作者 | gongyouliu
编辑 | gongyouliu
我们在上面一篇文章中介绍了排序算法的一些基本概念和知识点。大家应该已经非常清楚排序算法可以解决什么问题,可以用在哪些推荐场景了。上一章也对排序算法做了一个简单的说明性介绍,从本章开始我们会花3章的篇幅来介绍具体的排序算法的实现原理。本章我们先介绍最简单、最没有机器学习含量的规则策略排序方法。
虽然规则策略算法没有用到复杂的机器学习模型,主要是基于人对业务的理解来定义的排序方法,但在某些场景(比如没有什么数据、需要满足一些运营目标等)是必要的一种方法。规则策略排序算法根据不同的业务场景可以有非常多的实现方案,下面我来介绍几种非常直接简单的实施方案。具体来说,我们会讲解随机打散排序、按序排列排序、得分归一化排序、匹配用户画像排序、代理算法排序及它们的混合使用的排序等6种规则策略排序算法。
本章的目的是给读者提供一些思路,大家也可以结合自己公司的具体业务来思考,看是否有更好、更有业务价值、更有特色的实现方案。
在讲解具体的排序策略之前,我们先假设我们已经有了k个召回结果,分别记为Recall_1、Recall_2、... 、Recall_k,我们的目标是利用规则策略排序算法来对这k个召回结果进行排序。

图1:k个召回结果
11.1 多种召回随机打散
这种排序方法是最简单的。就是将图1中k个召回结果合并,构成一个召回结果的合集,然后利用随机函数将这个并集随机打散,然后从打散的列表中取前面的topN作为最终的排序结果推荐给最终的用户,这个过程可以用公式表示如下:

这种实现方式非常简单高效,可以直接在推荐web服务端实现,不过个人还是建议实现一个排序算子或者排序服务,这样可以跟推荐web服务解耦(下面讲到的排序方法建议都采用类似的处理方式,要么做成一个算子,要么做成一个微服务,下面不再赘述)。为了让读者可以更直观地理解这种随机打散的排序方案,下面画一个示意图。
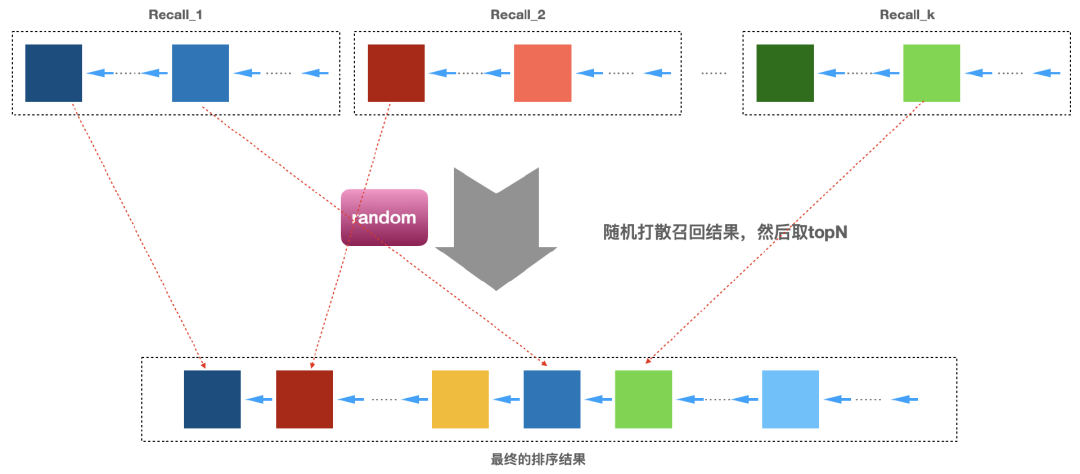
图2:随机打散的排序策略
这个排序策略非常简单粗暴。它的优势是非常简单,每次获得的结果都是不一样的,可以提供一定的新颖性和多样性,特别适合那种召回结果变化不大的召回场景(比如如果我们的推荐算法是T+1的,各个召回算法在前后两天的召回结果差别不大)。
这个排序算法最大的问题是没有一致性,也就是用户两次打开推荐系统获得的结果可能完全不一样。当然,这个缺点可以部分解决,可以先将排序结果缓存起来,设定一个缓存过期时间,在缓存过期时间内,每次用户请求推荐服务时,从缓存取推荐结果,这时推荐结果就一致了。
11.2 按照某种秩序排列
这种排序算法先将k种召回结果按照某种次序排定一个优先级,比如优先级排列如下( 意思是A的优先级大于B):
意思是A的优先级大于B):
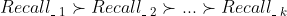
排定了优先级后,我们按照优先级的高低,依次从  、
、 、... 、
、... 、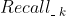 中选择1个来排列。第一轮选择好了之后,又开始按照
中选择1个来排列。第一轮选择好了之后,又开始按照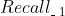 、
、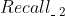 、... 、
、... 、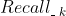 的顺序选择,直到选择的数量凑足N个就完成了,下面图3即说明了这个实现的过程。具体各个召回算法怎么排定优先级,可以有很多方式,比如基于业务的经验,基于运营需要,基于召回算法的效果(比如矩阵分解召回的效果好于item-based召回、item-based召回的效果好于热门召回)等。
的顺序选择,直到选择的数量凑足N个就完成了,下面图3即说明了这个实现的过程。具体各个召回算法怎么排定优先级,可以有很多方式,比如基于业务的经验,基于运营需要,基于召回算法的效果(比如矩阵分解召回的效果好于item-based召回、item-based召回的效果好于热门召回)等。
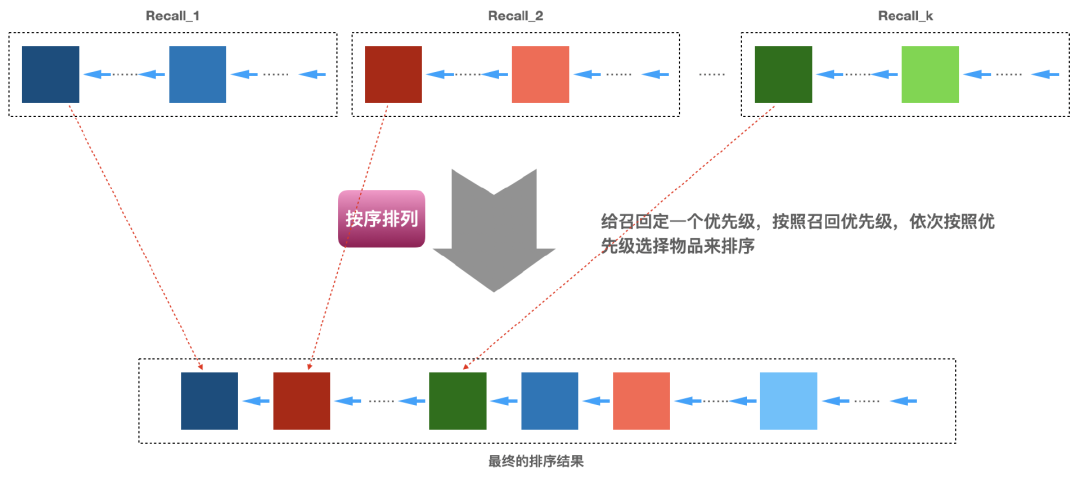
图3:按照某种秩序排列的排序策略
这种实现方案可以做一些调整和推广。上面每个召回算法只选择了1个结果进行排列,其实我们可以从每个召回算法中选择多个进行排序(可以选择固定数量的,比如每个召回选择2个;也可以选择不一样的,比如第一个召回选择3个,第二个召回选择2个等等,具体每个召回选择多少可以基于经验或者业务规则来定)。下面图4就是先从每个召回中选择topM个结果,按照顺序拼接起来,当第一轮选择结束后,然后又从第一个召回选择topM个,依次类推,当凑足了最终需要推荐的topN个推荐结果就停止(当然不会刚好凑足N个,这时当第一次超过N个就可以停止了)。上面多个召回列表中可能存在某些物品出现在多个召回中,只要在排序过程中将重复的剔除掉就好了。
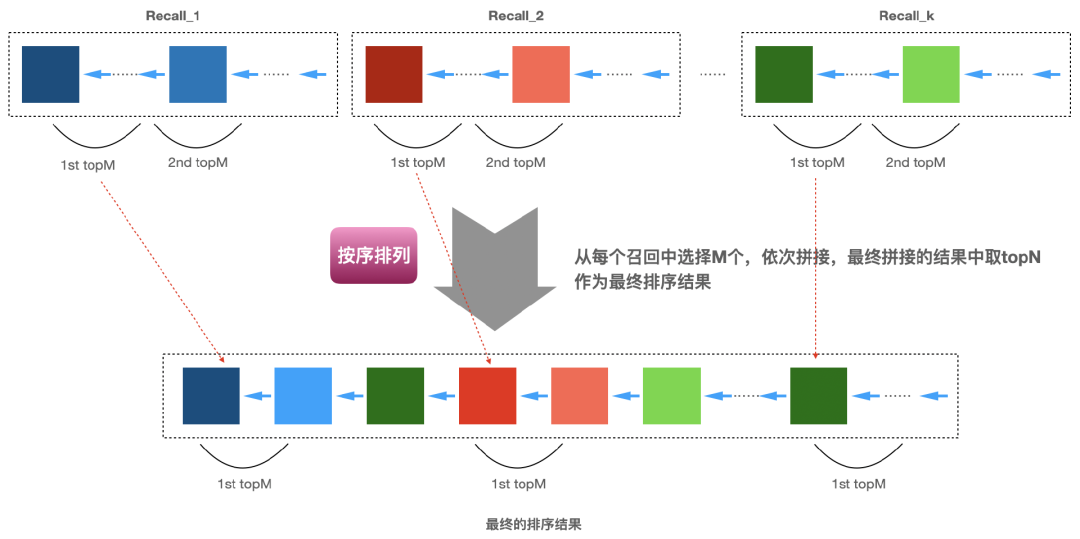
图4:每个召回算法选择topM,然后拼接获得最终的topN推荐结果
其实这个每组取topM的排序方法在现实生活中是可以找到原型的,我们的高考录取其实就是这种方式。每个省份的考生的成绩按照高低排列就是一个召回。清华北大每年进行招生它们是怎么做的呢?大家应该都知道清华北大在不同省份都有录取名额(当然不同省份名额不一样),这个招生过程的思路跟图4有异曲同工之妙。
一般各种召回算法的效果怎么样,我们是有一定的先验知识的,比如前面说到的矩阵分解召回的效果好于item-based召回,item-based召回的效果好于热门召回。有了这些先验知识,自然采用这种排序方式是一种不错的选择。虽然排在后面的召回算法的预期效果没有排在前面的召回好,但是它们是可以增加推荐的多样性和泛化能力的。
11.3 召回得分归一化排序
一般来说,某个召回算法本身是会对召回结果进行排序的,也就是每个召回结果中的物品是有序的,比如矩阵分解召回,每个召回的物品是有预测评分的,按照这个评分是可以给矩阵分解召回的物品按照得分高低排序的,实际召回时就是这么操作的。这个召回得分是可以被我们用于排序的,下面来讲解怎么使用。
如果我们的k个召回算法都有自己的排序,那么一种可行的综合排序方式是:先在每个召回算法内部将排序得分归一化到0到1之间,这样不同的召回算法的得分是在同一个区间范围(即0到1之间),那么它们之间就是可比较的了。我们可以将这些物品放在一起按照归一化的得分进行排序(这里存在一种情况,如果某个物品在多个召回算法中出现,那么就可以取它们的归一化得分的平均值),最终基于这个排序就可以选择归一化得分的topN作为最终的排序结果推荐给用户。下面图5可以非常直观地说明这个操作过程。

图5:每个召回算法先基于得分归一化,然后汇总排序取topN作为最终推荐结果
具体归一化的方法有很多,大家可以选择min-max归一化、分位数归一化或者正态分布归一化,下面分别简单介绍一下这3种归一化的方法:
min-max归一化
min-max归一化是通过求得该特征样本的最大值和最小值,采用如下公式来进行归一化,归一化后所有值分布在0-1之间。
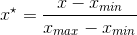
分位数归一化
分位数归一化是将该特征所有的值从小到大排序,假设一共有N个样本,某个值x排在第k位,那么我们用下式来表示x的新值。
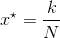
正态分布归一化
正态分布归一化是通过求出该特征所有样本值的均值![]() 和标准差
和标准差![]() ,再采用下式来进行归一化。
,再采用下式来进行归一化。
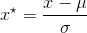
召回得分归一化排序方法比较简单,有一定的合理性。作者之前在做视频的排行榜推荐时就采用了这个方法。我们先分别计算电影、电视剧、综艺、动漫、少儿等各种类型节目的top100(按照播放量),然后按照本节介绍的方法归一化取最终的top100作为综合的热门推荐结果,这个结果中就会包含各种类型的视频了。
11.4 匹配用户画像排序
如果我们的物品是有标签的,那么我们基于用户行为是可以给用户构建用户兴趣画像的,这些物品的标签就可以作为用户的兴趣画像标签。例如,如果用户看了一些科幻、恐怖、美国的电影,那么就可以给该用户打上科幻、恐怖、美国的兴趣标签,代表了该用户对科幻、恐怖、美国相关题材的电影感兴趣。
用户对每个兴趣标签是可以有权重的,这个权重代表的就是用户对该标签的兴趣度,怎么计算这个权重,作者已经在第7章7.2.2.2节“利用用户兴趣标签召回”中进行了说明,读者可以去那篇文章看看,这里不再赘述。
有了用户的兴趣标签,每个物品也是有标签的,那么我们就可以计算每个物品与用户兴趣画像的相似得分,然后基于相似得分降序排列,取topN作为最终的推荐结果,这个过程可以很好地用下面的图6来说明。
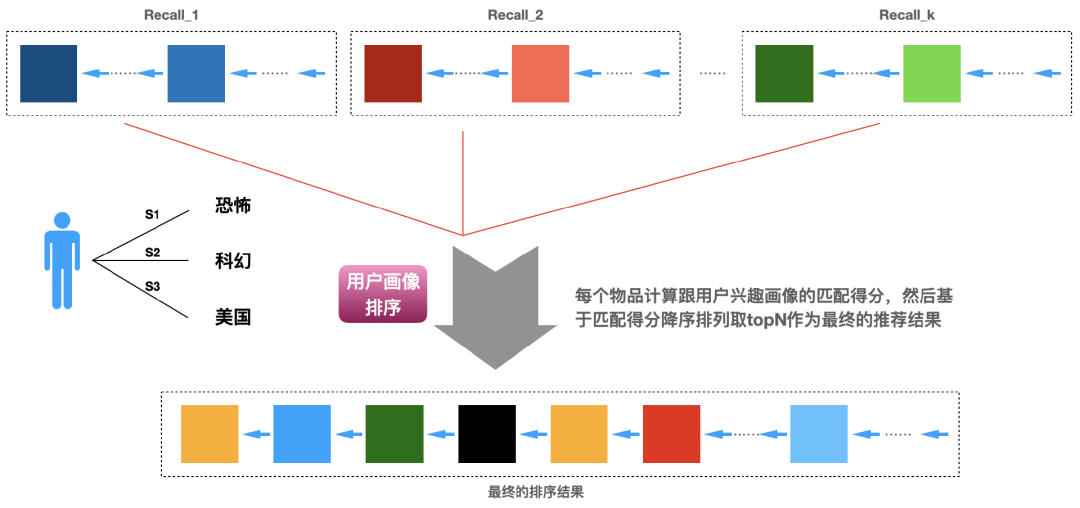
图6:基于物品跟用户画像的匹配度排序,然后取topN作为最终推荐
具体怎么计算用户U和某个物品W的标签匹配度,我们简单说明一下。首先我们先求出用户标签跟物品标签的交集。如果交集为空,那么它们的相似度为0。如果交集不为空,我们记交集为T,那么用户U的兴趣画像跟物品W的匹配度为 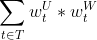 ,这里
,这里![]() 是用户U的兴趣标签t的权重,
是用户U的兴趣标签t的权重,![]() 是物品W的标签t的权重(如果物品的标签没有权重,那么可以是1)。
是物品W的标签t的权重(如果物品的标签没有权重,那么可以是1)。
上面是基于用户兴趣标签计算的用户跟物品的匹配度,如果用户或者物品可以嵌入到某个低维向量空间,那么也可以用向量的相似度(如cosine余弦相似度)来表示用户和物品的相似度。具体怎么嵌入,我们在第9章9.1.3.2节“个性化召回”中已经介绍了核心思想,这里不再赘述。
匹配用户画像的排序算法结合了用户的行为,是一种个性化的排序算法,所以是比较合理的一种排序方式。这种排序方式其实就是基于内容的推荐排序算法,只要用户有部分操作行为,这种排序算法就可以实施。它的缺点是可能给用户推荐的物品局限于用户比较有兴趣的类别中,容易产生信息茧房效应。
11.5 利用代理算法排序
如果我们有一个代理算法能够对物品进行排序,那么我们也可以基于这个排序算法来对多个召回结果进行综合排序。这里举一个例子说明一下:比如我们推荐的物品是文章,假设我们有一个文章质量的算法,能够基于文章的一些特征(比如标题、长度、里面图片、创作者等级、错别字多少、排版是否优美、点击率等特征)来给文章排序,那么这个文章质量算法就可以用来为多个召回结果进行排序。假设我们的代理排序算法为F,那么基于代理算法的排序可以用公式记为:
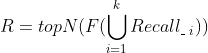
这种基于物品本身的代理排序算法最大的问题是非个性化的(即是没有包含用户特征的),所以排在前面的可能不一定是匹配用户兴趣的。为了让读者有更直观的理解,下面图7说明了利用代理算法的排序过程。
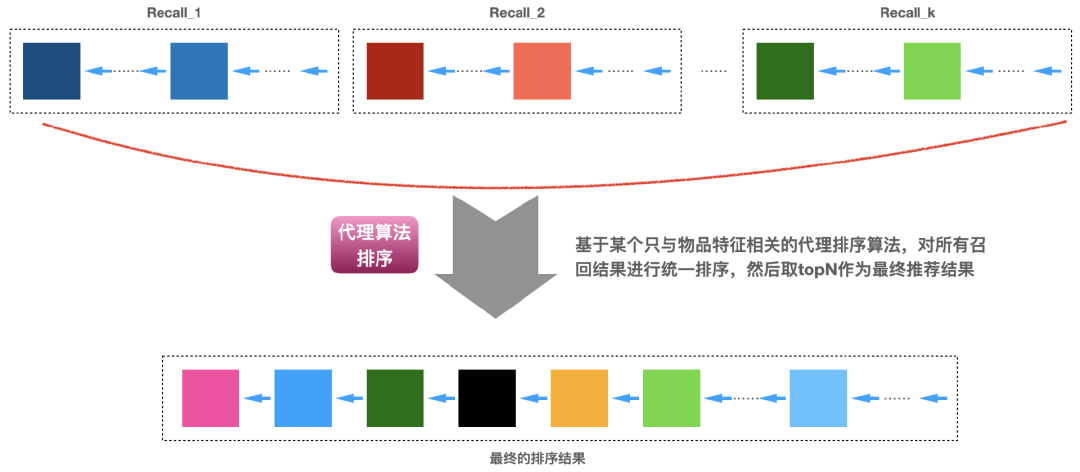
图7:基于某个代理算法对所有召回结果排序,然后取topN作为最终推荐
前面提到文章质量算法也是可以用到用户点击数据的(这些点击数据可能是通过爬虫爬取的外网数据),因此排序算法也代表了群体的一种行为偏好质量,所以代理排序算法是有一定科学性的。
11.6 几种策略的融合排序
上面我们讲到了5种可行的排序策略,这些排序策略是可以结合在一起使用的。比如我们可以先对每个召回列表按照11.4节介绍的方法对每个召回列表进行排序,那么这个排序后的召回列表中排在前面的就是与用户兴趣匹配度最高的,然后我们可以从排序好的召回结果中依次取1个按序排列(即上面11.2中的方法)获得最终的topN推荐结果,具体实现方案如下面图8所示。
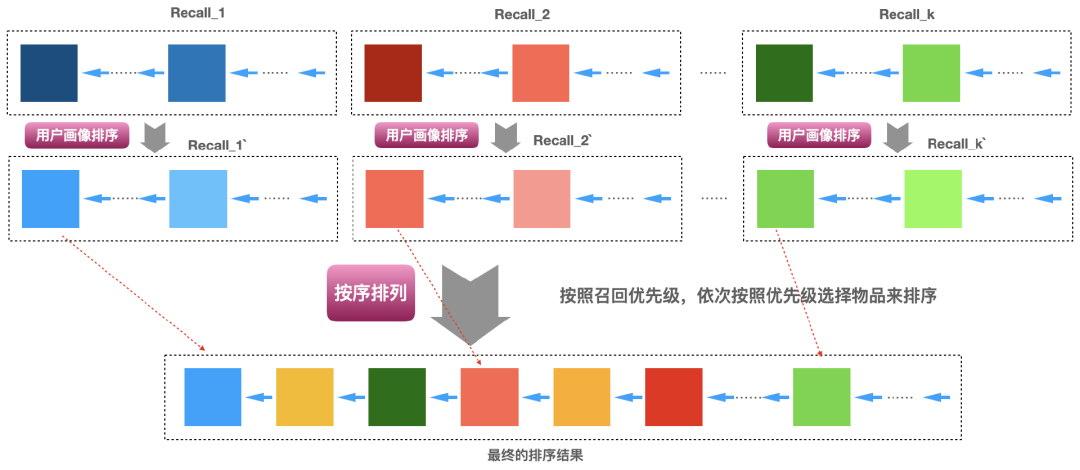
图8:先基于用户画像对每个召回排序得到新的有序列表,然后每个排序后的召回列表选择1个按序排列
下面我们再介绍一种更复杂的混合策略。我们可以先将召回结果分为两组,一组利用前面介绍的匹配用户画像排序获得最终的排序结果,我们记为Recall_P,另外一组我们可以用代理算法进行排序,排序后的列表我们记为Recall_k` ,然后对Recall_P和Recall_k`这两组列表,我们可以采用11.2节介绍的方法从每个列表中选取topM,然后将他们按照顺序拼接起来形成最终的topN推荐结果,具体实现过程可以参考下面图9。

图9:召回算法先分组,每组用不同排序策略,最终再一次排序
上面只是举了两个混合排序的例子,其它各种可行的混合排序策略大家可以自行尝试。可以说,上面提到的任何两个策略都是可以混合使用的,具体怎么使用需要结合具体场景和业务来实施,这里不再赘述。
总结
本章我们介绍了5种非常简单的基于规则和策略的排序算法,这几种方法也是可以混合使用的。这5种排序算法的原理非常简单,比较适合在没有太多用户行为数据(比如某个产品刚推入市场,还在拓展用户阶段)的场景下使用。虽然这5个排序方法简单粗暴,但是还是非常有适用价值的,这些思想读者可以好好掌握。我们会在接下来的2章介绍真正的基于机器学习算法的排序模型,这些方法就是更加科学有效的排序方式了。
大家如果想更全面学习推荐系统,可以购买作者之前出版的图书,购买链接如下:
