文章目录
一、算法介绍
线性回归:监督学习---->回归算法
二、算法原理
线性回归是利用回归方程(函数)对一个或多个自变量(特征值)和因变量(目标值)之间关系进行建模的一种分析方式
通用公式:
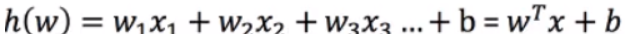 损失函数:
损失函数:
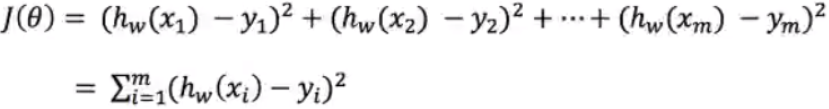 yi为第i个训练样本的真实值
yi为第i个训练样本的真实值
h(xi)为第i个训练样本特征值组合预测函数
又称最小二乘法
正规方程:
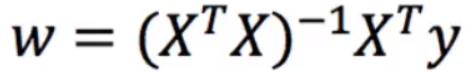 x为特征值矩阵,y为目标值矩阵。直接求到最好的结果
x为特征值矩阵,y为目标值矩阵。直接求到最好的结果
三、一元线性回归
1、简单
import numpy as np
import matplotlib.pyplot as plt
# 建立回归方程是: y = kx + b 为一元回归方程
X = np.array([[150],
[200],
[250],
[300],
[350],
[400],
[600]
])
X = X.reshape(-1, )
y = np.array([6450, 7450, 8450, 9450, 11450, 15450, 18450])
m = len(y)
x_mean = np.mean(X) # x的均值
fenzi = np.sum(y * (X - x_mean))
fenmu = np.sum(X ** 2) - 1 / m * (np.sum(X) ** 2)
w = fenzi / fenmu
b = 1 / m * np.sum((y - w * X))
print("系数和截距", w, b)
# y = 28.77659574468084 + 1771.8085106383014
y_pred = X * w + b
plt.scatter(X, y)
plt.plot(X, y_pred)
plt.show()
2、sklearn
from sklearn.linear_model import LinearRegression
import numpy as np
import matplotlib.pyplot as plt
X = np.array([[150],
[200],
[250],
[300],
[350],
[400],
[600]
])
y = np.array([6450, 7450, 8450, 9450, 11450, 15450, 18450])
# 实例化
lr = LinearRegression()
lr.fit(X, y)
print("系数和截距", lr.coef_[0], lr.intercept_)
y_pred = lr.predict(X)
plt.scatter(X, y)
plt.plot(X, y_pred)
plt.show()
3、正规方程解
import numpy as np
import matplotlib.pyplot as plt
X = np.array([[150],
[200],
[250],
[300],
[350],
[400],
[600]
])
y = np.array([6450, 7450, 8450, 9450, 11450, 15450, 18450])
# 左右合并
arr_ones = np.ones((7, 1))
X = np.hstack((arr_ones, X))
mat_X = np.mat(X)
mat_y = np.mat(y).reshape(-1, 1)
# print(mat_X)
# print(mat_y)
w = (mat_X.T * mat_X).I * mat_X.T * mat_y
print(w)
print("k b", w[1, 0], w[0, 0])
四、算法特点
1、简单,易实现
2、模型具有很好的解释性,有利于决策分析
3、不适合高度复杂的数据
五、算法API
def init(self, *, fit_intercept=True, normalize=False, copy_X=True, n_jobs=None, positive=False):
fit_intercept:是否计算偏置
六、性能评估
1、均方误差
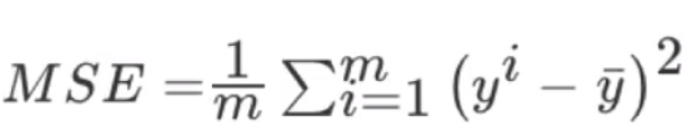 MSE=mean_squared_error(y_test, y_pred)
MSE=mean_squared_error(y_test, y_pred)
2、RMSE
RMSE=sqrt(MSE)
3、MAE 平均绝对误差
MAE=mean_absolute_error(y_test, y_pred)
七、波士顿房价预测
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression # 正规方程法回归
from sklearn.linear_model import SGDRegressor # 随机梯度下降回归
from sklearn.metrics import mean_squared_error # MSE 均方误差
# RMSE 需要自己实现
from sklearn.metrics import mean_absolute_error # MAE 平均绝对误差
import numpy as np
from sklearn.preprocessing import StandardScaler
out = load_boston() # 返回的结果是字典
# print(out.keys())
# print("描述信息\n", out['DESCR'])
f_name = out["feature_names"]
print("特征名称", out["feature_names"])
X, y = out["data"], out["target"] # (506,13)
# -----------------------拆分数据集-------------------------------
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=0.2,
random_state=1
)
# 如果数据是区分训练集 和测试集
# 使用训练集样本 计算 标准化的参数
# 分别对训练集 和测试进行转换处理
std = StandardScaler()
std.fit(X_train)
X_train = std.transform(X_train)
X_test = std.transform(X_test)
# ----------------------算法-----------------------------------------------
lr = LinearRegression()
lr = SGDRegressor()
# 有监督学习 使用训练集特征和标签 进行拟合算法
lr.fit(X_train, y_train)
# fit完毕后,算法也就存在,线性回归方程已经存在
coef = [round(i,2) for i in lr.coef_]
print("系数",coef )
print("截距", lr.intercept_)
# ---------------------------构建回归方程----------------------------------------------
# y = CRIM * -0.11 + ZN * 0.06
str1 = "y = "
for f, w in zip(f_name, coef):
str1 += "{}*{} +".format(f, w)
str1 += str(lr.intercept_)
print(str1)
"""
Nox系数是负的最大值, NOX 越大---房价 越低
RM系数是正的最大值, RM越大-----房价 越高
"""
# ----------------------------------数据可视化-----------------------------------------
# 在测试集上进行测试
y_pred = lr.predict(X_test) # 预测结果
# # 真实结果 y_test
#
import matplotlib.pyplot as plt
plt.plot(range(len(y_test)), y_pred, marker='o')
plt.plot(range(len(y_test)), y_test, marker='o')
plt.legend(["pred", "true"])
plt.show()
# ----------------------------------结果评估-------------------------------------------------
score = lr.score(X_test, y_test) # 0.7634174432138463
print("R2的得分是", score)
print("mse", mean_squared_error(y_test, y_pred))
print("rmse", np.sqrt(mean_squared_error(y_test, y_pred)))
print("mae", mean_absolute_error(y_test, y_pred))
八、总结
在特征和标签之间 建立一个 线性回归方程 研究两者之间的关系
线性回归方程-----N元一次方程
特征只有一个 y = kx+b --------一元线性回归
未知数 k b
特征有2个或以上 y = w1x2+w2x2+…wn*xn+b-------------多元线性回归
未知数:w1 w2…wn b
目的:寻找一组最优的系数 (特征数目+1)
衡量最优解:L = 1/2m ∑(真实值-预测值)**2 [均方误差损失函数]
寻找系数的方法:对L进行计算,在L最小的情况下,可获取最优的系数
通用的求解方法
1)正规方程法,对损失函数进行求导
如果特征矩阵行 或 列数很大----矩阵运算量大
矩阵的逆 可能不存在
2)随机梯度下降法