ShardingSphere-jdbc实战
前言
ShardingSphere-JDBC 是 Apache ShardingSphere 的第一个产品,现已更名为 ShardingSphere。 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
在学习Sharding-JDBC分库分表之前,我们有必要先了解分库分表的一些知识。
分库分表
一般的机器(4核16G),单库的MySQL并发(QPS+TPS)超过了2k,系统基本就完蛋了。最好是并发量控制在1k左右。这里就引出一个问题,为什么要分库分表?
分库分表目的:解决高并发,和数据量大的问题。
分库分表的维度有两个:垂直和水平
- 水平拆分 :把一个库或者一个表的数据,按照时间,地区或者某个业务键划分到不同的表或者不同的库中,拆分过后每个库表结构是一致的
- 垂直拆分 :把一个大表拆分成多个小表,每个库表的结构都不一样,从而达到冷热字段拆分,也可以按照业务进行垂直分库,如分成用户库,订单库,拆分过后每个库表都只包含部分字段
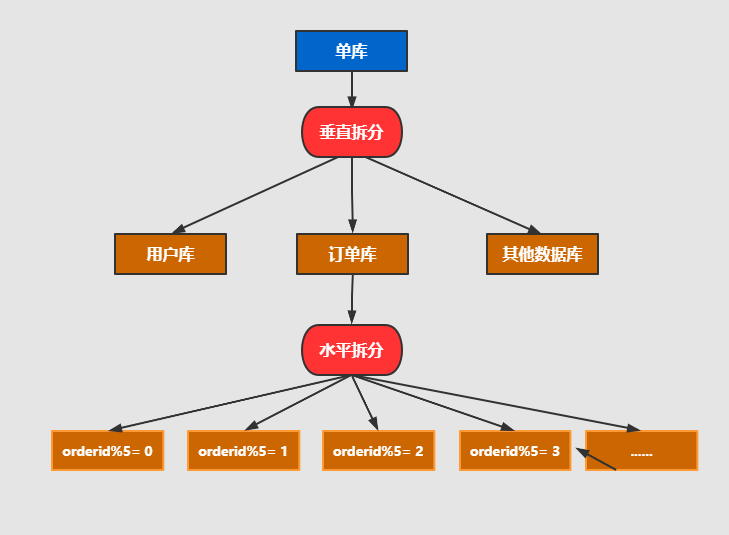
一般公司都会按照上图的模式进行拆分,先按照业务进行垂直分库,然后再根据需要分表的库进行水平拆分。
核心概念
1、分片
一般我们在提到分库分表的时候,大多是以水平切分模式(水平分库、分表)为基础来说的,而分片的可以理解为用于数据库(表)水平拆分的数据库字段,这个字段就叫做分片键,SQL 中如果无分片字段,将执行全路由,性能较差
2、逻辑表or真实表
逻辑表非真实存在的表,如一个订单表order,select * from order,这里的order指的就是逻辑表,并不存在,如果我们将order拆分成order_1,order_2…order_n,其中order_n才是真实存在的物理表
3、数据节点
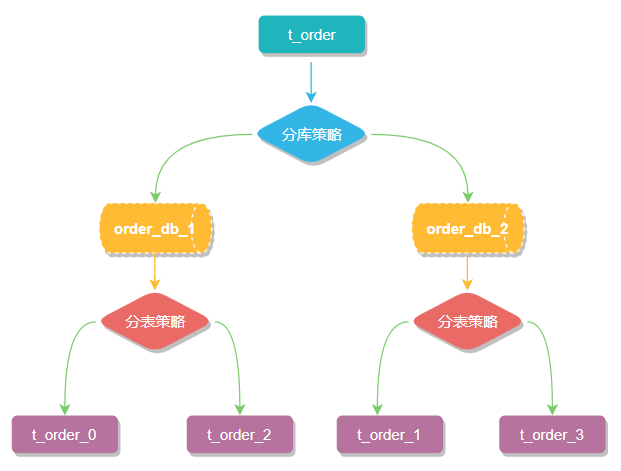
数据分片的最小单元,它由数据源名称和数据表组成,例如上图中 order_db_1.t_order_0就表示一个数据节点。
4、分布式主键
数据分⽚后,不同数据节点⽣成全局唯⼀主键是⾮常棘⼿的问题,同⼀个逻辑表(t_order)内的不同真实表(t_order_n)之间的⾃增键由于⽆法互相感知而产⽣重复主键,而sharding 内置了UUID、SNOWFLAKE 两种分布式主键⽣成器,默认使⽤雪花算法(snowflake)⽣成64bit的⻓整型数据。不仅如此它还抽离出分布式主键⽣成器的接口,⽅便我们实现⾃定义的⾃增主键⽣成算法。
5、分片策略&分片算法
分片策略只是抽象出的概念,它是由分片算法和分片健组合而成,分片算法做具体的数据分片逻辑。从执行 SQL 的角度来看,分库分表可以看作是一种路由机制,把 SQL 语句路由到我们期望的数据库或数据表中并获取数据,分片算法可以理解成一种路由规则。
分片策略:
标准分片策略(StandardShardingStrategy)
仅支持单分片键,可提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。
复合分片策略(ComplexShardingStrategy)
与标准分片一致,但支持多分片键
行表达式分片策略(InlineShardingStrategy)
使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键
Hint分片策略 (HintShardingStrategy)
强制路由到某库某表,此策略无需配置分片键,但需要通过外部 HintManager 指定分库、分表信息
不分片策略(NoneShardingStrategy)
分片算法:
精确分片算法(PreciseShardingAlgorithm)
用于处理使用单一键作为分片键的=与IN进行分片的场景。需要配合StandardShardingStrategy使用,且是Standard策略必须算法。
范围分片算法(RangeShardingAlgorithm)
用于处理使用单一键作为分片键的BETWEEN AND、>、<、>=、<=进行分片的场景。需要配合StandardShardingStrategy使用,是Standard策略可选算法。
复合分片算法(ComplexKeysShardingAlgorithm)
用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合ComplexShardingStrategy使用。
Hint分片算法(HintShardingAlgorithm)
用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用。
值得注意的是,sharding只提供了算法的接口,具体算法的实现还需要我们自己去实现。
列举了怎么多的分片策略,分片算法,大家一定很懵,下面来看一些具体的案例
配置
sharding提供了4种配置方式,java API、YAML、Spring Boot Starter、Spring命名空间,用于不同的使用场景。 通过配置,应用开发者可以灵活的使用数据分片、读写分离、数据加密、影子库等功能,并且能够叠加使用。
下面我们通过YAML和java API两种方式来测试
ShardingSphere实战操作
1 创建数据库

- 首先在navicat中,创建4个库,分别是:ds_0,ds_1,ds_2,ds_3 ;
- 在 doc 文档中 ,分别在 4个库里执行 init.sql 语句 ,执行后效果见上图 。
我们还是以订单表举例 ,当用户创建一条记录 , 会生成如下记录:
- 订单基础表 : t_ent_order 表 , 1条记录 ;
- 订单详情表: t_ent_order_detail ,1条记录;
- 订单明细表: t_ent_order_item , 多条记录 。
那我们使用怎样的分库分表策略呢 ?
- 订单基础表 t_ent_order 按照 ent_id (企业编号) 分库 ,订单详情表保持一致;
- 订单明细表 t_ent_order_item 按照 ent_id (企业编号) 分库 , 同时也要分表 。
2 使用shardingsphere jdbc
首先配置依赖:
<!-- shardingsphere jdbc start -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
<!-- shardingsphere jdbc end -->
重点强调, 原来分库分表之前, 很多 springboot 工程依赖 druid ,必须要删除如下的依赖:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
</dependency>
在配置文件中配置如下:
shardingsphere:
datasource:
enabled: true
names: ds0,ds1,ds2,ds3
ds0:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/ds_0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT%2B8&useTimezone=true
username: root
password: ilxw
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/ds_1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT%2B8&useTimezone=true
username: root
password: ilxw
ds2:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/ds_2?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT%2B8&useTimezone=true
username: root
password: ilxw
ds3:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/ds_3?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT%2B8&useTimezone=true
username: root
password: ilxw
props:
# 日志显示 SQL
sql.show: true
sharding:
tables:
# 订单表基础表
t_ent_order:
# 真实表
actualDataNodes: ds$->{0..3}.t_ent_order
# 分库策略
databaseStrategy:
complex:
sharding-columns: id,ent_id
algorithm-class-name: com.courage.shardingsphere.jdbc.service.sharding.HashSlotAlgorithm
# 分表策略
tableStrategy:
none:
# 订单条目表
t_ent_order_item:
# 真实表
actualDataNodes: ds$->{0..3}.t_ent_order_item_$->{0..7}
# 分库策略
databaseStrategy:
complex:
sharding-columns: id,ent_id
algorithm-class-name: com.courage.shardingsphere.jdbc.service.sharding.HashSlotAlgorithm
# 分表策略
tableStrategy:
complex:
sharding-columns: id,ent_id
algorithm-class-name: com.courage.shardingsphere.jdbc.service.sharding.HashSlotAlgorithm
# 订单详情表
t_ent_order_detail:
# 真实表
actualDataNodes: ds$->{0..3}.t_ent_order_detail
# 分库策略
databaseStrategy:
complex:
sharding-columns: id,ent_id
algorithm-class-name: com.courage.shardingsphere.jdbc.service.sharding.HashSlotAlgorithm
# 分表策略
tableStrategy:
complex:
sharding-columns: id,ent_id
algorithm-class-name: com.courage.shardingsphere.jdbc.service.sharding.HashSlotAlgorithm
bindingTables:
- t_ent_order,t_ent_order_detail
配置很简单,需要配置如下几点:
-
配置数据源,上面配置数据源是: ds0, ds1 , ds2 , ds3 ;
-
配置打印日志,也就是:sql.show ,在测试环境建议打开 ,便于调试;
-
配置哪些表需要分库分表 ,在shardingsphere.datasource.sharding.tables 节点下面配置。

标红的是分库算法 ,下面的分表算法也是一样的。
3 复合分片算法
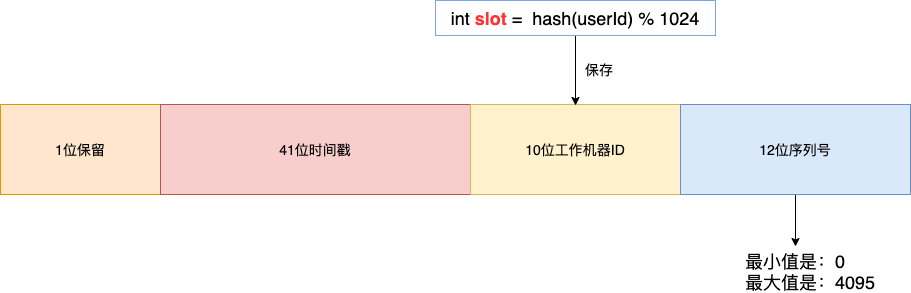
假设现在需要将订单表平均拆分到4个分库 shard0 ,shard1 ,shard2 ,shard3 。首先将 [0-1023] 平均分为4个区段:[0-255],[256-511],[512-767],[768-1023],然后对字符串(或子串,由用户自定义)做 hash, hash 结果对1024取模,最终得出的结果 slot 落入哪个区段,便路由到哪个分库。

路由算法 ,可以和 雪花算法 天然融合在一起, 订单 order_id 使用雪花算法,我们可以将 slot 的值保存在 10位工作机器ID 里。

通过订单 order_id 可以反查出 slot , 就可以定位该用户的订单数据存储在哪个分区里。
Integer getWorkerId(Long orderId) { Long workerId = (orderId >> 12) & 0x03ff; return workerId.intValue(); }接下来,我们看下分库分表算法的 JAVA 实现 ,因为我们需要按照主键 ID ,还有用户ID 来查询订单信息,那么我们必须实现复合分片 , 也就是实现 ComplexKeysShardingAlgorithm 类。

4 ID 生成器

- 查询本地内存,判定是否可以从本地队列中获取 currentTime , seq 两个参数 ,若存在,直接组装;
- 若不存在,调用 redis 的 INCRBY 命令 ,这里需要传递一个步长值,便于放一篇数据到本地内存里;
- 将数据回写到本地内存 ;
- 重新查询本地内存,本地队列中获取 currentTime , seq 两个参数 ,组装最后的结果,返回给生成器 。
源码地址:https://github.com/makemyownlife/shardingsphere-jdbc-demo