目录
基于内容的推荐算法
快速构建基于内容的推荐系统的基本流程,分为四步
1、特征内容提取
提取每个待推物品的特征(内容属性),比如书本电影的分类标签
2、用户偏好计算
利用用户过去的显示评分或隐式操作记录,计算用户在不同特征上的偏好分数
- 计算偏好分数方法:
| 表4.1用户A和B的评分矩阵 | ||||
| 电影名称 | 爱情 | 科幻 | 用户A | 用户B |
| 银河护卫队 | / | 1 | 5分 | ? |
| 变形金刚 | / | 1 | 4分 | 2分 |
| 星际迷航 | / | 1 | 5分 | 3分 |
| 独立日 | / | 1 | ? | 2分 |
| 七月与安生 | 1 | / | ? | 3分 |
| 三生三世 | 1 | / | 3分 | ? |
| 美人鱼 | 1 | / | 2分 | 3分 |
| 北京遇上西雅图 | 1 | / | 2分 | 5分 |
| 美人鱼 | 1 | / | 2分 | 3分 |
| 北京遇上西雅图 | 1 | / | 2分 | 5分 |
可以直接使用统计特征,即计算用户在不同标签下的分数,较快,在计算偏好得分的时候会增加时间因子,例如用户A在科幻下的分数为(5*+4*
+5*
)/3 其中a取小于1的数值,值越小时间衰减越快,difftime 是用户对该物品评分时到现在的时间间隔。
3、内容召回
将待推物品的特征(内容属性)与用户偏好得分相匹配,取出用户最有可能喜欢的物品池
4、物品排序
按用户偏好召回物品池,物品池里有很多内容,将这些内容按评分的平均分排序,将排序较高的物品优先推荐给用户
基于内容推荐的特征提取
| 表4.2电影内容特征二进制表示 | |||||||
| 爱情 | 剧情 | 科幻 | 战争 | 中国 | 日本 | 韩国 | 美国 |
| 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| 其中0表示该电影不具备该特征,1表示该电影具备该特征。 | |||||||
- 结构化特征就是特征的取值限定在某个区间范围内,并且可以按照定长的格式来表示。例如电影类别特征,算法人员往往会和编辑提前约定好所有可选的电影类别,并把所有备选的电影都标注上这些类别标签。假如可选的电影类别有“爱情、剧情、科幻、战争、中国、日本、韩国、美国”共计8个类别(当然真实的分类远不止8个)。《星球大战》同时具有科幻和美国2个内容特征,那么它的结构化特征可用一个8位的二进制数表示。
- 非结构化的特征往往无法按固定格式表示,最常见的非结构化数据就是文章。例如对推荐文章,我们往往会把文本上的非结构化特征转化为结构化特征
如何把非结构化的文字信息结构化:
例如N个待推荐文章的集合为D={d1,d2,d3,···,dN},而所有文章中出现的词的是集合为T={t1,t2,t3···,tm},下面将其称为词典(对于英文文本,可直接取单词;对于挑中文文章,需要先进行分词,常用的开源分词工具有结巴分词①、中科院分词等)。也就是说,我们有N篇待推荐的文章,而这些描述里包含了m个不同的词。我们最终要使用 一个向量来表示每一篇文章,比如第j篇文章表示为dj=(w1j,w2j)···,wnj),其中 表示第1个词t1j在第j篇文章中的权重,该值越大表示越重要;中其他向量的解释 类似。所以,现在关键就是如何计算dj各分量的值了。
常见的计算方法:
(1)基础统计法:例如,如果词t1出现在第j篇文章中,我们可以选取W1j为1; 如果t1未出现在第j篇文章中,选取为0。我们也可以选取2013为词t1出现在第j个商品描述中的次数(frequency)。
(2)词频统计法:基础统计法,只考虑了词t是否出现在某一篇文章中,并没有考虑其整体出现的频次。例如词k是“我们”,第j篇文章包含这个词,则取1。但这个 词其实并没有信息量,因为很多文章都包含了“我们”,Wk都会取1。
所以通常会引入词频—逆文档频率①。第j篇文章与词典里第k个词对应的TF—IDF为:

其中 TF(tk,dj)是第k个词在第j个商品描述中出现的次数,出现的次数越多,代表该词越重要,从而TF值越大。而nk是包括第k个词的文章数量,越少,代表该词越稀有,越能代表这篇文章,从而TF值越大。最终第k个词在文章j 中的权重由下面的公式获得:

这时候我们已经获得每篇文章的内容特征向量,形如dj=(W1j,W2j,.··,wnj),下一 步就可以计算用户的内容偏好,比较直接的做法就是取用户喜欢文章的向量平均值。假设用户k喜欢第1、3、7篇文章,则该用户的内容特征向量为:Uk=(dk1+dk3+dk)/3=(u1k,u1k,⋯,unk)
那么用户k在文章t上的得分则可用以下余弦公式计算:
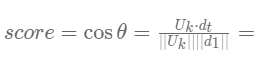
#直接使用向量计算余弦距离
def cosSim(U_k,W_t):
num = float(U_k.T * W_t)
denom = linalg.norm(U_k)* linalg.norm(W_t)
return 0.5 + 0.5 * (num/denom)- 推荐系统取得得分score最高的文章推荐即可,余弦值范围在[1,-1]之间,值越靠近1,代表两个向量的方向越接近,用户可能越喜欢,值越趋近于- 1,两个商品方向越相反,用户越不可能喜欢,完成文章这种不具备结构化内容特征的物品的推荐
基于内容的召回
一、标签召回
内容标签提取
- 类目获取
- 关键词提取
- TF-IDF
- TextRank
给用户打标签
用户标签权重=行为类型权重∗行为频次∗时间衰减∗TF−IDF标签重要度
物品拉链排序
当数据库中没有内容特征数据时,需要提取内容特征。真实推荐系统中待推荐的物品具有两方面的特征:结构化特征和非结构化特征。
二、向量表示召回
- LDA
- Doc2Vec
- 向量检索
- 离线计算
- 在线召回
深入浅出推荐系统(二):召回:内容为王_慕阮的博客-CSDN博客_lda召回
基于内容的推荐算法优点:
- 物品没有冷启动问题,物品的内容特征不依赖与用户数据,同时推荐出的物品不会存在过热门的问题
- 考虑到有特殊兴趣爱好的用户的推荐
- 原理简单,易于定位问题