
从这个日志中我们可以看到,程序中执行的Logic SQL经过ShardingJDBC处理后,被转换成了Actual SQL往数据库里执行。执行的结果可以在MySQL中看到,course_1和course_2两个表中各插入了五条消息。这就是ShardingJDBC帮我们进行的数据库的分库分表操作。
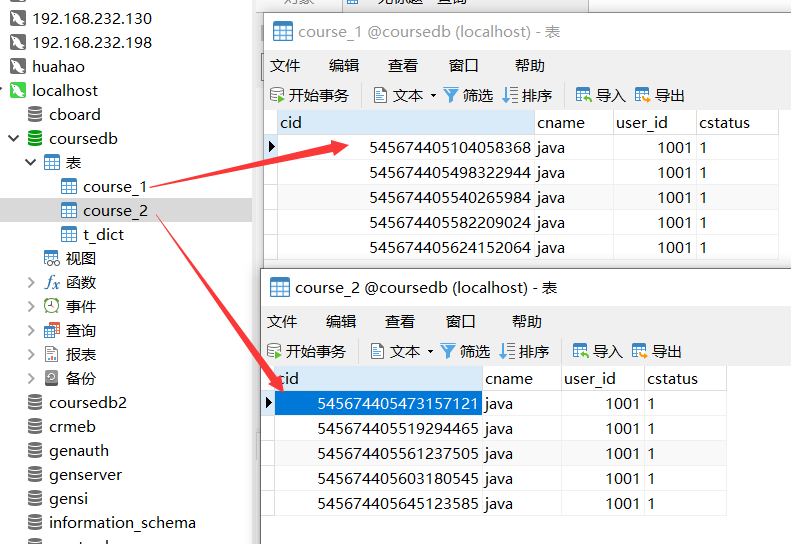
然后,其他的几个配置文件依次对应了其他几种分库分表策略,我们可以一一演示一下。
application02.properties: 分库分表示例配置。内置分片算法示例, inline、standard、complex、hint。广播表配置示例。 application03.properties: 绑定表示例配置 application04.properties: 读写分离示例配置
要注意理解在读写分离策略中,ShardingJDBC只能帮我们把读写操作分发到不同的数据库上,而数据库之间的数据同步,还是需要由MySQL主从集群来完成。
4、ShardingJDBC的分片算法
ShardingJDBC的整个实战完成后,可以看到,整个分库分表的核心就是在于配置的分片算法。我们的这些实战都是使用的inline分片算法,即提供一个分片键和一个分片表达式来制定分片算法。这种方式配置简单,功能灵活,是分库分表最佳的配置方式,并且对于绝大多数的分库分片场景来说,都已经非常好用了。但是,如果针对一些更为复杂的分片策略,例如多分片键、按范围分片等场景,inline分片算法就有点力不从心了。所以,我们还需要学习下ShardingSphere提供的其他几种分片策略。
ShardingSphere目前提供了一共五种分片策略:
NoneShardingStrategy
- 不分片。这种严格来说不算是一种分片策略了。只是ShardingSphere也提供了这么一个配置。
InlineShardingStrategy
最常用的分片方式
- 配置参数: inline.shardingColumn 分片键;inline.algorithmExpression 分片表达式
- 实现方式: 按照分片表达式来进行分片。
StandardShardingStrategy
只支持单分片键的标准分片策略。
-
配置参数:standard.sharding-column 分片键;standard.precise-algorithm-class-name 精确分片算法类名;standard.range-algorithm-class-name 范围分片算法类名
-
实现方式:shardingColumn指定分片算法。preciseAlgorithmClassName 指向一个实现了io.shardingsphere.api.algorithm.sharding.standard.PreciseShardingAlgorithm接口的java类名,提供按照 = 或者 IN 逻辑的精确分片 示例:com.roy.shardingDemo.algorithm.MyPreciseShardingAlgorithm。rangeAlgorithmClassName 指向一个实现了 io.shardingsphere.api.algorithm.sharding.standard.RangeShardingAlgorithm接口的java类名,提供按照Between 条件进行的范围分片。示例:com.roy.shardingDemo.algorithm.MyRangeShardingAlgorithm
-
说明: 其中精确分片算法是必须提供的,而范围分片算法则是可选的。
ComplexShardingStrategy
支持多分片键的复杂分片策略。
-
配置参数:complex.sharding-columns 分片键(多个); complex.algorithm-class-name 分片算法实现类。
-
实现方式:shardingColumn指定多个分片列。algorithmClassName指向一个实现了org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingAlgorithm接口的java类名。提供按照多个分片列进行综合分片的算法。示例:com.roy.shardingDemo.algorithm.MyComplexKeysShardingAlgorithm
HintShardingStrategy
不需要分片键的强制分片策略。这个分片策略,简单来理解就是说,他的分片键不再跟SQL语句相关联,而是用程序另行指定。对于一些复杂的情况,例如select count(*) from (select userid from t_user where userid in (1,3,5,7,9)) 这样的SQL语句,就没法通过SQL语句来指定一个分片键。这个时候就可以通过程序,给他另行执行一个分片键,例如在按userid奇偶分片的策略下,可以指定1作为分片键,然后自行指定他的分片策略。
-
配置参数:hint.algorithm-class-name 分片算法实现类。
-
实现方式:algorithmClassName指向一个实现了org.apache.shardingsphere.api.sharding.hint.HintShardingAlgorithm接口的java类名。 示例:com.roy.shardingDemo.algorithm.MyHintShardingAlgorithm。在这个算法类中,同样是需要分片键的。而分片键的指定是通过HintManager.addDatabaseShardingValue方法(分库)和HintManager.addTableShardingValue(分表)来指定。使用时要注意,这个分片键是线程隔离的,只在当前线程有效,所以通常建议使用之后立即关闭,或者用try资源方式打开。
而Hint分片策略并没有完全按照SQL解析树来构建分片策略,是绕开了SQL解析的,所有对某些比较复杂的语句,Hint分片策略性能有可能会比较好(情况太多了,无法一一分析)。
但是要注意,Hint强制路由在使用时有非常多的限制:
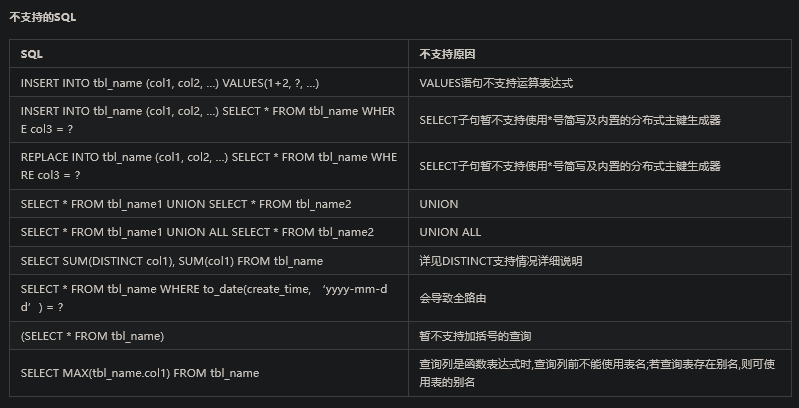
– 不支持UNION SELECT * FROM t_order1 UNION SELECT * FROM t_order2 INSERT INTO tbl_name (col1, col2, …) SELECT col1, col2, … FROM tbl_name WHERE col3 = ?
– 不支持多层子查询 SELECT COUNT(*) FROM (SELECT * FROM t_order o WHERE o.id IN (SELECT id FROM t_order WHERE status = ?))
– 不支持函数计算。ShardingSphere只能通过SQL字面提取用于分片的值 SELECT * FROM t_order WHERE to_date(create_time, ‘yyyy-mm-dd’) = ‘2019-01-01’;
示例详见application02.properties配置。
从这里也能看出,即便有了ShardingSphere框架,分库分表后对于SQL语句的支持依然是非常脆弱的。
5、ShardingSphere的SQL使用限制
参见官网文档: https://shardingsphere.apache.org/document/current/cn/features/sharding/use-norms/sql/ 文档中详细列出了非常多ShardingSphere目前版本支持和不支持的SQL类型。这些东西要经常关注。

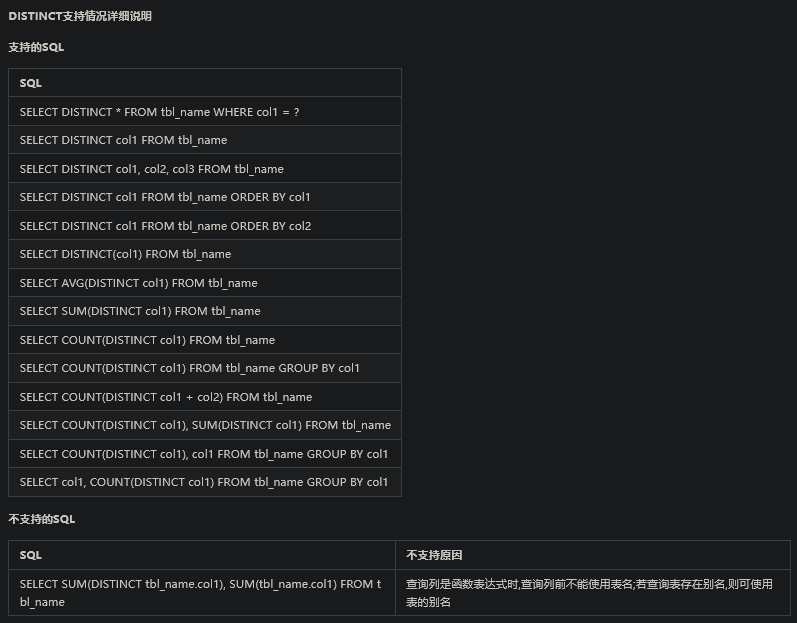
6、分库分表带来的问题
1、分库分表,其实围绕的都是一个核心问题,就是单机数据库容量的问题。我们要了解,在面对这个问题时,解决方案是很多的,并不止分库分表这一种。但是ShardingSphere的这种分库分表,是希望在软件层面对硬件资源进行管理,从而便于对数据库的横向扩展,这无疑是成本很小的一种方式。
2、一般情况下,如果单机数据库容量撑不住了,应先从缓存技术着手降低对数据库的访问压力。如果缓存使用过后,数据库访问量还是非常大,可以考虑数据库读写分离策略。如果数据库压力依然非常大,且业务数据持续增长无法估量,最后才考虑分库分表,单表拆分数据应控制在1000万以内。
当然,随着互联网技术的不断发展,处理海量数据的选择也越来越多。在实际进行系统设计时,最好是用MySQL数据库只用来存储关系性较强的热点数据,而对海量数据采取另外的一些分布式存储产品。例如PostGreSQL、VoltDB甚至HBase、Hive、ES等这些大数据组件来存储。
3、从上一部分ShardingJDBC的分片算法中我们可以看到,由于SQL语句的功能实在太多太全面了,所以分库分表后,对SQL语句的支持,其实是步步为艰的,稍不小心,就会造成SQL语句不支持、业务数据混乱等很多很多问题。所以,实际使用时,我们会建议这个分库分表,能不用就尽量不要用。
如果要使用优先在OLTP场景下使用,优先解决大量数据下的查询速度问题。而在OLAP场景中,通常涉及到非常多复杂的SQL,分库分表的限制就会更加明显。当然,这也是ShardingSphere以后改进的一个方向。
4、如果确定要使用分库分表,就应该在系统设计之初开始对业务数据的耦合程度和使用情况进行考量,尽量控制业务SQL语句的使用范围,将数据库往简单的增删改查的数据存储层方向进行弱化。并首先详细规划垂直拆分的策略,使数据层架构清晰明了。而至于水平拆分,会给后期带来非常非常多的数据问题,所以应该谨慎、谨慎再谨慎。一般也就在日志表、操作记录表等很少的一些边缘场景才偶尔用用。
7、分库分表方案设计实战
接下来,我们来给电商的商品管理模块设计一个分库分表的方案,来理解下分库分表应该如何落地。
一个典型的电商场景,商品管理模块大致的功能组件如下图:
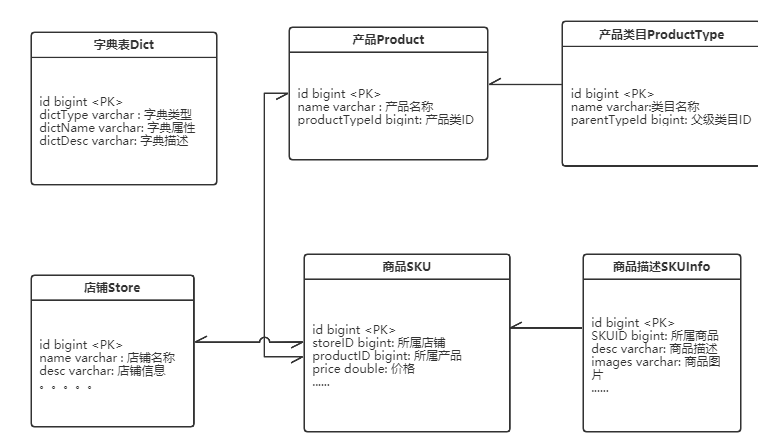
针对这个场景,考虑到商品信息会持续增长,越来越多的情况,要如何设计分库分表方案?
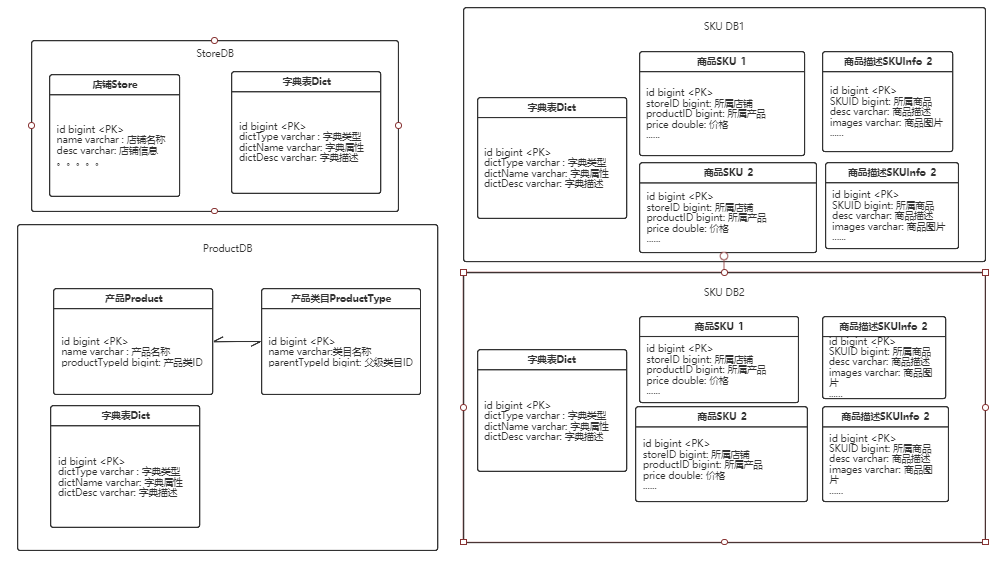
1、以业务为单位考虑对数据进行垂直分片,店铺、产品、商品三种业务数据垂直拆分成三个不同的库。字典表作为广播表冗余到三个不同的库中。
2、考虑数据增长情况,商品将会是以后增长最快的数据,店铺和产品的数据增速会逐渐降低。所以对商品表进行分片。分片策略采用商品ID取模的方式,尽量保证商品数据平均分片。
3、将关联性较强的商品信息表和商品补充信息表配置为绑定表。
整体分库分表大致如下图:
三、内核剖析
ShardingSphere虽然有多个产品,但是他们的数据分片主要流程是完全一致的。
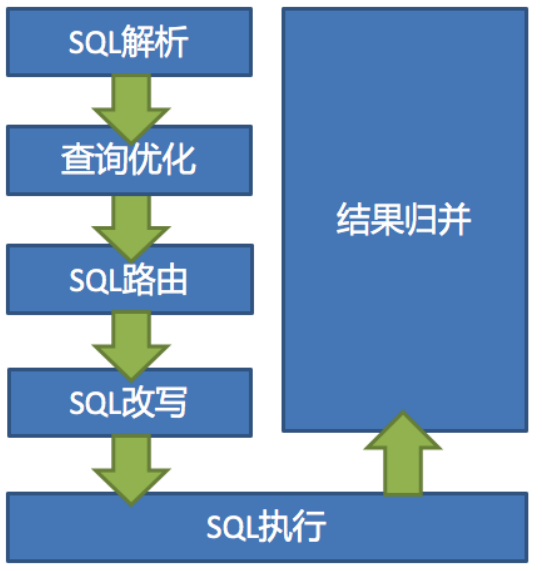
解析引擎
解析过程分为词法解析和语法解析。 词法解析器用于将SQL拆解为不可再分的原子符号,称为Token。并根据不同数据库方言所提供的字典,将其归类为关键字,表达式,字面量和操作符。 再使用语法解析器将SQL转换为抽象语法树(简称AST, Abstract Syntax Tree)。
例如对下面一条SQL语句:
SELECT id, name FROM t_user WHERE status = ‘ACTIVE’ AND age > 18
会被解析成下面这样一颗树:
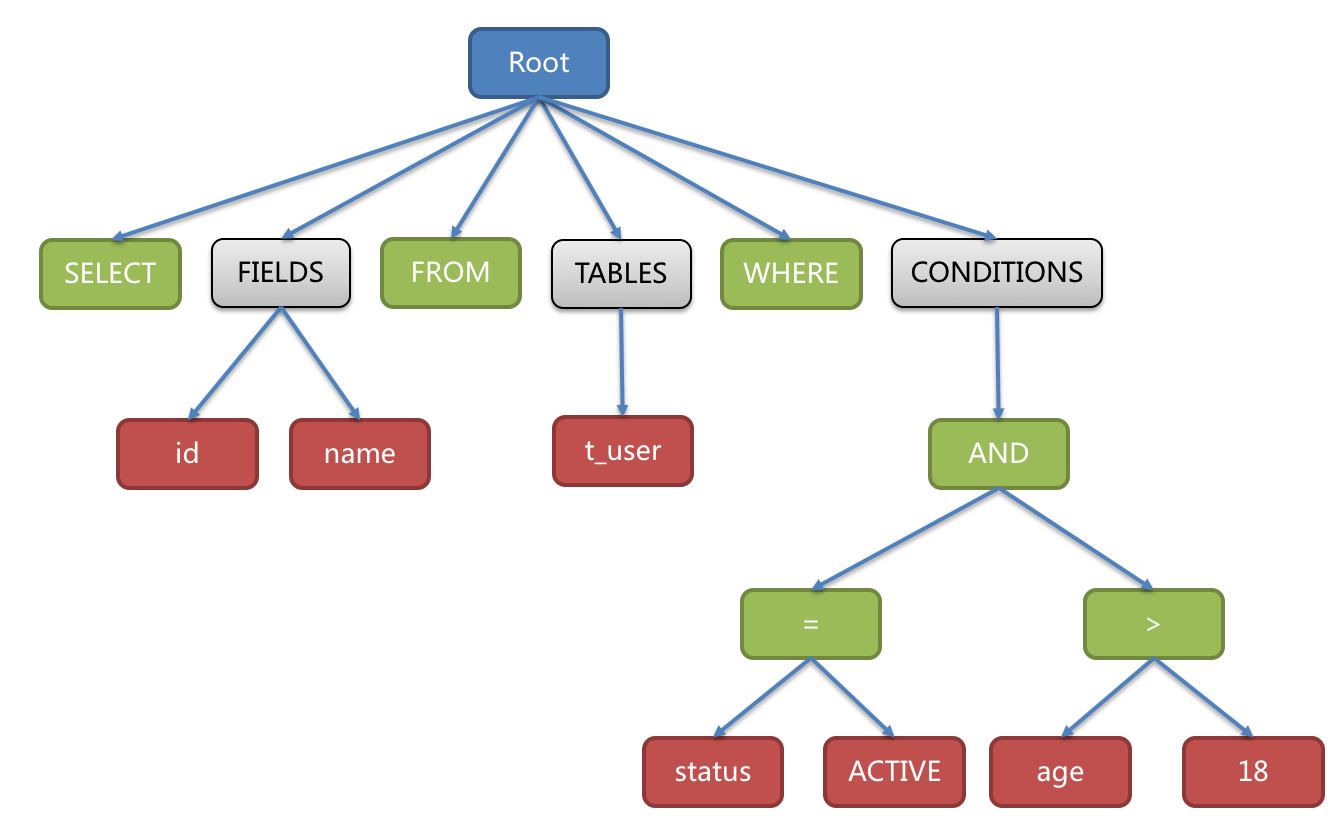 为了便于理解,抽象语法树中的关键字的 Token 用绿色表示,变量的 Token 用红色表示,灰色表示需要进⼀步拆分。通过对抽象语法树的遍历,可以标记出所有可能需要改写的位置。SQL的一次解析过程是不可逆的,所有token按SQL原本的顺序依次进行解析,性能很高。并且在解析过程中,需要考虑各种数据库SQL方言的异同,提供不同的解析模版。
为了便于理解,抽象语法树中的关键字的 Token 用绿色表示,变量的 Token 用红色表示,灰色表示需要进⼀步拆分。通过对抽象语法树的遍历,可以标记出所有可能需要改写的位置。SQL的一次解析过程是不可逆的,所有token按SQL原本的顺序依次进行解析,性能很高。并且在解析过程中,需要考虑各种数据库SQL方言的异同,提供不同的解析模版。
其中,SQL解析是整个分库分表产品的核心,其性能和兼容性是最重要的衡量指标。ShardingSphere在1.4.x之前采用的是性能较快的Druid作为SQL解析器。1.5.x版本后,采用自研的SQL解析器,针对分库分表场景,采取对SQL半理解的方式,提高SQL解析的性能和兼容性。然后从3.0.x版本后,开始使用ANLTR作为SQL解析引擎。这是个开源的SQL解析引擎,ShardingSphere在使用ANLTR时,还增加了一些AST的缓存功能。针对ANLTR4的特性,官网建议尽量采用PreparedStatement的预编译方式来提高SQL执行的性能。
sql解析整体结构:
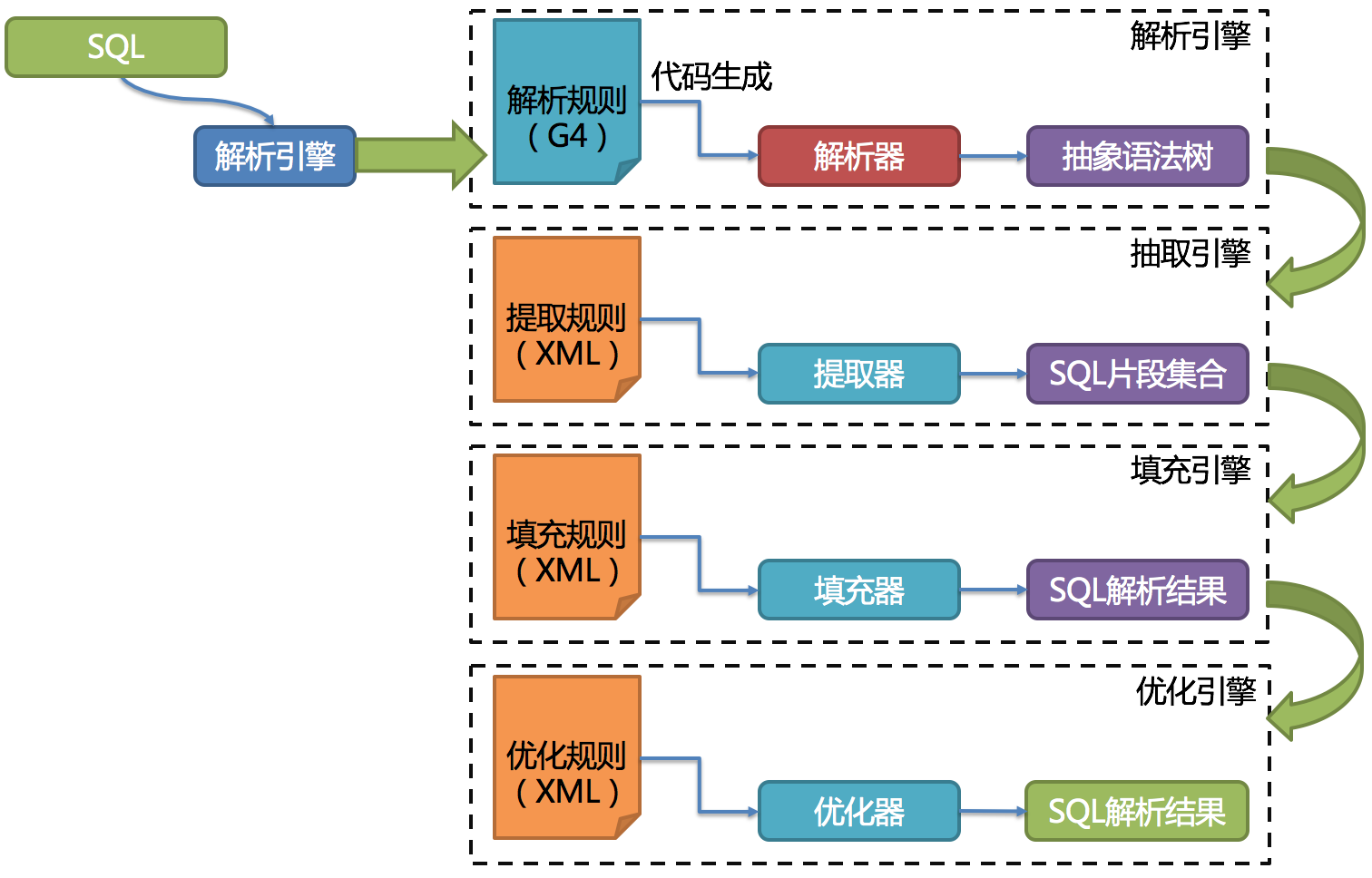
路由引擎
根据解析上下文匹配数据库和表的分片策略,生成路由路径。
ShardingSphere的分片策略主要分为单片路由(分片键的操作符是等号)、多片路由(分片键的操作符是IN)和范围路由(分片键的操作符是Between)。不携带分片键的SQL则是广播路由。
分片策略通常可以由数据库内置也可以由用户方配置。内置的分片策略大致可分为尾数取模、哈希、范围、标签、时间等。 由用户方配置的分片策略则更加灵活,可以根据使用方需求定制复合分片策略。
实际使用时,应尽量使用分片路由,明确路由策略。因为广播路由影响过大,不利于集群管理及扩展。

全库表路由:对于不带分片键的DQL、DML以及DDL语句,会遍历所有的库表,逐一执行。例如 select * from course 或者 select * from course where ustatus=‘1’(不带分片键)
全库路由:对数据库的操作都会遍历所有真实库。 例如 set autocommit=0
全实例路由:对于DCL语句,每个数据库实例只执行一次,例如 CREATE USER [email protected] identified BY ‘123’;
单播路由:仅需要从任意库中获取数据即可。 例如 DESCRIBE course
阻断路由:屏蔽SQL对数据库的操作。例如 USE coursedb。就不会在真实库中执行,因为针对虚拟表操作,不需要切换数据库。
改写引擎
用户只需要面向逻辑库和逻辑表来写SQL,最终由ShardigSphere的改写引擎将SQL改写为在真实数据库中可以正确执行的语句。SQL改写分为正确性改写和优化改写。
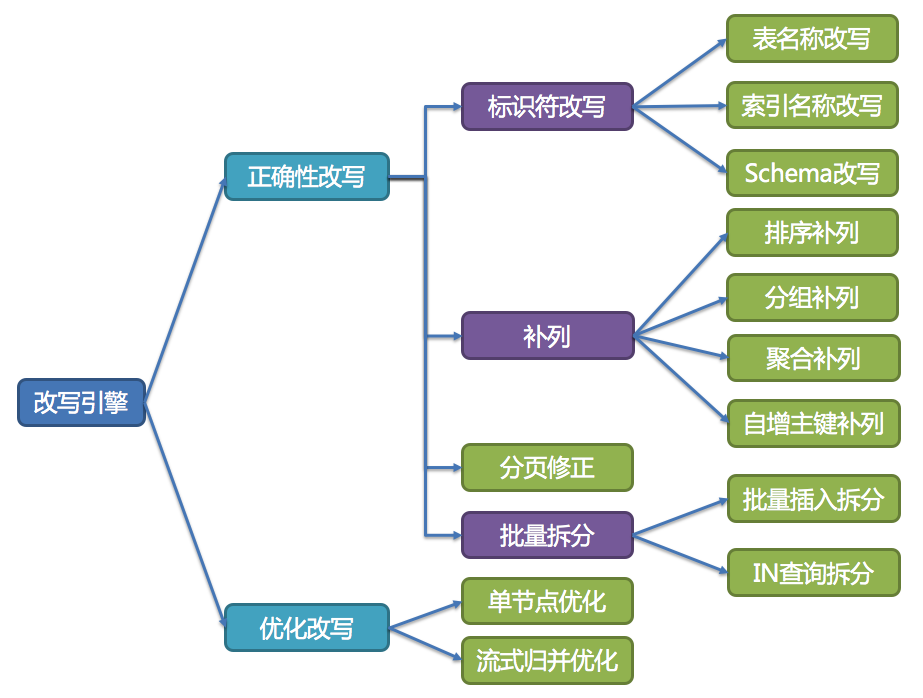
执行引擎
ShardingSphere并不是简单的将改写完的SQL提交到数据库执行。执行引擎的目标是自动化的平衡资源控制和执行效率。
例如他的连接模式分为内存限制模式(MEMORY_STRICTLY)和连接限制模式(CONNECTION_STRICTLY)。内存限制模式只关注一个数据库连接的处理数量,通常一张真实表一个数据库连接。而连接限制模式则只关注数据库连接的数量,较大的查询会进行串行操作。
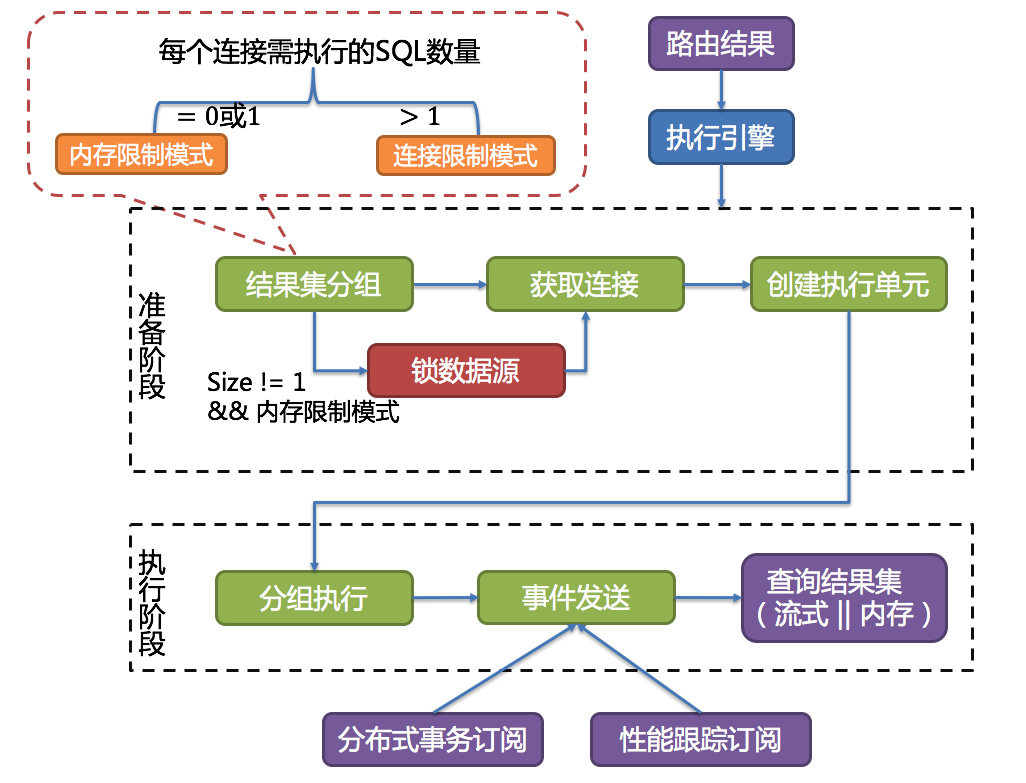
ShardingSphere引入了连接模式的概念,分为内存限制模式(MEMORY_STRICTLY)和连接限制模式(CONNECTION_STRICTLY)。
这两个模式的区分涉及到一个参数 spring.shardingsphere.props.max.connections.size.per.query=50(默认值1,配置参见源码中ConfigurationPropertyKey类)。ShardingSphere会根据 路由到某一个数据源的路由结果 计算出 所有需在数据库上执行的SQL数量,用这个数量除以 用户的配置项,得到每个数据库连接需执行的SQL数量。数量>1就会选择连接限制模式,数量<=1就会选择内存限制模式。
内存限制模式不限制连接数,也就是说会建立多个数据连接,然后并发控制每个连接只去读取一个数据分片的数据。这样可以最快速度的把所有需要的数据读出来。并且在后面的归并阶段,会选择以每一条数据为单位进行归并,就是后面提到的流式归并。这种归并方式归并完一批数据后,可以释放内存了,可以很好的提高数据归并的效率,并且防止出现内存溢出或垃圾回收频繁的情况。他的吞吐量比较大,比较适合OLAP场景。
连接限制模式会对连接数进行限制,也即是说至少有一个数据库连接会要去读取多个数据分片的数据。这样他会对这个数据库连接采用串行的方式依次读取多个数据分片的数据。而这种方式下,会将数据全部读入到内存,进行统一的数据归并,也就是后面提到的内存归并。这种方式归并效率会比较高,例如一个MAX归并,直接就能拿到最大值,而流式归并就需要一条条的比较。比较适合OLTP场景。
归并引擎
将从各个数据节点获取的多数据结果集,组合成为一个结果集并正确的返回至请求客户端,称为结果归并。
其中,流式归并是指以一条一条数据的方式进行归并,而内存归并是将所有结果集都查询到内存中,进行统一归并。
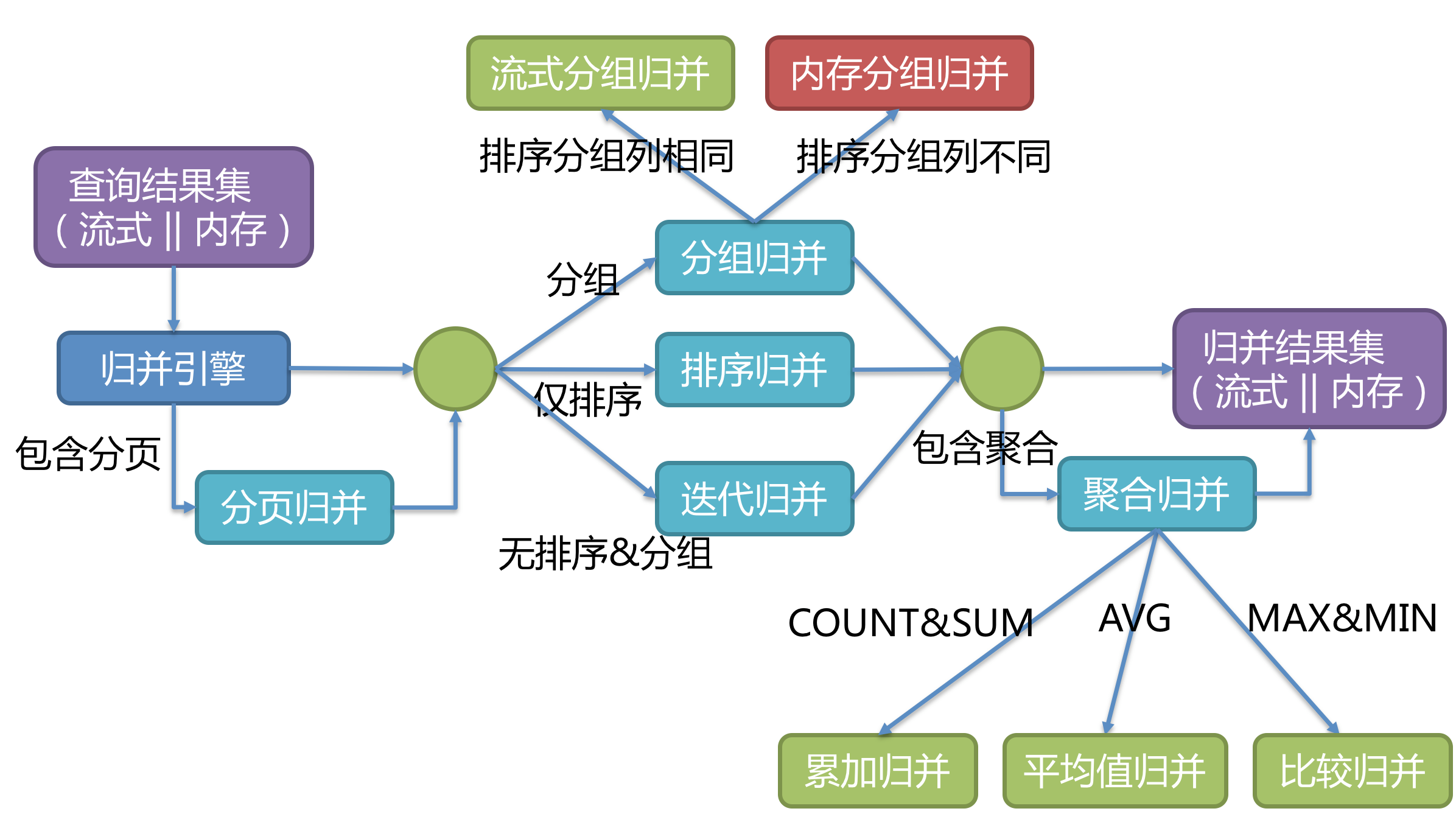 例如: AVG归并就无法直接进行分片归并,需要转化成COUNT&SUM的累加归并,然后再计算平均值。
例如: AVG归并就无法直接进行分片归并,需要转化成COUNT&SUM的累加归并,然后再计算平均值。
排序归并的流程如下图:
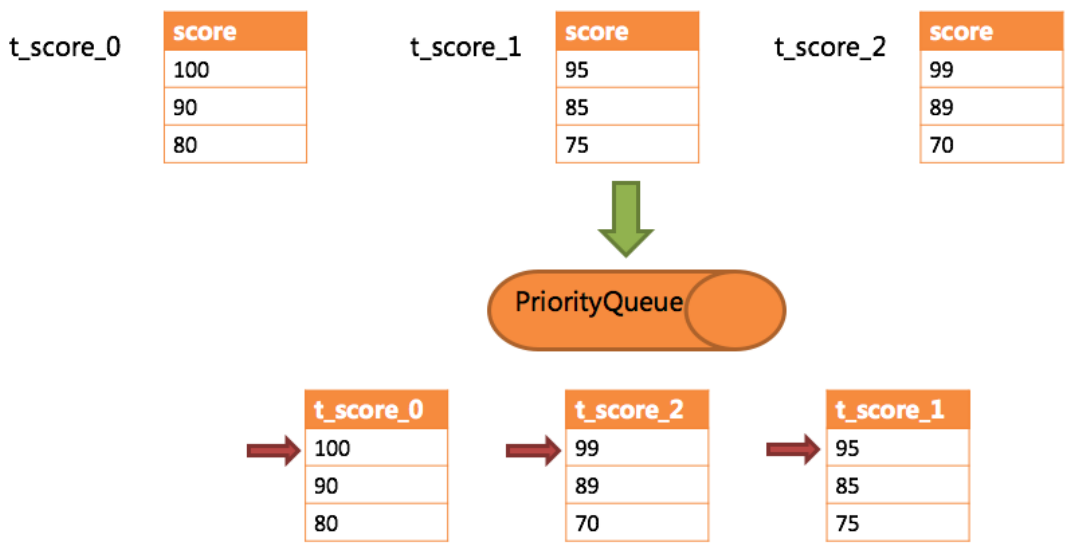 分布式主键
分布式主键
内置生成器支持:UUID、SNOWFLAKE,并抽离出分布式主键生成器的接口,方便用户自行实现自定义的自增主键生成器。
UUID
采用UUID.randomUUID()的方式产生唯一且不重复的分布式主键。最终生成一个字符串类型的主键。缺点是生成的主键无序。
SNOWFLAKE
雪花算法,能够保证不同进程主键的不重复性,相同进程主键的有序性。二进制形式包含4部分,从高位到低位分表为:1bit符号位、41bit时间戳位、10bit工作进程位以及12bit序列号位。
- 符号位(1bit)
预留的符号位,恒为零。
- 时间戳位(41bit)
41位的时间戳可以容纳的毫秒数是2的41次幂,一年所使用的毫秒数是:365 * 24 * 60 * 60 * 1000 Math.pow(2, 41) / (365 * 24 * 60 * 60 * 1000L) = 69.73年不重复;
- 工作进程位(10bit)
该标志在Java进程内是唯一的,如果是分布式应用部署应保证每个工作进程的id是不同的。该值默认为0,可通过属性设置。
- 序列号位(12bit)
该序列是用来在同一个毫秒内生成不同的ID。如果在这个毫秒内生成的数量超过4096(2的12次幂),那么生成器会等待到下个毫秒继续生成。

优点:
-
毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
-
不依赖第三方组件,稳定性高,生成ID的性能也非常高。
-
可以根据自身业务特性分配bit位,非常灵活
缺点:
- 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复。
四、源码环境安装
将配套资料中的源码包导入到IDEA后,就可以执行指令mvn clean install -Dmaven.test.skip=true -Dmaven.javadoc.skip=true来完成编译。
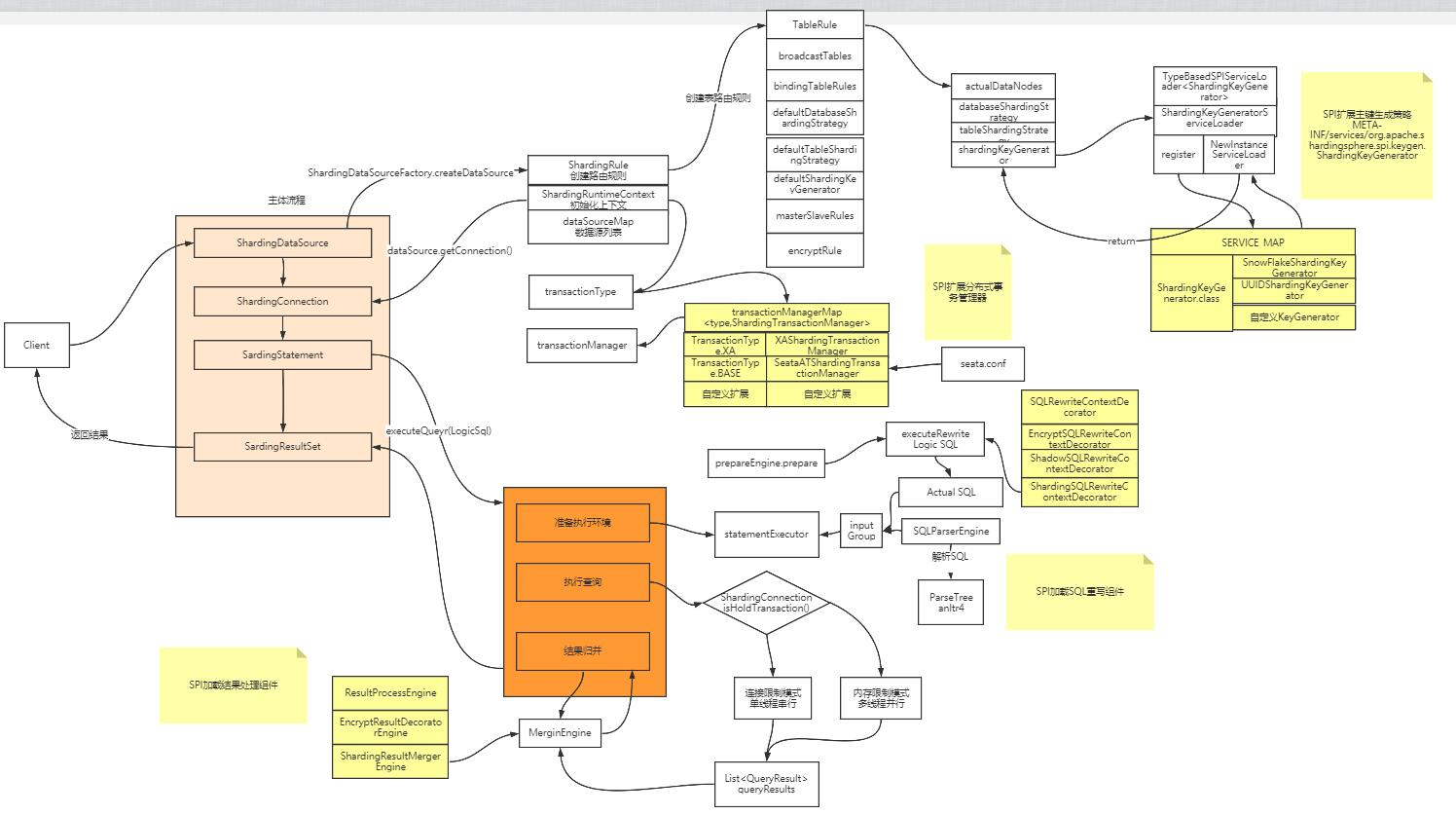
然后我们的源码调试从ShardingJDBCDemo.java这个测试类开始。这个示例是重现我们之前示例application02.properties中配置的分库分表规则。
ShardingSphere的分库分表功能,不管是JDBC还是Proxy,最终都是会转化成Java API的配置方式。具体参见官网的配置说明https://shardingsphere.apache.org/document/legacy/4.x/document/cn/manual/sharding-jdbc/configuration/config-java/
源码流程图:
五、ShardingSphere的SPI扩展点
ShardingSphere为了兼容更多的应用场景,在源码中保留了大量的SPI扩展点。所以在看源码之前,需要对JAVA的SPI机制有足够的了解。
1、SPI机制
SPI的全名为:Service Provider Interface。在java.util.ServiceLoader的文档里有比较详细的介绍。
简单的总结下 Java SPI 机制的思想。我们系统里抽象的各个模块,往往有很多不同的实现方案,比如日志模块的方案,xml解析模块、jdbc模块的方案等。面向的对象的设计里,我们一般推荐模块之间基于接口编程,模块之间不对实现类进行硬编码。
一旦代码里涉及具体的实现类,就违反了可拔插的原则,如果需要替换一种实现,就需要修改代码。为了实现在模块装配的时候能不在程序里动态指明,这就需要一种服务发现机制。
Java SPI 就是提供这样的一个机制:为某个接口寻找服务实现的机制。有点类似IOC的思想,就是将装配的控制权移到程序之外,在模块化设计中这个机制尤其重要
Java SPI 的具体约定为:当服务的提供者,提供了服务接口的一种实现之后,在jar包的META-INF/services/目录里同时创建一个以服务接口命名的文件。该文件里就是实现该服务接口的具体实现类。
而当外部程序装配这个模块的时候,就能通过该jar包META-INF/services/里的配置文件找到具体的实现类名,并装载实例化,完成模块的注入。
基于这样一个约定就能很好的找到服务接口的实现类,而不需要再代码里制定。jdk提供服务实现查找的一个工具类:java.util.ServiceLoader。
2、ShardingSphere中的SPI扩展点
ShardingSphere的开发思想是对源码中主体流程封闭,而对SPI开放。在配套的官方文档《shardingsphere_docs_cn.pdf》的开发者手册部分详细列出了ShardingSphere的所有SPI扩展点。
3、实现自定义主键生成策略
使用ShardingSphere提供的SPI扩展点,实现自定义分布式主键生成策略。
六、ShardingProxy使用
ShardingProxy的功能同样是分库分表,但是他是一个独立部署的服务端,提供统一的数据库代理服务。注意,ShardingProxy目前只支持MySQL和PostgreSQL。并且,客户端连接ShardingProxy时,最好使用MySQL的JDBC客户端。下面我们来部署一个ShardingProxy服务。
1、ShardingProxy部署
ShardingProxy在windows和Linux上提供了一套统一的部署发布包。我们可以从ShardingSphere官网下载4.1.1版本的ShardingProxy发布包apache-shardingsphere-4.1.1-sharding-proxy-bin.tar.gz,解压到本地目录。配套资料中已经提供
注意不要有中文路径
首先,我们需要把MySQL的JDBC驱动包mysql-connector-java-8.0.20.jar手动复制到ShardingProxy的lib目录下。ShardingProxy默认只附带了PostgreSQL的JDBC驱动包,而不包含MySQL的JDBC驱动包。
然后,我们需要到conf目录下,修改server.yaml,将配置文件中的authentication和props两段配置的注释打开。
authentication:
users:
root:
password: root
sharding:
password: sharding
authorizedSchemas: sharding_db
props:
max.connections.size.per.query: 1
acceptor.size: 16 # The default value is available processors count * 2.
executor.size: 16 # Infinite by default.
proxy.frontend.flush.threshold: 128 # The default value is 128.
# LOCAL: Proxy will run with LOCAL transaction.
# XA: Proxy will run with XA transaction.
# BASE: Proxy will run with B.A.S.E transaction.
proxy.transaction.type: LOCAL
proxy.opentracing.enabled: false
proxy.hint.enabled: false
query.with.cipher.column: true
sql.show: false
allow.range.query.with.inline.sharding: false
然后,我们修改conf目录下的config-sharding.yaml,这个配置文件就是shardingProxy关于分库分表部分的配置。整个配置和之前我们使用ShardingJDBC时的配置大致相同,我们在最下面按照自己的数据库环境增加以下配置:
schemaName: sharding_db
dataSources:
m1:
url: jdbc:mysql://localhost:3306/userdb?serverTimezone=GMT%2B8&useSSL=false
username: root
password: root
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
shardingRule:
tables:
course:
actualDataNodes: m1.course_$->{1..2}
tableStrategy:
inline:
shardingColumn: cid
algorithmExpression: course_$->{cid%2+1}
keyGenerator:
type: SNOWFLAKE
column: cid
这一段就是按照我们之前的application01.properties文件中的规则配置的。可以看到,整个配置其实是大同小异的。
然后,还一个小问题要注意,我们进入ShardingProxy的Lib目录,里面会有些jar包因为名字太长了,导致有些文件的后缀被截断了,我们要手动把他们的文件后缀给修改过来。
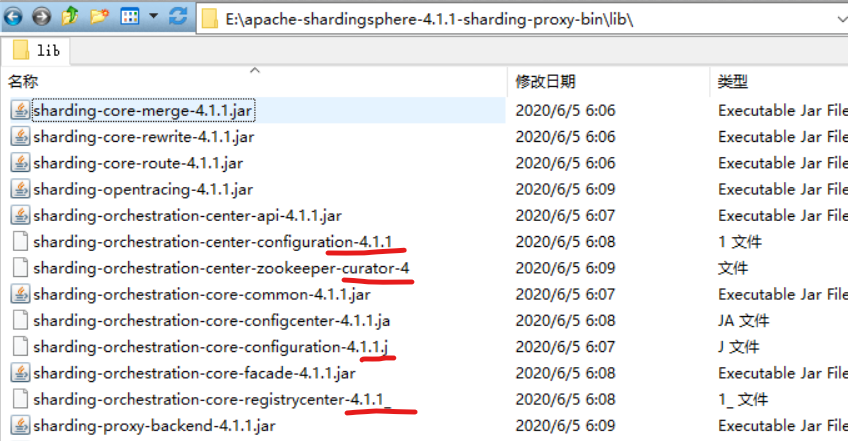
然后,我们就可以启动ShardingProxy的服务了。启动脚本在bin目录下。其中,windows平台对应的脚本是start.bat,Linux平台对应的脚本是start.sh和stop.sh
启动时,我们可以直接运行start.bat脚本,这时候,ShardingProxy默认占用的是3307端口。为了不跟我们之前搭建的多个MySQL服务端口冲突,我们定制下启动端口,改为3316端口。
start.bat 3316
为什么windows平台上没有stop.bat呢?因为start.bat会独占一个命令行窗口,把命令行窗口关闭,就停止了ShardingProxy的服务。
启动完成后,可以看到几行关键的日志标识服务启动成功了。
[INFO ] 10:46:53.930 [main] c.a.d.xa.XATransactionalResource - resource-1-m1: refreshed XAResource
[INFO ] 10:46:54.580 [main] ShardingSphere-metadata - Loading 1 logic tables' meta data.
[INFO ] 10:46:54.717 [main] ShardingSphere-metadata - Loading 8 tables' meta data.
[INFO ] 10:46:56.953 [nioEventLoopGroup-2-1] i.n.handler.logging.LoggingHandler - [id: 0xc90e0eef] REGISTERED
[INFO ] 10:46:56.958 [nioEventLoopGroup-2-1] i.n.handler.logging.LoggingHandler - [id: 0xc90e0eef] BIND: 0.0.0.0/0.0.0.0:3316
[INFO ] 10:46:56.960 [nioEventLoopGroup-2-1] i.n.handler.logging.LoggingHandler - [id: 0xc90e0eef, L:/0:0:0:0:0:0:0:0:3316] ACTIVE
2、ShardingProxy使用
这样,我们就可以像连接一个标准MySQL服务一样连接ShardingProxy了。
D:\dev-hook\mysql-8.0.20-winx64\bin>mysql.exe -P3316 -uroot -p
Enter password: ****
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1
Server version: 8.0.20-Sharding-Proxy 4.1.0
Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases;
+-------------+
| Database |
+-------------+
| sharding_db |
+-------------+
1 row in set (0.03 sec)
mysql> use sharding_db
Database changed
mysql> show tables;
+--------------------+
| Tables_in_coursedb |
+--------------------+
| course |
| t_dict |
+--------------------+
2 rows in set (0.16 sec)
mysql> select * from course;
+--------------------+-------+---------+---------+
| cid | cname | user_id | cstatus |
+--------------------+-------+---------+---------+
| 545730330389118976 | java | 1001 | 1 |
| 545730330804355072 | java | 1001 | 1 |
| 545730330842103808 | java | 1001 | 1 |
| 545730330879852544 | java | 1001 | 1 |
| 545730330917601280 | java | 1001 | 1 |
+--------------------+-------+---------+---------+
5 rows in set (0.08 sec)
之前在ShardingJDBC部分完成了的其他几种分库分表策略以及读写分离策略,就请大家自行验证了。
3、ShardingProxy的服务治理
从ShardingProxy的server.yaml中看到,ShardingProxy还支持非常多的服务治理功能。在server.yaml配置文件中的orchestration部分属性就演示了如何将ShardingProxy注册到Zookeeper当中。
orchestration:
orchestration_ds:
orchestrationType: registry_center,config_center,distributed_lock_manager
instanceType: zookeeper
serverLists: localhost:2181
namespace: orchestration
props:
overwrite: false
retryIntervalMilliseconds: 500
timeToLiveSeconds: 60
maxRetries: 3
operationTimeoutMilliseconds: 500
ShardingSphere在服务治理这一块主要有两个部分:
一是数据接入以及弹性伸缩。简单理解就是把MySQL或者其他数据源的数据快速迁移进ShardingSphere的分片库中。并且能够快速的对已有的ShardingShere分片库进行扩容以及减配。这一块由ShardingSphere-scaling产品来提供支持。只是这个功能在目前的4.1.1版本中,还处于Alpha测试阶段。
另一方面,ShardingSphere支持将复杂的分库分表配置上传到统一的注册中心中集中管理。目前支持的注册中心有Zookeeper和Etcd。而ShardingSphere也提供了SPI扩展接口,可以快速接入Nacos、Apollo等注册中心。在ShardingProxy的server.yaml中我们已经看到了这一部分的配置示例。
另外,ShardingSphere针对他的这些生态功能,提供了一个ShardingSphere-UI产品来提供页面支持。ShardingSphere-UI是针对整个ShardingSphere的一个简单有用的Web管理控制台。它用于帮助用户更简单的使用ShardingSphere的相关功能。目前提供注册中心管理、动态配置管理、数据库编排管理等功能。
配套资料中也收集了ShardingSphere-UI的最新版本5.0.0-alpha版的运行包。解压后执行其中的start.bat就可以直接运行。
4、Shardingproxy的其他功能
影子库
这部分功能主要是用于进行压测的。通过给生产环境上的关键数据库表配置一个影子库,就可以将写往生产环境的数据全部转为写入影子库中,而影子库通常会配置成跟生产环境在同一个库,这样就可以在生产环境上直接进行压力测试,而不会影响生产环境的数据。
在conf/config-shadow.yaml中有配置影子库的示例。其中最核心的就是下面的shadowRule这一部分。
#shadowRule:
# column: shadow
# shadowMappings:
# 绑定shadow_ds为ds的影子库
# ds: shadow_ds
数据加密
在conf/config-encrypt.yaml中还演示了ShardingProxy的另一个功能,数据加密。默认集成了AES对称加密和MD5加密。还可以通过SPI机制自行扩展更多的加密算法。
5、ShardingProxy的SPI扩展
上一部分提到了ShardingSphere保留了大量的SPI扩展接口,对主流程封闭、对SPI开放。这在ShardingJDBC中还体现不出太大的作用,但是在ShardingProxy中就能极大程度提高服务的灵活性了。
在ShardingProxy中,只需要将自定义的扩展功能按照SPI机制的要求打成jar包,就可以直接把jar包放入lib目录,然后就配置使用了。
例如如果想要扩展一个新的主键生成策略,只需要自己开发一个主键生成类
import org.apache.shardingsphere.spi.keygen.ShardingKeyGenerator;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicLong;
public final class MykeyGenerator implements ShardingKeyGenerator {
private AtomicLong atom = new AtomicLong(0);
private Properties properties = new Properties();
public synchronized Comparable<?> generateKey() {
//读取了一个自定义属性
String prefix = properties.getProperty("mykey-offset", "100");
LocalDateTime ldt = LocalDateTime.now();
String timestampS = DateTimeFormatter.ofPattern("HHmmssSSS").format(ldt);
return Long.parseLong(""+prefix+timestampS+atom.incrementAndGet());
}
//扩展算法的类型
public String getType() {
return "MYKEY";
}
public Properties getProperties() {
return this.properties;
}
public void setProperties(Properties properties) {
this.properties = properties;
}
}
然后增加一个META-INF\services\org.apache.shardingsphere.spi.keygen.ShardingKeyGenerator文件,并在文件中写明自己的实现类。com.roy.shardingDemo.spiextention.MykeyGenerator 将扩展类和这个SPI服务文件一起打成jar包,就可以直接放到ShardingProxy的lib目录下。
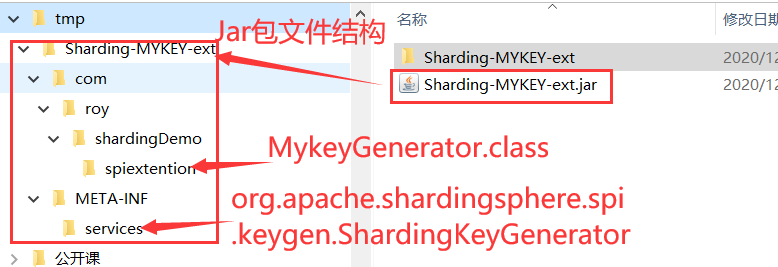
接下来就可以在config-sharding.yaml中以类似下面这种配置方式引入了。
shardingRule:
tables:
course:
actualDataNodes: m1.course_$->{1..2}
tableStrategy:
inline:
shardingColumn: cid
algorithmExpression: course_$->{cid%2+1}
keyGenerator:
# type: SNOWFLAKE
type: MYKEY # 自定义的主键生成器
column: cid
然后我们可以启动ShardingProxy,试试我们自定义的主键生成器。
mysql> select * from course;
+--------------------+-------+---------+---------+
| cid | cname | user_id | cstatus |
+--------------------+-------+---------+---------+
| 222 | java2 | 1002 | 1 |
| 545730330389118976 | java | 1001 | 1 |
| 545730330804355072 | java | 1001 | 1 |
| 545730330842103808 | java | 1001 | 1 |
| 545730330879852544 | java | 1001 | 1 |
| 545730330917601280 | java | 1001 | 1 |
+--------------------+-------+---------+---------+
6 rows in set (0.01 sec)
mysql> insert into course(cname,user_id,cstatus) values ('java2',1002,'1');
Query OK, 1 row affected (0.11 sec)
mysql> insert into course(cname,user_id,cstatus) values ('java2',1003,'1');
Query OK, 1 row affected (0.01 sec)
mysql> select * from course;
+--------------------+-------+---------+---------+
| cid | cname | user_id | cstatus |
+--------------------+-------+---------+---------+
| 222 | java2 | 1002 | 1 |
| 1001509178012 | java2 | 1003 | 1 |
| 545730330389118976 | java | 1001 | 1 |
| 545730330804355072 | java | 1001 | 1 |
| 545730330842103808 | java | 1001 | 1 |
| 545730330879852544 | java | 1001 | 1 |
| 545730330917601280 | java | 1001 | 1 |
| 1001509119631 | java2 | 1002 | 1 |
+--------------------+-------+---------+---------+
8 rows in set (0.01 sec)
从结果可以看到,插入的两条记录,自动生成的CID分别为1001509178012、1001509119631。这样我们就很快的完成了一个自定义的主键生成策略。
7、ShardingSphere总结
我们现在已经学完了ShardingSphere除了Sharding-SideCar以外的所有产品了,整个sharding + proxy的所有这些功能,本质上其实都只解决了一个问题,就是单机数据库容量的问题。在软件层面对硬件资源进行管理,从而便于对数据库的横向扩展。
但是,我们也要意识到他带来的很多问题。
例如对业务的侵入大。业务系统写的SQL将不再是纯粹的能在服务器上运行的SQL了,对大量跨维度的JOIN、聚合、子查询、排序等功能在业务上很难进行验证。这必然会弱化数据库的功能。
并且,使用ShardingSphere管理后,数据库之间变成了结合非常紧密的依赖关系,对整个集群的扩容也会带来相当大的难度。
另外,ShardingSphere这种方式实际上将原本由业务管理SQL的工作方式,转化成了由业务管理逻辑SQL,而运维管理实际SQL的混合工作模式,再加上一大堆服务的引入,整个服务运维的维护工作量以及工作难度也上升了非常多。
当然,相信随着ShardingSphere后续版本的不断升级优化,这些问题都会得到不同程度的改善。
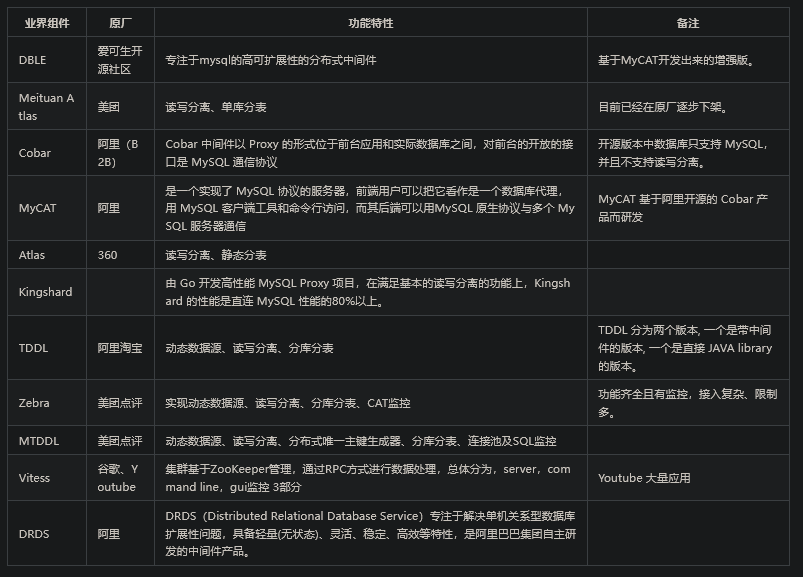
对比其他产品