######################
尊重版权,转载注明地址
######################
相似度算法介绍
相似度算法主要任务是衡量对象之间的相似程度,是信息检索、推荐系统、数据挖掘等的一个基础性计算。下面重点介绍几种比较常用的相似度算法。
向量表示
通常假设对象X和Y都具有N维的特征,即
X=(x_1,x_2,…x_n) Y=(y_1,y_2,…y_n)
在推荐场景下,假设用户物品矩阵为:

item1=(0,1,1) item2=(1,0,1)
1.欧氏距离
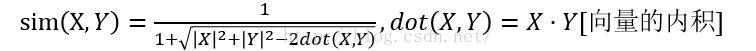
欧式距离相似度算法需要保证各个维度指标在相同的刻度级别,比如对身高、体重两个单位不同的指标使用欧氏距离可能使结果失效。
并且,欧氏距离适合比较稠密的矩阵。
增量计算说明:
•【在计算增量时候,|x|+|y|必然会增大】
•当|x*y|都出现时候,|x|+|y|至少增加了2,两项抵消,最多是相等,否则分母变大,值会变小
•当|x*y|只出现其中一个,|x+y|至少增加 1,依然是分母变大,值变小。
•规律,随着增量的增加,该公式一定会让出现的相似度减小。相反,没有再出现的物品,x,y,反倒相似度维持不变
2.余弦相似
数据稀疏性强,就考虑用夹角余弦相似度算法
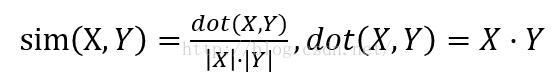
缺点:余弦相似度受到向量的平移影响,上式如果将x平移到x+1,余弦值就会改变【即当各个对象的评分指标不一致的时候,余弦相似度不能稳定刻画其相似,这种情况下使用皮尔逊相似度会更好】
3. 皮尔逊相似度
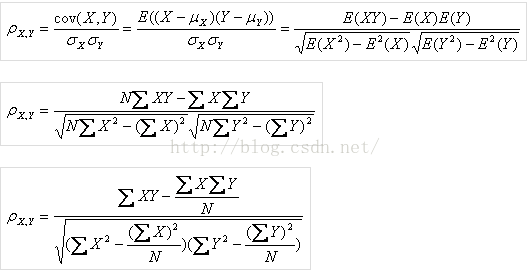
计算相对比较复杂,只能应用于带评分的场景,对不同刻度的评分(如一个对象评分集中在4分,另一个集中在3分)衡量相似度时具有良好的效果。在计算相似度时采用了这种方法,近似的可以把最后一个带N的去掉(默认N很大,作为分母几乎趋近于0)。出现一次的计为1,出现多次的统一计为2.
4. 简单粗暴的N/M
应用于元素值为1或者0的向量。
当计算与A相似对象的相似值的时候, 如A与X,Y之间的相似,则计算公式为
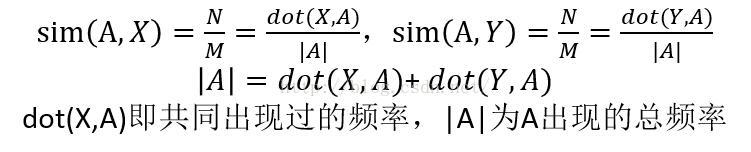
计算结果不是特别准,适用于数据量非常庞大,对若干对象的近似估计
5. IUF相似度(基于用户活跃度倒数的参数)
对比前面的余弦相似,余弦相似也可以表示为
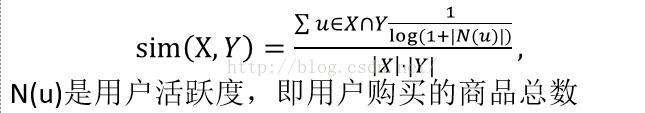
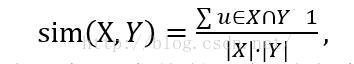
这里即为对每一个值的累加时考虑了用户的因素。
效果:能推出更多的商品来,提高召回率
相似度算法效果测试
样本数据
测试结果


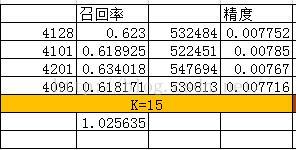
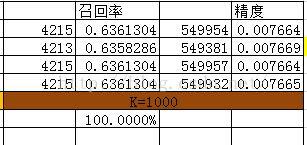
其中: 精度 = 推荐被购买的商品总数 / 总推荐商品数
召回率 = 推荐被购买的商品总数 / 测试集商品数
结论
当推荐坑位商品曝光数小于15时,如果追求更多的商品曝光建议采用IUF相似度,如果追求精确度建议采用N/M+,当曝光商品足够多时,相似度算法已经成为传说~~恩 对,只是传说而已。然而在博主实际项目使用中发现,可以根据相似度矩阵的稀疏程度,对K取阈值,多种相似度算法协同使用~~~在此基础之上后 续可以考虑增加商业因子进行二次排序~~空间很大,看你能触摸到多少~
————————————————
版权声明:本文为CSDN博主「蚂蚁大哥大」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/pztyz314151/article/details/52094588
