注意力机制基本原理
人类的视觉系统中存在一种特殊的大脑信号处理机制,会选择性地对场景中重点区域即注意力焦点花费更多的时间,而忽视其他并不重要的信息。这是人类从大量信息中快速筛选出重要信息的手段,极大地提高了视觉系统处理海量信息的效率和精准率。
从人类视觉信号处理机制中得到启发,深度学习中也有类似的注意力机制,选择并强调对目标有重要影响的信息,而抑制不重要的信息。自然语言处理中序列模型通常采用的是循环神经网络,它对于序列所有位置上的信息都一视同仁。
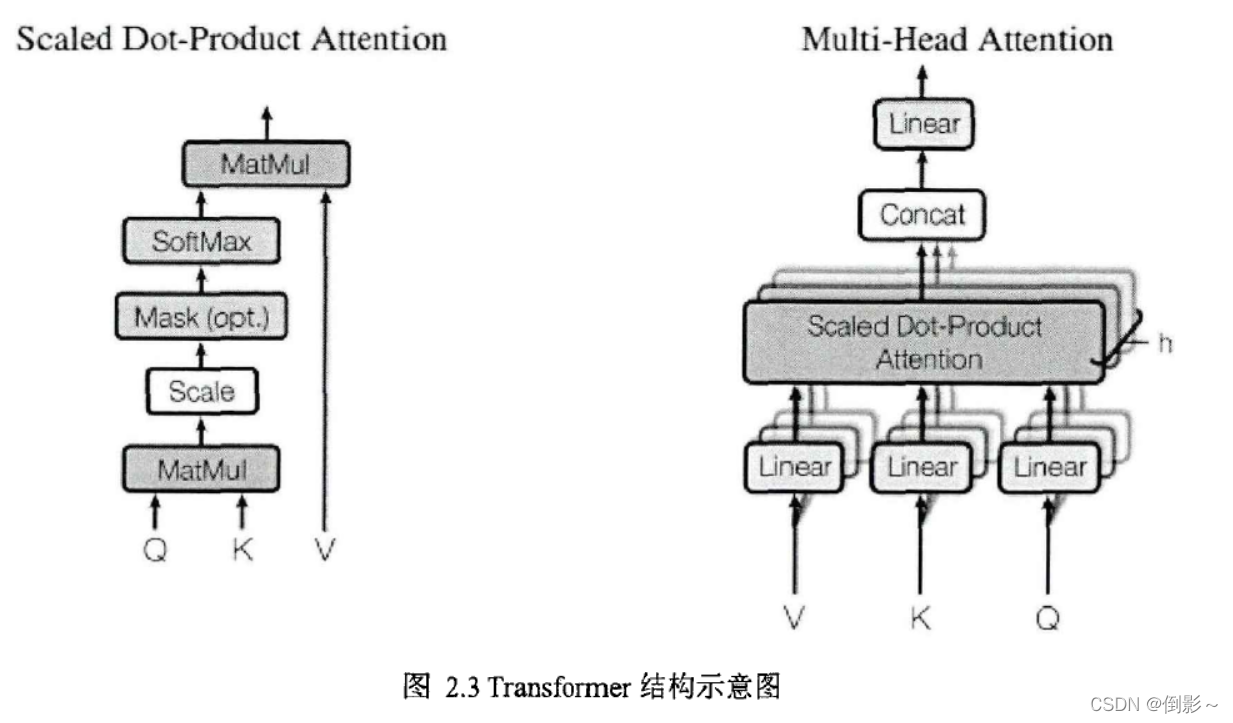
2017年,谷歌团队仅使用注意力机制和前馈神经网络搭建的Transformer模型是具有里程碑意义的研究工作,Transformer是第一个完全依赖自注意力机制建模输入和输出对应关系的模型,而没有米用循环神经网络或卷积神经网络。其中频繁使用的自注意力模型是一种特殊的注意力机制,其依靠单一序列中不同位置之间的相关性信息来建模序列的特征。注意力机制用数学形式表示,即建立查询向量和键值对向量到输出向量的映射关系,Transformer中采用的是缩放点积注意力(Scaled Dot-Product Attention),其具体计算见公式:
Attention ( Q , K , V ) = Softmax ( Q K T d k ) V \operatorname{Attention}(\mathbf{Q}, \mathbf{K}, \mathbf{V})=\operatorname{Softmax}\left(\frac{\mathbf{Q K}^{\mathrm{T}}}{\sqrt{d_{k}}}\right) \mathbf{V} Attention(Q,K,V)=Softmax(dkQKT)V
其中,Q、K、V分别表示查询向量,键向量和值向量,dk表示向量维度,也作为缩放因子。在自注意力中,Q、K、V都是由同一个输入X经过不同矩阵W映射变换得到,具体计算见公式:
Q = X W Q , K = X W K , V = X W v \mathbf{Q}=\mathbf{X} \mathbf{W}^{\mathbf{Q}}, \mathbf{K}=\mathbf{X} \mathbf{W}^{\mathbf{K}}, \mathbf{V}=\mathbf{X} \mathbf{W}^{\mathbf{v}} Q=XWQ,K=XWK,V=XWv
在缩放点积注意力的基础上,Transformer设计了多头部注意力(Multi-head attention)结构,从不同的特征空间中学习自适应注意力分布,进而得到更好的序列特征,具体计算见公式:
Multi-head ( X ) = Concat ( head 1 , … , head h ) W 0 where head i = Attention ( X W i Q , X W i K , X W i V ) \begin{aligned} &\text { Multi-head }(\mathbf{X})=\text { Concat }\left(\text { head }_{1}, \ldots, \text { head }_{\mathrm{h}}\right) \mathbf{W}^{0} \\ &\text { where head }_{\mathrm{i}}=\text { Attention }\left(\mathbf{X} \mathbf{W}_{\mathrm{i}}^{\mathrm{Q}}, \mathbf{X} \mathbf{W}_{\mathrm{i}}^{\mathrm{K}}, \mathbf{X} \mathbf{W}_{\mathrm{i}}^{\mathrm{V}}\right) \end{aligned} Multi-head (X)= Concat ( head 1,…, head h)W0 where head i= Attention (XWiQ,XWiK,XWiV)
Transformer中缩放点积注意力和多头部注意力的结构如图2.3所示,其使用自注意力机制在常数操作复杂度下将序列中任意位置信息建立联系,而循环神经网络需要0(n)复杂度才能实现,这意味着自注意力机制更容易学习到长距离依赖关系,同时自注意力机制的参数量和计算量通常比循环神经网络更少,而且更利于模型的并行计算。
目标检测中的注意力机制
目标检测中主要通过掩码方式形成注意力分配,可以分为硬注意力和软注意力。硬注意力是非0即1的分布问题,而软注意力是[〇,1]之间的连续分布问题,都代表各区域需要被关注的程度高低。更关键的是软注意力是连续可微分的,可以通过梯度下降等算法学习到注意力权重分布,因此软注意力相比硬注意力应用更加广泛,本节主要介绍软注意力的实现及应用。
STN网络
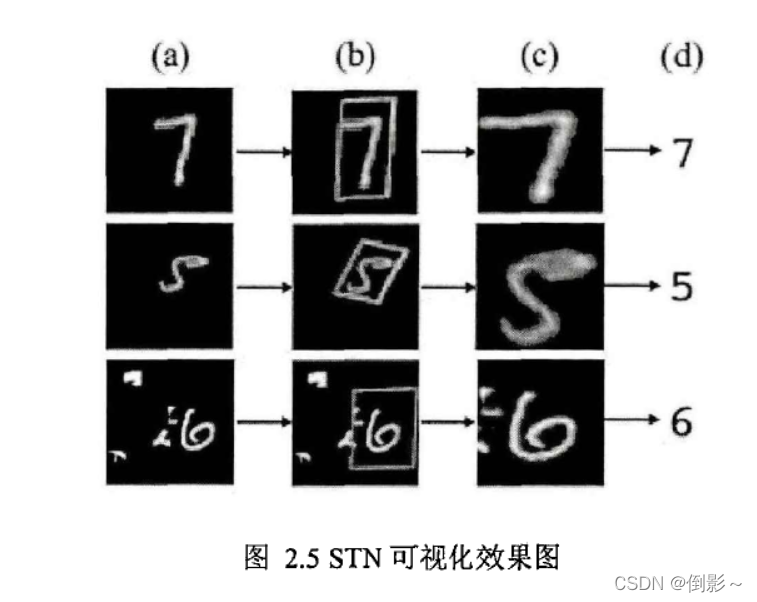
2015年Jaderberg等提出Spatial Transformer Networks,在特征图层面上实现全局的缩放、旋转等变换,从而使网络具有缩放、旋转等变换不变性。同时STN也是注意力机制的一种实现,其不但能够选择图像中最值得注意的区域特征,而且能够将这些特征经过变换后调整到正确的姿态,从而更有利于之后的分类器进行识别。

STN网络结构如图2.4所示,先使用Localisation network得到特征图所对应的变换参数, θ = f l o c ( U ) \theta=f_{loc}(U) θ=floc(U),若米用仿射变换则 θ \theta θ是六维向量。
然后使用转换参数 θ \theta θ来创建一个采样网格见公式(2.4),代表输入特征图上需要被采样的一组点集,即需要关注的区域。最后通过连续插值的方式从原特征图中得到变换后的特征图,这里可以使用双边插值。
( x i s y i s ) = T θ ( G i ) = [ θ 11 θ 12 θ 13 θ 21 θ 22 θ 23 ] ( x i t y i t 1 ) (2.4) \left(\begin{array}{c} \mathrm{x}_{\mathrm{i}}^{\mathrm{s}} \\ \mathrm{y}_{\mathrm{i}}^{\mathrm{s}} \end{array}\right)=\mathrm{T}_{\theta}\left(\mathbf{G}_{\mathrm{i}}\right)=\left[\begin{array}{ccc} \theta_{11} & \theta_{12} & \theta_{13} \\ \theta_{21} & \theta_{22} & \theta_{23} \end{array}\right]\left(\begin{array}{c} \mathrm{x}_{\mathrm{i}}^{\mathrm{t}} \\ \mathrm{y}_{\mathrm{i}}^{\mathrm{t}} \\ 1 \end{array}\right) \tag{2.4} (xisyis)=Tθ(Gi)=[θ11θ21θ12θ22θ13θ23]⎝⎛xityit1⎠⎞(2.4)
其中, ( x i t , y i t ) \left(x_{i}^{t}, y_{i}^{t}\right) (xit,yit)表示变换后特征图网格位置, ( x i s , y i s ) \left(x_{i}^{s}, y_{i}^{s}\right) (xis,yis)表示原特征图上采样点的坐标位置。STN变换可视化效果如图2.5所示,可以直观看出STN网络可以自适应学习到不同图像需要关注的重点区域,并且通过一些变换方式得到更利于
识别的特征图。
SENet网络
特征和空间注意力检测技术
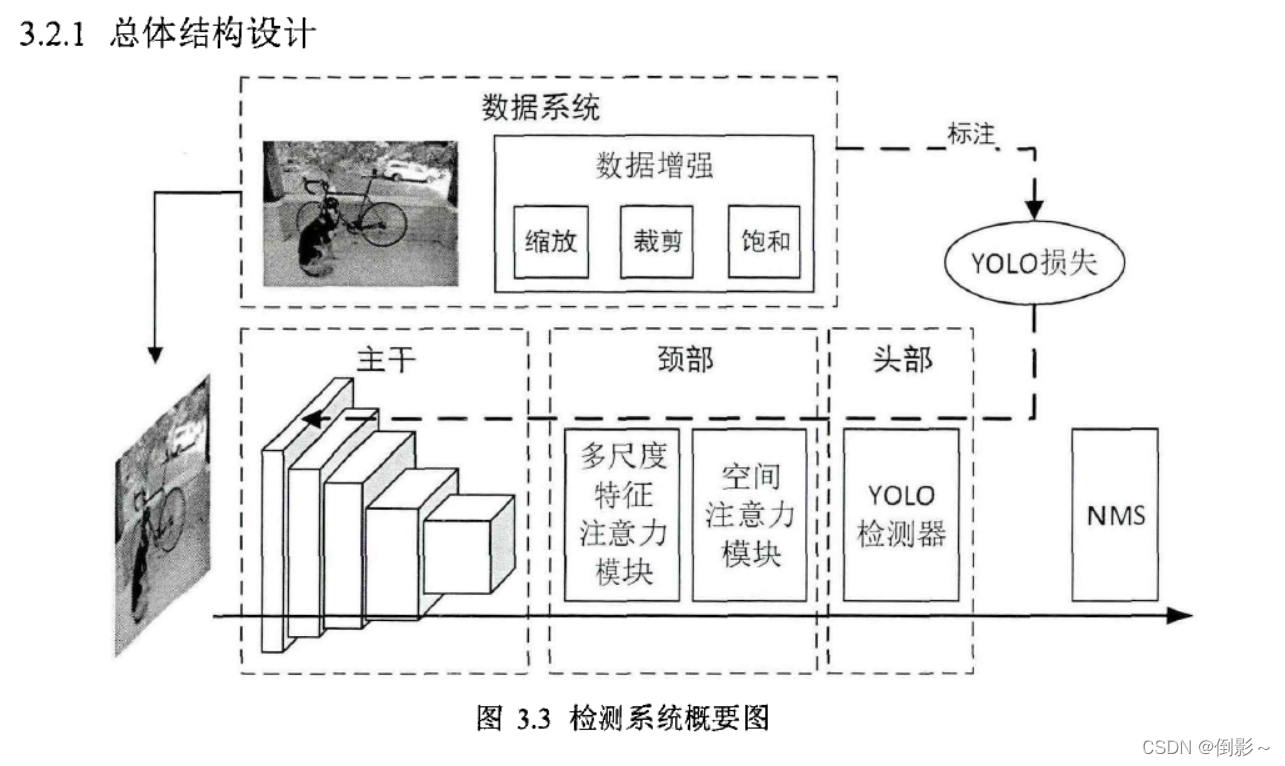
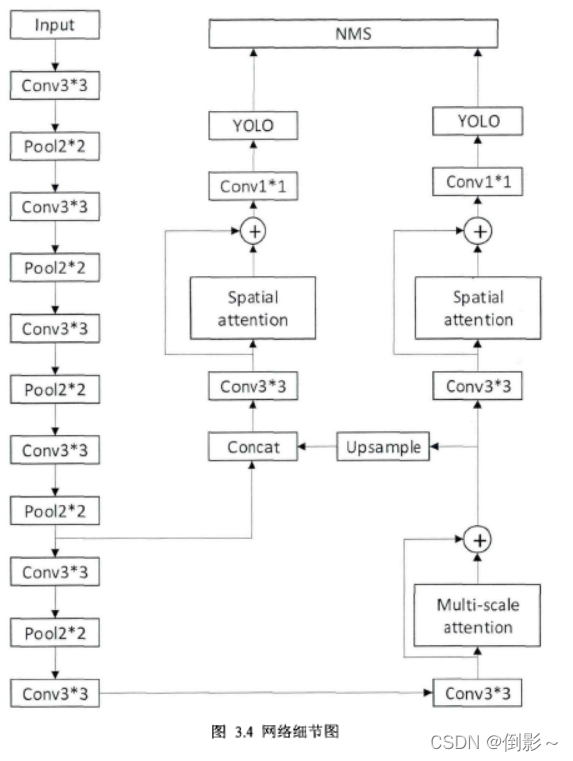
主干网络由卷积层和池化层组成,用来提取图像多层级特征,在最高层特征图后接上多尺度特征注意力模块提取多尺度感受野融合特征。检测器在两个尺度特征图上做检测,通过多尺度特征注意力模块后的特征图经过上采样后和低层特征图融合以提升特征表达,在检测器前通过空间注意力模块自适应选取更重要的区域,有助于检测器更高效学习。最后将所有检测结果输入NMS模块抑制重复的检测框,得到最终检测结果。
参考文献:
[1] 庄小平. 融合多维度注意力的视频目标检测技术研究[D].浙江大学,2021.DOI:10.27461/d.cnki.gzjdx.2021.001251.