note
一、推特开源推荐算法
项目地址:https://github.com/twitter/the-algorithm
内容:从数据获取,到特征加工、召回再到粗排、精排,到最后的混合出结果整个链路。推特更关注用户以及推特之间组成的数据网络图。会涉及一些图特征和图算法。

项目亮点:
- 多模态:该项目支持多种类型的数据,包括文本、图片、视频等。
- 实时性:该项目使用实时流处理技术,能够及时处理大量的用户行为数据,并实时地生成推荐结果。
- 可扩展性:该项目使用分布式计算技术,可以方便地进行水平扩展和增加计算资源。
- 精度高:该项目采用了多种推荐算法,包括内容过滤、协同过滤、基于图的推荐等,能够提供高质量的个性化推荐服务
二、Twitter Recommendation Algorithm
项目中包括的组件模块(含有大部分的Bazel BUILD files):
| Type | Component | Description |
|---|---|---|
| Feature | SimClusters | Community detection and sparse embeddings into those communities. |
| TwHIN | Dense knowledge graph embeddings for Users and Tweets. | |
| trust-and-safety-models | Models for detecting NSFW or abusive content. | |
| real-graph | Model to predict likelihood of a Twitter User interacting with another User. | |
| tweepcred | Page-Rank algorithm for calculating Twitter User reputation. | |
| recos-injector | Streaming event processor for building input streams for GraphJet based services. | |
| graph-feature-service | Serves graph features for a directed pair of Users (e.g. how many of User A’s following liked Tweets from User B). | |
| Candidate Source | search-index | Find and rank In-Network Tweets. ~50% of Tweets come from this candidate source. |
| cr-mixer | Coordination layer for fetching Out-of-Network tweet candidates from underlying compute services. | |
| user-tweet-entity-graph (UTEG) | Maintains an in memory User to Tweet interaction graph, and finds candidates based on traversals of this graph. This is built on the GraphJet framework. Several other GraphJet based features and candidate sources are located here | |
| follow-recommendation-service (FRS) | Provides Users with recommendations for accounts to follow, and Tweets from those accounts. | |
| Ranking | light-ranker | Light ranker model used by search index (Earlybird) to rank Tweets. |
| heavy-ranker | Neural network for ranking candidate tweets. One of the main signals used to select timeline Tweets post candidate sourcing. | |
| Tweet mixing & filtering | home-mixer | Main service used to construct and serve the Home Timeline. Built on product-mixer |
| visibility-filters | Responsible for filtering Twitter content to support legal compliance, improve product quality, increase user trust, protect revenue through the use of hard-filtering, visible product treatments, and coarse-grained downranking. | |
| timelineranker | Legacy service which provides relevance-scored tweets from the Earlybird Search Index and UTEG service. | |
| Software framework | navi | High performance, machine learning model serving written in Rust. |
| product-mixer | Software framework for building feeds of content. | |
| twml | Legacy machine learning framework built on TensorFlow v1. |
2.1 召回模型
Twitter有很多召回数据源,为用户召回最新、最感兴趣的相关推文。
- 输入:推文候选池大小,hundreds of millions 亿万级别。
- 输出:两类召回通道:你关注的用户圈(in-network)、你未关注的用户圈(out-of-network),整体上,二者比例是55开。
- in-Network召回:使用自研Earlybird搜索引擎,导致是倒排索引,要过一个Light ranker海选粗排模型进行该召回路的截断。
- out-of-Network召回:SimClusters、TwHIN等表征学习
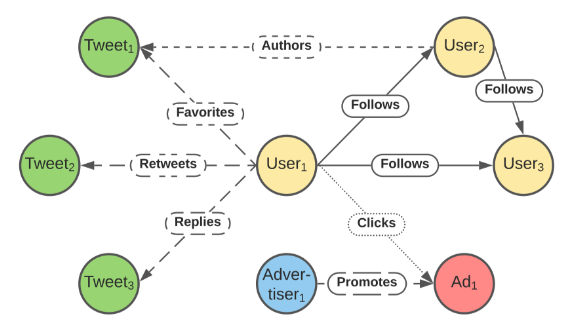
2.2 排序模型
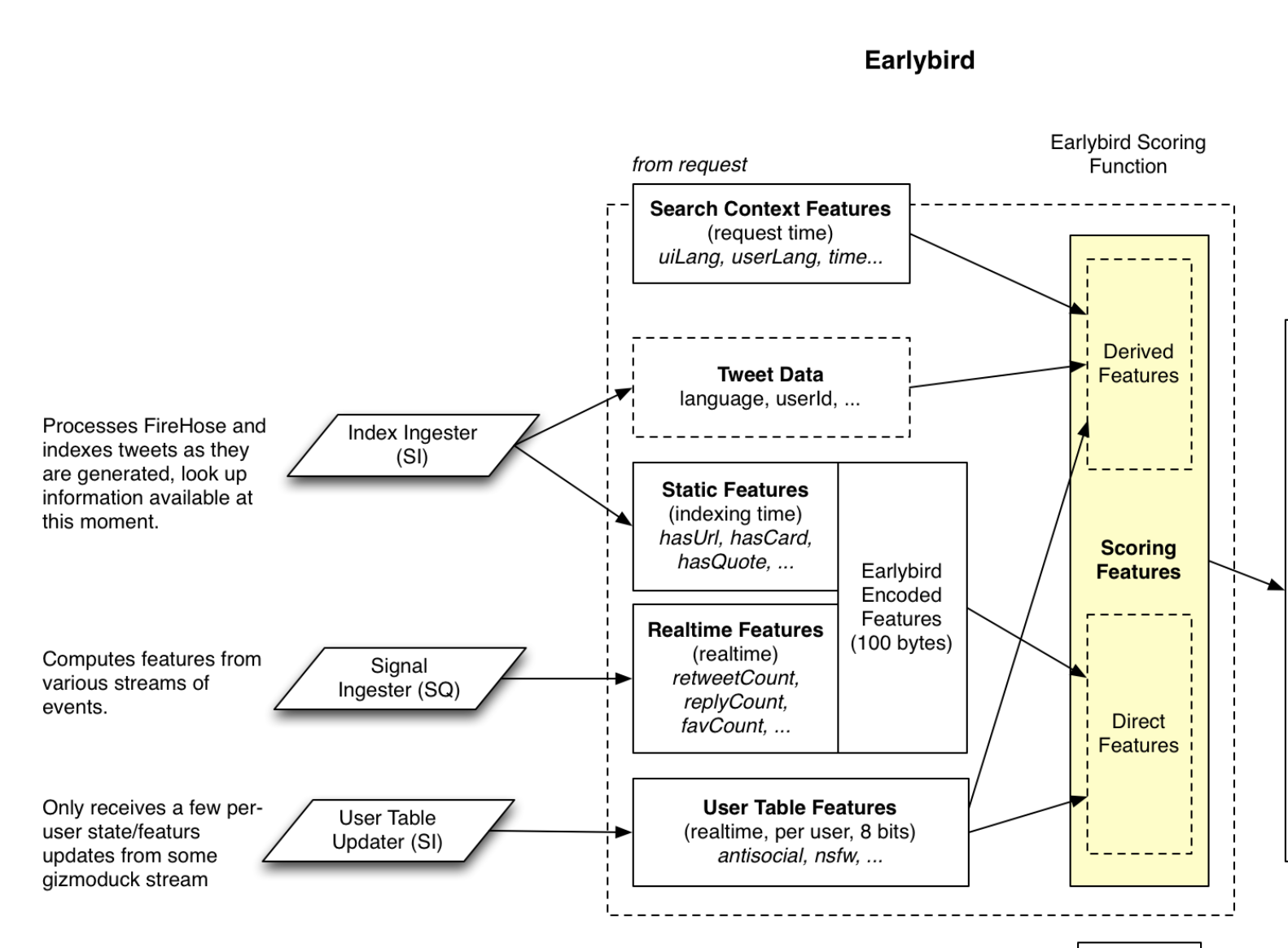
- 粗排:light ranker的特征pipeline如上图,LR模型
- 粗排模型基于推特本身以及用户时间线构建特征,会对用户收到推特之后的多个反应做出预测。也就是说这是一个多目标模型,会对用户收到推特之后是否会点击、点赞、评论等做出预测。最后再将这些多个目标之间的预测结果根据不同的权重融合得到一个得分,最后根据这个得分进行排序。
- 精排:heavy rank使用新浪以前的masknet模型
- 重排:规则导向有作者多样性、In-Network推文和Out-of-Network推文的控比、屏蔽的推文作者等
三、基础建设
- 模型serving服务:Navi,High performance, machine learning model serving written in Rust.
- Feeds信息流推荐框架:Product-mixer,Software framework for building feeds of content.
- 机器学习训练框架:twml,基于TF-1,目前用于训练粗排Earlybird light ranker
Reference
[1] https://github.com/twitter/the-algorithm
[2] A new era of transparency for Twitter
[3] KDD 2020:SimClusters: Community-Based Representations for Heterogeneous Recommendations at Twitter
[4] KDD 2022:TwHIN: Embedding the Twitter Heterogeneous Information Network for Personalized Recommendation