阿里QA导读:算法本身,它只是一个公式或者是一个解决方案,它只有真正的应用到具体的工业场景中,才真正发挥了它的价值,才能判断它在这个场景的效果的优劣。在互联网领域,算法应用的最好的莫过于推荐的场景,包括商品、图书、音乐、视频、新闻、电影等等。因此,本文会以推荐算法展开介绍。
目录
推荐算法的种类
-
基于内容的推荐
基于内容的推荐是建立在物品的内容信息上作出推荐的,不需要依据用户对物品的评价意见,更多地需要用机 器学习的方法从关于内容的特征描述的事例中得到用户的兴趣资料。因此,基于内容的推荐常常需要通过自然语言处理NLP技术对用户的行为数据进行分析,从而抽象出内容的共性,然后根据这些共性进行推荐。例如,某用户看了N部电影,我们可以从电影的标题、简介、演员表、评价中抽象出这些电影的共性,然后再给用户推荐相关的电影。
-
协同过滤推荐
基协同过滤本质上是利用事务之间的相似性,推荐与主体相似的物品或者推荐相似用户偏好的物品来完成推荐。因此,协同过滤推荐分为三种类型:一种是基于用户的协同过滤推荐,一种是基于物品的协同过滤推荐,一种是基于模型的协同过滤推荐。
-
基于关联规则的推荐
基于关联规则的推荐以关联规则为基础,把用户行为的物品作为规则头,规则体为推荐对象。关联规则挖掘可以发现不同商品在销售过程中的相关性,在零售业中已经得到了成功的应用。关联规则就是在一个交易数据库中统计购买了商品集X的交易中有多大比例的交易同时购买了商品集Y,其直观的意义就是用户在购买某些商品的时候有多大倾向去购买另外一些商品。比如购买牛奶的同时很多人会同时购买面包。
-
基于知识推荐
基于知识的推荐在某种程度是可以看成是一种推理技术,它不是建立在用户需要和偏好基础上推荐的。基于知识的方法因它们所用的功能知识不同而有明显区别。效用知识是一种关于一个物品如何满足某一特定用户的知识,因此能解释需要和推荐的关系,所以用户资料可以是任何能支持推理的知识结构,它可以是用户已经规范化的查询,也可以是一个更详细的用户需要的表示。
-
组合推荐
组合推荐也叫混合推荐。顾名思义,组合推荐就是将各种推荐算法进行组合,集各家之长。通过多个推荐算法的集合,弥补各自的缺点,集合各自的优点,往往能得到一个更好的推荐算法,但是也会提高算法的复杂度。在实际应用中,内容推荐和协同过滤推荐的组合最为常用。
推荐算法测试方法
测试推荐算法其实并不需要你去搞清楚算法到底是怎么计算的,因为算法通常只有优劣之分而没有对错之分,而对于推荐算法而言,结果是优还是劣,需要用户去评判。测试在这个过程中,应该着重保障3个环节的产出结果质量,分别是:离线数据的产出、实时数据的时效性、最终推荐结果是否满足业务需求。
-
离线数据质量测试
对于算法产出的数据,需要保障数据的质量和是否满足场景的要求,因此会从数据正确性和业务正确性两方面入手。
数据正确性
数据正确性是为了保证算法数据的正常产出,例如监控数据大小、数据产出时间、数据产出格式、数据依赖是否正确、主键是否唯一、字段值是否为空、字段值是否在一个期望值区间、表数据量的波动是否正常、字段值的平均值、最大最小值等等,这类策略属于纯数据测试。
业务正确性
一个算法应用于某个场景其产出的数据必须要满足该场景的业务需求。业务正确性的测试点完全取决于业务的场景需求,以及我们测试站在用户的角度思考出的用户体验性的测试点。
实时数据的时效性
一个好的推荐算法必定会考虑用户的实时行为,并通过对用户实时行为分析后给出实时推荐的数据,那么这个过程中,测试最需要保障的是用户的实时行为算法是不是实时采集到并处理了。
-
工程端结果质量
推荐结果的正确性
推荐结果的正确性的指标点,一般会和离线数据业务正确性的测试点相吻合。这个时候有同学会问,那既然离线数据已经保障了,为什么在工程端还要做一次测试呢?那是因为整个推荐系统的环节特别多,除了离线数据还有实时数据、还有排序系统、还有推荐系统里的一些处理逻辑,任何一个环节都可能引入问题,因此必须在推荐结果产出的最后一环做出保障。说到这里,有同学可能又会问,那既然在最后一环做了保障,为什么在离线数据环节还要测试呢?那是因为离线数据是推荐结果非常重要的输入,如果在离线数据产出时没有做好各种业务需求的把关,而是直接在最终推荐系统里做各种业务校验的话,很有可能最终满足需求的推荐结果个数不够,或者都被实时行为数据占领又或者被补全的数据占领,这对于推荐效果都是一个很大的损伤。
推荐系统的性能测试
在保障了算法的各种数据正确性和业务正确性的基础上,还需要保障推荐系统的性能。如果是一个新的场景,那么性能测试的数据需要根据场景请求造出来,如果是一个已经在线的场景,算法迭代上线那就会好办很多,直接拿到线上的请求作为性能压测的请求数据就可以。
那么除了以上的算法正确性相关的测试,对于算法的效果的优劣有什么测试手段么?答案肯定是有。下面介绍一些算法效果优劣的测试手段。
-
算法效果测试
算法效果测试的手段有ABtest、多样性、更新率、基尼系数,而一般算法都会用到的准确率和召回率以及AUC、DCG、NDCG这样的指标反而不适合作为推荐算法的指标,因为我们无法拿到用户确切的喜欢或者不喜欢的数据,即便花很大的代价用人工评测来完成也会带有很强的主观性。
ABtest
ABtest即将A算法和B算法进行线上用户真实行为的对比,前提是线上已经有一个稳定运行的算法了,它所作用的流量部分我们称之为基准桶,一般会拿出线上流量的5%-10%进行ABtest,我们称之为测试桶,每个算法作用5%的流量,一般会有一个基准桶和2个测试桶在线上测试。当其中一个测试桶在线上运行一段时间,各项指标都显著优于基准桶的时候会进行算法切换,并且以一个阶梯递进的方式切换。
多样性
多样性反映了推荐内容的丰富程度,多样性的好坏影响用户的体验,总体来讲用户更希望看到多样性不错的推荐内容。无论是推荐商品、电影、新闻抑或是音乐,能尽可能的推荐用户喜欢的不同的种类的数据,对算法上线后的商业指标肯定能起到正向的作用。但是多样性也不是越多越好,要考虑用户实际的喜好偏向,对于相同权重的类目可以适当增加多样性,但是不同权重的自然以用户喜爱度为重,这个是算法需要找到的一个平衡。
更新率
用户的行为是不断变化的,一个好的算法的推荐内容必定会根据用户行为的变化而变化。这一指标更多的是应用于离线数据上,对于用户的历史行为会有一定的衰减,并且增加用户近期行为的权重,从而达到推荐结果的不断更新。更新率一定程度上是推荐结果“新颖度”的一种量化。
假设两个推荐集合,其中一个作为参照对象,推荐的总次数(或推荐对象总个数)为
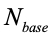
,实验对象于参照对象有不同的次数(或推荐对象个数)累计为VN,则更新率公式描述如下:
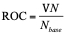
-
推荐算法测试流程
推荐算法测试的流程要根据不同的情况采用不同的策略,一般分以下3种情况:
全新场景上线
对于一个全新的场景,一个算法要上线,必须要经过严谨的全流程测试,包括离线的数据质量测试(数据正确性、业务正确性)、实时数据时效性测试、工程端结果质量保障(推荐结果的正确性、推荐系统的性能测试)、算法的效果测试(多样性、更新率、基尼系数)。并且和传统的功能测试一样,测试也是在需求阶段就介入、然后经过日常、预发测试,最后再进行线上质量监控,整个测试流程如下:

算法迭代ABtest
算法迭代ABtest考虑到一方面算法的改动不会特别大,特别是对于主流程的正确性逻辑不会有什么变动;另一方面考虑到ABtest的线上流量比较小,通常是线上总流量的5%。为了保证算法能快速上线,测试会提供工程端的预发验收测试和性能压测的工具,供开发自测使用,预发验收和性能压测通过之后,算法即可上线ABtest,整个测试流程如下。
![]()

测试桶切换基准桶
一般算法在ABtest后都会下线,进行新一轮的优化然后再ABtest,周而复始。但是有一些优秀的算法经过优化之后,ABtest的各项商业指标明显优于线上基准桶的算法,就会切换线上基准桶。此时,我们要当做一个全新的场景全新的算法上线来看待,走全新场景上线的测试流程,如下:

总结
对于推荐场景来说,一旦哪个场景上线之后,它的需求基本是固定的,剩下的就是算法不断迭代优化的过程。因此,对于测试来说,重点要做的是对于新场景的需求分析,并将测试过程中的测试点沉淀下来,用脚本化、自动化、甚至是平台化的手段去实现。这样,对于已上线的场景,算法开发迭代算法完全可以自助验证,达到效率的指数级提升。